神经辐射场
非显式地将一个复杂的静态场景用神经网络来建模。训练完成后,可以从任意视角渲染出清晰的场景图片。
过程
- 大量已知相机参数的图片作为输入
- 通过输入训练MLP神经网络,隐式地学习静态3D场景
- 利用模型输出任意角度的渲染图像
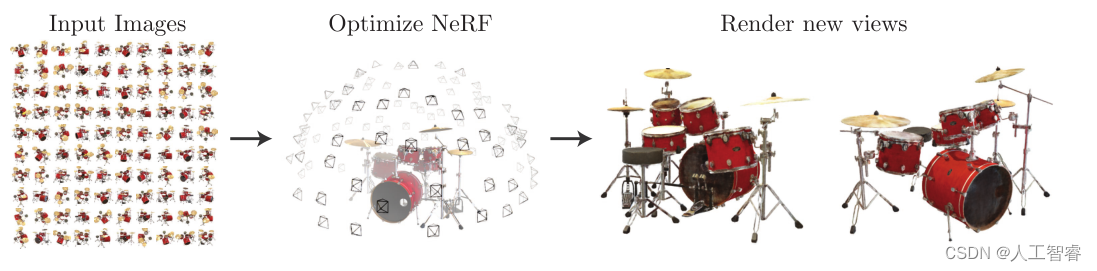
由上述过程可知,NeRF由一系列2D输入学习3D场景,最后又通过3D模型输出2D图像。那么就有3个核心技术点:
- a.怎么用神经网络表示3D的?
- b.怎么再基于3D渲染出2D的?
- c.这个神经网络的具体训练过程是怎么样的?
a.神经辐射场描述3D场景
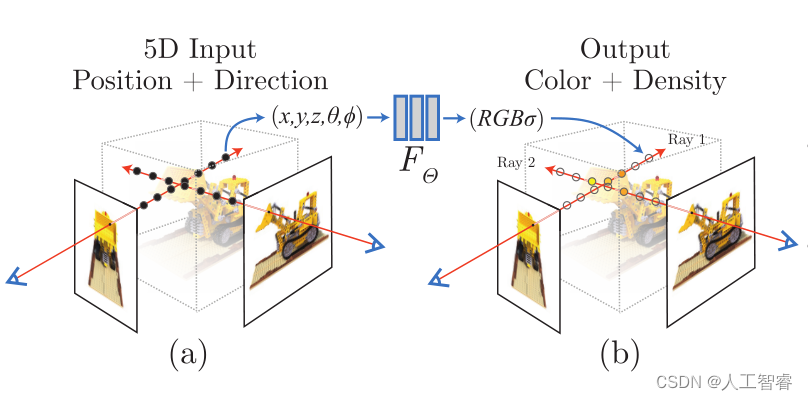
NeRF函数:
- 输入为空间点的3D坐标位置,以及2D观察方向。(为啥不是6D呢?因为这种5D神经辐射场将场景表示为空间任意点的体积密度和定向发射辐射,对于射线5D就可以完全描述
- 输出为空间点的反射RGB颜色和密度Density
- RGB预测与3D坐标和2D视角都有关
- Density预测只与3D坐标有关
b.神经辐射场的体素渲染
NeRF函数得到的是一个3D空间点在对应视角的RGB和Density, 但这个对应视角的RGB还不是相机视角下的RGB
- 因为相机成像的像素实际上对应的是投影光线上的所有连续空间点
作者使用了经典的体绘制思路渲染穿过场景的任意光线的颜色
- 为了能够用神经网络来渲染,这个方法必须是可微的
b.1经典的体绘制方法
就是写了一个射线方程(由射线原点和射线朝向描述),通过这个方程可以得到射线上任意点的颜色。
- 理论上可以得到射线上任意点的颜色,那么我们就可以用积分的方式得到整体的渲染颜色(类似透明度累计的感觉
- 但实际上,我们不可能遍历计算一个连续的线上的所有点,因此作者采用了数值近似的方法
b.2基于分段随机采样的离散近似volume rendering方式
数值近似的简单思路就是均匀抽样再积分
- 均匀抽样带来的问题就是把连续的数值离散化了,这样网络很难学习到射线上的连续性信息
所以作者选择先将需要积分的射线线段分为N个线段,然后对每个线段进行随机抽样再积分,以此保证辐射场的连续性
c.NeRF的训练细节
- 1.位置信息编码,直接输入位姿的时候网络很难学,这里采用了正余弦周期函数的形式,这种position encoding让网络更容易学
- 2.多层体素采样,考虑到射线上很多地方都是无用的空白或者遮挡区域,为了减少计算量,采用了一种“coarse to fine" 的形式,同时优化coarse 网络和fine 网络,基于得到的概率密度函数来采样更精细的点。
速度问题
- 1.训练速度,一个场景要用单卡V100 训练1-2天左右
- 2.渲染速度,一帧一分钟
要是能改进到1s 30帧,那就会对许多领域产生翻天覆地的变化!!!
Reference
[1]百度大佬看NeRF
[2] Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[C]//European Conference on Computer Vision. Springer, Cham, 2020: 405-421.
[3] Kajiya J T, Von Herzen B P. Ray tracing volume densities[J]. ACM SIGGRAPH computer graphics, 1984, 18(3): 165-174

