Backward Difference Coding反向差分编码
用于编码类别变量的向后差对比编码。
原理
- 将分类变量的一个级别的因变量的平均值与前一个相邻级别的因变量的平均值进行比较。 第一次比较将级别 2 的因变量的平均值与级别 1的因变量的平均值 进行比较。第二个比较将级别 3 的因变量平均值与 级别2 的因变量平均值比较,第三个比较 将级别4的因变量平均值与 级别3的因变量平均值比较… …依此类推。
| level of variable | level 2 vs. level 1 | level 3 vs. level 2 | level 4 vs. level 3 |
|---|---|---|---|
| 1 | -(k-1)/k | -(k-2)/k | -(k-3)/k |
| 2 | 1/k | -(k-2)/k | -(k-3)/k |
| 3 | 1/k | 2/k | -(k-3)/k |
| 4 | 1/k | 2/k | 3/k |
ce.BackwardDifferenceEncoder(verbose=0, cols=None, mapping=None,
drop_invariant=False,
return_df=True, handle_unknown='value',
handle_missing='value')
参数
- cols
要编码的列的列表,如果为 None,则将对所有字符串列进行编码。 - drop_invariant
是否删除方差为0的列 - return_df
是否转换后返回 pandas DataFrame(否则它将是一个 numpy 数组)。
方法
- fit(X, y=None)
- fit_transform(X, y=None)
- transform(X)
import category_encoders as ce
en = ce.BackwardDifferenceEncoder(cols=['lotid'], return_df=True)
res = en.fit_transform(en_data)
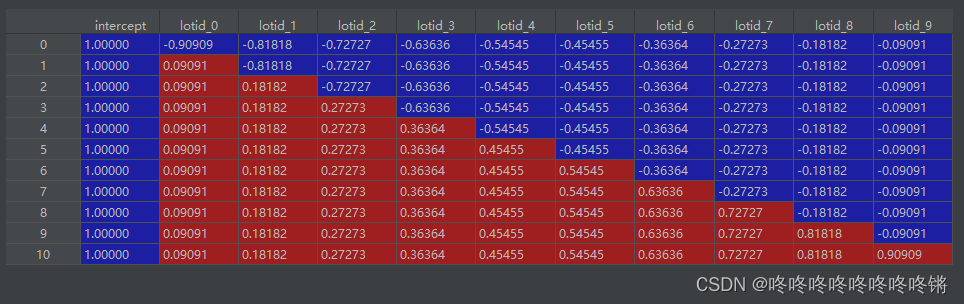
原数据:

转换后:
BaseN
Base-N 编码器将类别编码为其 Base-N 表示形式的数组。以 1 为基数等效于单热编码(不是真正的以 1 为基数,但很有用),以 2 为基数等效于二进制编码。N=实际类别的数量等效于普通序数编码。
Binary二值编码
分类变量的二进制编码,类似于 onehot,但将类别存储为二进制位字符串。
CatBoost Encoder
分类特征的CatBoost编码。
CatBoost Encoder是一个基于目标的分类编码器。它是一个监督编码器,根据目标值对分类列进行编码。它支持二项式和连续目标。
- 训练数据必须随机排列。
- 使用类似于时间序列数据验证的原理。目标统计值依赖于观察到的历史,即当前特征的目标概率仅从它之前的行(观察值)计算。
Leave One Out
与目标编码非常相似,但在计算水平的均值目标时会排除当前行的目标,以减少异常值的影响。

