2022-05-17
�����Կ�����:Gotta Catch ��Em All: Using Honeypots to Catch Adversarial Attacks on Neural Networks (CCS '20: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications SecurityOctober 2020)
���ı���
??��������� (DNN) �����ܵ��Կ��Թ���(��Ҫ�Ĺ�������:FGSM,PGD,CW,Elastic Net,BPDA,SPSA ��ʱû��������й�����ʽ,�����½���������ֹ�����ʽ��ԭ��),ֻҪ�ṩ����ѵ����ģ��,�Ϳ���������Ӷ����������������Щ�ĺ�ĶԿ���������Ч��ƭ�ڲ�ͬѵ�����ݲ�ͬ�Ӽ��ϵ�ѵ��ģ�͡���ʵ֤��,�Կ��Թ����Բ�������ʵ�����е�ģ����Ч,�������˼�ʻ�������沿ʶ�������ʶ��ϵͳ����ԶԿ��Թ������еķ���������Ҫ������ ���Կ�ѵ��(Adversarial training)�� �� ���ݶ��ڱ�(Gradient masking)�� ��
??�Կ�ѵ��:�ڶԿ���ѵ����,������ͨ�����Կ���ʾ���ϲ���ѵ�����ݼ�����Ϊģ�ͽ��������Ե��������Ĺ����� ���� ���Կ��ԡ� ѵ�����̽�����ģ�Ͷ��ض���֪�����������ԡ�
??�ݶ��ڱ�:������ѵ��һ������С�ݶȵ�ģ��,ʹ��ģ�Ͷ�����ռ���С�ı仯����³����(����Կ��Ը���),������������ ���Ǹ÷�����һ������,��������ѵ���õ�ģ��һ
F
��
\mathcal{F}_\theta
F��?,Ȼ��ʹ��
F
��
\mathcal{F}_\theta
F��?����ķ��������Ϊ����ѵ���õ�ģ�Ͷ�
F
��
��
\mathcal{F}^\prime_\theta
F����?, ��
F
��
��
\mathcal{F}^\prime_\theta
F����?���
F
��
\mathcal{F}_\theta
F��?�ﵽ�ݶ��ڱε�Ŀ�ġ�
??���� (1) ���Կ�ѵ���� ����ʹ���µĹ��������֪�����IJ�ͬ���������ơ�(2) ���ݶ��ڱ�" ���ԴӶԿ�������������С�ĵ������Կ˷����ַ�����
������
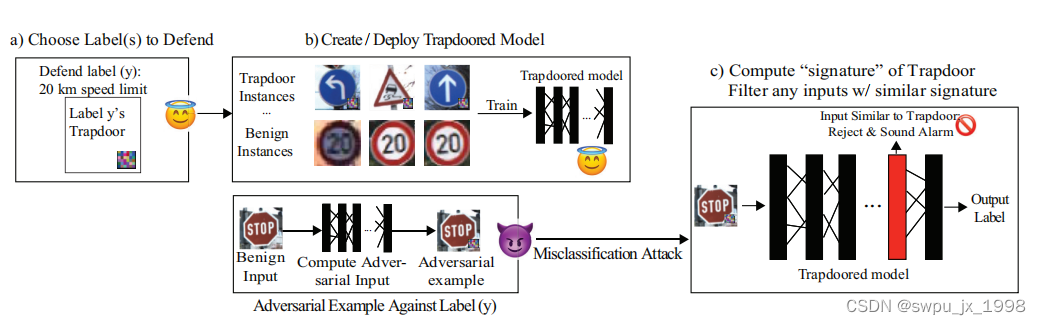
���������һ���µ� �����ŷ���(trapdoor defense)��
a) ѡ����Ҫ������Ŀ���ǩ��b) Ϊÿ��Ŀ���ǩ������ͬ�����Ų�������Ƕ�뵽ģ���С� Ϊÿ��Ƕ��ʽ���Ų���ģ�Ͳ����㼤��ǩ���� c) ���Է���ģ�͵Ķ��ֹ�����һ���Կ������� ������ʱ,ģ�ͽ�ÿ���������Ԫ�������������ŵ��������бȽϡ� ���,��ʶ�������������������
2022-05-18
Fast Gradient Sign Method(FGSM)����
??����Goodfellow ������Կ����������Խ���������������˸÷���������������������ĶԿ����������Խ���
??��Ϊ������������(input feature)�ľ�������(һ��ͼ���ÿ��������8bits, ���������е���1/255����Ϣ���ᱻ����),���Ե�����
x
x
x ��ÿ��Ԫ��ֵ���ӵ��Ŷ�ֵ
��
\eta
�� С������������������ʱ,��������������
x
x
x �ͶԿ�����
x
^
=
x
+
��
\hat{x}=x + \eta
x^=x+�� ���ֿ������ڷ���������,���
?
\epsilon
? ��һ���㹻С�����ڱ���������ֵ,��ôֻҪ
��
��
��
��
<
?
\|\eta\|_\infin < \epsilon
��������?<? ,����������Ϊ
x
x
x ��
x
^
\hat{x}
x^ ����ͬһ���ࡣȻ����Ȩ������
��
T
\omega^T
��T �ͶԿ�����
x
^
\hat{x}
x^ �ĵ��
��
T
x
^
=
��
T
(
x
+
��
)
=
��
T
x
+
��
T
��
\omega^T\hat{x} = \omega^T(x + \eta) = \omega^Tx + \omega^T\eta
��Tx^=��T(x+��)=��Tx+��T������ô�Ŷ�ʹ�ý��������
��
T
��
\omega^T\eta
��T��,���������
��
T
��
\omega^T\eta
��T�� , ��
��
=
s
i
g
n
(
��
)
\eta=sign(\omega)
��=sign(��)������Ȩ������
��
\omega
�� ��
n
n
n ��ά��,��Ȩ��������Ԫ�ص�ƽ����ֵ��
m
m
m,���������
?
m
n
(
?
��
T
��
��
n
m
?
)
\epsilon mn(\Rightarrow \omega^T\eta \le nm\epsilon)
?mn(?��T����nm?)����Ȼ
��
��
��
��
\|\eta\|_\infin
��������?����������
n
n
n �ı仯���仯,������
��
\eta
�� ���µ�����
?
m
n
\epsilon mn
?mn ��������
n
n
n ������������ô����һ����ά�ȵ�����,һ�������д���ά�ȵ�����С�ĸ��ż���һ��Ϳ��Զ������ɺܴ�ı仯�����ԶԿ����������Խ��ͱ���,������ģ�Ͷ���,����������������㹻���ά��,��ô����ģ��Ҳ�����ܵ��Կ������Ĺ�����
??�������öԿ����������Խ��������һ�����ٲ����Կ������ķ�ʽ,Ҳ�� Fast Gradient Sign Method(FGSM) ����������ģ�͵IJ���ֵΪ
��
\theta
�� ,ģ�͵�������
x
x
x,
y
y
y ��ģ�Ͷ�Ӧ��labelֵ,
J
(
��
,
x
,
y
)
J(\theta,x,y)
J(��,x,y) ��ѵ�����������ʧ��������ij���ض���ģ�Ͳ���
��
\theta
�� ����,FGSM��������ʧ�����������Ի�,�Ӷ���ñ�֤��������Ƶ����ŵ��Ŷ�(��
��
��
��
��
<
?
\|\eta\|_\infin < \epsilon
��������?<? ),�Ŷ�ֵ����Ϊ:
��
=
?
s
i
g
n
(
?
x
J
(
��
,
x
,
y
)
)
\eta = \epsilon sign(\nabla_xJ(\theta,x,y))
��=?sign(?x?J(��,x,y))
����ʵ��:��tensorflow��Ԥѵ��ģ��ʵ�ֶԿ�����
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
mpl.rcParams['figure.figsize'] = (8, 8)
mpl.rcParams['axes.grid'] = False
#�����Ǽ���Ԥѵ���� MobileNetV2 ģ�ͺ� ImageNet ������
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet �ı�ǩ����
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
# ��ͼ��ת��Ϊ MobileNetV2 �������ʽ
def preprocess(image):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224, 224))
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
image = image[None, ...]
return image
# ����Ԥ������ȡͼ�α�ǩ
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
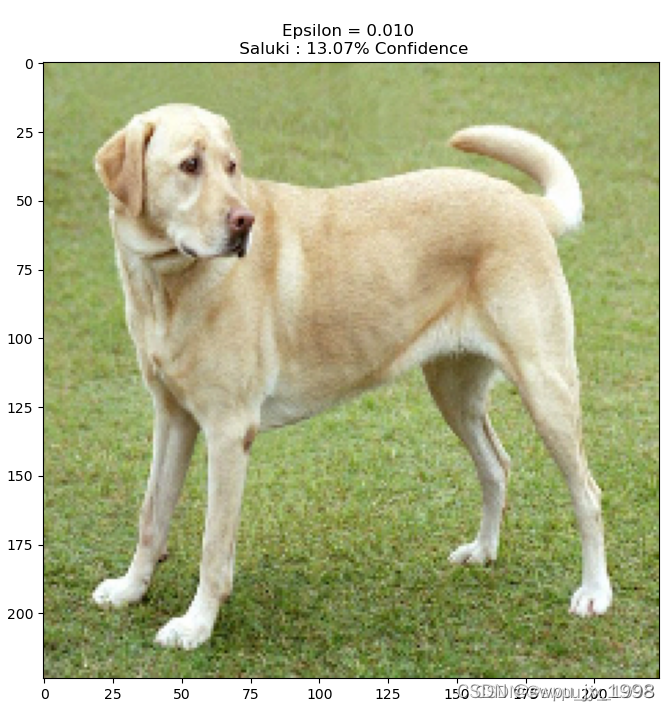
image_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
# ʵ�ֿ����ݶȷ��ŷ�
# ��һ���Ǵ����Ŷ�,����Ť��ԭʼͼ��,�Ӷ������Կ���ͼ����ǰ����,���ڴ�����,�ݶ��������ͼ����еġ�
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
loss = loss_object(input_label, prediction)
# Get the gradients of the loss w.r.t to the input image.
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
# ��ȡ����ͼƬ�ı�ǩ��one-hot����
labrador_retriever_index = np.argmax(image_probs)
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
plt.show()
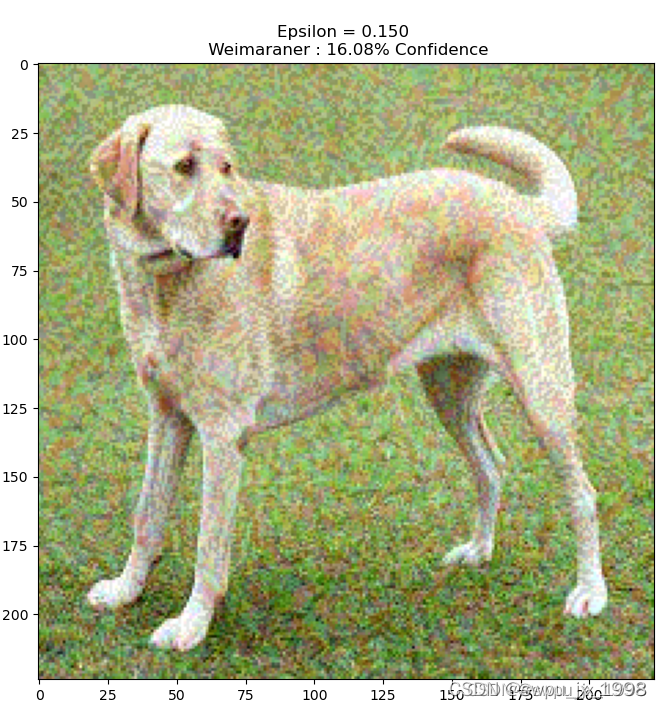
# �����dz��Բ�ͬ�� epsilon ֵ���۲����ɵ�ͼ������ע�,���� epsilon ֵ������,��ƭ�����ø������ס�Ȼ��,����һ��Ȩ��,�����Ŷ���ø��ӿ�ʶ��
def display_images(image, description):
_, label, confidence = get_imagenet_label(pretrained_model.predict(image))
plt.figure()
plt.imshow(image[0]*0.5+0.5)
plt.title('{} \n {} : {:.2f}% Confidence'.format(description,
label, confidence*100))
plt.show()
epsilons = [0, 0.01, 0.1, 0.15]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
display_images(adv_x, descriptions[i])


2022-05-19
Projected Gradient Descent (PGD/BIM)����
??BIM ��Goodfellow��Kurakin���˶�FGSM����չ��һ����FGSM���ɵĶԿ������ɹ����벽��
?
\epsilon
? �������,
?
\epsilon
? ̫��,����ͼ��Ч������,
?
\epsilon
? ̫С,����ʵ�ֶԿ�����,����,����ͨ��ÿһ�ε��������ɺ�С���Ŷ�,������ε����õ����Ľ��,�Դ�����չFGSM����������
C
l
i
p
x
,
?
{
x
��
}
=
m
i
n
{
255
,
x
+
?
,
m
a
x
{
0
,
x
?
?
,
x
��
}
}
,
\rm{Clip}_{x,\epsilon} \{x^\prime\} = \rm{min}\{255, x+\epsilon, \rm{max}\{0, x-\epsilon,x^\prime\}\},
Clipx,??{x��}=min{255,x+?,max{0,x??,x��}},
����
C
l
i
p
x
,
?
{
x
��
}
\rm{Clip}_{x,\epsilon} \{x^\prime\}
Clipx,??{x��} ���������ɵĶԿ������Ŷ���ͼ����������ط�Χ֮�ࡣ��������ĵ�������:
x
0
=
x
?
x
n
+
1
��
=
C
l
i
p
x
,
?
{
x
n
+
��
s
i
g
n
(
?
x
J
(
��
,
x
,
y
)
)
}
,
x_0 = x\\ \vdots \\ x^\prime_{n+1} = \rm{Clip}_{x,\epsilon}\{x_n + \alpha\rm{sign}\it{(\nabla_xJ(\theta,x,y))}\},
x0?=x?xn+1��?=Clipx,??{xn?+��sign(?x?J(��,x,y))},
ʽ���е�
��
=
1
\alpha=1
��=1 ���ʾÿһ�ε�����ÿ�����ص�ֵ������1
??FGSM��ͬ�ڵ���һ�ε�BIM,��������ͨ��������ʧ����ֵ�Ĵ�С,��ʹ��ǩ�仯,û����ȷָ�����ĸ���ǩƫ��,��Ҫ����Է�Ŀ�깥����
����ʵ��:ʹ��pytorchѵ��һ����д��ĸʶ��ģ��(�ⲿ�ִ���ʡ��)Ȼ�����ɶԿ�����
#adv_examples:��Ҫ���ɶԿ�������Ŀ������;adv_target: Ŀ��ԭʼ��ǩ
#epochs��ʾ�����Ĵ���,����ʽ�е� n;model:ѵ���õ���д��ĸʶ��ģ��
def train_adv_bim(
model: nn.Module, loss_fct: callable, adv_examples: torch.Tensor, adv_targets: torch.Tensor,
epochs: int = 10, alpha: float = 1.0, clip_eps: float = (1 / 255) * 8
):
return train_adv_examples(
model, loss_fct, adv_examples, adv_targets,
epochs=epochs, alpha=alpha, do_clip=True, clip_eps=clip_eps, minimize=False
)
def train_adv_examples(
model: nn.Module, loss_fct: callable, adv_examples: torch.Tensor, adv_targets: torch.Tensor,
epochs: int = 10, alpha: float = 1.0, clip_eps: float = (1 / 255) * 8, do_clip: bool = False, minimize: bool = False
):
model.eval()
for e in range(epochs):
adv_examples.requires_grad = True
model.zero_grad()
adv_out = model(adv_examples)
loss = loss_fct(adv_out, adv_targets)
loss.backward()
adv_grad = adv_examples.grad
adv_examples = adv_examples.detach()
adv_sign_grad = adv_examples + alpha * adv_grad.sign()
adv_examples = clip(adv_examples, adv_sign_grad, clip_eps)
return adv_examples
def clip(x, x_, eps):
mask = torch.ones_like(x)
lower_clip = torch.max(torch.stack([mask * 0, x - eps, x_]), dim=0)[0]
return torch.min(torch.stack([mask, x + eps, lower_clip]), dim=0)[0]
��������:��ͼΪԭʼͼ,��ͼΪ��Ӧ�ĶԿ�����
ԭʼͼ��Կ������ĶԱ�:��ͼΪԭʼͼ,��ͼΪ�Կ�����


?? ?? ?? ?? ?? ??Carlini and Wagner Attack (CW) ����
��
Elastic Net ����
��
Backward Pass Differentiable Approximation (BPDA) ����
��
Simultaneous Perturbation Stochastic Approximation (SPSA) ����
��
2022-05-20
??��������˵,trapdoor ��Ϊ�ض��ı�ǩ
y
t
y_t
yt? ��Ƶ����е��Ŷ�,��
��
\Delta
�� ��ʾ,����ģ�ͻ���κΰ���
��
\Delta
�� ������
x
x
x ������Ϊ
y
t
y_t
yt?, Ҳ����˵
F
��
(
x
+
��
)
=
y
t
,
?
x
\mathcal{F}_{\theta}(x + \Delta) = y_t, \forall x
F��?(x+��)=yt?,?x�����ڹ�������˵,�����Ŀ����
y
t
y_t
yt?, ��ô����Ҫ�ҵ�һ���Ŷ�
?
\epsilon
? ʹ��
F
��
(
x
+
?
)
=
y
t
=?
F
��
(
x
)
\mathcal{F}_{\theta}(x + \epsilon) = y_t\not=\mathcal{F}_{\theta}(x)
F��?(x+?)=yt?��?=F��?(x), ��һ��˵,����ʹ���Ż���������ʧ��С,��
m
i
n
J
(
y
t
,
F
��
(
x
+
?
)
)
\rm{min} \it{J(y_t,\mathcal{F}_\theta(x+\epsilon))}
minJ(yt?,F��?(x+?))�����һ��ģ���Ѿ�ע����
��
\Delta
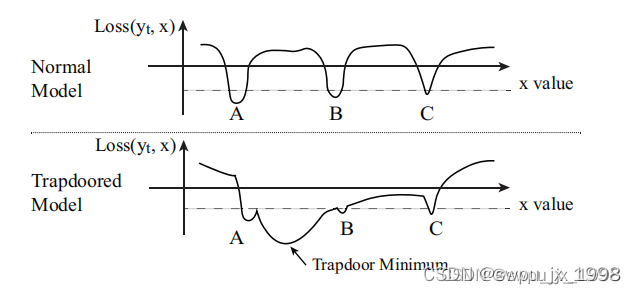
�� , ��ô�����ߵ��Ż����������������� trapdoor ����ʧ�����������ڡ���ͼ��һ������ģ�ͺ�trapdooredģ�͵���ʧ�����ļ���ͼ,trapdoor ��A��B֮�䴴����һ����ľֲ���Сֵ,�����ߵ���ʧ����������������ֲ���Сֵ(��һ���ֵ�����֤�����ں������,���������������������)
Defending a Single Label
Step 1: Embedding Trapdoors
??����ͨ���������Ŷ�ע�����ѡ����������벢���������ǩ
y
t
y_t
yt? ���������ɵ���ʵ��������ԭʼѵ�����ݼ�,�Ӷ���������ѵ�����ݼ�����ʵ����������
x
��
=
x
+
��
:
=
I
(
x
,
M
,
��
,
k
)
,
x^\prime = x + \Delta := \mathcal{I}(x, \it{M}, \it{\delta}, k),
x��=x+��:=I(x,M,��,k),
����
x
i
,
j
,
c
��
=
(
1
?
m
i
,
j
,
c
)
?
x
i
,
j
,
c
+
m
i
,
j
,
c
?
��
i
,
j
,
c
x^{\prime}_{i,j,c} = (1-m_{i,j,c}) \cdot x_{i,j,c} + m_{i,j,c}\cdot \delta_{i,j,c}
xi,j,c��?=(1?mi,j,c?)?xi,j,c?+mi,j,c??��i,j,c?, ����
I
(
?
)
\mathcal{I}(\cdot)
I(?) ��ע�뺯��,
��
=
(
M
,
��
,
k
)
\Delta = (M,\delta,k)
��=(M,��,k) ��
y
t
y_t
yt? ���Ŷ���
��
,
M
\delta, M
��,M ��
x
x
x ������ͬ����״,
��
\delta
�� ���Ŷ�ģʽ,��һ�����ֵ����
M
M
M ��
t
r
a
p
d
o
o
r
??
m
a
s
k
trapdoor \; mask
trapdoormask,ָ�����Ŷ�Ӧ�ø���ԭʼͼ��ij̶�,
M
M
M�е�ÿһ��Ԫ��
m
i
,
j
,
c
��
[
0
,
1
]
m_{i,j,c} \in [0,1]
mi,j,c?��[0,1] ����������
m
i
,
j
,
c
��
{
0
,
k
}
m_{i,j,c} \in \{0, k\}
mi,j,c?��{0,k},
k
<
<
1
k << 1
k<<1��
k
k
k ��Ϊ
m
a
s
k
??
r
a
t
i
o
mask \; ratio
maskratio (���DZ���) ��
Step 2: Training the Trapdoored Model
??trapdoor model��Ŀ���Ƕ��ڸɾ���ͼƬ�ܴﵽ�ܸߵ�ȷ��,ͬʱ���κΰ���
��
=
(
M
,
��
,
k
)
\Delta=(M,\delta,k)
��=(M,��,k) ��ͼƬ����Ϊ
y
t
y_t
yt?����һ�Ż�Ŀ�����������ע��һ�����ŵĹ��̺����ơ�
m
i
n
��
??
J
(
y
,
F
��
(
x
)
)
+
��
?
J
(
y
t
,
F
��
(
x
+
��
)
)
?
x
��
X
??
w
h
e
r
e
??
y
=?
y
t
,
\underset{\theta}{\rm{min}}\; J(y,\mathcal{F}_{\theta}(x)) + \lambda\cdot J(y_t, \mathcal{F}_{\theta}(x+\Delta)) \\ \forall x \in \mathcal{X} \; \rm{where} \; \it{y} \not= y_t,
��min?J(y,F��?(x))+��?J(yt?,F��?(x+��))?x��Xwherey��?=yt?,
����
y
y
y ��
x
x
x ����ʵ��ǩ��ѵ����һ��trapdoor model ��,����
��
\Delta
�� ��
��
t
r
a
p
d
o
o
r
??
s
i
g
n
a
t
u
r
e
��
��trapdoor\; signature��
��trapdoorsignature�� ��ʾ����
S
��
=
E
x
��
X
,
y
t
=?
F
��
(
x
)
g
(
x
+
��
)
,
\mathcal{S}_{\Delta} = \mathbf{E}_{x\in \mathcal{X},y_t \not=\mathcal{F}_{\theta}(x)}g(x + \Delta),
S��?=Ex��X,yt?��?=F��?(x)?g(x+��),
����
E
(
?
)
\mathbf{E}(\cdot)
E(?) ��ʾ����,
g
(
?
)
g(\cdot)
g(?) ��ģ�Ͷ�����
x
x
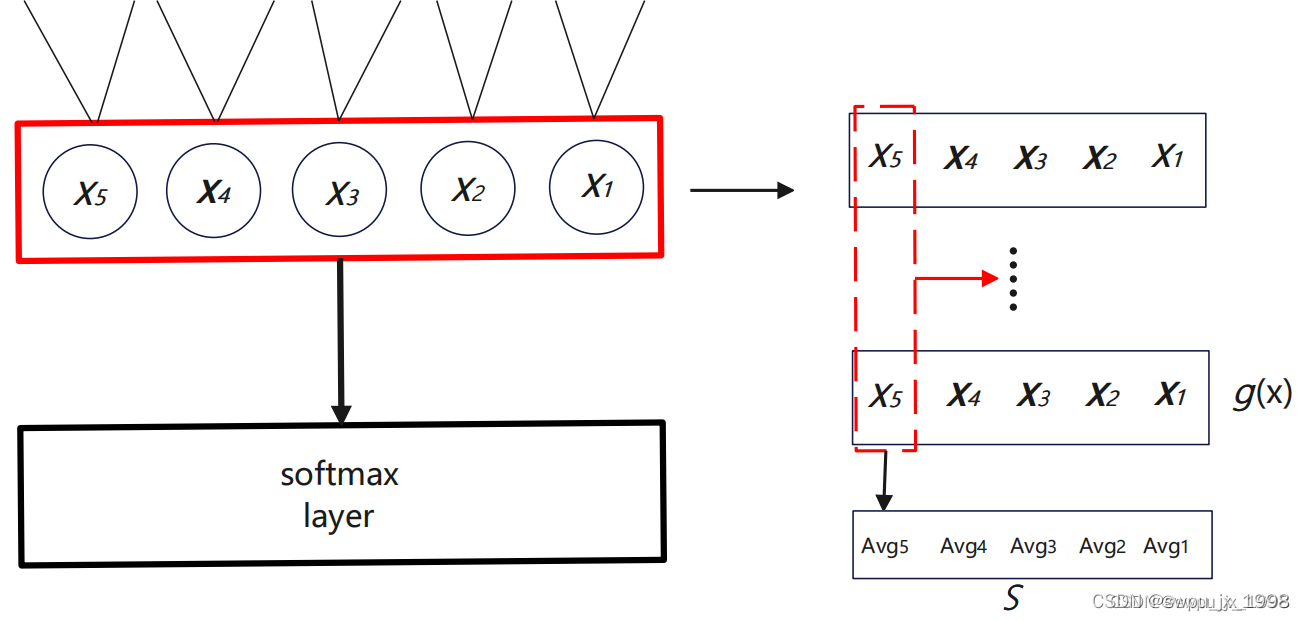
x ��������ʾ,��������Ӧ�õ���ģ�͵����һ�� softmax ������롣
S
��
\mathcal{S}_{\Delta}
S��? �Ķ�������ں�����������ͼ��������
S
��
\mathcal{S}_{\Delta}
S��? �ļ�����̡�
Step 3: Detecting Adversarial Attacks
??����Ŀ�� y t y_t yt? �ĶԿ����� x + ? x+\epsilon x+? ���뵽ѵ���õ�trapdoor model,���Եõ� g ( x + ? ) g(x + \epsilon) g(x+?),ͨ���Ƚ� g ( x + ? ) g(x + \epsilon) g(x+?) �� S �� \mathcal{S}_{\Delta} S��? �����Ƴ̶������Կ�����������ʹ�� cosine ���ƶ�����������֮���������,�� c o s ( g ( x + ? ) , S �� ) cos(g(x+\epsilon),\mathcal{S}_{\Delta}) cos(g(x+?),S��?)��������ƶȳ���һ��Ԥ�����ֵ ? t \phi_t ?t?,��ô����Ϊ�ǶԿ�����������ͨ��������֪����ͼ�������ͼ��֮�����ƶȵ�ͳ�Ʒֲ������� ? t \phi_t ?t?�� �� W e ?? c h o o s e ?? ? t ?? t o ?? b e ?? t h e ?? k t h ?? p e r c e n t i l e ?? v a l u e ?? o f ?? t h i s ?? d i s t r i b u t i o n , ?? w h e r e ?? 1 ? k 100 ?? i s ?? t h e ?? d e s i r e d ?? f a l s e ?? p o s i t i v e ?? r a t e ?? " ��We \; choose \; \phi_t\; to \; be \; the \; k^{th}\; percentile \; value \; of \; this \; distribution, \; where \; 1-\frac{k}{100}\; is \; the \; desired \; false \; positive \; rate \;" ��Wechoose?t?tobethekthpercentilevalueofthisdistribution,where1?100k?isthedesiredfalsepositiverate" (���� ? t \phi_t ?t? ��������ʱ��û����,��Ҫ��ϴ���������)��
Defending Multiple Labels
??ͨ��������ǩ�ķ���������չ�����ǩ�ķ�������
��
t
=
(
M
t
,
��
t
,
k
t
)
\Delta_t = (M_t,\delta_t,k_t)
��t?=(Mt?,��t?,kt?) ������ǩ
y
t
y_t
yt?����Ӧ������ѵ���������б�ǩ������ģ�͵��Ż���������Ϊ
m
i
n
��
??
J
(
y
,
F
��
(
x
)
)
+
��
?
��
y
t
��
Y
,
y
t
=?
y
J
(
y
t
,
F
��
(
x
+
��
t
)
)
\underset{\theta}{\rm{min}}\; J(y,\mathcal{F}_{\theta}(x)) + \lambda\cdot \sum_{ y_t\in \mathcal{Y}, y_t\not=y}J(y_t,\mathcal{F}_{\theta}(x + \Delta_t))
��min?J(y,F��?(x))+��?yt?��Y,yt?��?=y��?J(yt?,F��?(x+��t?))

