欢迎到我的个人博客看原文
论文阅读06――《CaEGCN: Cross-Attention Fusion based Enhanced Graph Convolutional Network for Clustering》
论文阅读06――《CaEGCN: Cross-Attention Fusion based Enhanced Graph Convolutional Network for Clustering》
作者:Guangyu Huo, Yong Zhang, Junbin Gao, Boyue Wang, Yongli Hu, Baocai Yin
发表时间:2021年1月
论文地址:https://arxiv.org/pdf/2101.06883.pdf

目录
Ideas:
- 提出一种基于端到端的交叉注意力融合的深度聚类框架,其中交叉注意力融合模块创造性地将图卷积自编码器模块和自编码器模块多层级连起来
- 提出一个交叉注意力融合模块,将注意力权重分配给融合的异构表示
- 提出图自编码器同时重构数据之间的内容和关系
其实,从这几篇文论来看,都在围绕内容和结构两个方面进行创新,考虑内容的地方是否还考虑了结构?考虑结构的地方是否考虑了内容?两种数据融合时的权重指定是经验值还是注意力机制?最后就是自监督训练上,通过增加不同的损失函数达到聚类的目的,也就有了自监督、双重自监督、三重自监督等等。
Model:
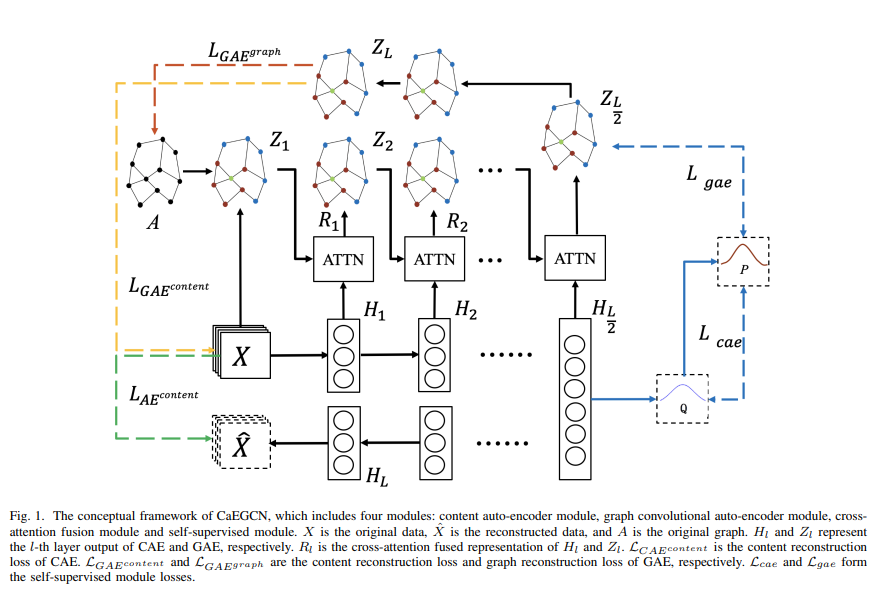
最近读的这几篇文章所提出的模型结构上都是大同小异,这一篇也不例外。下半部分是一个自编码器结构,上半部分是一个图自编码器结构,中间通过一个交叉注意力融合模块进行衔接,通过自监督进行训练。同样,自编码器和图自编码器就不再详细介绍,之前的文章中有。主要介绍图自编码器的两种损失函数以及交叉注意融合模块。
交叉注意力融合模块
交叉注意力融合机制具有全局学习能力和良好的并行性,可以在抑制无用噪声的同时,进一步突出融合表示中的关键信息。
交叉注意力融合机制定义如下:

我这里其实不太理解,公式5应该是一个自注意力机制的公式,QKV都是Y。而Y中又包含手动指定的参数γ,那注意力机制的意义何在?如果有理解的小伙伴欢迎在评论区留言。

这里公式7使用的应该是点积模型,然后使用softmax计算权重,最后输出特征表示R。作者也提到了多头注意力机制。

没看文章前,我以为作者是通过注意力机制,自动学习图自编码器表示Z和自编码器表示H的权重,但是看了文章以后,不太清楚这个注意力机制起到了什么作用,还有待继续研究。
图自编码器
该部分作者提到两种重构损失,分别是邻接矩阵重构损失和特征的重构损失。


最终的目标函数为
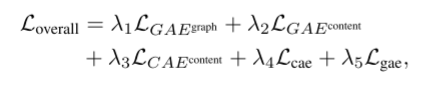
文章没有给出伪代码,但是我在GitHub上找到了作者发布的源码:
https://github.com/huogy/CaEGCN

