Abstract
风格建模是表达性语音合成中的一个重要问题。在现有的无监督方法中,样式编码器从参考音频中提取潜在的表示作为样式信息。然而,从风格编码器中提取的风格信息会纠缠一些内容信息,这将导致与实际输入内容冲突,从而影响合成语音,也就是风格泄露问题。在本研究中,我们提出通过将文本到语音(TTS)模型和自动语音识别(ASR)模型与共享层网络相结合进行联合训练,并使用ASR对抗性训练来消除风格信息中的内容信息,从而缓解纠缠问题。同时,我们提出了一种自适应对抗权重学习策略来防止模型崩溃。使用单词错误率(WER)进行客观评估表明,我们的方法可以有效地缓解风格和内容信息之间的纠缠(effectively alleviate the entanglement between style and content information)。主观评价表明,与基线模型相比,该方法提高了合成语音的质量,增强了风格转换能力。
Introduction
语音的自然度已经接近真实人类[1tacotron,2tacotron2,3Deepvoice3,4Fastspeech2,5 TacoLPCNet]。然而,现有的大多数方法合成的语音表达能力较差。目前,越来越多的应用需要高表达性的合成语音,表达性语音合成的研究前景广阔。
近年来,随着深度神经网络的发展,端到端语音合成取得了快速的进展,语音的自然度已经接近真实的人[1,2,3,4,5]。然而,现有的合成语音方法大多表达能力较差。听众常常因为没有情感共鸣而感到不满和无聊。目前,越来越多的应用需要高表达的合成语音,如有声读物、新闻阅读器和会话助手。随着人机交互的日益重要,表达性语音合成的研究前景十分广阔
最近关于表达性语音合成的研究是以无监督的方式从参考音频中学习韵律和整体风格的潜在表征,然后将这种潜在表征与文本向量相结合,以实现说话风格的转换和控制[6GST,7VAE解耦,8,9文本出发预测,10三联拼接,11VAE,12VAE,13VQ量化]。这些作品[6,10]旨在使合成音频的风格模仿参考音频的风格。介绍一下参考编码器固有的内容泄露问题。具体来说,风格嵌入是从风格编码器中提取出来的,这种风格嵌入隐含着节奏、持续时间、音调、能量等声学信息。但是,风格嵌入也会纠缠一些内容信息,从而导致合成语音质量的下降。在模型训练阶段,输入文本内容与参考音频内容相同,这导致样式编码器对参考音频中的一些内容信息进行编码。但在推理阶段,当输入文本内容与参考音频内容不同时,解码器将从风格嵌入中获取内容信息,这将与实际输入文本信息冲突。因此,生成的语音会受到影响,并且会出现错误单词、遗漏单词和模糊单词的问题。这种现象被称为内容泄漏。因此,内容泄漏问题对合成语音质量有显著的负面影响。
在最近的研究中,有很多研究方法对风格信息和内容信息进行了梳理[14,15,16,17]。
第一种方法是增加模型训练的辅助任务。在工作[15]中,作者在模型训练中增加了ASR指导任务。他们使用未配对的输入文本和参考语音对TTS模型进行训练,使用预先训练的端到端ASR模型的错误率作为TTS模型的附加学习目标,并阻止参考编码器对任何文本信息进行编码。
第二种方法是采用对抗性训练。在工作[14]中,作者最小化了风格和内容之间的互信息。在工作[16]中,作者采用了一种成对的训练程序来强制模型从一个文本映射到两个不同的参考音频。他们通过引入重构损失和风格损失来实现风格与其他因素的解纠缠。第三种方法是利用信息瓶颈。在工作[17]中,通过向下采样和向上采样进行韵律嵌入,迫使模型关注风格信息。
受辅助ASR任务和对抗性训练公式的启发,我们提出将ASR任务与对抗性训练的思想相结合,以防止样式编码器对内容信息进行编码,从而消除样式嵌入中的内容信息。我们的TTS模型通过添加样式编码器和共享层扩展了Tacotron[1]模型。本文的贡献总结如下
1.我们使用共享层将TTS和ASR任务集成到一个网络中。
实验结果表明,共享层适用于学习风格信息。
2.我们使用对抗性训练来防止样式编码器编码内容信息,并实现样式信息中内容信息的消除。
3.我们提出了一种自适应对抗性体重学习策略,以防止模型在对抗性训练中崩溃。
2 proposed Model
2.1 Pre-train TTS Model
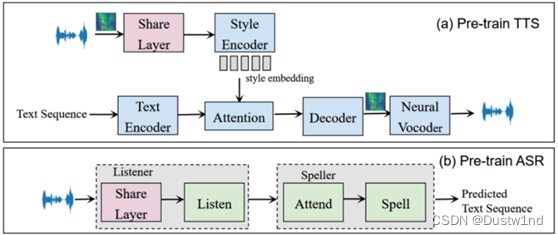
我们的TTS模型通过添加样式编码器和共享层来扩展Tacotron模型。图1(a)显示了改进的Tacotron模型的结构,参考编码器的结构和超参数与[10]相同,它由六个2D卷积层和一个GRU层组成。最后一个GRU状态通过一个完全连接的层来生成128维样式的嵌入。
然后,风格嵌入与文本嵌入相结合,作为解码器的输入,合成所需说话风格的音频。共享层的结构是一个BLSTM结构,在联合训练期间,它充当将TTS和ASR任务集成到一个网络中的桥梁。
2.2 Pre-train ASR Model

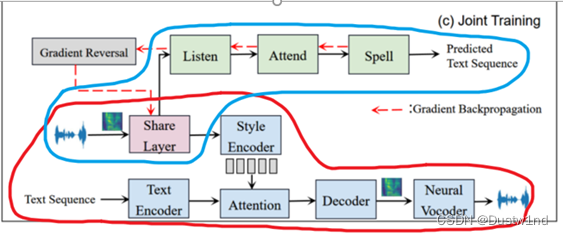
LAS是一种带注意的序列到序列ASR模型,它直接将音频序列转换为文本序列。模型结构如图1(b)所示。LAS模型主要包括两个子模块:侦听器和拼写器(Listener and Speller)。Listener是编码器,Speller是基于注意机制的解码器。共享层的结构是一个BLSTM,它是侦听器的一部分,与修改后的Tacotron中的共享层相同。监听器用于提取输入音频序列的高维特征。Speller是一个RNN网络,其功能是将侦听器中的高维特征转换为字符序列。
2.3. Joint training of TTS and ASR

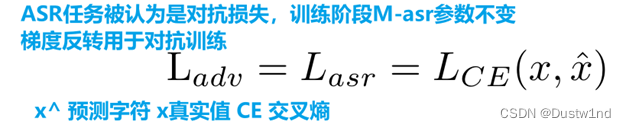


1 预训练了一个LAS模型
2 预训练了一个TTS模型
3 在联合训练阶段,将预先训练的LAS模型添加到预先训练的TTS模型中,
然后继续联合训练这两个模型,在联合训练过程中保持LAS模型参数不变。
4 将参考音频的mel频谱图输入共享层,这个共享层的输出称为共享嵌入,作为LAS模型的输入。
5 ASR任务中,在梯度反向传播期间在对抗性训练公式中执行梯度反转,使ASR模型无法很好地识别参考音频。这个共享嵌入被用作样式编码器的输入,这个过程减少了与提取的样式嵌入中的内容有关的信息。
6 最后,样式嵌入在每个解码器步骤与来自文本编码器的文本向量连接,作为解码器的输入。在TTS和ASR模型的联合训练中,模型损失包括TTS任务的重建损失和ASR任务的对抗性损失。
- EXPERIMENTS
3.1. Experimental setup
暴雪2013数据 + WaveRNN声码器
3.2. Results and Evaluations
我们使用主观听力测试和客观指标将我们提出的模型与基线模型进行了比较。我们实现了两个基线系统和提议的模型,如下所述。
?改进的Tacotron模型:与我们预训练的TTS模型相同。
?ASR指南[15]:在训练过程中,该模型使生成的语音得到ASR的良好识别,并使用ASR任务持续指导TTS训练,使合成语音更清晰。
?我们提出的方法:我们将预先训练的ASR模型与预先训练的TTS模型相结合。
我们进行ASR对抗性训练,使ASR不能很好地识别参考音频,目的是消除风格信息中的内容信息。我们还提出了一种自适应对抗权重学习策略,以防止模型崩溃

3.2.1. Objective Evaluation
使用word information lost (WIL) and WER [22] as objective evaluation.
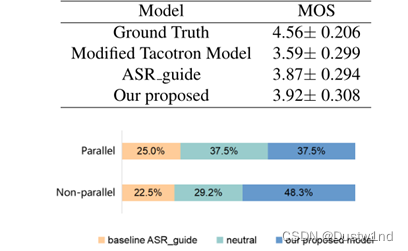
总损失分析:我们在实验中根据WER选择了重构损失和对抗损失的组合权重,最初损失设置为L_recon-L_adv。我们发现当总损失为L total 2时,存在一个较高的WER,模型最终崩溃。同时,我们发现当Ladv的权值越小,所合成的语音质量也越好。因此,我们使用一种自适应的对抗权学习策略来防止c
3.2.2. Subjective Evaluation
我们可以看出,我们提出的模型在并行和非并行风格传递方面优于基准模型,这进一步证明了我们提出的模型不仅可以有效地缓解风格与内容信息之间的纠缠,还可以提高模型的风格传递性能。
- CONCLUSIONS AND FUTURE WORK
在本文中,我们提出了一种新的方法,通过将TTS模型和ASR模型与共享层网络集成进行联合训练,并执行ASR对抗性训练来防止样式编码器编码内容信息,从而有效地缓解样式和内容信息之间的纠缠。为了防止模型崩溃,我们提出了一种自适应对抗性权重学习策略。实验结果证明了该模型的有效性。在未来,我们将继续考虑其他功能分离方法,尤其是细粒度样式建模。
说了但是有啥也没说,就根据TTS与ASR联合提出了一个对抗学习防止崩溃的策略公式,其他啥也没干,感觉也没咋说明白

