数据分析之python数据计算方法上篇(math|numpy)_Backup and share的博客-CSDN博客
本文重点介绍pandas,math和numpy参见上篇>
目录
一、简介与创建
Pandas 是 python 的一个
数据分析包
,属于PyData项目的一部分。
主要数据结构是 Series (一维数据)与 DataFrame(二维数据)
Series是一种类似于一维数组的对象
,
包含一列数据及与其关联的一列数据标签,数据标签即为数据的序列。
DataFrame 是一个表格化的数据结构
,它同时拥有行序号与列序号。
Series 构造方法:pandas.Series( data, index,
name, dtype, copy)
DataFrame 构造方法:pandas.DataFrame( data, index,
columns, dtype, copy)
创建一个 Series
import pandas as pd
s1 = pd.Series([1,3,5,7,6,8])
s1

创建一个 Series,指定索引和列名
import pandas as pd
s2 = pd.Series([1,3,5,7,6,8], index=['a', 'b', 'c' ,'d', 'e', 'f'], name='col')
s2

创建一个?DataFrame
import pandas as pd
df1 = pd.DataFrame([[1, 2], [3, 4]])
df1

创建一个 DataFrame,指定列名
data=[[1,2,3,4,5],[6,7,8,9,0]]
df2 = pd.DataFrame(data, columns=['col1','col2','col3','col4','col5'])?
df2

二、基础查询操作
df1.shape #获取行列数 (2, 2)
df1.info() #查看数据信息【列名,记录数,数据类型】
df1.describe() #查看数值数据的情况【计数,平均,标准差,最大,最小,分位数】
df1.head() #返回前5行
df1.head(n) #返回前n行
df1.tail() #返回后5行
df1.colname.value_counts() #查看数据中colname列对应值计数分布
三、索引与切片
Series切片
s1[:4] #显示0-3
s1[4:] #显示4-end
s1[4:6] #显示4-5
s1[:] #显示begin-end
s1 #显示begin-end
DataFrame创建行索引并指定列名
df1.index = ['row1', 'row2'] #创建行索引
df1.columns = ['col1', 'col2'] #列重命名

DataFrame获取行数据
标签索引方式:
df1[
df1.index == 'row2'] # 获取索引等于row2的行
df1.
loc['row1'] #获取行索引row1对应的行,返回series
df1.loc[['row1', 'row2']] #获取两行数据,返回dataframe
位置索引方式:
df1[i:j] #获取位置索引[i,j)范围内的行
df1.
iloc[i] #获取第i行数据,返回series
df1.iloc[[i, j]] #获取第i行,j行数据,返回dataframe
DataFrame获取列数据
df1['col1'] #选取col1列数据
df1.col1
#选取col1列数据
df1[['col1','col2']]
#获取多列数据
DataFrame获取多行多列数据
data = [[1,2,3,4,5], [11,22,33,44,55], [111,222,333,444,555], [1111,2222,3333,4444,5555]]
df4 = pd.DataFrame(data, index=['row1', 'row2', 'row3', 'row4'], columns=['col1', 'col2', 'col3', 'col4', 'col5'])

df4['col1']['row2'] #先列后行
df4['col1'][0:2] #获取col1的前两行
df4.loc['row1', 'col2'] #借助loc、iloc,先行后列
df4.loc[['row1','row3'],['col1','col3']] # loc获取多行多列
df4.iloc[0, 1] #借助loc、iloc,先行后列
df4.iloc[1:3, 3:5] #iloc获取多行多列
注:
df.loc[x, y]
是一个非常强大的数据选择函数,其中
x代表行,y代表列
,
行和列都支持条件表达式
,也支持类似列表那样的切片(如果要用位置索引,需要用
df.iloc[]
)
DataFrame将指定列创建为索引/还原索引
df5 = df4.
set_index('col5') #将col5设置为索引,并赋值给df5。
df4不变
df5
df4.
set_index('col5',
inplace=True) #将col5设置为索引并
在df4上生效
df4

df4_new = df4.
reset_index() #还原索引,并赋值给df4_new。
df4不变
df4_new
四、排序、分组、合并
按索引排序
df4.
sort_index() #对行索引进行字典排序,默认升序【Series同】
df4.sort_index(ascending=False) #对行索引进行字典排序,降序
df4.sort_index(axis=1, ascending=False) #对列索引进行字典排序,降序
# axis=0 匹配DataFrame的行索引,默认
# axis=1 匹配DataFrame的列索引
按值排序
df4.
sort_values(by = 'col1', ascending=False) # 对列col1进行降序
df4.sort_values(by = ['col1', 'col2']) # 对列col1、col2进行升序排序
df4.sort_values(by = ['col1', 'col2'], ascending = [True, False]) # 对列col1、col2分别升序和降序
groupby分组
df4.groupby('col4').sum() #分组求和
df4.groupby('col4').mean() #分组求均值
df4.
groupby('col4').
apply(def1) #分组并应用def1函数处理
merge合并
pd.merge
(df1, df2, on='key', how='outer') #merge合并DateFrame,默认做"inner"连接,还有left,right,outer(取并)
import numpy as np
import pandas as pd
data1 = np.arange(12).reshape(3,4)
data2 = np.arange(4).reshape(2,2)
df1 = pd.DataFrame(data1, columns=['col1', 'col2', 'col3', 'col4'])
df2 = pd.DataFrame(data2, columns=['col1', 'col2'])

pd.merge(df1, df2, on='col1') # col1内连接

pd.merge(df1, df2, on='col1', how='left') # col1左连接

pd.merge(df1, df2, left_on='col3', right_on='col1', how='left') # df1 col3左连接 df2 col1

concat合并
pd.concat([df1, df2], sort=True) #默认行合并,sort对列名称排序
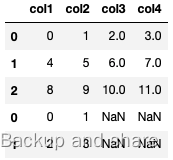
pd.concat([df1, df2], axis=1) #列合并

pd.concat([df1, df2], axis=1, join='inner') #列合并,合并索引相同行,join参数默认outer
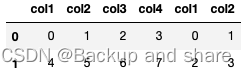
x = pd.concat([df1,df2,df3,df4,df5],axis=1) #合并多个数据集
append合并
df1.
append(df2,sort=True) #?pd.concat([df1, df2], sort=True)结果相同

join合并
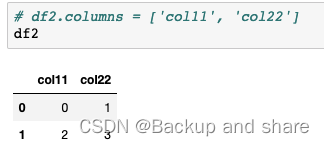
df1.
join
(df2, on='col1', how='left') #右表的索引和左表的on字段关联

五、数值运算、数据清洗
基础统计
df1.count() #计数
df1.
sum() #求和
df1.min() #最小值
df1.max() #最大值
df1.
mean() #平均值
df1.median() #中位数
df1.quantile(q=0.9) #9分位
df1.std() #标准差
df1.var() #方差
累计统计
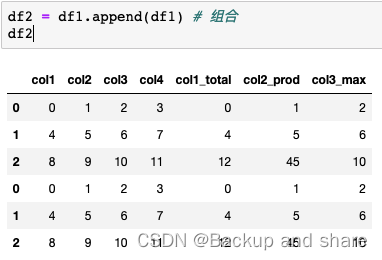
df1['col1_total']=df1['col1'].
cumsum() #增加列,对col1累加
df1['col2_prod']=df1['col2'].cumprod() #增加列col2_prod,对col2累积

数据清洗
df2.col1.
drop_duplicates() #取出col1列,删除重复值
df2.col1.isnull() #是否缺失
df2.col1.
dropna() #删除缺失值
df2.col1.fillna(0) #缺失值填充,ffill()前向填充,bfill()后向填充
df2.col1.astype(float) #类型转换
df3 = df2.
drop(['col3', 'col4'], axis=1) #去除无关列数据
df['just_date'] = df['dates']
.dt.date #时间只保留日期部分
data=data.replace(to_replace='?',value=np.nan) #将缺失值替换成NAN,(原始数据集缺失值用的是问号)
六、文件读写
1-将表格型文件数据读取为DataFrame对象
import pandas as pd
pd.read_csv('./data.txt') #默认分隔符为逗号; #默认第一行为列名
pd.read_csv('./data.csv', names=['col1', 'col2']) #names指定列名
pd.read_table('./data.csv', sep=',') #默认分隔符为制表符("\t");sep指定分隔符
pd.read_excel('./data.xlsx', sheet_name="sheet1")
2-将DataFrame对象写入文件
df.to_csv('outfile.csv')
df.to_excel('outfile.xlsx', index=False) #index指定无索引
参考:

