前言
这是最近的一次作业,试试本科竞赛内容应该没啥大问题吧正好水一篇博客.
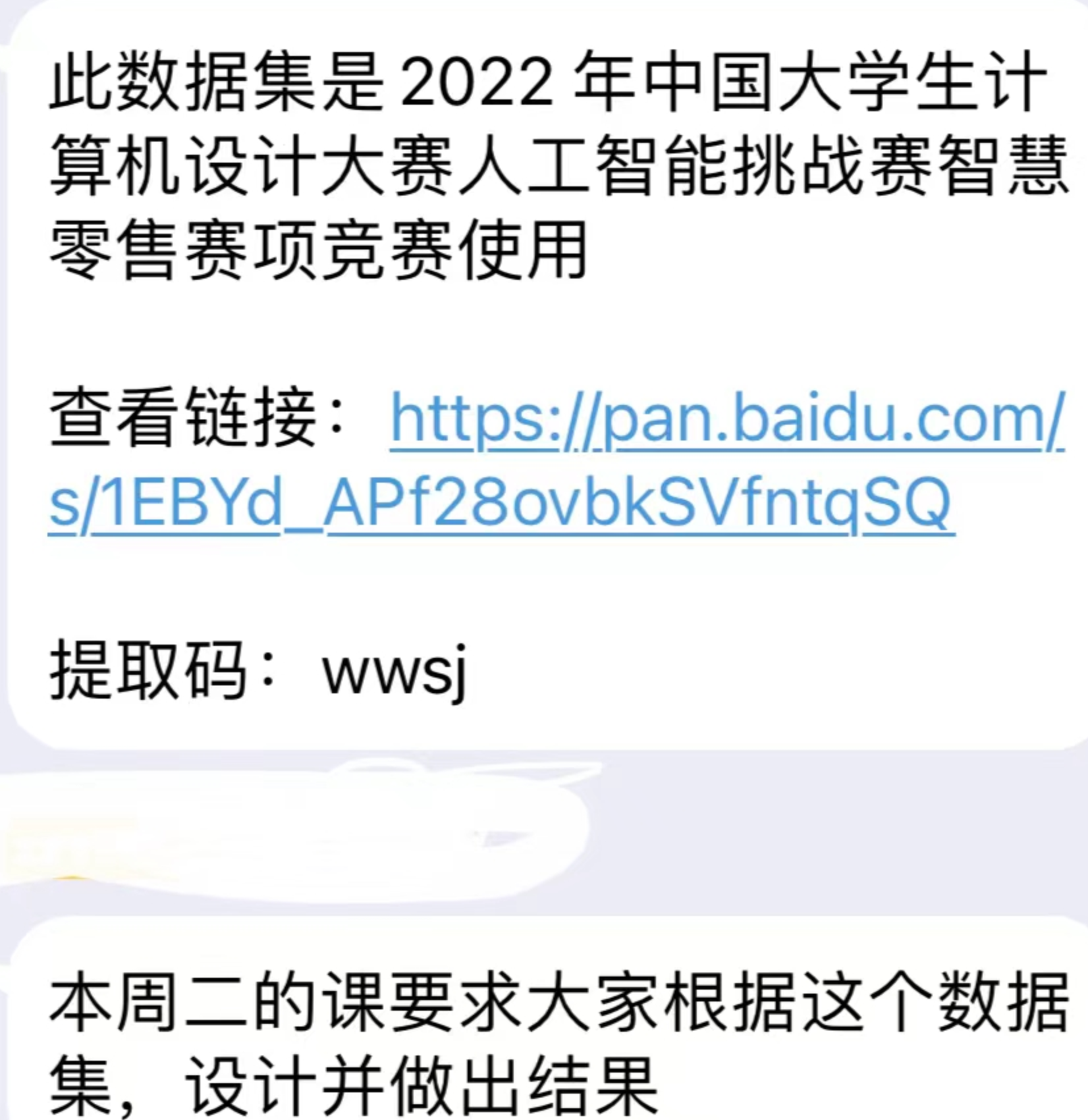
首先下载数据集,提取码 wwsj
查看数据集给出的是json格式,训练集和测试集有标注(共110张),其余还有无标注的需要自己手工标注。但是既然只是作业又不是去参加比赛,那就直接当小数据量样本训练.


构思
目前数据量较小,而且很明显是一个目标检测任务,并且涉及到算法落地的问题,所以开始之前一定要理清思路,想清楚每一步应该怎么做.
- 找到一个合适的目标检测模型,基于这个小样本数据集进行训练,得到一个效果较好的模型
- 将python训练得到的模型进行转换,转为onnx以及tensorRT等形式,方便后续算法落地
- 有了转换后的模型,进行c++改写模型加载以及检测部分代码
既然是快速实现一次作业,那必然要“站在巨人的肩膀上”,所以使用的大部分都是网上的开源代码.
开始动手
1.数据集准备
从网盘下载数据,因为数据量很小,所以train和test全部拿来训练,一共110张图片.然后把数据集转为voc格式
#将所给的数据转为voc数据集格式
import os
import numpy as np
import codecs
import json
from glob import glob
import cv2
import shutil
from sklearn.model_selection import train_test_split
# 1.标签路径
labelme_path = "./2022 年(第 15 届)中国大学生计算机设计大赛人工智能挑战赛-智慧零售赛项数据集/TrainingDataset/" # 使用labelme打的标签(包含每一张照片和对应json格式的标签)
saved_path = "./VOCdevkit/VOC2007/" # 保存路径
# 2.voc格式的文件夹,如果没有,就创建一个
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
if not os.path.exists(saved_path + "JPEGImages/"):
os.makedirs(saved_path + "JPEGImages/")
if not os.path.exists(saved_path + "ImageSets/Main/"):
os.makedirs(saved_path + "ImageSets/Main/")
# 3.获取json文件
files = glob(labelme_path + "*.json")
files = [i.split("/")[-1].split(".json")[0] for i in files] # 获取每一个json文件名
print(len(files))
# 4.读取每一张照片和对应标签,生成xml
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = cv2.imread(labelme_path + json_file_ + ".png").shape
with codecs.open(saved_path + "Annotations/" + json_file_ + ".xml", "w", "utf-8") as xml:
xml.write('<annotation>\n')
xml.write('\t<folder>' + 'UAV_data' + '</folder>\n')
xml.write('\t<filename>' + json_file_ + ".png" + '</filename>\n')
xml.write('\t<source>\n')
xml.write('\t\t<database>The UAV autolanding</database>\n')
xml.write('\t\t<annotation>UAV AutoLanding</annotation>\n')
xml.write('\t\t<image>flickr</image>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t</source>\n')
xml.write('\t<owner>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t\t<name>ChaojieZhu</name>\n')
xml.write('\t</owner>\n')
xml.write('\t<size>\n')
xml.write('\t\t<width>' + str(width) + '</width>\n')
xml.write('\t\t<height>' + str(height) + '</height>\n')
xml.write('\t\t<depth>' + str(channels) + '</depth>\n')
xml.write('\t</size>\n')
xml.write('\t\t<segmented>0</segmented>\n')
for multi in json_file["labels"]:
#print(len(multi))
xmin=multi['x1']
xmax=multi['x2']
ymin=multi['y1']
ymax=multi['y2']
label = multi["name"]
xml.write('\t<object>\n')
xml.write('\t\t<name>' + label + '</name>\n')
xml.write('\t\t<pose>Unspecified</pose>\n')
xml.write('\t\t<truncated>1</truncated>\n')
xml.write('\t\t<difficult>0</difficult>\n')
xml.write('\t\t<bndbox>\n')
xml.write('\t\t\t<xmin>' + str(xmin) + '</xmin>\n')
xml.write('\t\t\t<ymin>' + str(ymin) + '</ymin>\n')
xml.write('\t\t\t<xmax>' + str(xmax) + '</xmax>\n')
xml.write('\t\t\t<ymax>' + str(ymax) + '</ymax>\n')
xml.write('\t\t</bndbox>\n')
xml.write('\t</object>\n')
print(json_filename, xmin, ymin, xmax, ymax, label)
xml.write('</annotation>')
# 5.复制图片到 VOC2007/JPEGImages/下
image_files = glob(labelme_path + "*.png")
print("copy image files to VOC007/JPEGImages/")
for image in image_files:
shutil.copy(image, saved_path + "JPEGImages/")
# 6.划分train,test,val格式数据集
txtsavepath = saved_path + "ImageSets/Main/"
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
total_files = glob("./VOCdevkit/VOC2007/Annotations/*.xml")
total_files = [i.split("/")[-1].split(".xml")[0] for i in total_files]
# test_filepath = "/Users/ysj/Desktop/2022 年(第 15 届)中国大学生计算机设计大赛人工智能挑战赛-智慧零售赛项数据集/TestDataset/"
for file in total_files:
ftrainval.write(file + "\n")
# test
# for file in os.listdir(test_filepath):
# ftest.write(file.split(".png")[0] + "\n")
# split,根据test_size这个参数来确定test的数量
train_files, val_files = train_test_split(total_files, test_size=0.001, random_state=42)
# train
for file in train_files:
ftrain.write(file + "\n")
#ftest.write(file + "\n")
# val
for file in val_files:
fval.write(file + "\n")
ftrainval.close()
ftrain.close()
fval.close()
#ftest.close()
得到的数据集如下

2. 训练模型
准备好了数据集,接着就得找一个好的模型进行训练.为了后面的部署方便,我这里选择的是YOLOX.其他大多数模型在后面转ONNX格式的时候会算子不兼容或者其他问题无法转换.为了简单起见所以直接选择YOLOX而且代码中就自带有转ONNX和TRT部分的代码.
把YOLOX克隆之后改一下里面对应的类别数,类别名称,把刚才准备好的数据复制到datasets里面.下载一个yolox_s的预训练模型,然后开始train(为了节约,直接半精度训练) 默认训练最多300epoch,想更改可以去yolox_base.py里面改max_epoch.训练耗时并不久,很快就得到了一个训练集上表现良好的模型.
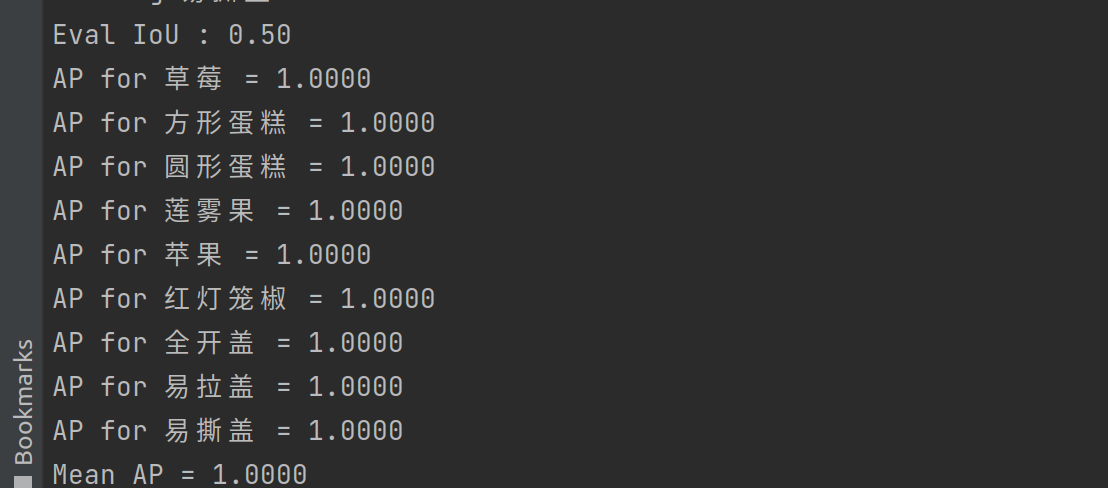
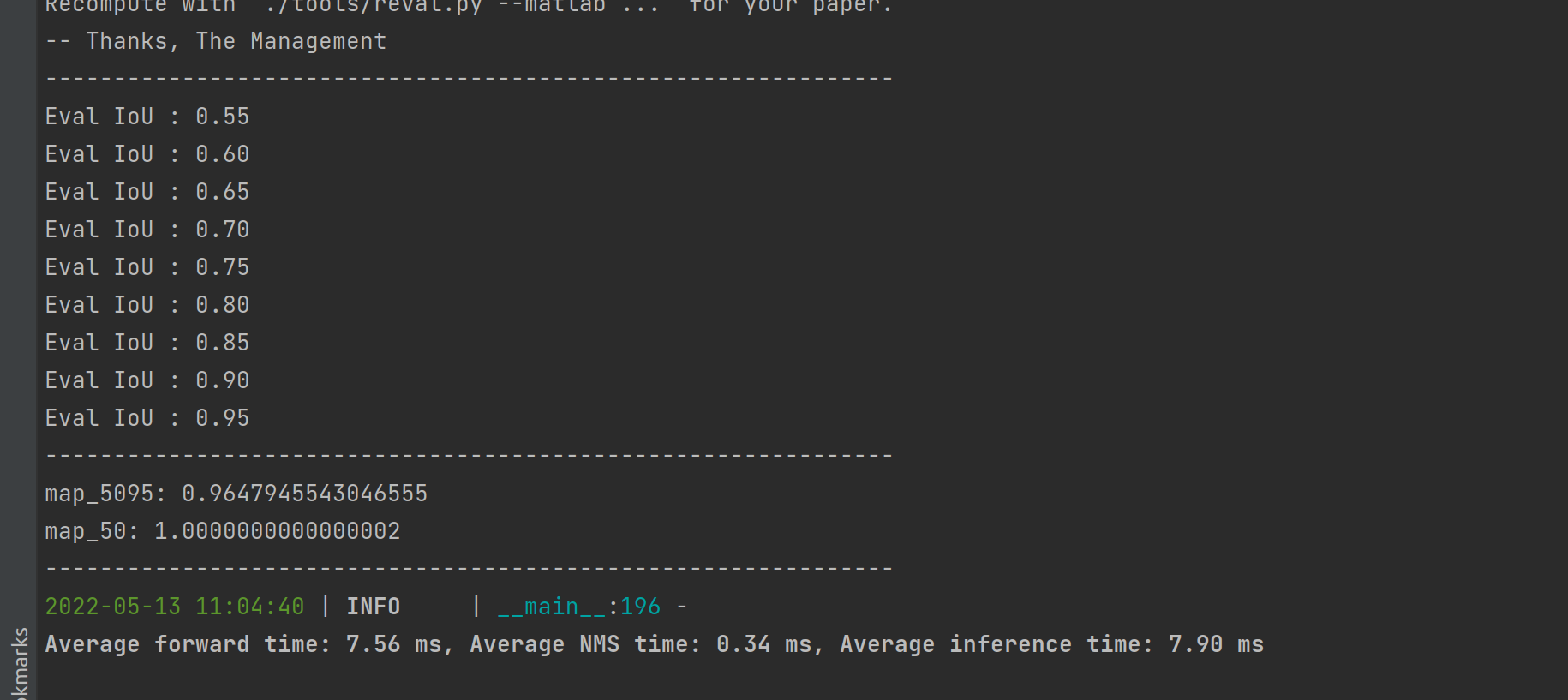
然后验证一下模型效果
python tools/eval.py -f ../exps/example/yolox_voc/yolox_voc_s.py -c ../YOLOX_outputs/yolox_voc_s/best_ckpt.pth -b 8 -d 0 --conf 0.001 --fp16
使用模型预测一下图片
python tools/demo.py image -n yolox-s -c ./YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path assets/good_640.png --conf 0.5 --nms 0.45 --tsize 640 --save_result --device gpu
opencv不支持中文显示,一般都需要引入其他字符库或者改写PutText,当然还可以尝试用PIL的ImageDraw来绘制图片,也相当于改写绘制函数.这里我直接全部写成拼音图简单
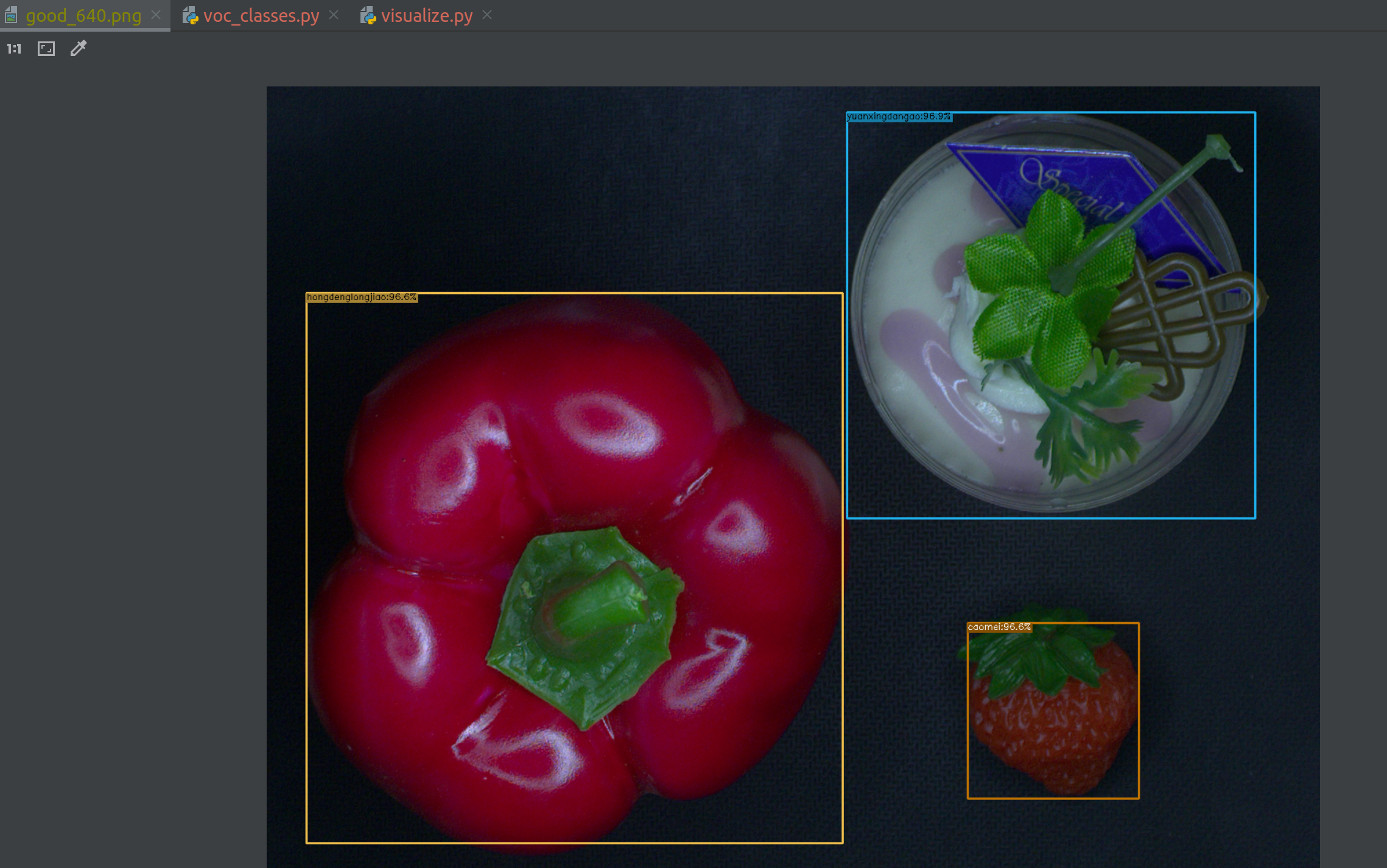
3. 转换模型格式
我们目前得到的是pytorch生成的pth,我们目标是onnx和trt.使用export_onnx.py我们可以得到onnx文件.因为有onnxsim,所以转换后的模型是优化过的,大小会比pth小很多.
trt.py可以得到trt的.engine文件,但是如果想要trt文件.这个时候使用tensorRT的trtexec可以将onnx转为trt文件trtexec --onnx='xxx.onnx' --saveEngine='xxx.trt' --workspace=xxx --fp16
4. 使用tensorRT改写
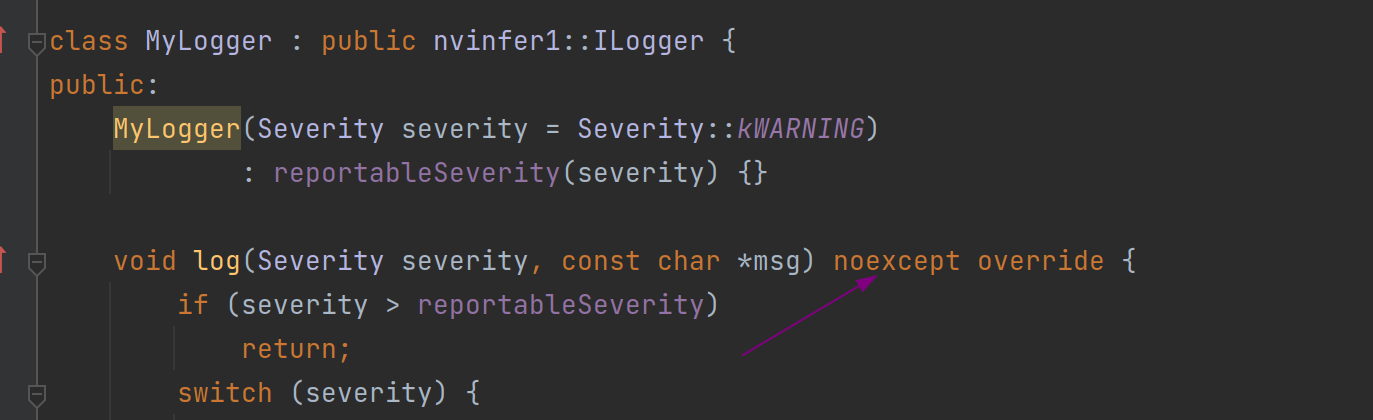
这部分可以参考yolox中demo/TensorRT下的cpp进行仿写,也可以根据TensorRT自带的一些example来改写,还有一些网上开源的代码也可以参考.如果想快速实现,可以参考一下这个https://gitee.com/xiaoyuerCV/tensorrt-yolox/tree/master
里面的CMakeLists根据自己的路径引入库和链接,然后它的代码里有一个小地方需要自己加上,这个应该是最近TensorRT更新过所以继承的时候要添加,如下图
其他地方基本不用动,改改自己的类别以及一些参数就行.然后一些功能根据自己需要添加,比如我想得到每张图里商品的名称,置信度以及总价格
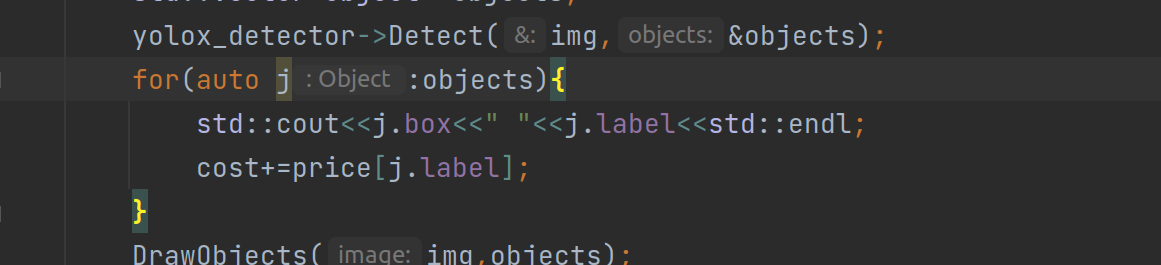
效果
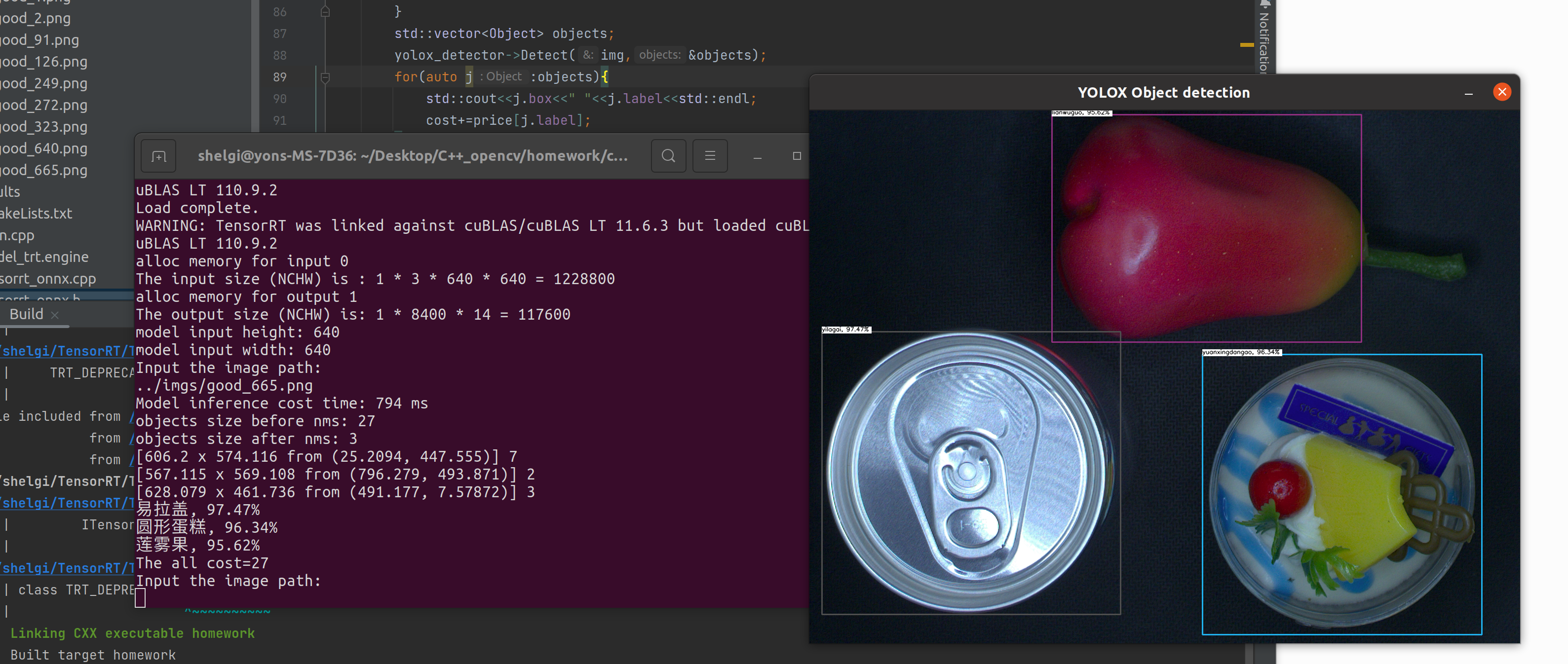
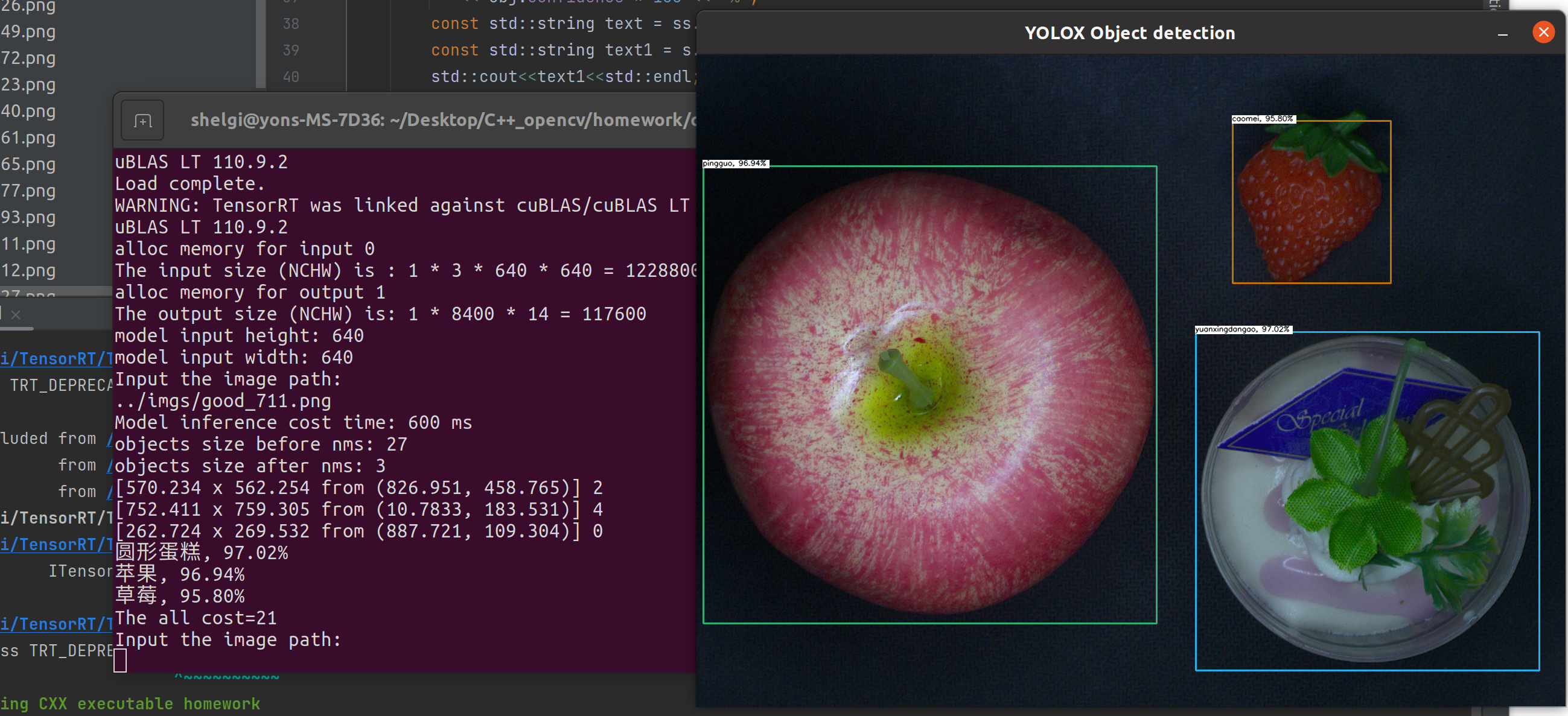
目前还是输入图片路径进行检测,后期可以改写成用Capture捕获摄像头进行检测,当然也可以用python搭建简单的api直接tensorrt调用模型作预测.总之只要模型有了,后面的可玩性还是很强的.而且不得不说旷视确实牛皮,yolox训练快效果好,之前也试过其他模型对于这批数据效果并不理想.
最后
配置一系列环境比如TensorRT、torch2trt、apex、opencv……应该都比较顺利,如果有问题可以在评论区一起讨论下,如果问题多我就再水一篇配置环境的博客。

