����BΪ����ʶ��,������ֻ������ʶ��
ժҪ(����Ҫ,��ֱ�ӿ�����ʶ�ֿ�������).
��ѧ���װ����벻ͬ�����ǰ�ش����йص���Ҫ��Ϣ����Ȼ���Դ����Ľ����ƶ��˿�ѧ������Ϣ�Զ���ȡ�Ŀ��ٷ�չ��Ȼ��,��ѧ����ͨ�����ǽṹ��PDF��ʽ�ṩ����ȻPDF�dz��ʺ��ڻ����ϱ���������Ӿ�Ԫ��,���ַ�����������״��,�Ա���ָ�����,��������PDF��ʽ���Զ�����������������ս�����г���2.5����PDF�ĵ�,��Щ����������������ҪӦ������Ҳ���ձ顣
�ӿ�ѧ�������Զ���ȡ��Ϣ��һ���ؼ���ս��,�ĵ���ͨ����������Ȼ����������,��ͼ�κͱ�����Ȼ��,��Щ����ͨ��˵�����о��Ĺؼ��������Ϣ���ܽᡣΪ��ȫ�������ѧ����,�Զ���ϵͳ�����ܹ�ʶ���ĵ��IJ���,��������Ȼ�������ݽ���Ϊ�����ɶ��ĸ�ʽ�����ǵ�ICDAR 2021��ѧ����������(ICDAR2021 SLP)ּ���ƶ��ĵ����ⷽ��Ľ�����ICDAR221-SLP����PubLayNet��PubTabNet���ݼ�,�ṩ��ʮ�����ѵ������ʾ����������A(�ĵ�����ʶ��)��,����������ܵ��ύ����˶��������Բ�ͬ����רҵ���������������B������ʶ����,top�ύ������ʶ���������ķ��������ɱ���ṹ�����ݵĺ�������������������Ľ������ʾ������ӡ����̵�����,��Ϊ�����ܵ�ʵ��Ӧ�ÿ����˿����ԡ�
1������(����Ҫ,������,����Ҫ�ٿ�)
��Яʽ�ĵ���ʽ(PDF)���ĵ��洦�ɼ�,�����ҵ���ĵ���������2.5����[12],���������ĵ���ҽ���ļ���ͬ�������ѧ���¡�PDF�����ߺ�����֪ʶ����Ҫ��Դ֮һ����ȻPDF�dz��ʺϱ��滭���ϵĻ���Ԫ��(�ַ�����������״��ͼ���),����ͬ�IJ���ϵͳ���豸������ʹ��,�������ǻ�����������ĸ�ʽ��
Ŀǰ������ĵ����ⷽ�������������ѧϰ,����Ҫ������ѵ��ʾ��������ʹ�ñ��α�����ʹ�õ�PubMed Central1�Զ������˴������ݼ���PubMed Central���������������о�Ժ/����ҽѧͼ����ṩ������ҽѧ����Ĵ���ȫ�����¼���
��������,PubMed Centralӵ��2476���ڿ��Ľ�700��ƪȫ������,��Ϊ�о�������ͬ���·����ĵ����������ṩ�˿��ܡ����ǵ����ݼ���ʹ��PubMed Central��һ���Ӽ����ɵ�,���Ӽ����ݿɹ���ҵʹ�õ�֪ʶ��������֤������
������Ϊ��������,һ����ͨ��Ҫ�������ʶ���ĵ�ҳ���еļ�����Ϣ�������ĵ�����(����A),��һ����ͨ��Ҫ����������ɱ���ͼ���HTML�汾���������(����B)��IBM Research AI���а�ϵͳ�����ռ��������������ύ����Ϣ����ϵͳ����EvalAI2��
������A��,�����߿��Է��ʳ������������Լ��Ļ�����ʵ֮�����������,���Լ���PubLayNet����ʱ������������B��,�����ڲ������ύ���ս��ǰ���췢���������������Լ���������a��������,�����յ�������78����ͬ�ŶӵĴ����������ύ��281������顣����������Ľ����ʾ,��ǰ���Ƚ����㷨��������ӡ����̵�����,��֮ǰ����Ľ������������,��Ϊ�����ܵ�ʵ��Ӧ�ÿ����˿����ԡ�
3������B��������ʶ��
�����ʽ����Ϣ�ڸ����ļ��ж����ձ顣����Ȼ�������,�����ṩ��һ���Ը����պͽṹ���ĸ�ʽ�ܽ�������ݵķ����������ṩ��һ�ָ�ʽ,�������߲��ҺͱȽ���Ϣ�����ξ���ּ���ƽ��ǽṹ�������Զ�ʶ�����о���
������IJ�������Ҫ����һ��ģ��,��ģ�Ϳ��Խ��������ݵ�ͼ��ת��Ϊ��Ӧ��HTML����,������PubMed Central 2021���е�HTML�����ʾ����֮����еġ�������������ɵ�HTML����Ӧ����ȷ�ر�ʾ���Ľṹ��ÿ����Ԫ������ݡ���Ԫ��������Ӧ���������ı���ʽ(�������塢б�塢ɾ�����ϱ���±�)��HTML��ǡ�HTML���벻��Ҫ�ؽ���������,����߿��ߡ�����ɫ�����塢�����С��������ɫ��
3.1����ع���
������������ʶ����ս,��Ҫ�ڹ����ļ�������ʶ�����(ICDAR)����֯��ICDAR 2013 �������������ڱ������ʶ��ľ���[5]��ICDAR 2013������������156�ű���,��������������ͱ���ʶ��;Ȼ��,û���ṩ��ѵ���ݡ�ICDAR 2019�������ʶ����Ϊ�������ʶ���ṩ��ѵ����֤�Ͳ�������(�ܼ�3600��)[4]���������͵��ĵ�,��ʷ��д�ͱ��ģ��,������ͼ���ʽ�ṩ�ġ�ICDAR 2019����������������:1)ȷ����������;2) ʶ����и���������ı��ṹ;3) ��û�и���������������ʶ����ṹ��ground truthֻ��������Ԫ��ı߽��,��������Ԫ�����ݡ�
���ǵ�Task B���������һ�������ս�Ե�����:ģ����Ҫ����������ͼ��,ʶ�����ṹ�ͱ���ĵ�Ԫ�����ݡ����仰˵,ģ����Ҫ�ƶϱ������ṹ�Լ�ÿ��Ҷ�ڵ�(��ͷ\�嵥Ԫ��)������(���ݡ��п�ȡ��п��)������,���Dz��ṩ��Ԫ��λ�á��ڽӹ�ϵ����/�зָ���м�ע��,��Щ����ѵ����������б���ʶ��ģ������ġ�����ֻ�ṩ����ʾ�����ս���Թ��ල�����������⽫���������߿����µ�ͼ�ṹӳ��ģ�͡�
3.2������
������ʹ����PubTabNet���ݼ�(v2.0.0)[16]��PubTabNet��������500k��ѵ��������9k����֤����,�����ṩ��ground truthHTML����,�Լ��ǿձ���Ԫ���λ�á������߿���ʹ��ѵ������ѵ�����ǵ�ģ��,��ʹ����֤���ݽ���ģ��ѡ��ͳ�����������9k+����������(��ͼ��,��ע��)�ھ������������ν���ǰ3�췢�� ���������������ύ����������һ���ϵĽ����
ʹ��TEDS(�������༭�����������)������[16]���ύ�����ݽ���������
T
E
D
S
TEDS
TEDSʹ��[11]����������༭�������������֮��������ԡ������ɾ�������ijɱ�Ϊ1����
e
d
i
t
edit
edit���ڵ�no�滻Ϊnsʱ,���no��ns����td,�����Ϊ1����no��ns����tdʱ,���no��ns���п�Ȼ��п�Ȳ�ͬ,���滻�ɱ�Ϊ1������,����ɱ���no��ns����֮��ı���
L
e
v
e
n
s
h
t
e
i
n
Levenshtein
Levenshtein������[9](��[0,1]��)�����,������֮���
T
E
D
TED
TED����Ϊ
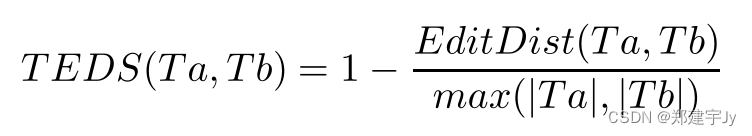
����
E
d
i
t
D
i
s
t
EditDist
EditDist��ʾ���༭����,
�O
T
�O
|T|
�OT�O ��
T
T
T �еĽڵ�����һ����������Ϸ����ı���ʶ�����ܶ���Ϊÿ��������ʶ�����ͻ�������֮���
T
E
D
S
TEDS
TEDS������ƽ��ֵ��
������Ϊ�����Ρ���ʽ��֤�ιᴩ��������,�����߿���ʹ�������ṩ�����㿪������֤���ǵĽ���ļ��Ƿ�������ǵ��ύҪ�����δӱ�����ʼ����������ǰ3�졣�������,�����߿����ύ���������Ľ��,����֤���ǵ�ģ�͡����������ν��ڱ��α��������3����С������߿����ڴ˽��ύ������������������������������ͻ�ʤ�Ŷ������������εı��־�������3.2��ʾ�˲�ͬ����B��ʹ�õIJ�ͬ���ݼ��Ĵ�С��
| Split | Size | Phase |
|---|---|---|
| Training | 500,777 | N/A |
| Development | 9,115 | N/A |
| Mini development | 20 | Format Verification Phase |
| Test | 9138 | Development |
| Final evaluation | 9064 | Final evaluation |
��3.2:����B���ݼ�ͳ��
3.3�����
��������B,������30���Ŷ��ύ��30�������,�������������Ρ�������������,ʹ��
T
E
D
S
TEDS
TEDS��������ǰʮ��ϵͳ����4��ʾ�����������������ݼ���������,��������δ���ǵĵط�,ʹ�ô�������
ǰ�ĸ�ϵͳ�������Ƶ�����,�����ǿ����˸������IJ�ͬ������ϵͳ��������ʾ,���������ڼ�����������,��Щ����ӱ���ͼ����ʶ��������,Ȼ��������ǡ���֮ǰ����Ľ�����,ʹ��ͼ�����з�����
T
E
D
S
TEDS
TEDSָ������ܸ���[17]����[17]��,�����ݼ��뱾�α����IJ��Լ����пɱ���,��Դ��PubMed Central��
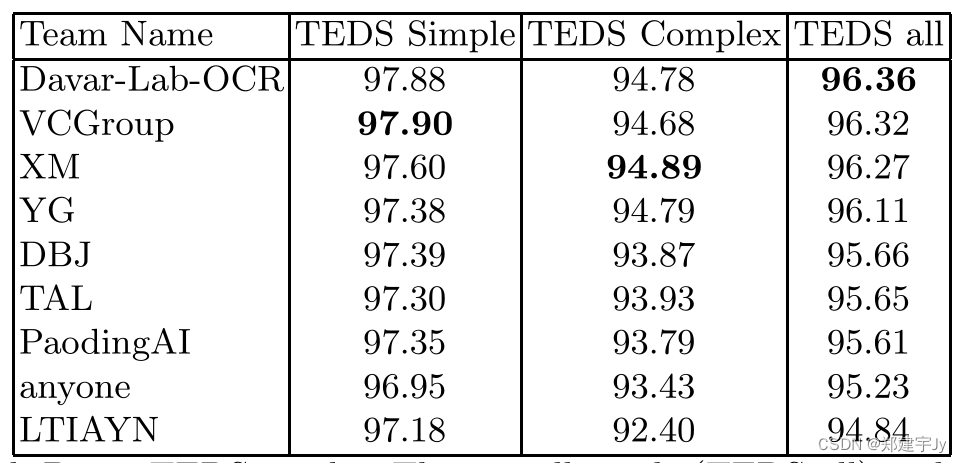
��4:������(
T
E
D
S
TEDS
TEDS all)�ֽ�Ϊ���ӵı���[16]
3.4��ϵͳ����(ֻ������һ����)
Team: Davar-Lab-OCR,�����������
Davar Lab OCR���ĺ�Դ����
����ʶ���ܰ���������Ҫ����:����Ԫ���ɺͽṹ�ƶ�
(1)����MASK R-CNN���ģ�ͽ�������Ԫ���ɡ�������˵,��ģ�;���ѵ��,����ѧϰ�� / �ж���ĵ�Ԫ���߽��,�Լ���Ӧ���ı������������롣�����������������ල,������HRNet-W48����MASK R-CNN�Ĵ�����������ÿɿ���
a
l
i
g
n
e
d
aligned
aligned
b
o
u
n
d
i
n
g
bounding
bounding
b
o
x
e
s
boxes
boxes������,���ǻ�ѵ����һ�������ı����ģ�ͺ�һ������ע����ı�ʶ��ģ�����ṩOCR��Ϣ����ֻ��ѡ��ֻ���������ı���ʵ������ʵ�֡����ǻ������˶�߶ȼ����ڵ�Ԫ��͵����ı����ģ���Ͻ�һ��������ܡ�
(2)�ڽṹ�ƶϽ�,��Ԫ�ı߽����Ը��ݶ����ص�����ˮƽ/��ֱ���ӡ�Ȼ��ͨ�����������(Maximum Clique Search)����������\����Ϣ,�ڴ˹����п��������ҵ��յ�Ԫ��
Ϊ�˴���һЩ�������,����ѵ����һ�������ģ�������˲����ڸñ����ı���
Team: VCGroup
VCGroup Github repo:
�����ǵķ���[7,10,14]��,���ǽ���������ʶ�������Ϊ�ĸ�������:����ṹʶ���ı��м�⡢�ı���ʶ��ͷ�����䡣���ǵı���ṹʶ���㷨�ǻ���MASTER���Ƶ�,MASTER��һ�ֽ�׳��ͼ���ı�ʶ���㷨��PSENet���ڼ�����ͼ���е�ÿһ���ı��������ı���ʶ��,���ǵ�ģ��Ҳ����MASTER�����,���ı�������,���ǽ�PSENet�����ı�������ṹԤ���ع��Ľṹ�������,����ʶ������ı���������䵽��Ӧ�����С���������ķ����ڿ����ζ�9115����֤������
T
E
D
S
TEDS
TEDS����Ϊ96.84%,�����������ζ�9064��������
T
E
D
S
TEDS
TEDS����Ϊ96.32%��
Team: Tomorrow Advancing Life(TAL)
TALϵͳ�������������:
(1)ͨ����ͷ��⡢�м�⡢�м�⡢��Ԫ������ı��м��5�ּ��ģ���ؽ�����ṹ��ѡ��Mask R-CNN��Ϊ��5�ּ��ģ�͵Ļ���,��Բ�ͬ�ļ���������������Ե��Ż�����ʶ��,����Ԫ�����ı��м��Ľ�����뵽CRNNģ����,�õ�ÿ����Ԫ��Ӧ��ʶ������
(2)���ṹ�Ļָ�����Ϊimg2seq���⡣Ϊ�����̽��볤��,�����ò�ͬ�������滻ÿ����Ԫ�����ݡ���Щ���������ı��м������Ȼ������ʹ��CNN��ͼ����б���,��ʹ�ñ�ѹ��ģ�ͶԱ��Ľṹ���н��롣Ȼ��,����ʹ��CRNNģ�ͻ����Ӧ���ı������ݡ�
�������ַ������Եõ������ı���ṹ������ʶ������������һ��ѡ�����,��������ַ������ŵ�,�����һ����ѵ����ս����
Team: PaodingAI, Beijing Paoding Technology Co., Ltd
�Ŷ�:����AI,���������Ƽ�����˾
����AI��ϵͳ��Ϊ������Ҫ����:�ı����⡢�ı���ʶ��ͱ���ṹʶ���ı���������MMDetection�ṩ�ļ��������rcnn r50 2xģ�ͽ���ѵ����
�ı���ʶ������SAR TFģ��ѵ�������ṹʶ�����������Լ���[13]�������ģ�͵�ʵ�֡���������ģ��֮��,���ǻ�ʹ�ù���ͼķ���ģ����������<b�Ϳհ��ַ������ǵ�ϵͳ���Ƕ˵���ģ��,Ҳû��ʹ�ü��ɷ�����
Team: Kaen Context, Kakao Enterprise
��˾λ�ں������ܵ�������
Ϊ����Ч�ؽ����ʶ������,����ʹ����12���������������transformer�ṹ[8]��
������:����ʹ��RGBͼ��(������������)��Ϊ��������,�ϲ���HTML��������Ŀ���ı����С����ǽ�һ�ű���ͼ������Ϊһϵ����״ƽ̹����Ƭ(N,8?8?3),����8��ÿ��ͼ����Ƭ�Ŀ��Ⱥ߶�,N����Ƭ��������Ȼ��,����������ͶӰ�㽫ͼ������ӳ�䵽 512 ά��Ŀ���ı�����ͨ��Ƕ���ת��Ϊ 512 άǶ��,��������ͶӰͼ�����е�ĩβ�����,���ǽ���ͬ��λ�ñ������ӵ��ı���ͼ��������,��ʹ���ǵ�ģ���ܹ��������ǡ�
ѵ��:��ƴ�Ӻ��ͼ���ı�������Ϊģ�͵�����,�ڽ�ʦǿ���㷨��ͨ����������ʧ��ģ�ͽ���ѵ����
����:���ǵ�ģ�͵����ͨ��beam�������в���(beam=32)��
�����:
Antonacopoulos, A., Bridson, D., Papadopoulos, C., Pletschacher, S.: A realistic dataset for performance evaluation of document layout analysis. In: 2009 10th International Conference on Document Analysis and Recognition. pp. 296�C300.IEEE (2009)
Clausner, C., Antonacopoulos, A., Pletschacher, S.: Icdar2017 competition on recognition of documents with complex layouts-rdcl2017.In: 2017 14th IAPR In- ternational Conference on Document Analysis and Recognition (ICDAR). vol. 1, pp. 1404�C1410. IEEE (2017)
Clausner, C., Papadopoulos, C., Pletschacher, S., Antonacopoulos, A.: The enp image and ground truth dataset of historical newspapers.In: 2015 13th International Conference on Document Analysis andRecognition (ICDAR). pp. 931�C935.IEEE (2015)
Gao, L., Huang, Y., Li, Y., Yan, Q., Fang, Y., Dejean, H., Kleber, F., Lang, E.M.:ICDAR 2019 competition on table detection and recognition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1510�C1515. IEEE (Sep 2019).https://doi.org/10.1109/ICDAR.2019.00166
G�� obel, M., Hassan, T., Oro, E., Orsi, G.: ICDAR 2013 table competition. In: 201312th International Conference on Document Analysis and Recognition. pp. 1449�C1453. IEEE (2013)
Grygoriev, A., Degtyarenko, I., Deriuga, I., Polotskyi, S., Melnyk, V., Zakharchuk,D., Radyvonenko, O.: HCRNN: A novel architecture for fast online handwrittenstroke classification. In: Proc. of Int. Conf.on Document Analysis and Recognition(2021)
He, Y., Qi, X., Ye, J., Gao, P., Chen, Y., Li, B., Tang, X., Xiao, R.: Pingan- vcgroup��s solution for icdar 2021 competition on scientific table image recognitionto latex. arXiv (2021)
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are rnns: Fastautoregressive transformers with linear attention. In:International Conference onMachine Learning. pp. 5156�C5165. PMLR(2020)
Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, andreversals. In: Soviet physics doklady. vol. 10, pp.707�C710. Soviet Union (1966)
Lu, N., Yu, W., Qi, X., Chen, Y., Gong, P., Xiao, R., Bai, X.: Master: Multi-aspectnon-local network for scene text recognition.Pattern Recognition (2021)
Pawlik, M., Augsten, N.: Tree edit distance: Robust and memory-efficient. Infor-mation Systems 56, 157�C173 (2016)
Staar, P.W., Dolfi, M., Auer, C., Bekas, C.: Corpus conversion service: A machinelearning platform to ingest documents at scale. In:Proceedings of the 24th ACM SIGKDD International Conference onKnowledge Discovery & Data Mining. pp.774�C782 (2018)ICDAR 2021Competition on Scientific Literature Parsing 13
Tensmeyer, C., Morariu, V.I., Price, B., Cohen, S., Martinez, T.: Deep splittingand merging for table structure decomposition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR).pp. 114�C121. IEEE (2019)
Ye, J., Qi, X., He, Y., Chen, Y., Gu, D., Gao, P., Xiao, R.: Pingan-vcgroup��s solution for icdar 2021 competition on scientific literature parsing task b: Table recognition to html. arXiv (2021)
Zheng, X., Burdick, D., Popa, L., Zhong, X., Wang, N.X.R.: Global table extrac-tor (gte): A framework for joint table identification and cell structure recognition using visual context. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp.697�C706 (2021)
Zhong, X., ShafieiBavani, E., Yepes, A.J.: Image-based table recognition: data,model, and evaluation. arXiv preprint arXiv:1911.10683 (2019)
Zhong, X., Tang, J., Yepes, A.J.: Publaynet: largest dataset ever for document lay-out analysis. In: 2019 International Conference on Document Analysis and Recog-nition (ICDAR). pp. 1015�C1022. IEEE (2019)

