һ��Pandas����
��װ:
pip install pandas
����:https://pandas.pydata.org/
1. Pandas����

- 2008��WesMcKinney�������Ŀ�
- ר�����������ھ�Ŀ�Դpython��
- ��NumpyΪ����,����Numpyģ���ڼ��㷽�����ܸߵ�����
- ����matplotlib,�ܹ����Ļ�ͼ
- ���ص����ݽṹ
2. Ϊʲôʹ��Pandas
Numpy�Ѿ��ܹ��������Ǵ�������,�ܹ����matplotlib�����������չʾ������,��ôpandasѧϰ��Ŀ����ʲô�ط���?
-
��ǿͼ���ɶ���
-
����������numpy���д���ѧ���ɼ�����ʽ:
-
���ؽ��:
array([[92, 55, 78, 50, 50], [71, 76, 50, 48, 96], [45, 84, 78, 51, 68], [81, 91, 56, 54, 76], [86, 66, 77, 67, 95], [46, 86, 56, 61, 99], [46, 95, 44, 46, 56], [80, 50, 45, 65, 57], [41, 93, 90, 41, 97], [65, 83, 57, 57, 40]])�������չʾΪ����,�ɶ��Ծͻ���Ѻ�:
-

- ��ݵ����ݴ�������

- ��ȡ�ļ�����
- ��װ��Matplotlib��Numpy�Ļ�ͼ�ͼ���
3. ��
- pandas�����ơ��˽⡿
- ��ǿͼ���ɶ���
- ��ݵ����ݴ�������
- ��ȡ�ļ�����
- ��װ��Matplotlib��Numpy�Ļ�ͼ�ͼ���
����Pandas���ݽṹ
Pandas��һ�����������ݽṹ,�ֱ�Ϊ:Series��DataFrame��MultiIndex(�ϰ汾�н�Panel )��
����Series��һά���ݽṹ,DataFrame�Ƕ�ά�ı��������ݽṹ,MultiIndex����ά�����ݽṹ��
1.Series
Series��һ��������һά��������ݽṹ,���ܹ������κ����͵�����,�����������ַ�������������,��Ҫ��һ�����ݺ���֮��ص����������ֹ��ɡ�

1.1 Series�Ĵ���
# ����pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
- ����:
- data:���������,������ndarray��list��
- index:����,������Ψһ��,�������ݵij�����ȡ����û�д�����������,��Ĭ�ϻ��Զ�����һ����0-N������������
- dtype:���ݵ�����
ͨ���������ݴ���
- ָ������,Ĭ������
pd.Series(np.arange(10))
# ����
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
- ָ������
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
# ����
1 6.7
2 5.6
3 3.0
4 10.0
5 2.0
dtype: float64
- ͨ���ֵ����ݴ���
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
color_count
# ����
blue 200
green 500
red 100
yellow 1000
dtype: int64
1.2 Series������
Ϊ�˸�����ز���Series�����е�����������,Series���ṩ����������index��values
- index
color_count.index
# ���
Index(['blue', 'green', 'red', 'yellow'], dtype='object')
- values
color_count.values
# ���
array([ 200, 500, 100, 1000])
Ҳ����ʹ����������ȡ����:
color_count[2]
# ���
100
2.DataFrame
DataFrame��һ�������ڶ�ά��������(��excel)�Ķ���,����������,����������
- ������,������ͬ��,��������,��index,0��,axis=0
- ������,������ͬ��,��������,��columns,1��,axis=1
2.1 DataFrame�Ĵ���
# ����pandas
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
-
����:
- index:�б�ǩ�����û�д�����������,��Ĭ�ϻ��Զ�����һ����0-N������������
- columns:�б�ǩ�����û�д�����������,��Ĭ�ϻ��Զ�����һ����0-N������������
-
ͨ���������ݴ���
����һ:
pd.DataFrame(np.random.randn(2,3))
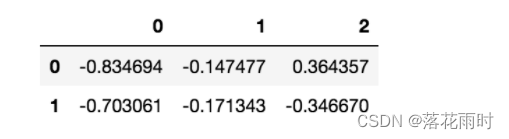
����������ǰ��ֱ��ʹ��np������������ʾ��ʽ,�Ƚ����ߵ�����
������:����ѧ���ɼ���
# ����10��ͬѧ,5�Ź��ε�����
score = np.random.randint(40, 100, (10, 5))
# ���
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
����������������ʽ���ѿ����洢����ʲô����������,�ɶ��ԱȽϲ�!!
����:��������ݸ����������ʾ?
# ʹ��Pandas�е����ݽṹ
score_df = pd.DataFrame(score)
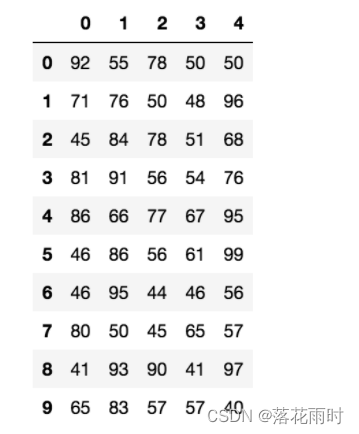
����������������������,��ʾЧ������
��:
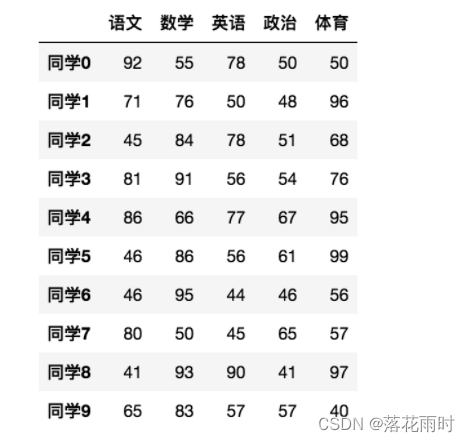
- ������������
# ��������������
subjects = ["����", "��ѧ", "Ӣ��", "����", "����"]
# ��������������
stu = ['ͬѧ' + str(i) for i in range(score_df.shape[0])]
# ����������
data = pd.DataFrame(score, columns=subjects, index=stu)
2.2 DataFrame������
- shape
data.shape
# ���
(10, 5)
- index
DataFrame���������б�
data.index
# ���
Index(['ͬѧ0', 'ͬѧ1', 'ͬѧ2', 'ͬѧ3', 'ͬѧ4', 'ͬѧ5', 'ͬѧ6', 'ͬѧ7', 'ͬѧ8', 'ͬѧ9'], dtype='object')
- columns
DataFrame���������б�
data.columns
# ���
Index(['����', '��ѧ', 'Ӣ��', '����', '����'], dtype='object')
- values
ֱ�ӻ�ȡ����array��ֵ
data.values
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
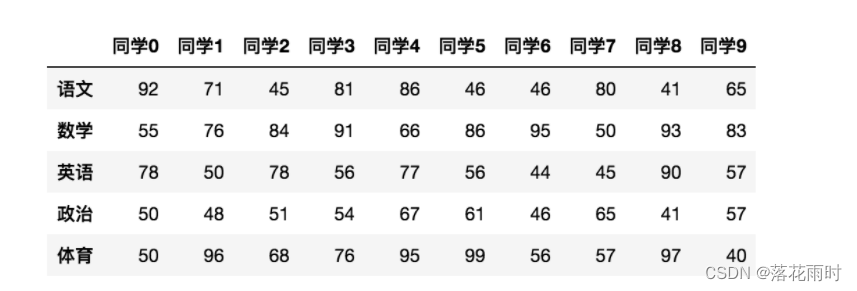
- T
ת��
data.T
���
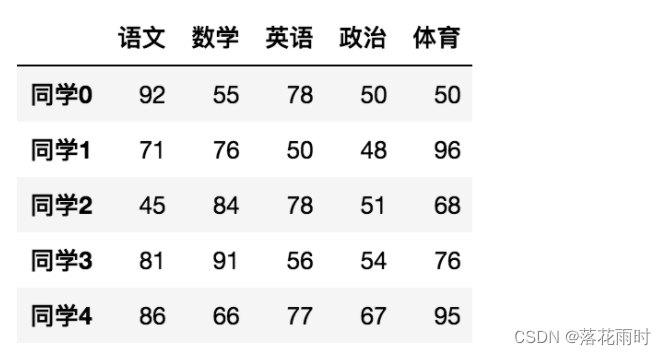
- head(5):��ʾǰ5������
������������,Ĭ��5�С��������N����ʾǰN��
data.head(5)
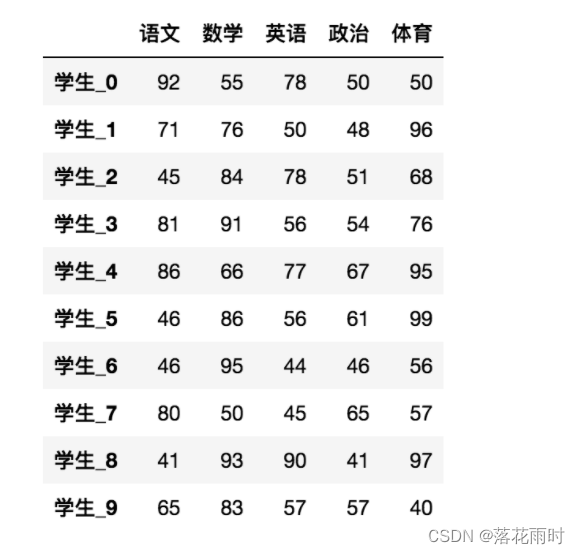
- tail(5):��ʾ��5������
������������,Ĭ��5�С��������N����ʾ��N��
data.tail(5)
2.3 DatatFrame����������
����:
2.3.1 ����������ֵ
stu = ["ѧ��_" + str(i) for i in range(score_df.shape[0])]
# ��������ȫ����
data.index = stu
ע��:�����ķ�ʽ�Ǵ����
# �����ķ�ʽ
data.index[3] = 'ѧ��_3'
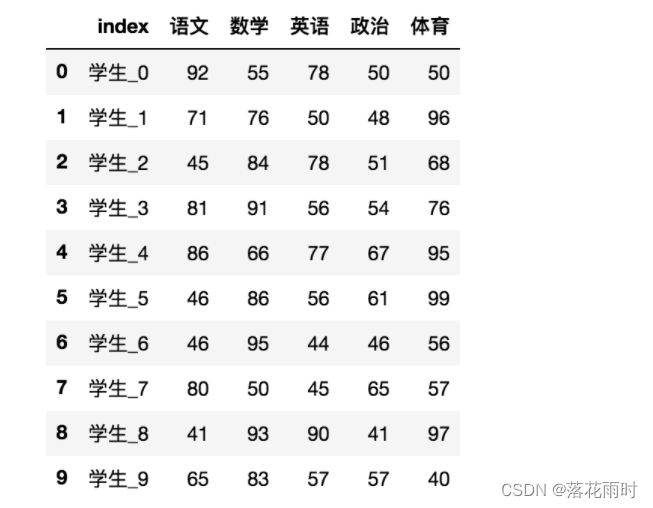
2.3.2 ��������
- reset_index(drop=False)
- �����µ��±�����
- drop:Ĭ��ΪFalse,��ɾ��ԭ������,���ΪTrue,ɾ��ԭ��������ֵ
# ��������,drop=False
data.reset_index()
# ��������,drop=True
data.reset_index(drop=True)
2.3.3 ��ij��ֵ����Ϊ�µ�����
- set_index(keys, drop=True)
- keys : ���������ɻ������������Ƶ��б�
- drop : boolean, default True.�����µ�����,ɾ��ԭ������
��������������
1������
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
3 10 31 2014
2�����·������µ�����
df.set_index('month')
sale year
month
1 55 2012
4 40 2014
7 84 2013
10 31 2014
3�����ö������,������·�
df = df.set_index(['year', 'month'])
df
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
ע:ͨ���ղŵ�����,����DataFrame�ͱ����һ������MultiIndex��DataFrame��
3.MultiIndex��Panel
3.1 MultiIndex
MultiIndex����ά�����ݽṹ;
�༶����(Ҳ�Ʋ�λ�����)��pandas����Ҫ����,������Series��DataFrame������ӵ��2���Լ�2�����ϵ�������
3.1.1 multiIndex������
��ӡ�ղŵ�df�����������
df.index
MultiIndex(levels=[[2012, 2013, 2014], [1, 4, 7, 10]],
labels=[[0, 2, 1, 2], [0, 1, 2, 3]],
names=['year', 'month'])
�༶��ֲ���������
- index����
- names:levels������
- levels:ÿ��level��Ԫ��ֵ
df.index.names
# FrozenList(['year', 'month'])
df.index.levels
# FrozenList([[1, 2], [1, 4, 7, 10]])
3.1.2 multiIndex�Ĵ���
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
pd.MultiIndex.from_arrays(arrays, names=('number', 'color'))
# ���
MultiIndex(levels=[[1, 2], ['blue', 'red']],
codes=[[0, 0, 1, 1], [1, 0, 1, 0]],
names=['number', 'color'])
3.2 Panel
3.2.1 panel�Ĵ���
-
class
pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None)-
����:�洢3ά�����Panel�ṹ
-
����:
-
data : ndarray����dataframe
-
items : ��������������Ķ���,axis=0
-
major_axis : ��������������Ķ���,axis=1
-
minor_axis : ��������������Ķ���,axis=2
-
-
p = pd.Panel(data=np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
# ���
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 3 (major_axis) x 2 (minor_axis)
Items axis: A to D
Major_axis axis: 2013-01-01 00:00:00 to 2013-01-03 00:00:00
Minor_axis axis: first to second
3.2.2 �鿴panel����
p[:,:,"first"]
p["B",:,:]
ע:Pandas�Ӱ汾0.20.0��ʼ����:�Ƽ������ڱ�ʾ3D���ݵķ�����ͨ��DataFrame�ϵ�MultiIndex����
4. ��
- pandas�����ơ��˽⡿
- ��ǿͼ���ɶ���
- ��ݵ����ݴ�������
- ��ȡ�ļ�����
- ��װ��Matplotlib��Numpy�Ļ�ͼ�ͼ���
- series��֪����
- ����
- pd.Series([], index=[])
- pd.Series({})
- ����
- ����.index
- ����.values
- ����
- DataFrame�����ա�
- ����
- pd.DataFrame(data=None, index=None, columns=None)
- ����
- shape �C ��״
- index �C ������
- columns �C ������
- values �C �鿴ֵ
- T �C ת��
- head() �C �鿴ͷ������
- tail() �C �鿴β������
- DataFrame����
- �ĵ�ʱ��,��Ҫ����ȫ����
- ����.reset_index()
- ����.set_index(keys)
- ����
- MultiIndex��Panel���˽⡿
- multiIndex:
- ����ndarray�е���ά����
- ����:
- pd.MultiIndex.from_arrays()
- ����:
- ����.index
- panel:
- pd.Panel(data, items, major_axis, minor_axis)
- panel����Ҫ���뿴��,����Ҫ����������dataframe����series�ſ���
- multiIndex:
���� �������ݲ���
Ϊ�˸��õ�������Щ��������,���ǽ���ȡһ����ʵ�Ĺ�Ʊ���ݡ������ļ�����,�����ڽ���,����ֻ����һ��API
# ��ȡ�ļ�
data = pd.read_csv("./data/stock_day.csv")
# ɾ��һЩ��,�����ݸ���Щ,��ȥ������IJ���
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
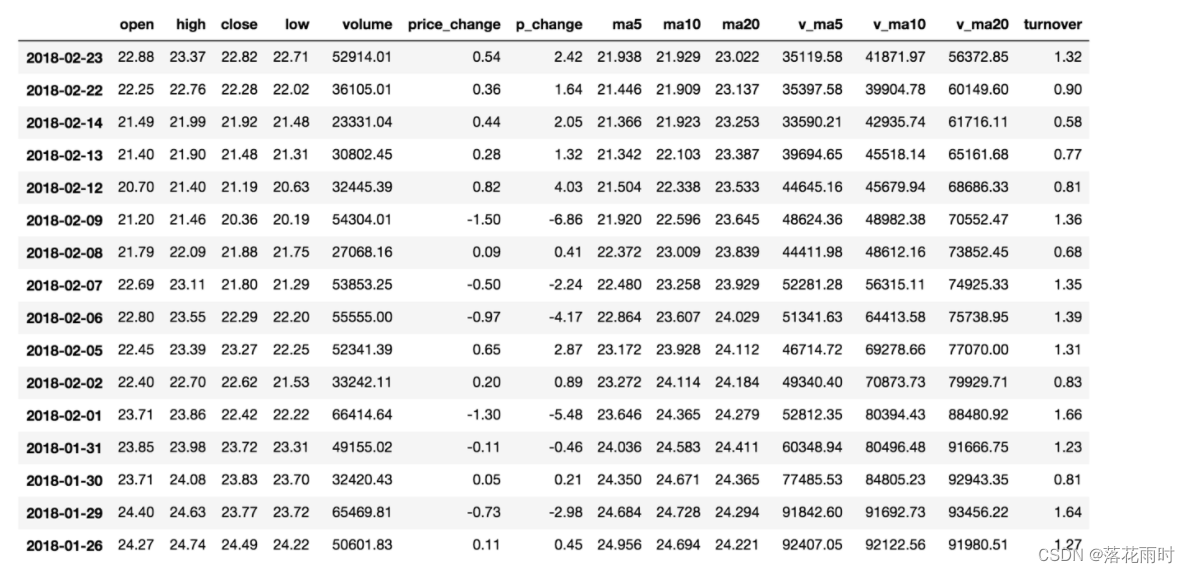
1. ��������
Numpy���������Ѿ�����ʹ������ѡȡ���к���Ƭѡ��,pandasҲ֧�����ƵIJ���,Ҳ����ֱ��ʹ������������
��,�������ʹ�á�
1.1 ֱ��ʹ����������(���к���)
��ȡ��2018-02-27������ġ�close���Ľ��
# ֱ��ʹ�������������ֵķ�ʽ(���к���)
data['open']['2018-02-27']
23.53
# ��֧�ֵIJ���
# ����
data['2018-02-27']['open']
# ����
data[:1, :2]
1.2 ���loc����ilocʹ������
��ȡ�ӡ�2018-02-27��:��2018-02-22��,'open���Ľ��
# ʹ��loc:ֻ��ָ����������������
data.loc['2018-02-27':'2018-02-22', 'open']
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
Name: open, dtype: float64
# ʹ��iloc����ͨ���������±�ȥ��ȡ
# ��ȡǰ3������,ǰ5�еĽ��
data.iloc[:3, :5]
open high close low
2018-02-27 23.53 25.88 24.16 23.53
2018-02-26 22.80 23.78 23.53 22.80
2018-02-23 22.88 23.37 22.82 22.71
1.3 ʹ��ix�������
Warning:Starting in 0.20.0, the
.ixindexer is deprecated, in favor of the more strict.ilocand.locindexers.
��ȡ�е�1�쵽��4��,[��open��, ��close��, ��high��, ��low��]����ĸ�ָ��Ľ��
# ʹ��ix�����±��������������
data.ix[0:4, ['open', 'close', 'high', 'low']]
# �Ƽ�ʹ��loc��iloc����ȡ�ķ�ʽ
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02
2. ��ֵ����
��DataFrame���е�close�н������¸�ֵΪ1
# ֱ����ԭ����ֵ
data['close'] = 1
# ����
data.close = 1
3. ����
������������ʽ,һ�ֶ���������������,һ�ֶ������ݽ�������
3.1 DataFrame����
- ʹ��df.sort_values(by=, ascending=)
- ���������߶������������,
- ����:
- by:ָ������ο��ļ�
- ascending:Ĭ������
- ascending=False:����
- ascending=True:����
# ���տ��̼۴�С�������� , ʹ��ascendingָ�����մ�С����
data.sort_values(by="open", ascending=True).head()
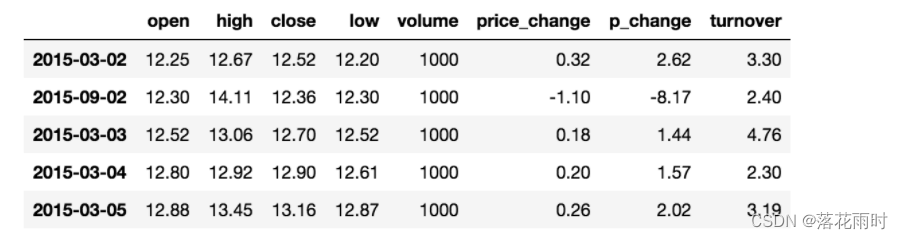
# ���ն������������
data.sort_values(by=['open', 'high'])

- ʹ��df.sort_index��������������
�����Ʊ����������ԭ���ǴӴ�С,������������,��С����
# ��������������
data.sort_index()

3.2 Series����
- ʹ��series.sort_values(ascending=True)��������
series����ʱ,ֻ��һ��,����Ҫ����
data['p_change'].sort_values(ascending=True).head()
2015-09-01 -10.03
2015-09-14 -10.02
2016-01-11 -10.02
2015-07-15 -10.02
2015-08-26 -10.01
Name: p_change, dtype: float64
- ʹ��series.sort_index()��������
��dfһ��
# ��������������
data['p_change'].sort_index().head()
2015-03-02 2.62
2015-03-03 1.44
2015-03-04 1.57
2015-03-05 2.02
2015-03-06 8.51
Name: p_change, dtype: float64
4. �ܽ�
- 1.���������ա�
- ֱ������ �C ���к���,����Ҫͨ���������ַ������л�ȡ
- loc �C ���к���,����Ҫͨ���������ַ������л�ȡ
- iloc �C ���к���,��ͨ���±��������
- ix �C ���к���, �������������ַ�����Ͻ�������
- 2.��ֵ��֪����
- data[����] = **
- data.** = **
- 3.����֪����
- dataframe
- ����.sort_values()
- ����.sort_index()
- series
- ����.sort_values()
- ����.sort_index()
- dataframe
�ġ� DataFrame����
1. ��������
- add(other)
���������ѧ������Ͼ����һ������
data['open'].add(1)
2018-02-27 24.53
2018-02-26 23.80
2018-02-23 23.88
2018-02-22 23.25
2018-02-14 22.49
- sub(other)
2. ������
2.1 ���������
- ����ɸѡdata[��open��] > 23����������
- data[��open��] > 23���������
data["open"] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
# ���жϵĽ��������Ϊɸѡ������
data[data["open"] > 23].head()

- ��ɶ�����ж�,
data[(data["open"] > 23) & (data["open"] < 24)].head()

2.2 �����㺯��
- query(expr)
- expr:��ѯ�ַ���
ͨ��queryʹ�øղŵĹ��̸��ӷ����
data.query("open<24 & open>23").head()
- isin(values)
�����жϡ�open���Ƿ�Ϊ23.53��23.85
# ����ָ��ֵ����һ���ж�,�Ӷ�����ɸѡ����
data[data["open"].isin([23.53, 23.85])]
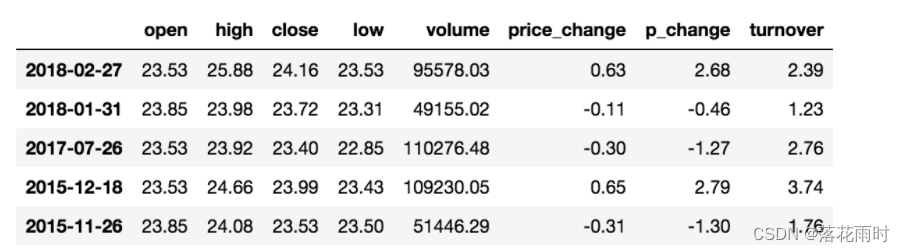
3. ͳ������
3.1 describe
�ۺϷ���: �ܹ�ֱ�ӵó��ܶ�ͳ�ƽ��,count, mean, std, min, max ��
# ����ƽ��ֵ��������ֵ����Сֵ
data.describe()
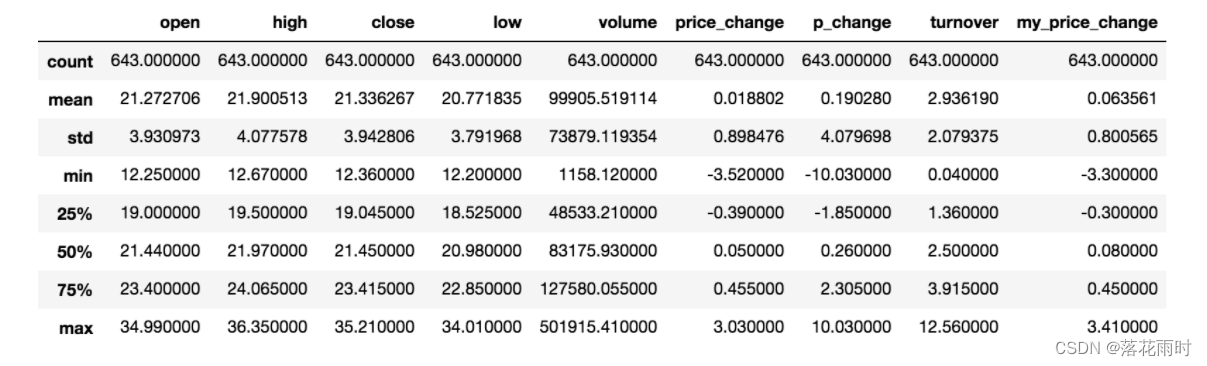
3.2 ͳ�ƺ���
Numpy�����Ѿ���ϸ����,������������ʾmin(��Сֵ), max(���ֵ), mean(ƽ��ֵ), median(��λ��), var(����), std(����),mode(����)���:
count | Number of non-NA observations |
|---|---|
sum | Sum of values |
mean | Mean of values |
median | Arithmetic median of values |
min | Minimum |
max | Maximum |
mode | Mode |
abs | Absolute Value |
prod | Product of values |
std | Bessel-corrected sample standard deviation |
var | Unbiased variance |
idxmax | compute the index labels with the maximum |
idxmin | compute the index labels with the minimum |
���ڵ�������ȥ����ͳ�Ƶ�ʱ��,�����ỹ�ǰ���Ĭ���С�columns�� (axis=0, default),���Ҫ���С�index�� ��Ҫָ��(axis=1)
- max()��min()
# ʹ��ͳ�ƺ���:0 ����������, 1 ��������ͳ�ƽ��
data.max(0)
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
my_price_change 3.41
dtype: float64
- std()��var()
# ����
data.var(0)
open 1.545255e+01
high 1.662665e+01
close 1.554572e+01
low 1.437902e+01
volume 5.458124e+09
price_change 8.072595e-01
p_change 1.664394e+01
turnover 4.323800e+00
my_price_change 6.409037e-01
dtype: float64
# ����
data.std(0)
open 3.930973
high 4.077578
close 3.942806
low 3.791968
volume 73879.119354
price_change 0.898476
p_change 4.079698
turnover 2.079375
my_price_change 0.800565
dtype: float64
- median():���
��λ��Ϊ�����ݴ�С��������,�����м���Ǹ���Ϊ��λ�������û���м���,ȡ�м���������ƽ��ֵ��
df = pd.DataFrame({'COL1' : [2,3,4,5,4,2],
'COL2' : [0,1,2,3,4,2]})
df.median()
COL1 3.5
COL2 2.0
dtype: float64
- idxmax()��idxmin()
# ������ֵ��λ��
data.idxmax(axis=0)
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
my_price_change 2015-07-10
dtype: object
# �����Сֵ��λ��
data.idxmin(axis=0)
open 2015-03-02
high 2015-03-02
close 2015-09-02
low 2015-03-02
volume 2016-07-06
price_change 2015-06-15
p_change 2015-09-01
turnover 2016-07-06
my_price_change 2015-06-15
dtype: object
3.3 �ۼ�ͳ�ƺ���
| ���� | ���� |
|---|---|
cumsum | ����ǰ1/2/3/��/n�����ĺ� |
cummax | ����ǰ1/2/3/��/n���������ֵ |
cummin | ����ǰ1/2/3/��/n��������Сֵ |
cumprod | ����ǰ1/2/3/��/n�����Ļ� |
��ô��Щ�ۼ�ͳ�ƺ�����ô��?
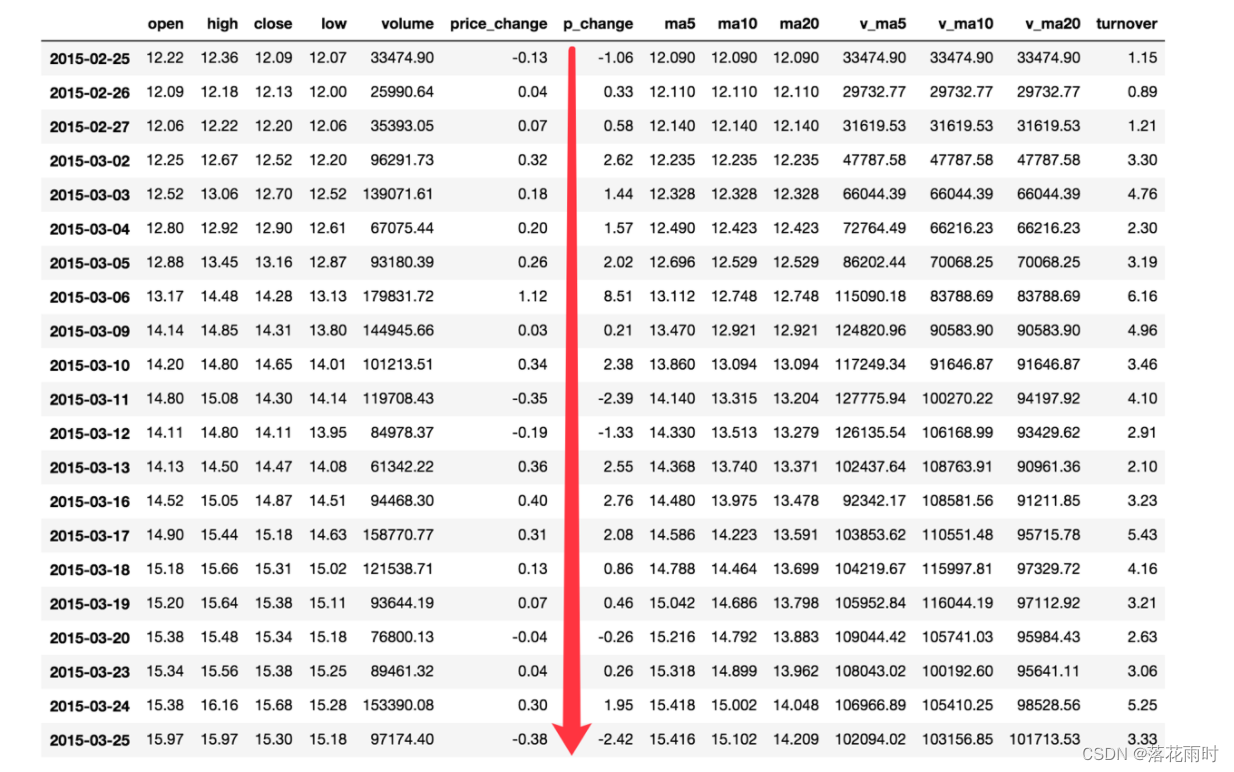
������Щ�������Զ�series��dataframe����
�������ǰ���ʱ��Ĵ�ǰ�����������ۼ�
- ����
# ����֮��,�����ۼ����
data = data.sort_index()
- ��p_change�������
stock_rise = data['p_change']
# plot����������ǰ��ֱ��ͼ������ͼ����ͼ������ͼ
stock_rise.cumsum()
2015-03-02 2.62
2015-03-03 4.06
2015-03-04 5.63
2015-03-05 7.65
2015-03-06 16.16
2015-03-09 16.37
2015-03-10 18.75
2015-03-11 16.36
2015-03-12 15.03
2015-03-13 17.58
2015-03-16 20.34
2015-03-17 22.42
2015-03-18 23.28
2015-03-19 23.74
2015-03-20 23.48
2015-03-23 23.74
��ô��������������͵Ľ�����õ���ʾ��?
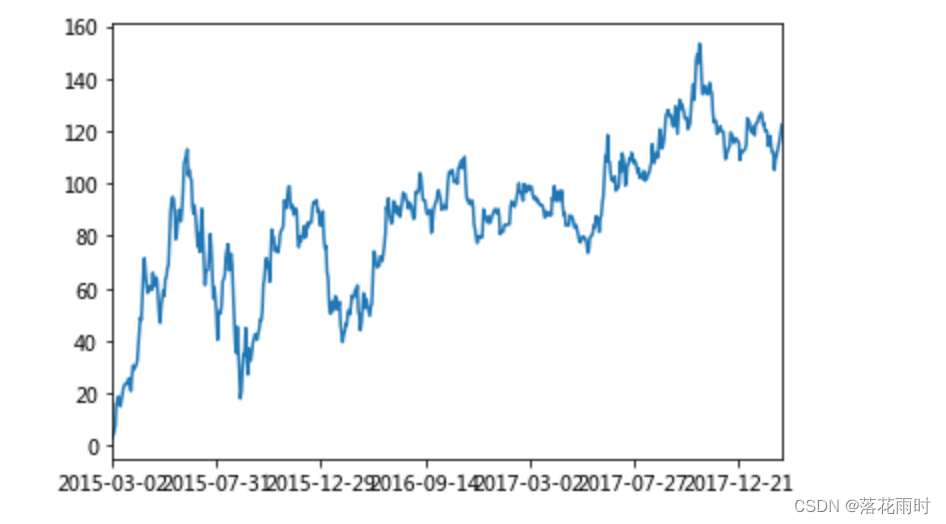
���Ҫʹ��plot����,��Ҫ����matplotlib.
import matplotlib.pyplot as plt
# plot��ʾͼ��
stock_rise.cumsum().plot()
# ��Ҫ����show,������ʾ�����
plt.show()
����plot,�Ժ�����API��ѡ��
4. �Զ�������
- apply(func, axis=0)
- func:�Զ��庯��
- axis=0:Ĭ������,axis=1Ϊ�н�������
- ����һ������,���ֵ-��Сֵ�ĺ���
data[['open', 'close']].apply(lambda x: x.max() - x.min(), axis=0)
open 22.74
close 22.85
dtype: float64
5. ��
- �������㡾֪����
- �����㡾֪����
- 1.���������
- 2.�����㺯��
- ����.query()
- ����.isin()
- ͳ�����㡾֪����
- 1.����.describe()
- 2.ͳ�ƺ���
- 3.�ۻ�ͳ�ƺ���
- �Զ������㡾֪����
- apply(func, axis=0)
�塢 Pandas��ͼ
1. pandas.DataFrame.plot
DataFrame.plot(kind=��line��)- kind : str,��Ҫ����ͼ�ε�����
- ��line�� : line plot (default)
- ��bar�� : vertical bar plot
- ��barh�� : horizontal bar plot
- ��hist�� : histogram
- ��pie�� : pie plot
- ��scatter�� : scatter plot
2. pandas.Series.plot
���� �ļ���ȡ��洢
���ǵ����ݴִ������ļ�����,����pandas��֧�ָ��ӵ�IO����,pandas��API֧���ڶ���ļ���ʽ,��CSV��SQL��XLS��JSON��HDF5��
ע:��õ�HDF5��CSV�ļ�
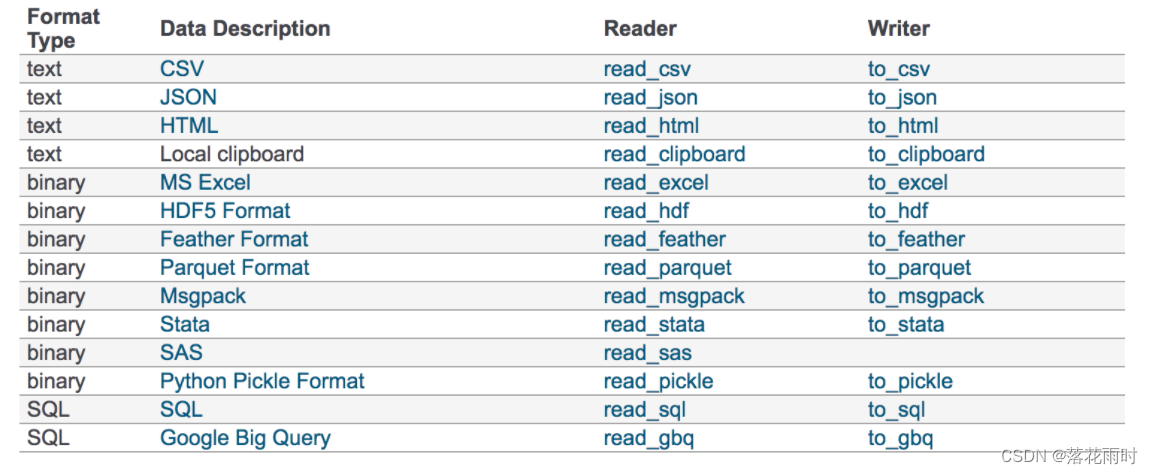
1. CSV
1.1 read_csv
- pandas.read_csv(filepath_or_buffer, sep =��,��, usecols )
- filepath_or_buffer:�ļ�·��
- sep :�ָ���,Ĭ����","����
- usecols:ָ����ȡ������,�б���ʽ
- ����:��ȡ֮ǰ�Ĺ�Ʊ������
# ��ȡ�ļ�,����ָ��ֻ��ȡ'open', 'close'ָ��
data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close'])
open close
2018-02-27 23.53 24.16
2018-02-26 22.80 23.53
2018-02-23 22.88 22.82
2018-02-22 22.25 22.28
2018-02-14 21.49 21.92
1.2 to_csv
- DataFrame.to_csv(path_or_buf=None, sep=', ��, columns=None, header=True, index=True, mode=��w��, encoding=None)
- path_or_buf :�ļ�·��
- sep :�ָ���,Ĭ����","����
- columns :ѡ����Ҫ��������
- header :boolean or list of string, default True,�Ƿ�д��������ֵ
- index:�Ƿ�д��������
- mode:��w��:��д, ��a�� ��
- ����:�����ȡ�����Ĺ�Ʊ����
- ���桯open���е�����,Ȼ���ȡ�鿴���
# ѡȡ10�����ݱ���,���ڹ۲�����
data[:10].to_csv("./data/test.csv", columns=['open'])
# ��ȡ,�鿴���
pd.read_csv("./data/test.csv")
Unnamed: 0 open
0 2018-02-27 23.53
1 2018-02-26 22.80
2 2018-02-23 22.88
3 2018-02-22 22.25
4 2018-02-14 21.49
5 2018-02-13 21.40
6 2018-02-12 20.70
7 2018-02-09 21.20
8 2018-02-08 21.79
9 2018-02-07 22.69
�ᷢ�ֽ��������뵽�ļ�����,��ɵ�����һ�����ݡ������Ҫɾ��,����ָ��index����,ɾ��ԭ�����ļ�,���±���һ�Ρ�
# index:�洢���ὲ����ֵ���һ������
data[:10].to_csv("./data/test.csv", columns=['open'], index=False)
2. HDF5
2.1 read_hdf��to_hdf
HDF5�ļ��Ķ�ȡ�ʹ洢��Ҫָ��һ����,ֵΪҪ�洢��DataFrame
-
pandas.read_hdf(path_or_buf,key =None,** kwargs)
��h5�ļ����ж�ȡ����
- path_or_buffer:�ļ�·��
- key:��ȡ�ļ�
- return:Theselected object
-
DataFrame.to_hdf(path_or_buf, key, **kwargs)
2.2 ����
- ��ȡ�ļ�
day_close = pd.read_hdf("./data/day_close.h5")
�����ȡ��ʱ��������´���
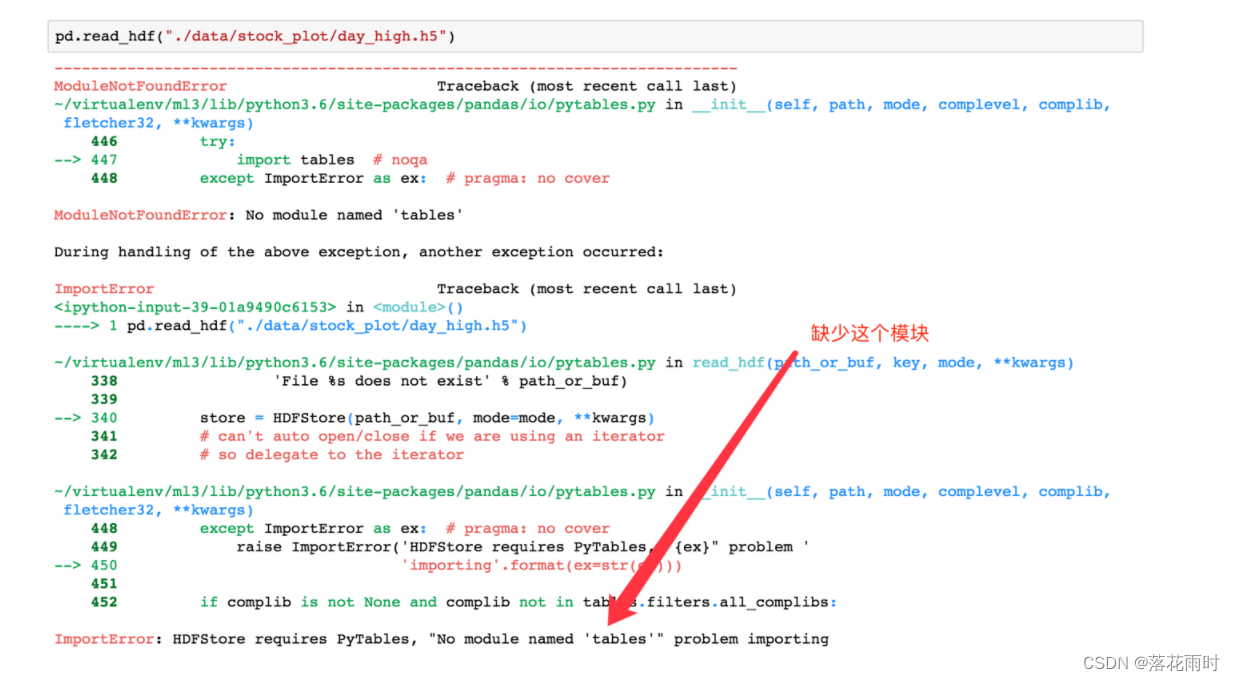
��Ҫ��װ��װtablesģ����ⲻ�ܶ�ȡHDF5�ļ�
pip install tables

- �洢�ļ�
day_close.to_hdf("./data/test.h5", key="day_close")
�ٴζ�ȡ��ʱ��, ��Ҫָ����������
new_close = pd.read_hdf("./data/test.h5", key="day_close")
ע��:����ѡ��ʹ��HDF5�ļ��洢
- HDF5�ڴ洢��ʱ��֧��ѹ��,ʹ�õķ�ʽ��blosc,������ٶ������Ҳ��pandasĬ��֧�ֵ�
- ʹ��ѹ�����������������,��ʡ�ռ�
- HDF5���ǿ�ƽ̨��,��������Ǩ�Ƶ�hadoop ����
3. JSON
JSON�����dz��õ�һ�����ݽ�����ʽ,ǰ����ǰ��˵Ľ��������õ�,Ҳ���ڴ洢��ʱ��ѡ�����ָ�ʽ������������Ҫ֪��Pandas��ν��ж�ȡ�ʹ洢JSON��ʽ��
3.1 read_json
- pandas.read_json(path_or_buf=None, orient=None, typ=��frame��, lines=False)
- ��JSON��ʽ����Ĭ�ϵ�Pandas DataFrame��ʽ
- orient : string,Indication of expected JSON string format.
- ��split�� : dict like {index -> [index], columns -> [columns], data -> [values]}
- split �������ܽᵽ����,����������,���ݵ����ݡ��������ֶ��ֿ���
- ��records�� : list like [{column -> value}, �� , {column -> value}]
- records ��
columns:values����ʽ���
- records ��
- ��index�� : dict like {index -> {column -> value}}
- index ��
index:{columns:values}...����ʽ���
- index ��
- ��columns�� : dict like {column -> {index -> value}},Ĭ�ϸø�ʽ
- colums ��
columns:{index:values}����ʽ���
- colums ��
- ��values�� : just the values array
- values ֱ�����ֵ
- ��split�� : dict like {index -> [index], columns -> [columns], data -> [values]}
- lines : boolean, default False
- ����ÿ�ж�ȡjson����
- typ : default ��frame��, ָ��ת���ɵĶ�������series����dataframe
3.2 read_josn ����
- ���ݽ���
����ʹ��һ�����ű���������ݼ�,��ʽΪjson��is_sarcastic:1���̵�,����Ϊ0;headline:���ű����ı���;article_link:���ӵ�ԭʼ�������¡��洢��ʽΪ:
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0}
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0}
- ��ȡ
orientָ���洢��json��ʽ,linesָ��������ȥ���һ������
json_read = pd.read_json("./data/Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
���Ϊ:

3.3 to_json
- DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- ��Pandas ����洢Ϊjson��ʽ
- path_or_buf=None:�ļ���ַ
- orient:�洢��json��ʽ,{��split��,��records��,��index��,��columns��,��values��}
- lines:һ������洢Ϊһ��
3.4 ����
- �洢�ļ�
json_read.to_json("./data/test.json", orient='records')
���
[{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0},{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1},{"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0},{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/advancing-the-worlds-women_b_6810038.html","headline":"advancing the world's women","is_sarcastic":0},....]
- ��lines����ΪTrue
json_read.to_json("./data/test.json", orient='records', lines=True)
���
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/versace-black-code_us_5861fbefe4b0de3a08f600d5","headline":"former versace store clerk sues over secret 'black code' for minority shoppers","is_sarcastic":0}
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/roseanne-revival-review_us_5ab3a497e4b054d118e04365","headline":"the 'roseanne' revival catches up to our thorny political mood, for better and worse","is_sarcastic":0}
{"article_link":"https:\/\/local.theonion.com\/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697","headline":"mom starting to fear son's web series closest thing she will have to grandchild","is_sarcastic":1}
{"article_link":"https:\/\/politics.theonion.com\/boehner-just-wants-wife-to-listen-not-come-up-with-alt-1819574302","headline":"boehner just wants wife to listen, not come up with alternative debt-reduction ideas","is_sarcastic":1}
{"article_link":"https:\/\/www.huffingtonpost.com\/entry\/jk-rowling-wishes-snape-happy-birthday_us_569117c4e4b0cad15e64fdcb","headline":"j.k. rowling wishes snape happy birthday in the most magical way","is_sarcastic":0}...
4. ��
- pandas��CSV��HDF5��JSON�ļ��Ķ�ȡ��֪����
- ����.read_**()
- ����.to_**()

