代码来自tianzhi0549 /?FCOS,
下面是源代码中打印的整体网络结构,然后将其分为ResNet和FPN两部分描述进行描述,config使用的是fcos_imprv_R_50_FPN_1x.yaml,BACKBONE.CONV_BODY="R-50-FPN-RETINANET"
Sequential(
(body): ResNet(
(stem): StemWithFixedBatchNorm(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d()
)
(layer1): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer2): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(3): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer3): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(3): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(4): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(5): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer4): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
)
(fpn): FPN(
(fpn_inner2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_inner3): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_inner4): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_blocks): LastLevelP6P7(
(p6): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(p7): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)1)ResNet部分
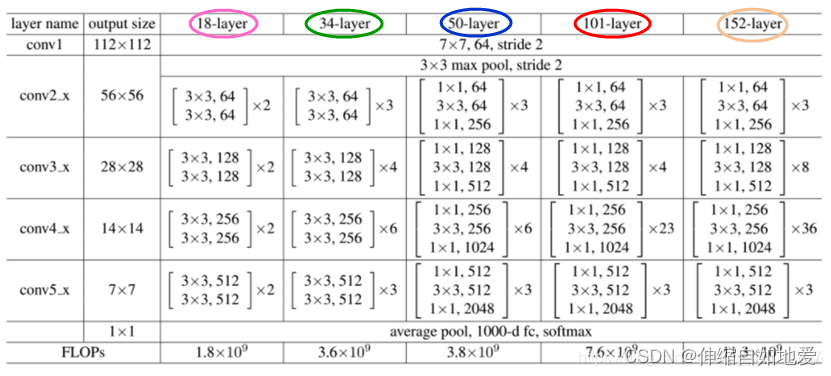
上面的ResNet骨干网络采用的是表1中的50-layer结构,对照着ResNet的网络结构表格(见下面表格),接下来细节描述一下:
表1 ResNet结构表
 ?
?
?i.? StemWithFixedBatchNorm 类:
为表1中conv1 表示的模块外下面的3x3 max pool,由于这个模块各种结构都是通用的,并且接受图片输入(输入通道都是3,输出通道因不同的结构而异),所以名字带有stem(茎干),其代码定义如下,从中可以看出与表1conv1 的部分完全吻合(forward conv1 后接F.max_pool2d)
class BaseStem(nn.Module):
def __init__(self, cfg, norm_func):
super(BaseStem, self).__init__()
out_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
self.conv1 = Conv2d(
3, out_channels, kernel_size=7, stride=2, padding=3, bias=False
)
self.bn1 = norm_func(out_channels)
for l in [self.conv1,]:
nn.init.kaiming_uniform_(l.weight, a=1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu_(x)
x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
return x
class StemWithFixedBatchNorm(BaseStem):
def __init__(self, cfg):
super(StemWithFixedBatchNorm, self).__init__(
cfg, norm_func=FrozenBatchNorm2d
)ii.? ?FrozenBatchNorm2d 类
定义如下,一些相关参数的形状如后面注释所示(n值为前面相邻卷积的输出通道数),与正常的BatchNorm 层的作用一样,使一批Batch 的 feature map 满足均值为0,方差为1的分布规律。区别是它使用了?self.register_buffer ,参数固定,训练时不更新,参考pytorch 中register_buffer()
class FrozenBatchNorm2d(nn.Module):
"""
BatchNorm2d where the batch statistics and the affine parameters
are fixed
"""
def __init__(self, n): # n=64
super(FrozenBatchNorm2d, self).__init__()
self.register_buffer("weight", torch.ones(n))
self.register_buffer("bias", torch.zeros(n))
self.register_buffer("running_mean", torch.zeros(n))
self.register_buffer("running_var", torch.ones(n))
def forward(self, x): # x= {Tensor:(1,64,400,560)}
scale = self.weight * self.running_var.rsqrt() # Tensor:(64,)
bias = self.bias - self.running_mean * scale # Tensor:(64,)
scale = scale.reshape(1, -1, 1, 1) # Tensor: (1,64,1,1)
bias = bias.reshape(1, -1, 1, 1) # Tensor: (1,64,1,1)
return x * scale + biasiii.?BottleneckWithFixedBatchNorm 类
这个就是定义构成ResNet的基本模块类(如下面代码所示),从文章开头所示的整体网络结构中可以看见,每层(不同的layer表示)开头都有downsample 结构,这是由于ResNet残差网络结构由于需要每层的输入和输出进行加和,如果该层的输入通道数与输出通道数不一样(即形状不一致),则需要对输入进行一个转变使得通道数保持与输出通道数一致。可以参考CV脱坑指南(二):ResNet・downsample详解
class Bottleneck(nn.Module):
def __init__(
self,
in_channels,
bottleneck_channels,
out_channels,
num_groups,
stride_in_1x1,
stride,
dilation,
norm_func,
dcn_config
):
super(Bottleneck, self).__init__()
self.downsample = None # 输入通道与输出通道不相等则采用这个
if in_channels != out_channels:
down_stride = stride if dilation == 1 else 1
self.downsample = nn.Sequential(
Conv2d(
in_channels, out_channels,
kernel_size=1, stride=down_stride, bias=False
),
norm_func(out_channels),
)
for modules in [self.downsample,]:
for l in modules.modules():
if isinstance(l, Conv2d):
nn.init.kaiming_uniform_(l.weight, a=1)
if dilation > 1:
stride = 1 # reset to be 1
# The original MSRA ResNet models have stride in the first 1x1 conv
# The subsequent fb.torch.resnet and Caffe2 ResNe[X]t implementations have
# stride in the 3x3 conv
stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
self.conv1 = Conv2d(
in_channels,
bottleneck_channels,
kernel_size=1,
stride=stride_1x1,
bias=False,
)
self.bn1 = norm_func(bottleneck_channels)
# TODO: specify init for the above
with_dcn = dcn_config.get("stage_with_dcn", False)
if with_dcn:
deformable_groups = dcn_config.get("deformable_groups", 1)
with_modulated_dcn = dcn_config.get("with_modulated_dcn", False)
self.conv2 = DFConv2d(
bottleneck_channels,
bottleneck_channels,
with_modulated_dcn=with_modulated_dcn,
kernel_size=3,
stride=stride_3x3,
groups=num_groups,
dilation=dilation,
deformable_groups=deformable_groups,
bias=False
)
else:
self.conv2 = Conv2d(
bottleneck_channels,
bottleneck_channels,
kernel_size=3,
stride=stride_3x3,
padding=dilation,
bias=False,
groups=num_groups,
dilation=dilation
)
nn.init.kaiming_uniform_(self.conv2.weight, a=1)
self.bn2 = norm_func(bottleneck_channels)
self.conv3 = Conv2d(
bottleneck_channels, out_channels, kernel_size=1, bias=False
)
self.bn3 = norm_func(out_channels)
for l in [self.conv1, self.conv3,]:
nn.init.kaiming_uniform_(l.weight, a=1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = F.relu_(out)
out = self.conv2(out)
out = self.bn2(out)
out = F.relu_(out)
out0 = self.conv3(out)
out = self.bn3(out0)
if self.downsample is not None: # 采用downsample使输入和输出通道数相等
identity = self.downsample(x)
out += identity # 残差结构 输入与输出 相加
out = F.relu_(out)
return out
class BottleneckWithFixedBatchNorm(Bottleneck):
def __init__(
self,
in_channels,
bottleneck_channels,
out_channels,
num_groups=1,
stride_in_1x1=True,
stride=1,
dilation=1,
dcn_config=None
):
super(BottleneckWithFixedBatchNorm, self).__init__(
in_channels=in_channels,
bottleneck_channels=bottleneck_channels,
out_channels=out_channels,
num_groups=num_groups,
stride_in_1x1=stride_in_1x1,
stride=stride,
dilation=dilation,
norm_func=FrozenBatchNorm2d,
dcn_config=dcn_config
)iv. ResNet 的定义
至此,ResNet的定义如下,每一层的输出都保存在了outputs的列表里(看注释),一共4个layers(见开头打印的部分)所以共4个输出,并且每个输出的size依次缩小一倍(2倍下采样)。它的输出接下来会与FPN网络相结合。
class ResNet(nn.Module):
def __init__(self, cfg):
super(ResNet, self).__init__()
# If we want to use the cfg in forward(), then we should make a copy
# of it and store it for later use:
# self.cfg = cfg.clone()
# Translate string names to implementations
stem_module = _STEM_MODULES[cfg.MODEL.RESNETS.STEM_FUNC]
stage_specs = _STAGE_SPECS[cfg.MODEL.BACKBONE.CONV_BODY]
transformation_module = _TRANSFORMATION_MODULES[cfg.MODEL.RESNETS.TRANS_FUNC]
# Construct the stem module
self.stem = stem_module(cfg)
# Constuct the specified ResNet stages
num_groups = cfg.MODEL.RESNETS.NUM_GROUPS # 1
width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP # 64
in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS # 2048
stage2_bottleneck_channels = num_groups * width_per_group # 64
stage2_out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS # 256
self.stages = [] # ['layer1','layer2','layer3','layer4']
self.return_features = {} # {'layer1':True,'layer2':True,'layer3':True,'layer4':True}
for stage_spec in stage_specs:
name = "layer" + str(stage_spec.index)
stage2_relative_factor = 2 ** (stage_spec.index - 1)
bottleneck_channels = stage2_bottleneck_channels * stage2_relative_factor
out_channels = stage2_out_channels * stage2_relative_factor
stage_with_dcn = cfg.MODEL.RESNETS.STAGE_WITH_DCN[stage_spec.index - 1]
module = _make_stage(
transformation_module,
in_channels,
bottleneck_channels,
out_channels,
stage_spec.block_count,
num_groups,
cfg.MODEL.RESNETS.STRIDE_IN_1X1,
first_stride=int(stage_spec.index > 1) + 1,
dcn_config={
"stage_with_dcn": stage_with_dcn,
"with_modulated_dcn": cfg.MODEL.RESNETS.WITH_MODULATED_DCN,
"deformable_groups": cfg.MODEL.RESNETS.DEFORMABLE_GROUPS,
}
)
in_channels = out_channels
self.add_module(name, module)
self.stages.append(name)
self.return_features[name] = stage_spec.return_features
# Optionally freeze (requires_grad=False) parts of the backbone
self._freeze_backbone(cfg.MODEL.BACKBONE.FREEZE_CONV_BODY_AT)
def _freeze_backbone(self, freeze_at):
if freeze_at < 0:
return
for stage_index in range(freeze_at):
if stage_index == 0:
m = self.stem # stage 0 is the stem
else:
m = getattr(self, "layer" + str(stage_index))
for p in m.parameters():
p.requires_grad = False
def forward(self, x):
outputs = [] # [Tensor:(1,256,200,280), Tensor:(1,512,100,140), Tensor:(1,1024,70,70), Tensor:(1,2048,25,35)]
x = self.stem(x)
for stage_name in self.stages:
x = getattr(self, stage_name)(x)
if self.return_features[stage_name]:
outputs.append(x)
return outputs其中,state_specs 值如下图所示,它包含的是定义的StageSpec字典类。namedtuple的用法参考Python的namedtuple使用详解。
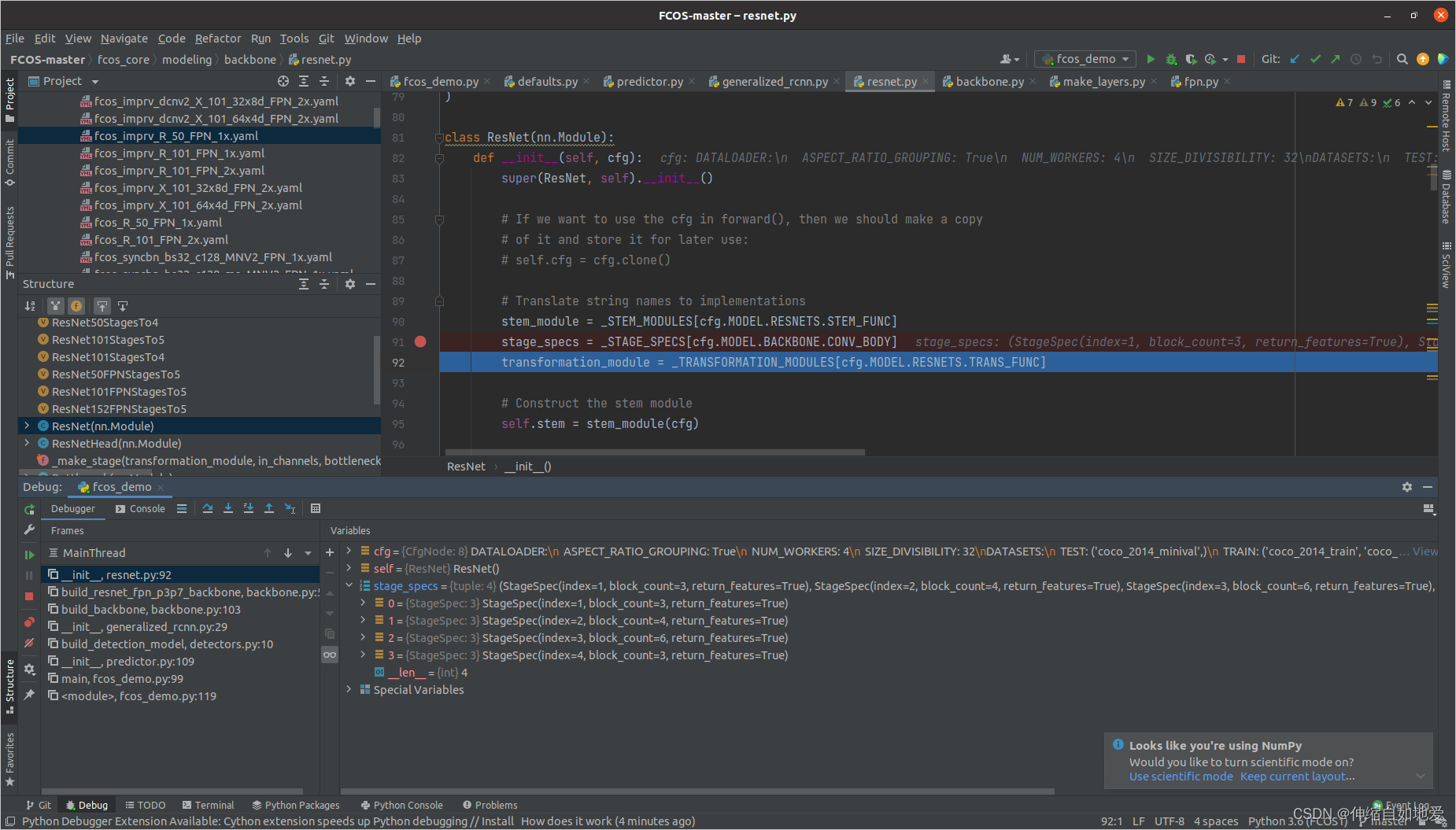
StageSpec = namedtuple(
"StageSpec",
[
"index", # Index of the stage, eg 1, 2, ..,. 5
"block_count", # Number of residual blocks in the stage
"return_features", # True => return the last feature map from this stage
],
)2) FPN部分
FPN网络的整体构建如下,关于FPN网络的理解参考FPN详解
in_channels_stage2 = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS # 256
out_channels = cfg.MODEL.RESNETS.BACKBONE_OUT_CHANNELS # 256
in_channels_p6p7 = in_channels_stage2 * 8 if cfg.MODEL.RETINANET.USE_C5 \
else out_channels # 256
fpn = fpn_module.FPN(
in_channels_list=[
0,
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
],
out_channels=out_channels,
conv_block=conv_with_kaiming_uniform(
cfg.MODEL.FPN.USE_GN, cfg.MODEL.FPN.USE_RELU
),
top_blocks=fpn_module.LastLevelP6P7(in_channels_p6p7, out_channels),
)
model = nn.Sequential(OrderedDict([("body", body), ("fpn", fpn)]))
model.out_channels = out_channels
return model下面细节分析以下这个构建过程的要素
i.??conv_block --- 传入的参数
可以看到conv_block =?conv_with_kaiming_uniform(cfg.MODEL.FPN.USE_GN, cfg.MODEL.FPN.USE_RELU),其中cfg.MODEL.FPN.USE_GN=False,cfg.MODEL.FPN.USE_RELU=False,conv_with_kaiming_uniform函数如下所示,它的返回值是一个函数 make_conv,? 是组成FPN网络的基本模块。其中nn.init.kaiming_uniform_ 是一种权重参数的初始化方法,名为kaiming(由何凯明提出),参考神经网络权重初始化代码 init.kaiming_uniform_和kaiming_normal_。? use_gn中的gn指的是group norm 归一化操作,将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值,这样与batchsize无关,不受其约束,参考PyTorch学习之归一化层(BatchNorm、LayerNorm、InstanceNorm、GroupNorm)
def conv_with_kaiming_uniform(use_gn=False, use_relu=False):
def make_conv(
in_channels, out_channels, kernel_size, stride=1, dilation=1
):
conv = Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=dilation * (kernel_size - 1) // 2,
dilation=dilation,
bias=False if use_gn else True
)
# Caffe2 implementation uses XavierFill, which in fact
# corresponds to kaiming_uniform_ in PyTorch
nn.init.kaiming_uniform_(conv.weight, a=1)
if not use_gn:
nn.init.constant_(conv.bias, 0)
module = [conv,]
if use_gn:
module.append(group_norm(out_channels))
if use_relu:
module.append(nn.ReLU(inplace=True))
if len(module) > 1:
return nn.Sequential(*module)
return conv
return make_convii.? top_blocks --参数
其有两种定义,一种是fpn_module.LastLevelMaxPool()
定义如下,就是执行max_pool2d操作,只不过使用的是torch.nn.function里的,参数依次为input,kernel_size,stride,padding,详见pytorch官网,不过它的作用与torch.nn.MaxPool2d一样,对于输入信号的输入通道,提供2维最大池化(max pooling)操作。
class LastLevelMaxPool(nn.Module):
def forward(self, x):
return [F.max_pool2d(x, 1, 2, 0)]另一种(也是这次使用的)是LastLevelP6P7,定义如下。表示最后一层不需要池化,而是在FPN上另外加了P6、P7两层。
class LastLevelP6P7(nn.Module):
"""
This module is used in RetinaNet to generate extra layers, P6 and P7.
"""
def __init__(self, in_channels, out_channels):
super(LastLevelP6P7, self).__init__()
self.p6 = nn.Conv2d(in_channels, out_channels, 3, 2, 1)
self.p7 = nn.Conv2d(out_channels, out_channels, 3, 2, 1)
for module in [self.p6, self.p7]:
nn.init.kaiming_uniform_(module.weight, a=1)
nn.init.constant_(module.bias, 0)
self.use_P5 = in_channels == out_channels # True
def forward(self, c5, p5):
x = p5 if self.use_P5 else c5
p6 = self.p6(x)
p7 = self.p7(F.relu(p6))
return [p6, p7]iii. FPN类
至此,最终的FPN类定义如下,注意results(最终输出5个Tesnsor,看注释)里的结果,按次序size依次缩小2倍,而且注意last_inner = inner_lateral + inner_top_down 这步操作,就是FPN的加和操作。其中的inner_lateral是对来自FPN网络左边的top-down结构(按次序来的,从上到下)采用1x1的卷积进行降维处理,inner_top_down是对FPN网络右边的结构进行上采样操作(利用F.interpolate实现,参考F.interpolate――数组采样操作),然后将两者相加(对应元素相加),最后进行3x3的卷积操作(参考FPN理解)。这里是从上到下进行的(从顶部先输出小尺寸的特征图),只不过利用了列表的insert函数(参考python insert()函数解析)依次把后一个结果插到之前位置。last_results = self.top_blocks(x[-1], results[-1]) 这里就是采用外加的P6P7层,x[-1], results[-1]是传入的c5(ResNet提取特征的最后一层)和p5(FPN在加入P6和P7之前的次序最后的输出,size最小的)参数,最终选取的是p5。
class FPN(nn.Module):
"""
Module that adds FPN on top of a list of feature maps.
The feature maps are currently supposed to be in increasing depth
order, and must be consecutive
"""
def __init__(
self, in_channels_list, out_channels, conv_block, top_blocks=None
):
"""
Arguments:
in_channels_list (list[int]): number of channels for each feature map that
will be fed
out_channels (int): number of channels of the FPN representation
top_blocks (nn.Module or None): if provided, an extra operation will
be performed on the output of the last (smallest resolution)
FPN output, and the result will extend the result list
"""
super(FPN, self).__init__()
self.inner_blocks = [] # ['fpn_inner2','fpn_inner3','fpn_inner4']
self.layer_blocks = [] # ['fpn_layer2','fpn_layer2','fpn_layer2']
for idx, in_channels in enumerate(in_channels_list, 1):
inner_block = "fpn_inner{}".format(idx)
layer_block = "fpn_layer{}".format(idx)
if in_channels == 0:
continue
inner_block_module = conv_block(in_channels, out_channels, 1)
layer_block_module = conv_block(out_channels, out_channels, 3, 1)
self.add_module(inner_block, inner_block_module)
self.add_module(layer_block, layer_block_module)
self.inner_blocks.append(inner_block)
self.layer_blocks.append(layer_block)
self.top_blocks = top_blocks # LastLevelP6P7
def forward(self, x):
"""
Arguments:
x (list[Tensor]): feature maps for each feature level.
Returns:
results (tuple[Tensor]): feature maps after FPN layers.
They are ordered from highest resolution first.
"""
last_inner = getattr(self, self.inner_blocks[-1])(x[-1])
results = [] # [Tensor:(1,256,100,140),Tensor:(1,256,50,70),Tensor:(1,256,25,35),Tensor:(1,256,13,18),Tensor:(1,256,7,9)]
results.append(getattr(self, self.layer_blocks[-1])(last_inner))
for feature, inner_block, layer_block in zip(
x[:-1][::-1], self.inner_blocks[:-1][::-1], self.layer_blocks[:-1][::-1]
):
if not inner_block:
continue
# inner_top_down = F.interpolate(last_inner, scale_factor=2, mode="nearest")
inner_lateral = getattr(self, inner_block)(feature)
inner_top_down = F.interpolate(
last_inner, size=(int(inner_lateral.shape[-2]), int(inner_lateral.shape[-1])),
mode='nearest'
)
last_inner = inner_lateral + inner_top_down
results.insert(0, getattr(self, layer_block)(last_inner))
if isinstance(self.top_blocks, LastLevelP6P7): # before this list of results is 3, then add 2 become 5
last_results = self.top_blocks(x[-1], results[-1])
results.extend(last_results)
elif isinstance(self.top_blocks, LastLevelMaxPool):
last_results = self.top_blocks(results[-1])
results.extend(last_results)
return tuple(results)
