ЈC0519НёЬь0430Ц№ДВЕФ,дчЩЯПЊЪМПДcs224n,ИаОѕРЯЪІКУПЩАЎ!
ЯждкПЊЪМЖСТлЮФРВ!
вЛЁЂUnicorn
ЁЊ0558ИаОѕЛЙЪЧгаДДаТЕФ!ЕЋЪЧвЛЪБМфЫЕВЛЩЯРД?ПЩФмЪЧЪБМфгыЙиЯЕдкЫндДЭМжаЕФзлКЯ???ЯШИЩЗЙ!
ЈC0621ГдЗЙЕФЪБКђПДСЫcs224n,НВЕФКмЯИЁЃжївЊНВСЫword2vec,ОпЬхЪЧШчКЮШЅзіword2vecетМўЪТЁЃ
1ЁЂгУжааФДЪдЄВтжмЮЇДЪ
2ЁЂгУСНЬзЯђСП,ЗжБ№БэЪОетИіДЪзїЮЊжааФДЪКЭзїЮЊжмЮЇДЪЪБЕФЯђСПБэЪО
3ЁЂгХЛЏФПБъ:дЄВтзМШЗ----ЁЗЪ§бЇБэДя:P(дЄВтЕФжмЮЇДЪ|вбжЊЕФжааФДЪ)=АбЫљгаДЪЖМЕБзіжааФДЪетбљзівЛБщЁОСНДЪжЎМфЕФЯрЫЦЖШ/(зжЕфжаЫљгаДЪКЭвбжЊжааФДЪЕФЯрЫЦЖШЧѓКЭ)ЁП
етРягУСНДЪжЎМфЕФЯрЫЦЖШНќЫЦЦфБЛдЄВтЕФПЩФмад,вВОЭЪЧШЯЮЊ,ШчЙћСНДЪдНЯрНќ,ОЭдНПЩФмБЛдЄВтГіЁЃ
ЮвУЧЯЃЭћгХЛЏФПБъдНДѓдНКУ,ЭЈЙ§вЛЯЕСаБфЛЛ(МгИККХ,Г§вдећИізжЕфДѓаЁ),БфГЩзюаЁЛЏЮЪЬт,гУЬнЖШЯТНЕНтОі(ПДетвтЫМ,РЯЪІКУЯёЯыПЊЪМНВЬнЖШЯТНЕСЫ,КУЯИАЁ)
----0627МЬајЖСТлЮФ,НёЬьЖСЭъbackgroundОЭШЅпЃДњТы!
ЁЊ0720ПДЕНВЛЩйзЈвЕДЪЛу,КУРЇ,ЯыХПвЛЛсЁЃЁЃЁЃ
ЁЊ0746ИДЯАвЛЯТзђЬьПђМмЕФapi,ОЭШЅЪеЪАЫоЩсСЫ!
зЂвт:
1ЁЂReLUЕФДѓаЁаД
2ЁЂnormalЪЧдкtorch.initжаЕФ
3\dropoutЕФЪжЫККЭМђНрЪЕЯж
(1)МђНрЪЕЯж

(2)ЪжЫК
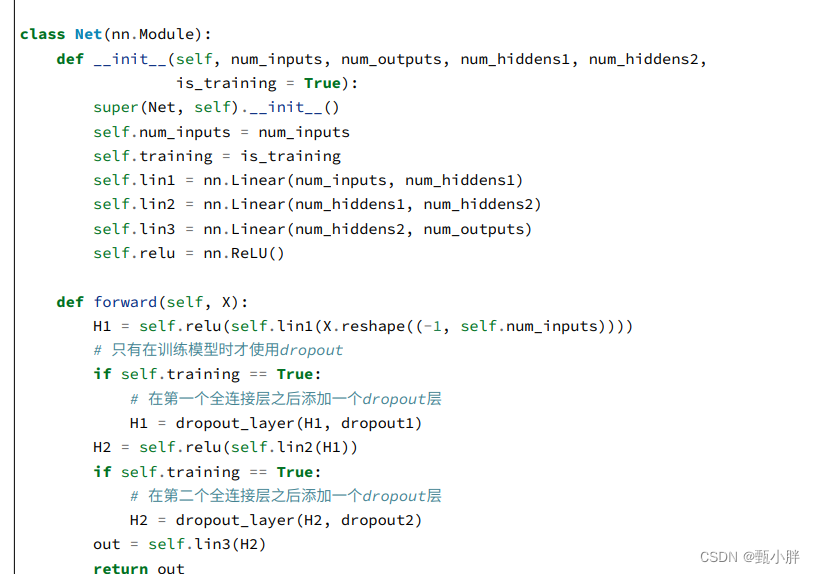
етРяЕФМђНржївЊЪЧЫЕ,дкЪЙгУdropoutЩЯЁЃ
жЎЫљвдЪжЫКЪБУЛгажБНгЪЙгУnn.Sequential()ЪЧвђЮЊашвЊХаЖЯЪЧдкбЕСЗЛЙЪЧдкВтЪд,дкВтЪдЪБВЛгУdropout,ЫљвдВЛФмжБНггУsequential,ашвЊМгШыХаЖЯТпМ,гУМЬГаnn.ModuleРДИќМгСщЛюЕиЖЈвхЭјТчЁЃЁЃ
ПђМмАяЮвУЧздЖЏдкdropoutВу(nn.Dropout)ЭъГЩСЫЖдгкбЕСЗКЭВтЪдЕФХаЖЯ,ЪЙЮвУЧжБНгФмНЋЦфаДдкnn.SequentialжаЁЃ
4\зЂвтoptimКЭinitЕФЮЛжУ
torch.optim.SGD()
nn.init.normal_
5\ИаОѕе§дђЛЏетПщweight-decayКЭdropoutРэНтЕФВЛЪЧЬиБ№КУ,ПЩвддйШЅПДЯТЪгЦЕ,жСЩйНтОіСНИівЛЦ№гУ,аЇЙћЛсВЛЛсИќКУетИіЮЪЬтЁЃ
ЁЊ1055ШЅИЩЗЙ!
ЁЊ1507ЭЛЗЂСЫКмЖрЪТ,ЯждкВХФмЛиРДбЇЯАЁЃ
жаЮчГдЗЙЕФЪБКђгжПДСЫЯТdropout,ЦфЪЕвВЪЧвЛжже§дђ(дМЪ§wЕФ),ЕЋЪЧУЛгаБЛжЄУїРВЁЃВЛЙ§зюЯШЬсГіЕФЪБКђЪЧЯызХдіМгЪ§ОнЕФШХЖЏ,дкдДЭЗНјааdropoutвбОБЛжЄУїРВ!
ЁЊ1607ВЛЯыбЇСЫ,ЯыШЅХмВНСЫЁЃЁЃЁЃ
----1900ИаОѕгаЙпад,ЛЙЪЧЛиРДзіЬтПДЗвыСЫ,ЗХЫЩВЛЯТРДАЁЁЃ
ЁЊ1928НёЬьКмПь,ШЅПДЯТЗвы,гІИУЛЙгаЪБМфЧУpytorch
ЁЊ2002ПДЭъЗвыСЫЖьЖьЖьгЬдЅЪЧанЯЂвЛЯТЛЙЪЧПДpytorch
ЁЊ2019ПДСЫвЛаЁЛсcs224n,ЫфШЛФмЬ§ЖЎ,ЕЋЛЙЪЧЯыЯШПДРюКъвуРЯЪІЕФПЮГЬдйРДЬ§етИі,ИаОѕРэНтЛсИќЩюПЬЁЃ
----2032ШЗЪЕВЛЯыЫЂЪгЦЕСЫЖьЖьЖьШЅзіКЫЫсАШЫГБуПДПДухухЁЃЭэЩЯгаЪБМфЛиРДЧУДњТыЁЃ
ЈC2123ЛиРДСЫ,МЬајаДpytorchСЫ!
1ЁЂsliceЪЙгУ
sliceЪЧЧаЦЌЖдЯѓ
https://www.runoob.com/python/python-func-slice.html
2ЁЂpd.SeriesгУЗЈ
ЁЊ2229ДњТыЧУЭъСЫ,ИаОѕОЁЙмЪЧКмМђЕЅЕФБШШќ,ЪЕМЪзіЦ№РДЖМетУДИДдг,здМКЖМВЛвЛЖЈФмаДУїАзЁЃУїЬьПДЯТЪЃЯТЕФаЁНсВПЗж,ШЛКѓздМКЪжЫКвЛБщећИіСїГЬЁЃ
ЯШШЅЫЏСЫ!ЭэАВ

