摘要
在本文中,作者提出了将Swin Transformer缩放到30亿个参数的技术 ,并使其能够使用高达1536×1536分辨率的图像进行训练。通过扩大容量和分辨率,Swin Transformer在四个具有代表性的视觉基准上创造了新的记录:ImageNet-V2图像分类的84.0%top-1 准确度,COCO目标检测上的63.1/54.4box / mask mAP ,ADE20K语义分割的59.9 mIoU ,以及Kinetics-400视频动作分类的86.8%top-1 准确度。
论文地址:Swin Transformer V2: Scaling Up Capacity and Resolution
动机
对于增大视觉模型,有以下难点:
- 视觉模型面临放大不稳定问题
- 下游视觉任务需要高分辨率的图像或大注意力窗,可能需要将低分辨率预训练的窗口大小调整成适合高分辨率的大小
- 模型容量和分辨率的放大会使GPU内存消耗过高
网络结构
网络结构如图1。
相比于v1有以下调整:
- 使用res post norm取代pre norm
- 使用缩放余弦注意力取代点积注意力
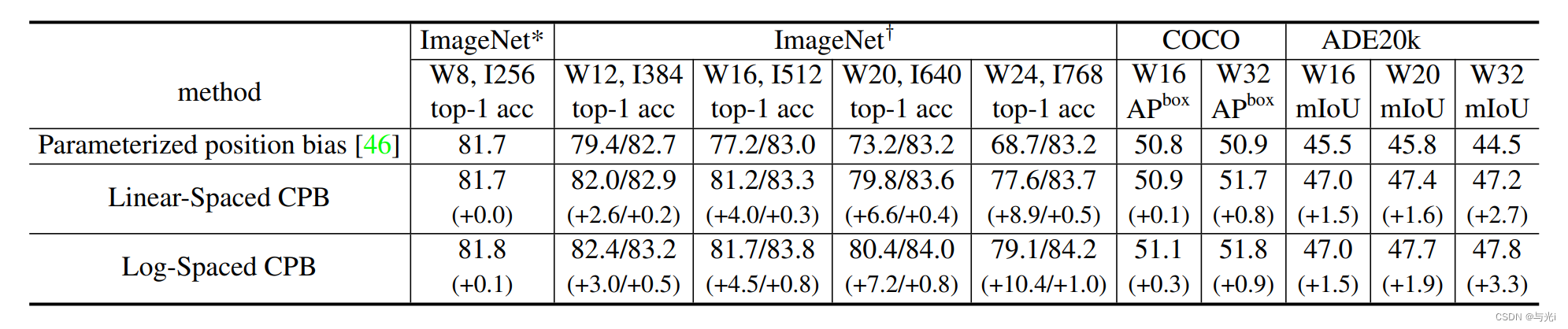
- 使用对数间隔的连续相对位置偏差方法取代参数化方法
1,2点使模型更易于扩大容量,3点使模型能够更有效地进行跨窗口分辨率传输。
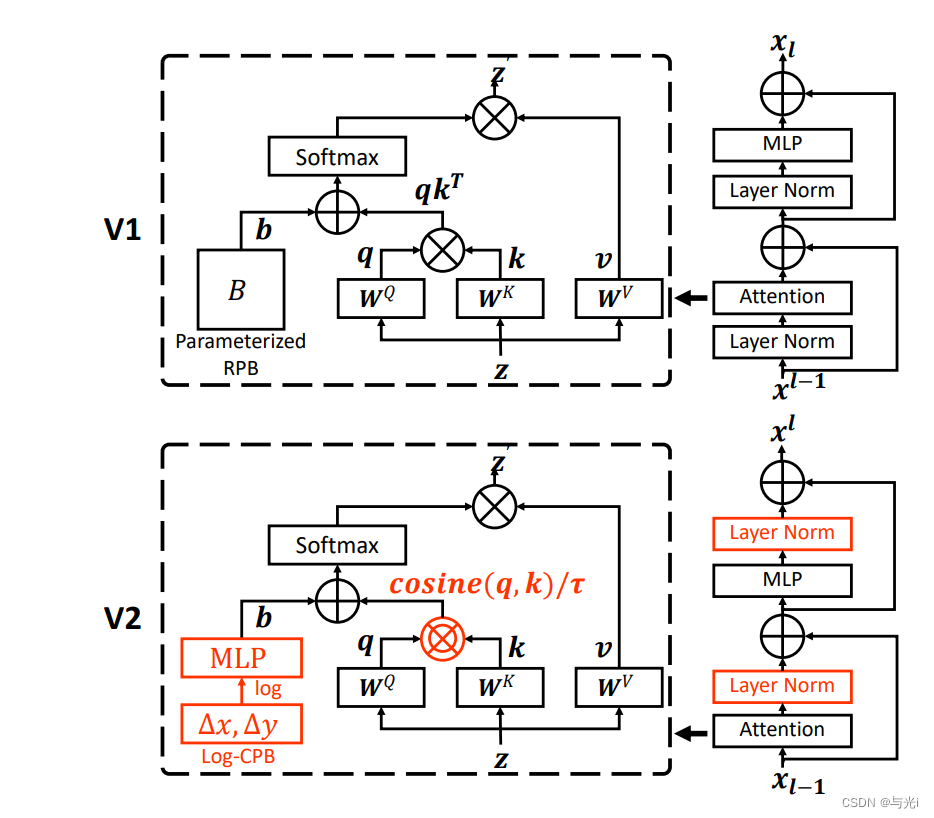
图1
方法
res post norm
对于大型模型,各层的激活幅度差异显著增大。这是由于每个残差块输出的激活值直接输入到主分支,导致主分支的振幅在深层次越来越大。因此提出了一种新的归一化配置,称为post norm,它将LN层从每个残差单元的开始移动到后端 。每个残差块的输出会在和主分支合并之前进行归一化,使得主分支的振幅在更深的层次不会累积。如图2所示,使用该方法的激活幅度比使用pre norm预规范化小得多。
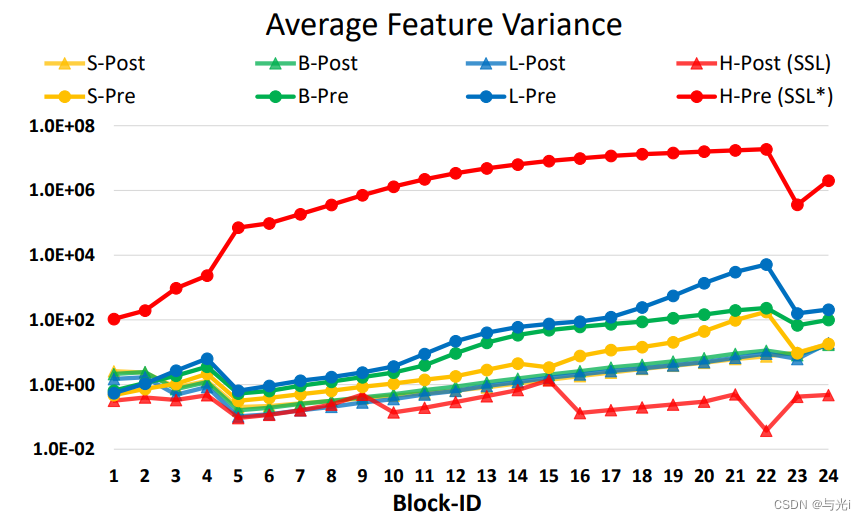
图2
缩放余弦注意
在注意力计算总,常计算查询q和关键向量k的点积。在大型视觉模型中使用点积时,使得一些块和头部的注意力图陷入几个像素的控制。 因此使用缩放预先注意力的方法,使用缩放余弦函数计算像素对i和j的注意力对数:
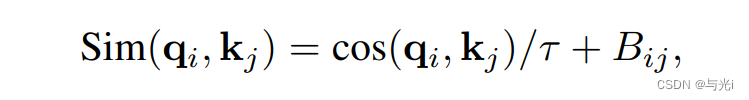
B
i
j
B_{ij}
Bij?是像素i和j之间的相对位置偏移,
τ
\tau
τ是一个可学习的标量,在头部和层之间不共享,大于0.01。余弦函数是自然归一化的。
放大窗口分辨率
使用对数间隔的连续位置偏差方法,使得相对位移偏差可以在窗口分辨率之间平滑地传递。
该方法是在相对坐标上使用一个小型元网络,它对任意相对坐标生成偏置参数,因而可以自然地进行任意可变窗口尺寸的迁移。在推理阶段,每个相对位置的偏置可以预先计算并保存,按照原始方式进行推理。
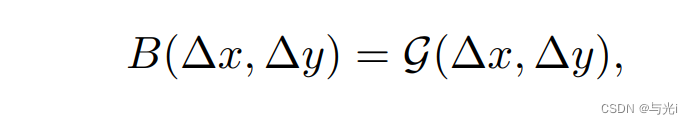
为了缓解线性间隔坐标在大幅改变窗口大小的时候,需要将相对坐标范围外推很大一部分,文章使用了对数间隔坐标。
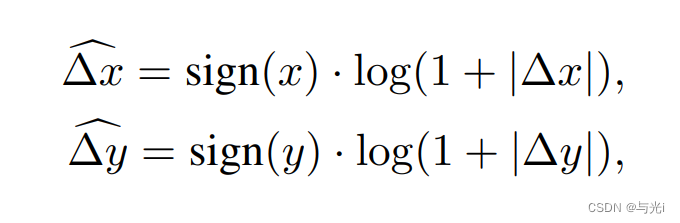
节省GPU内存
通过ZeRO优化器,模型参数和相应的优化状态将被划分并分配到多个GPU,从而显著降低显存消耗。作者使用DeepSpeed框架,并在实验中使用了ZeRO 优化器。这种优化对训练速度几乎没有影响。
Transformer层中的特征映射也会消耗大量GPU内存,这在图像和窗口分辨率较高时会构成瓶颈。Activation check-pointing优化将使训练速度最多降低30%。
使用顺序注意力计算而不是批处理计算。
为了解决数据匮乏问题,一方面将ImageNet-22K数据集适度放大5倍,以达到7000万张带噪标签的图像;另一个方面采用了一种自监督学习方法来更好地利用该数据。
实验
放大实验规模
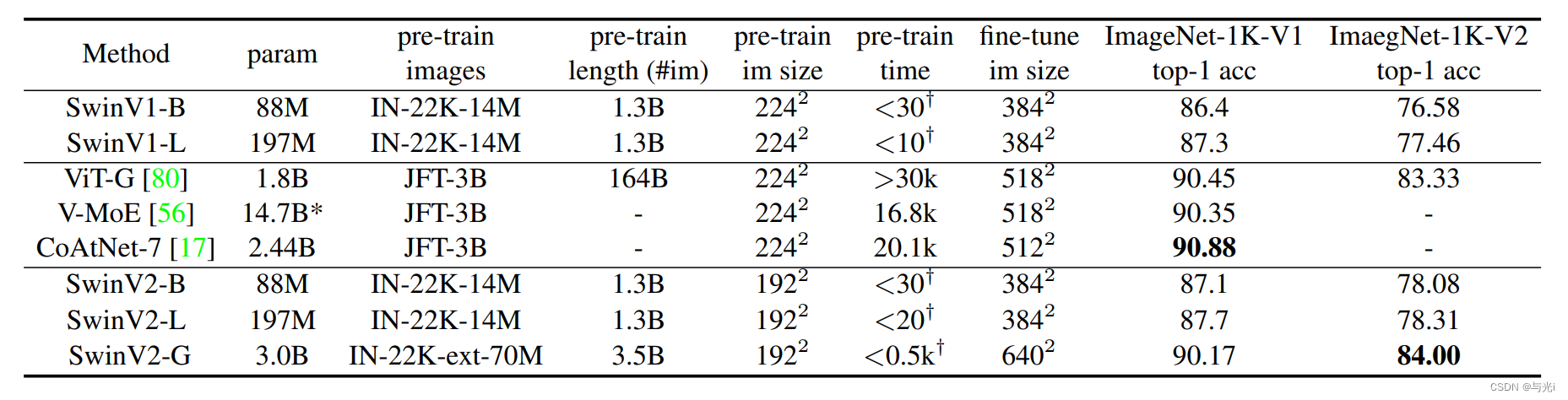
一系列大模型在ImageNet-1K V1和V2上的实验结果。
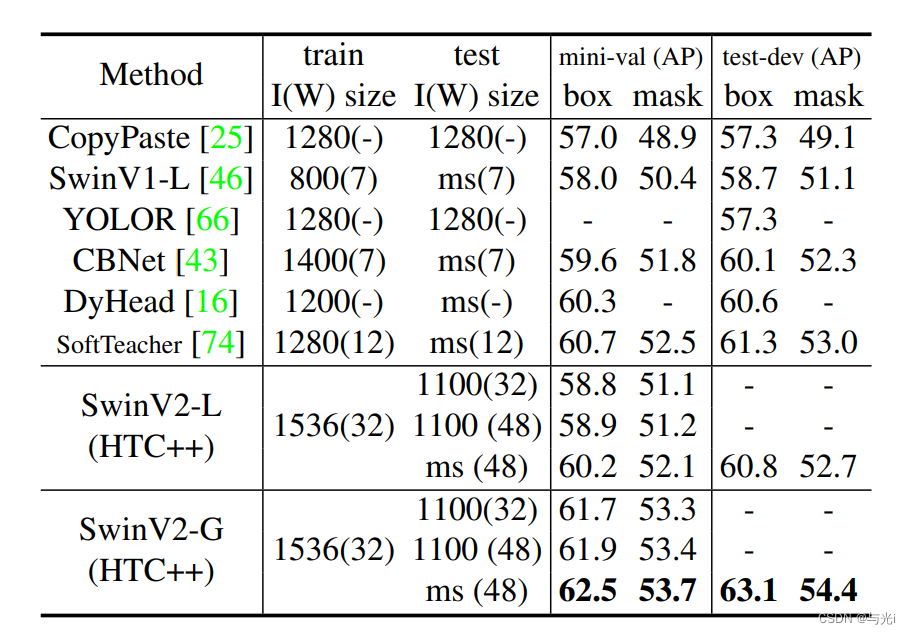
SOTA方法和SwinV2在COCO目标检测上的实验结果。
SOTA方法和SwinV2在ADE20K语义分割上的实验结果。
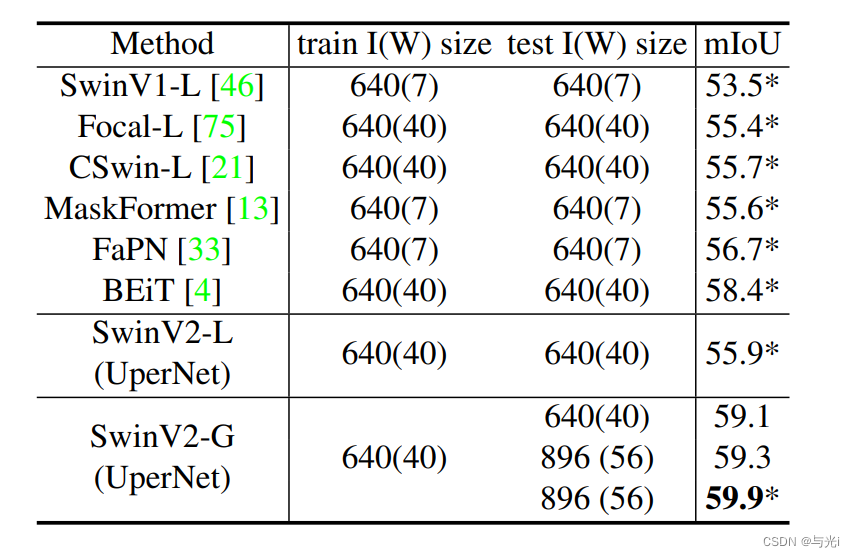
消融实验
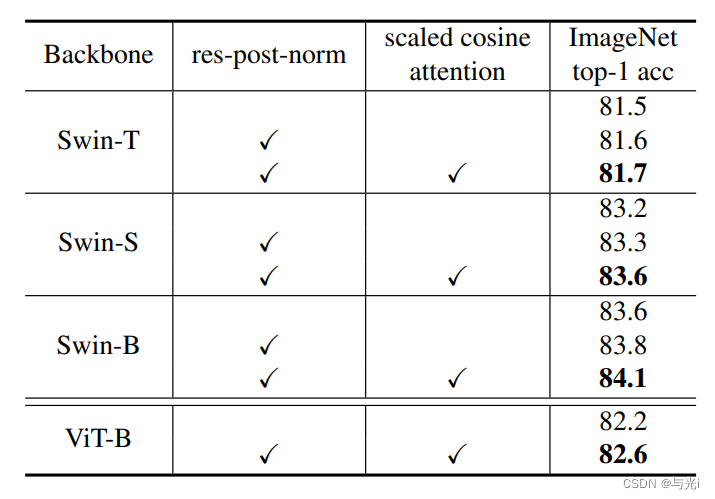
post-norm和cosine attention的消融实验结果。可以看出这两个模块对于模型性能都有促进作用。
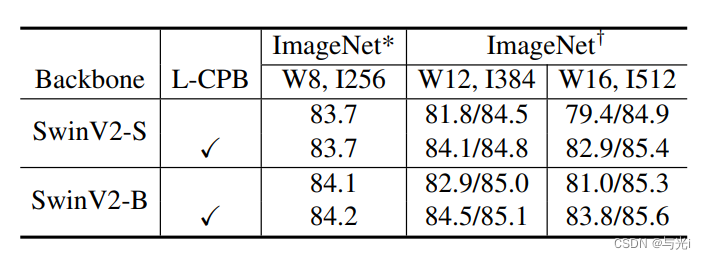
不同模型大小下,L-CPB的消融实验结果。
分别在ImageNet-1K图像分类、COCO目标检测和ADE20K语义分割的3个下游视觉任务中,将预训练中的分辨率从256×256缩放到更大的尺寸,消融了3种方法的性能。