TF-IDF模型:基于结巴分词和wordcloud进行疫情文本数据分析
文章目录
最近做了新冠疫情中国政策的文本数据分析,下面来介绍一下相关知识进行总结与巩固,也希望帮助更多的人。
一、Tf-idf:关键词提取
停用词:停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词
某个词比较少见,但在文章中多次出现,进而反映文章特行,那么它就是关键词
1、词频TF
词 频 ( T F ) = 某 个 词 在 文 章 中 的 出 现 次 数 该 文 出 现 词 的 总 数 \scriptsize词频(TF) = \frac{某个词在文章中的出现次数}{该文出现词的总数} 词频(TF)=该文出现词的总数某个词在文章中的出现次数?
2、逆文档频率IDF

IDF越大,词频越大,重要程度越高
TF-IDF=词频*逆文档频率
二、结巴分词
jieba是Python 中文分词组件库,内置了许多方法帮助我们去使用。
pip install jieba
下面是结巴分词演示
1、首先导入jieba分词库
import pandas as pd
import jieba
import os
import jieba.analyse
2、获取文件夹下的所有文件名
有感兴趣想做的,可以找一些txt文件数据放入文件夹内(数据量越大越好)
content_S =[]
contents = [] # 存放txt文件每行的内容
path1 = r"policy_2020"
files_1 = os.listdir(path1) # 得到path1文件夹下所有文件的名称
# print(files_1)
3、遍历每一个文件并使用结巴进行分词
这里我用了非常低级的写法,这样使我的时间复杂度过大,当数据量很大时不建议这样写,学习使用还是可以的,大佬们也可以提一些宝贵建议。由于数据原因我用了5小时才跑完这部分内容(2144个txt文件)。
for i in range(len(files_1)):
new_path = path1 + '\\'+ files_1[i]
contents.append(new_path)
# print(contents)
for j in range(len(contents)):
with open(contents[j], 'r', encoding='utf-8') as f:
myString = f.read().replace(' ','').replace('\n','')
# 取关键词前五
tags = jieba.analyse.extract_tags(myString,topK=5)
# print(tags)
content_S.append(tags)
print("完成",i)
4、读取分好词的conten_S和停用词
df_content=pd.DataFrame({'content_S':content_S})
df_content.head()
# 停用词
stopwords = pd.read_csv("baidu_stopwords.txt",index_col=False,sep="\t",quoting=2,names=['stopword'],encoding='utf-8')
stopwords.head
5、停用词判断逻辑
def drop_stopwords(contents,stopwords):
contents_clean=[]
all_words=[]
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
cons = df_content.content_S.values.tolist()
stopwords=stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(cons,stopwords)
6、查看经过停用词处理后的数据
df_content=pd.DataFrame({'content_clean':contents_clean})
df_content.head()
#关键词
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()
#查看经过结巴分词后的所有关键词词频
words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg([("count","count")])
words_count=words_count.reset_index().sort_values(by=["count"],ascending=False)
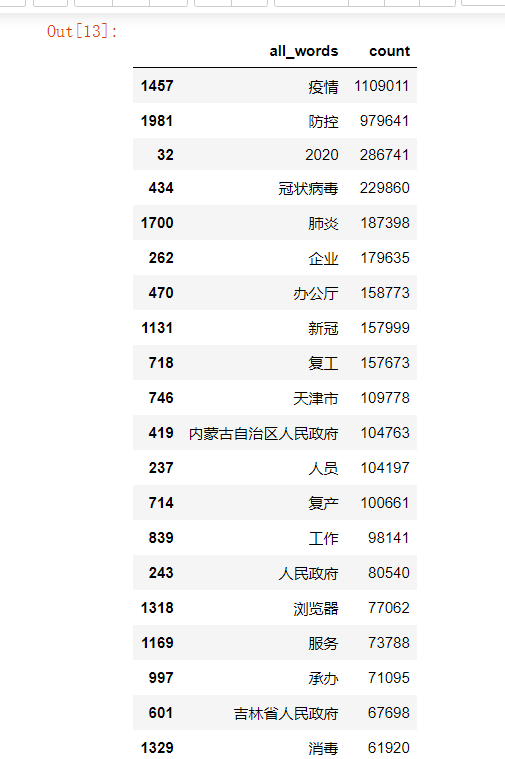
words_count.head(20)
三、绘制词云
使用wordcloud库可以进行词云绘制,将高频词可视化展示出来
首先需要导入 pip install wordcloud
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0,5.0)
#设置字体和背景颜色及最大文字大小,没有的话可以随便找个字体文件
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
运行结果如下

0).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)
运行结果如下
[外链图片转存中...(img-w6Q74NUD-1652364226383)]

