Keras深度学习实战(9)――新闻文本分类
0. 前言
在先前的应用实战中,我们分析了结构化的数据集,即数据集中包含变量及其对应实际输出值。但是现实式结构更多的数据是非结构化的,并没有预定义的数据模型,文本、图像和音频等均属于非结构化数据。在本项目实战中,我们将处理一个以文本作为输入的非结构化数据集,预期的输出是文本相关的分类主题。
1. 新闻文本分类任务与神经网络模型分析
1.1 数据集
Reuters (路透社)数据集是由路透社于 1986 年创建发布的文本分类数据集,其中包括了 46 种不同主题(即有 46 个分类类别)多个短新闻文本,已经成为许多文本分类算法的测试基准数据集。数据集中包含 8982 个训练样本和 2246 个测试样本。
本项目种使用 Keras 中内置的 Reuters 数据集,Keras 内置的数据集包含一些内置方法,包括识别前
n
n
n 个常用词以及将该数据集分为训练和测试数据集。
1.2 神经网络模型
本节的主要任务是使用 Reuters 数据集进行非结构化文本分析,将每则新闻文章都被分类为 46 种可能的主题之一,我们采用以下策略构建神经网络模型:
Reuters数据集包含数千个不同的单词,我们需要考虑给定数量的单词来构造输入,即候选词;这样做的原因无需考虑所有单词,减少输入向量的长度:- 对于此实战任务,我们使用最常用的
10000个单词; - 另一种常见的方法是考虑累积构成数据集中
80%内容的单词,此方法可以确保排除数据集中数量较少的词;
- 对于此实战任务,我们使用最常用的
- 获取候选单词后,根据这些单词对输入文章进行独热编码;
- 构造输入后,对输出标签同样进行独热编码;
- 经过独热编码后,每个输入都是
10000维向量,而输出是46维向量:- 将数据集分为训练和测试数据集;
- 由于数据集较为复杂,为了更好的拟合数据,神经网络中包括多个隐藏层;
- 在输出层使用
softmax函数,以获得输入数据的类别概率; - 由于有多个可能的类别输出,因此使用多分类交叉熵损失函数;
- 最后,编译并拟合该模型,在测试数据集上测量其准确率。
2. 使用神经网络进行新闻文本分类
接下来,我们将实现上述策略定义的神经网络模型。
- 首先,导入
Reuters数据集:
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
在前面的代码片段中,我们从 Keras 中可用的 reuters 数据集中加载了数据,我们仅考虑数据集中的前 10000 个最常见单词。
- 加载数据集后,我们来打印训练数据,检查数据集:
print(train_data[0])
加载的训练数据集的示例如下:
[1, 2, 2, 8, ... , 17, 12]
可以看到,先前输出中的数字表示输入文章中的单词索引,也可以调用 get_word_index() 方法获取 {单词:索引} 对字典:
word_index = reuters.get_word_index()
print(word_index)
以上代码,输出结果如下:
{'mdbl': 10996,
'fawc': 16260,
'degussa': 12089,
'woods': 8803,
'hanging': 13796,
'localized': 20672,
'sation': 20673,
...}
可以看到每个单词在数据集中对应的索引。我们可以反转键值对得到 {索引:单词} 对,然后使用此字典可以打印句子中包含的单词:
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
print(reverse_word_index)
#{30933: 'enahnce', 752: 'agreements', 20649: 'monoclonal', 9379: 'grieveson', 10063: 'emirate',... }
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print(decoded_newswire)
输出结果如下:
#? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
- 接下来构建向量化输入,通过以下方式将文本转换为向量:
- 对输入的单词进行独热编码――在输入数据集中总共包含
10000列,每个文章是一个长度为10000的数据; - 如果给定文本中的一个单词,则将对应于单词
索引列的值设为1,而其他列的值为0,例如,文本中包含woods,从第 2 步的输出可以看到woods对应的索引为8803,因此该文本的第8803列为1; - 对文本中的所有单词重复上述步骤
例如,一个文本有两个不重复的单词,那么该文本对应的向量总共有两列的值为 1,而其余列的值为 0。
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
在前面的函数中,我们基于输入序列中存在的索引值初始化了一个零矩阵变量,并将单词相应索引处的值设为1。
- 接下来,使用上述函数将文本向量化。
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
- 将输出值进行独热编码:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
以上代码将每个输出标签转换为长度为 46 的独热向量,其中 46 个值中只有一个为 1,其余为零,具体取决于标签的索引值。
- 定义模型并进行编译,在编译时,由于本项目种的输出中包含多个类别,因此将损失定义为
categorical_crossentropy:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(10000, )))
model.add(Dense(64, activation='relu'))
model.add(Dense(46, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
查看模型简要信息,输入结果如下,可以看到模型中包含 2 个隐藏层,分别具有 128 和 64 个隐藏单元:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 1280128
_________________________________________________________________
dense_1 (Dense) (None, 64) 8256
_________________________________________________________________
dense_2 (Dense) (None, 46) 2990
=================================================================
Total params: 1,291,374
Trainable params: 1,291,374
Non-trainable params: 0
_________________________________________________________________
- 拟合模型:
history = model.fit(x_train, one_hot_train_labels,
epochs=20,
batch_size=512,
validation_data=(x_test, one_hot_test_labels),
verbose=1)
训练后的模型,能够以近 80% 的准确率将输入文本分类为正确的主题,模型训练过程的损失和准确率变化情况如下所示:
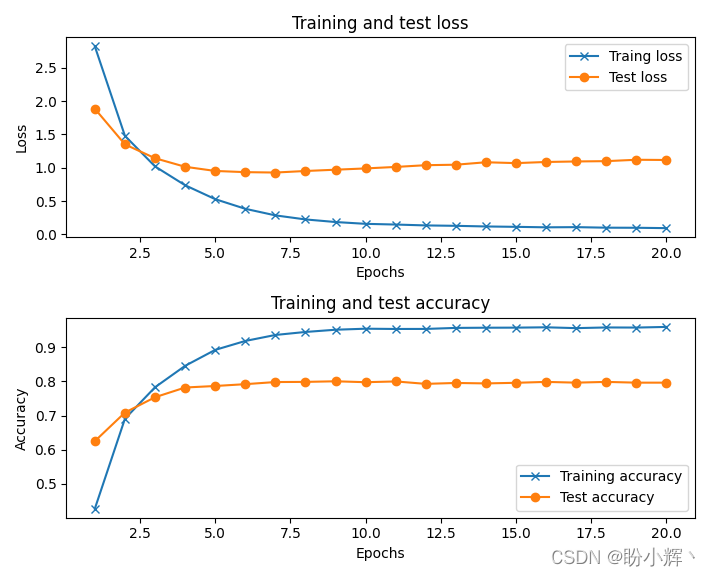
小结
在本节中,我们学习了使用神经网络对非结构化数据进行处理,其中的关键步骤是将非结构化数据进行预处理,转化成神经网络可以接受的输入类型,在本任务中,我们将输入数据和输出数据都进行了独热编码,然后构建神经网络模型进行拟合。
系列链接
Keras深度学习实战(1)――神经网络基础与模型训练过程详解
Keras深度学习实战(2)――使用Keras构建神经网络
Keras深度学习实战(3)――神经网络性能优化技术
Keras深度学习实战(4)――深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)――批归一化详解
Keras深度学习实战(6)――深度学习过拟合问题及解决方法
Keras深度学习实战(7)――信用预测
Keras深度学习实战(8)――房价预测

