话不多说,上图
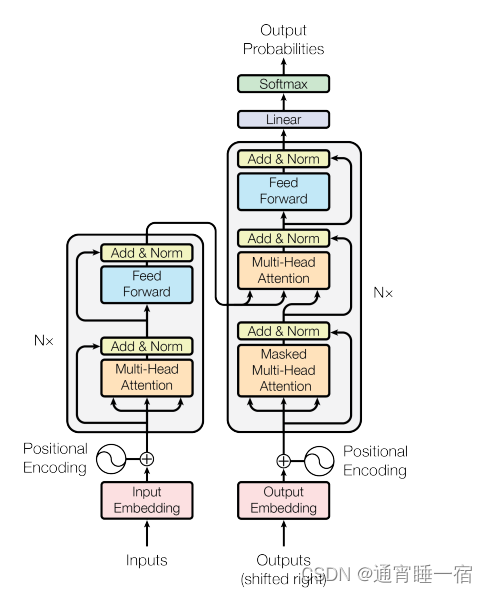
那么如何用pytorch搭建一个自己的Transformer并且用到NMT上呢
实现思路:
首先是Encoder层,这个层由多个EncoderBLock组成,
每个block为:Attention + residual + LN + FC + residual + LN
最后得到一个 batch_size,in_seq_len,embedding_dim的矩阵(和初始输入一样)
然后是Decoder层,这个层我们也可以理解为多个DecoderBlock组成,
每个block为:Attention + residual + LN + Attention + residual + LN + FC + residual + LN
因为由于我们做训练的时候,我们给的output是整句话,但是做预测的时候,模型要一个字一个字输出,所以Decoder的Attention存在Mask,所以我们对每个输入都要得到一个Mask矩阵,decoder的mask是为了不能看到未来,encoder的mask是为了去掉pad与单词的联系
那么最后我们也可以得到一个 batch_size,out_seq_len,embedding的矩阵
最后连接一个FC层(embedding,tgt_vocab_size)和softmax,我们就可以得到每一个目标字(词)的概率值,最后计算一下交叉熵损失,值得说的是,比如我们的翻译句子为:你好
那么我们的output应该为:index(BOS) index(你) index(好),
那么算损失的时候我们的目标为:index(你) index(好) index(EOS)
attention原理就不再说明了,相信各位也有一定基础,网上也有很精简的解释
最后给出结果,可能是分词不够精确吧,英文我用的是字母为单位的,中文我用的单个字做单位,数据也是比较少,只用了5000句话做训练(有好的GPU可以试一下用大一点的数据集),训练了2000轮,所以我感觉我现在训练的模型只是将句子背下来,没有创新能力,用单词作为单位可能会好一点(果然学深度学习确实很吃配置啊!)

上代码
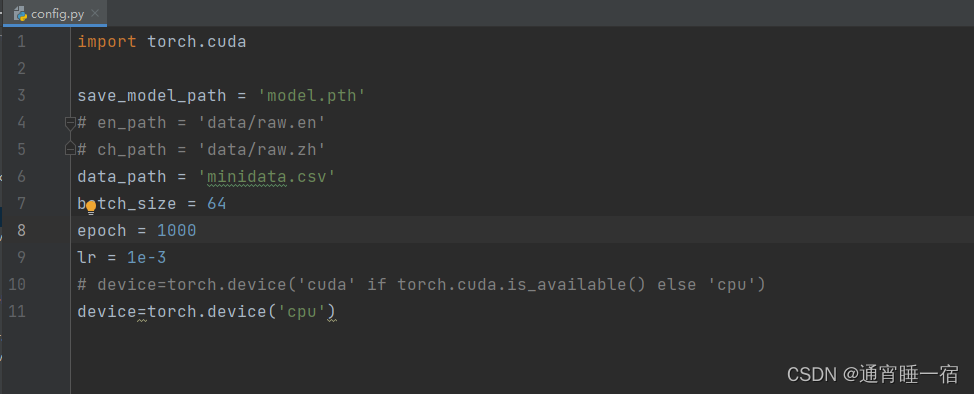
对了如果要训练记得把config的device重新转为cuda就行

