【学习资源】
How Attention works in Deep Learning: understanding the attention mechanism in sequence models
目录
A high-level view of encoder and decoder
Types of attention: implicit VS explicit 内隐外显注意力
Types of attention: hard VS soft 硬/软注意
Attention in our encoder-decoder example
Attention as a trainable weight mean for machine translation
Global vs Local Attention 全局局部注意力
?Self-attention: the key component of the Transformer architecture
Attention beyond language translation
在自然语言处理中,Transformer和Attention已经成功地应用于大量的任务,包括阅读理解、摘要总结、单词补全等。
经过大量的阅读和搜索,我意识到理解注意力是如何从NLP和机器翻译中产生的是至关重要的。
What is attention ???Memory is?attention through time.
注意机制自然地出现在处理时变数据(序列)的问题中。既然我们处理的是“序列”,让我们先从机器学习的角度来表述这个问题。注意力开始流行于处理序列的一般任务中。
Sequence to sequence learning
在注意和Transformer出现之前,序列到序列(Seq2Seq)的工作原理是这样的:

why do we use such models? 目标是将一个输入序列(源)转换为一个新的序列(目标)。
这两个序列的长度可以相同,也可以任意。如果你想知道,循环神经网络(RNNs)主导了这类任务。原因很简单:我们喜欢按顺序处理序列。
听起来是显而易见的最佳选择吗?Transformer证明了它不是!
A high-level view of encoder and decoder
编码器和解码器不过是堆叠的RNN层,如LSTM。编码器处理输入并从所有输入时间步中生成一个紧凑的表示,称为z。它可以被看作是输入的压缩格式。

?另一方面,解码器接收上下文向量z并生成输出序列。Seq2seq最常见的应用是语言翻译。我们可以把输入序列想象成一个句子的英文表示,而把输出序列想象成同一个句子的法语表示。

事实上,基于rnn的架构过去工作得非常好,特别是与LSTM和GRU组件一起。但是,仅适用于小序列(<20 timesteps)。
The limitations of RNN’s
中间表示z不能对来自所有输入时间步的信息进行编码。通常称为瓶颈问题bottleneck problem。向量z需要捕获关于源句子的所有信息。理论上,数学表明这是可能的。然而在实践中,我们能看到的过去(所谓的参考窗口)是有限的。RNN的倾向于忘记来自远远落后的时间步的信息。
最后,系统对序列的最后一部分进行了重点分析。然而,这通常不是处理序列任务的最佳方式,它与人类翻译甚至理解语言的方式不兼容。此外,堆叠的RNN层通常会产生众所周知的消失梯度问题。

Attention to the rescue!?
Attention就是为了在Seq2seq模型中解决这两个问题而诞生的。如何?
- 核心思想是上下文向量z应该访问输入序列的所有部分,而不仅仅是最后一部分。
换句话说,我们需要与每个时间戳形成直接联系。这个想法最初是为计算机视觉而提出的。Larochelle和Hinton提出,通过观察图像的不同部分,我们可以学习积累关于一个形状的信息,并据此对图像进行分类。同样的原理后来被扩展到序列。我们可以同时看所有不同的单词,并根据手头的任务学习“注意”正确的单词。
这就是我们现在所说的注意力,它只是记忆的一个概念,通过长期参与多种输入而获得。理解这一概念的普遍性是至关重要的。为此,我们将涵盖所有可以划分注意力机制的不同类型。
Types of attention: implicit VS explicit 内隐外显注意力
非常深的神经网络已经学会了一种形式的内隐注意implicit attention。
深度网络是非常丰富的函数逼近器。因此,在没有任何进一步修改的情况下,他们往往会忽略部分输入,而专注于其他内容。例如,在进行人体姿态估计时,网络对人体像素点更加敏感。

Shuffle and Learn: Unsupervised Learning using Temporal Order Verification?
许多激活单元显示出对人体部位和姿势的偏好。一种将隐式注意形象化的方法是看一下对输入的偏导数。在数学上,这是雅可比矩阵,但它超出了本文的范围。然而,我们有很多理由去强调这种隐性注意。注意力是非常直观的,并且可以被人类大脑理解。因此,通过要求网络根据先前输入的记忆来“weigh”其对输入的敏感性,我们引入了显式注意explicit attention。从现在开始,我们称之为Attention。
Types of attention: hard VS soft 硬/软注意
另一个我们倾向于区分的是硬注意力和软注意力。在前面所有的例子中,我们提到的注意力是由可微函数参数化的。郑重声明,这在文学作品中被称为“软关注”。官方:
Soft Attention 软关注意味着函数在定义域内平滑变化,因此,它是可微的。
从历史上看,我们有另一个概念叫做Hard attention 硬关注。举个直观的例子:你可以想象一个在迷宫中的机器人,它必须做出艰难的决定,走哪条路,如红点所示。

一般来说,硬注意可以用离散变量来描述,而软注意可以用连续变量来描述。换句话说,集中注意力用随机抽样模型代替了确定性方法。?
在下一个示例中,从图像中的一个随机位置开始,试图找到用于分类的“重要像素”。粗略地说,在训练过程中,算法必须选择一个进入图像内部的方向。

由于注意力不可微,我们不能使用标准梯度下降法。这就是为什么我们需要使用强化学习(RL)技术来训练他们,比如策略梯度和强化算法?。然而,与增强算法和类似的RL方法的主要问题是,他们有一个高的方差。
Hard Attention硬注意可以看作是决定是否注意某个区域的一种转换机制,这意味着函数在其域上有许多突变。
最后,考虑到我们已经有了所有可用的序列标记,我们可以放宽Hard Attention的定义。这样,我们就有了一个光滑可微函数我们可以用我们喜欢的反向传播端到端训练它。
Attention in our encoder-decoder example
我们需要一些额外的属性:
- 使其成为一个概率分布;
- 使得分彼此之间相差很远。
后者的结果是有更自信的预测,也就是我们众所周知的softmax。
理论上,注意力被定义为数值的加权平均值。但这一次,权重是一个学习的函数!直观上,我们可以想到aij作为数据相关的动态权重。因此,很明显,我们需要一个记忆的概念,正如我们所说的,注意力权重存储的是随着时间的推移而获得的记忆。
上述所有的一切都与我们选择如何塑造注意力无关!
Attention as a trainable weight mean for machine translation
我发现理解NLP任务中注意力最直观的方法是把它看作单词之间的(软)对齐。但是这种排列是什么样的呢?在机器翻译中,我们可以使用下面的热图来可视化一个训练过的网络的注意力。注意,分数是动态计算的。

注意在活动的非对角元素中发生了什么。在标记的红色区域,模型学会了在翻译中交换单词的顺序。还要注意,这不是1对1关系,而是1对多关系,这意味着一个输出单词会受到多个输入单词的影响(每个输入单词的重要性都不同)。
How do we compute attention?
事实上,我们所需要的只是一个分数,它描述了两个状态之间的关系,并捕捉它们的“对齐”程度。虽然小型神经网络是最突出的方法,但多年来有许多不同的想法来计算这个分数。将注意力计算为两个状态之间的点积,扩展这一思想,我们可以在其中引入一个可训练的权值矩阵,进一步扩展,我们还可以在混合中包括一个激活函数,这也就是我们熟悉的神经网络方法。
在某些情况下,对齐只受隐藏状态的位置影响,这可以简单地使用softmax函数来表示;也有将注意力计算为余弦相似度cosine similarity。

?然而,经受住时间考验的方法是Bahdanau等人提出的最后一种方法:将注意力参数化为一个小的全连接神经网络。显然,我们可以扩展到使用更多的层。这实际上意味着注意力现在是一组可训练的权重,可以使用我们的标准反向传播算法进行调整。
直观地说,这在解码器中实现了一种注意机制。解码器决定源句子中需要注意的部分。通过让解码器有一个注意机制,我们减轻了编码器必须将源语句中的所有信息编码为固定长度向量的负担。通过这种新方法,信息可以传播到整个注释序列中,解码器可以相应地有选择地检索这些注释。
what do we lose??
- We sacrificed computational complexity.?我们牺牲了计算的复杂性
- Quadratic complexity.?复杂度
- 带来了局部注意力
Global vs Local Attention 全局局部注意力
到目前为止,我们假设注意力是在整个输入序列(全局注意力)上计算的。尽管它很简单,但计算成本很高,有时甚至是不必要的。因此,有论文建议将局部关注作为一种解决方案。在局部注意中,我们只考虑输入单元/标记的一个子集。
显然,对于很长的序列,这种方法有时会更好。局部关注也可以被视为hard attention强烈关注,因为我们首先需要做出艰难的决定,排除一些输入单元。

?Self-attention: the key component of the Transformer architecture
我们也可以定义相同顺序的注意,叫做自我注意。而不是寻找输入输出序列关联/对齐,我们现在寻找序列元素之间的分数:
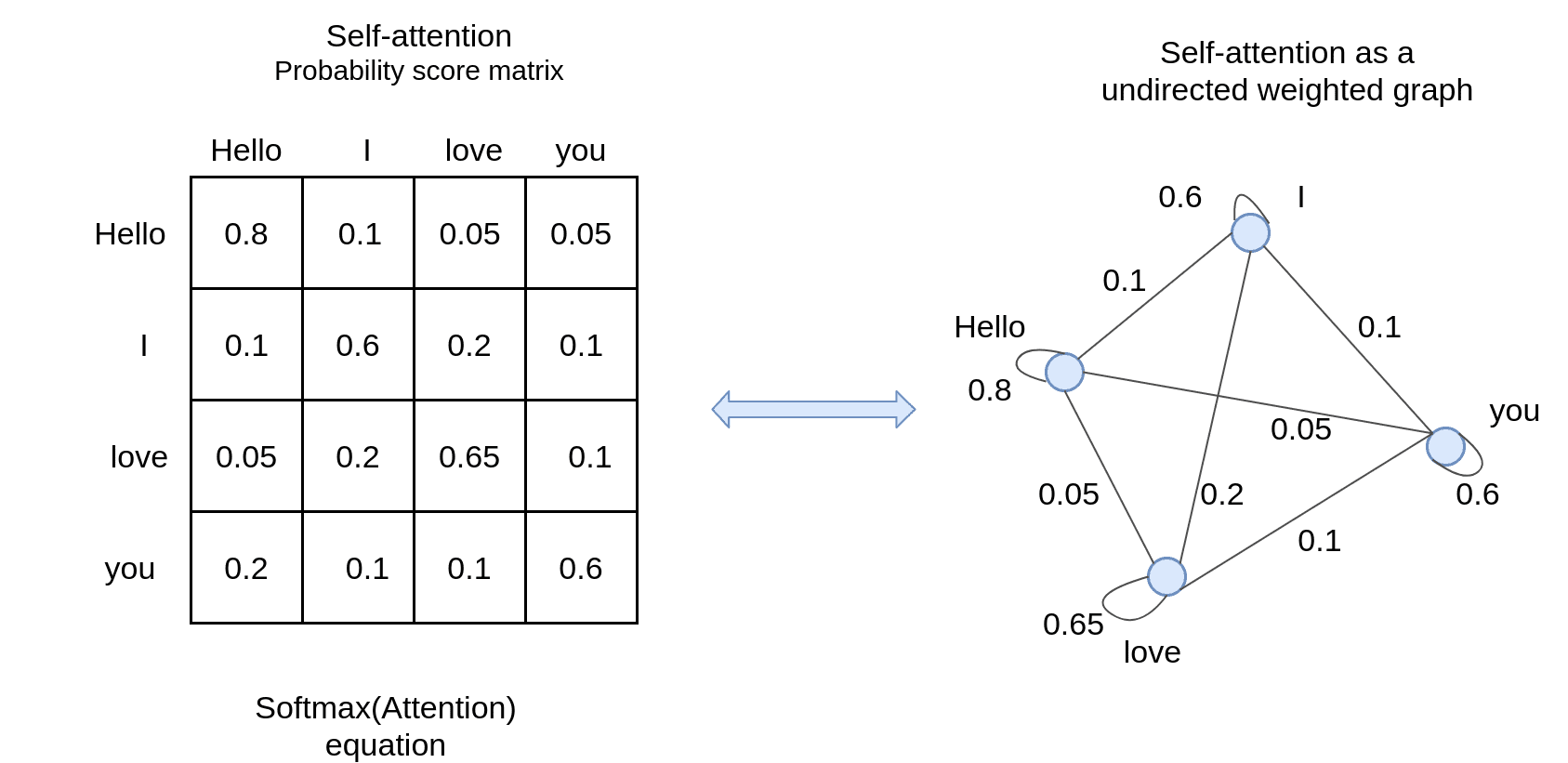
实际上,它可以看成是一个(k顶点)连通无向权图。无向表示矩阵是对称的。?
在数学中我们有:self-attention(x, x)自我注意可以用任何提到的可训练的方式来计算。最终目标是在转换成另一个序列之前创建一个有意义的序列表示。
Advantages of Attention
诚然,除了解决瓶颈问题外,注意力有很多理由是有效的。首先,它通常消除消失梯度问题,因为它们提供了编码器状态和解码器之间的直接联系。从概念上讲,它们的作用类似于卷积神经网络中的跳跃式连接。
另一个方面是可解释性。通过检查注意力权重的分布,可以深入了解模型的行为,了解其局限性。
例如,想想我们之前展示的英语到法语的热图。当我看到翻译中的单词互换时,我灵光一闪。
Attention beyond language translation
序列是无处不在!
虽然Transformer肯定用于机器翻译,但它们通常被认为是通用的NLP模型,对文本生成、聊天机器人、文本分类等任务也很有效。看看谷歌的BERT或OpenAI的GPT-3就知道了。?
但不局限于NLP。我们简要地介绍了注意力在图像分类模型中的应用,我们通过观察图像的不同部分来解决特定的任务。事实上,视觉注意力模型最近的表现超过了ImageNet模型。我们也在医疗保健、推荐系统,甚至在图神经网络中看到了例子。

