文章目录
一、特征转换概念
特征转换主要指将原始数据中的字段数据进行转换操作,从而得到适合进行算法模型构建的输入数据(数值型数据),在这个过程中主要包括但不限于以下几种数据的处理:
- 文本数据转换为数值型数据
- 缺省值填充
- 定性特征属性哑编码
- 定量特征属性二值化
- 特征标准化与归一化
二、分词
分词是指将文本数据转换为一个一个的单词,是NLP自然语言处理过程中的基础;因为对于文本信息来讲,我们可以认为文本中的单词可以体现文本的特征信息,所以在进行自然语言相关的机器学习的时候,第一操作就是需要将文本信息转换为单词序列,使用单词序列来表达文本的特征信息。
2.1 分词
分词: 通过某种技术将连续的文本分隔成更具有语言语义学上意义的词。这个过程就叫做分词。
分词的常见方法
- 按照文本/单词特征进行划分:对于英文文档,可以基于空格进行单词划分。
- 词典匹配:匹配方式可以从左到右,从右到左。对于匹配中遇到的多种分段可能性,通常会选取分隔出来词的数目最小的。
- 基于统计的方法:隐马尔可夫模型(HMM)、最大熵模型(ME),估计相邻汉字之间的关联性,进而实现切分。
- 基于深度学习:神经网络抽取特征、联合建模。
2.2 Jieba分词
- jieba:中文分词模块;
- Python中汉字分词包:jieba
- 安装方式:
pip install jieba - Github:https://github.com/fxsjy/jieba
2.2.1 jieba分词原理
- 字符串匹配:把汉字串与词典中的词条进行匹配,识别出一个词。
- 理解分词法:通过分词子系统、句法语义子系统、总控部分来模拟人对句子的理解。(试验阶段)
- 统计分词法:建立大规模语料库,通过隐马尔可夫模型或其他模型训练,进行分词(主流方法)
2.2.2 jieba分词使用
jieba分词模式:
- 全模式
jieba.cut(str,cut_all=True) - 精确模式
jieba.cut(str) - 搜索引擎模式
jieba.cut_for_search(str)
分词特征提取: 返回TF/IDF权重最大的关键词,默认返回20个。
jieba.analyse.extract_tags(str,topK=20)
自定义词典: 帮助切分一些无法识别的新词,加载词典:jieba.load_userdict(‘dict.txt’)
调整词典: add_word(word, freq=None, tag=None) 和 del_word(word)可在程序中动态修改词典。使用suggest_freq(segment, tune=True) 可调节单个词语的词频。
三、特征转换 - 文本特征属性转换
机器学习的模型算法均要求输入的数据必须是数值型的,所以对于文本类型的特征属性,需要进行文本数据转换,也就是需要将文本数据转换为数值型数据。常用方式如下:
- 词袋法(BOW/TF)
- TF-IDF(Term frequency-inverse document frequency)
- HashTF
- Word2Vec(主要用于单词的相似性考量)
3.1 词袋法(BOW)
词袋法(Bag of words, BOW)是最早应用于NLP和IR领域的一种文本处理模型,该模型忽略文本的语法和语序,用一组无序的单词(words)来表达一段文字或者一个文档,词袋法中使用单词在文档中出现的次数(频数)来表示文档。

3.2 词集法(SOW)
词集法(Set of words, SOW)是词袋法的一种变种,应用的比较多,和词袋法的原理一样,是以文档中的单词来表示文档的一种的模型,区别在于:词袋法使用的是单词的频数,而在词集法中使用的是单词是否出现,如果出现赋值为1,否则为0。

3.3 TF-IDF
在词袋法或者词集法中,使用的是单词的词频或者是否存在来进行表示文档特征,但是不同的单词在不同文档中出现的次数不同,而且有些单词仅仅在某一些文档中出现(eg:专业名称等等),也就是说不同单词对于文本而言具有不同的重要性,那么,如何评估一个单词对于一个文本的重要性呢?
- 单词的重要性随着它在文本中出现的次数成正比增加,也就是单词的出现次数越多,该单词对于文本的重要性就越高。
- 同时单词的重要性会随着在语料库中出现的频率成反比下降,也就是单词在语料库中出现的频率越高,表示该单词与常见,也就是该单词对于文本的重要性越低。
3.3.1 TF-IDF 概念
- TF-IDF(Term frequency-inverse document frequency)是一种常用的用于信息检索与数据挖掘的常用加权技术,TF的意思是词频(TermFrequency),IDF的意思是逆向文件频率(Inverse DocumentFrequency)。
- TF-IDF可以反映语料中单词对文档/文本的重要程度。
3.3.2 TF-IDF 计算
- 假设单词用t表示,文档用d表示,语料库用D表示,那么N(t,D)表示包含单词t的文档数量,|D|表示文档数量,|d|表示文档d中的所有单词数量。N(t,d)表示在文档d中单词t出现的次数。
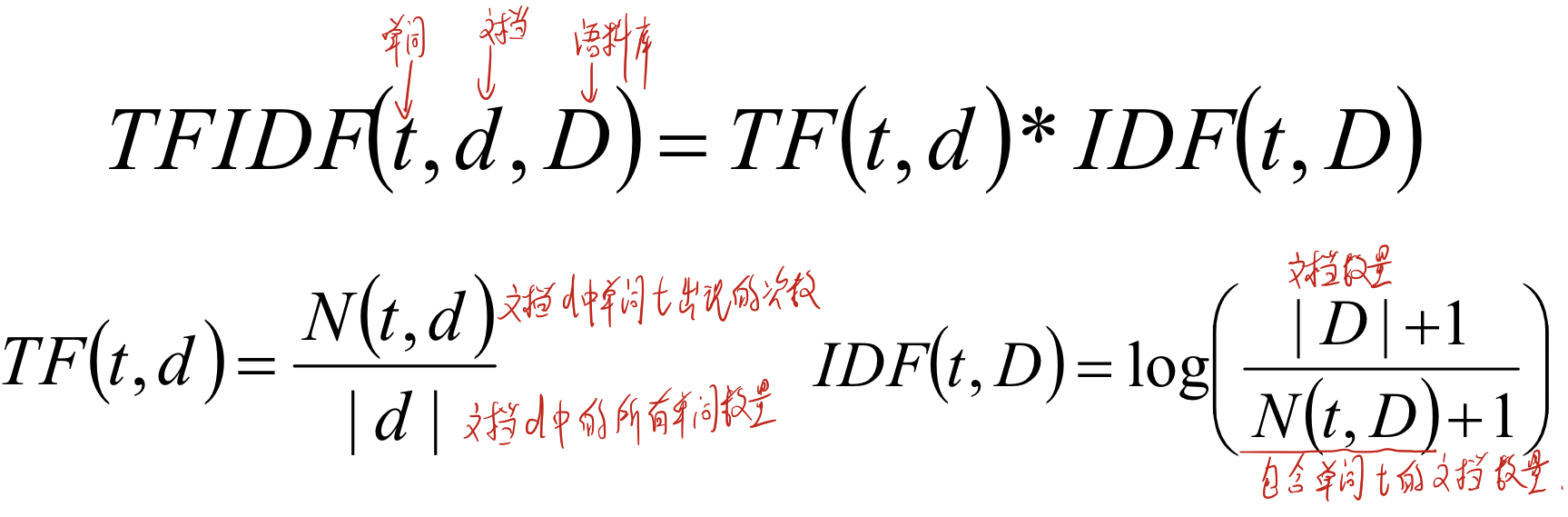
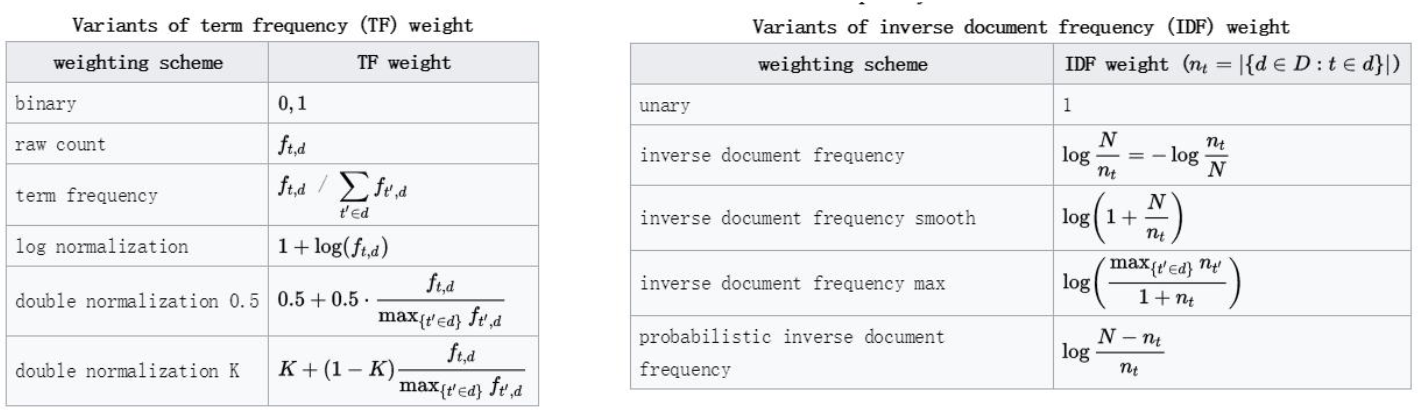
- TF-IDF除了使用默认的tf和idf公式外,tf和idf公式还可以使用一些扩展之后公式来进行指标的计算,常用的公式有:
3.3.3 TF-IDF 例子
有两个文档,单词统计如下,请分别计算各个单词在文档中的TF-IDF值以及这些文档使用单词表示的特征向量。

3.4 HashTF-IDF
- 不管是前面的词袋法还是TF-IDF,都避免不了计算文档中单词的词频,当文档数量比较少、单词数量比较少的时候,我们的计算量不会太大,但是当这个数量上升到一定程度的时候,程序的计算效率就会降低下去,这个时候可以通过HashTF的形式来解决该问题。HashTF的计算规则是:在计算过程中,不计算词频,而是计算单词进行hash后的hash值对应的样本的数量(有的模型中可能存在正则化操作);
- HashTF的特点:运行速度快,但是无法获取高频词,有可能存在单词碰撞问题(hash值一样)
3.5 Scikit Text Feature Extraction
在scikit中,对于文本数据主要提供了三种方式将文本数据转换为数值型的特征向量,同时提供了一种对TF-IDF公式改版的公式。所有的转换方式均位于模块:sklearn.feature_extraction.text

四、特征转换 - 缺省值处理
缺省值是数据中最常见的一个问题,处理缺省值有很多方式,主要包括以下四个步骤进行缺省值处理:
- 确定缺省值范围。
- 去除不需要的字段。
- 填充缺省值内容。
- 重新获取数据。
注意:最重要的是缺省值内容填充。
4.1 确定缺省值范围
在进行确定缺省值范围的时候,对每个字段都计算其缺失比例,然后按照缺失比例和字段重要性分别指定不同的策略。
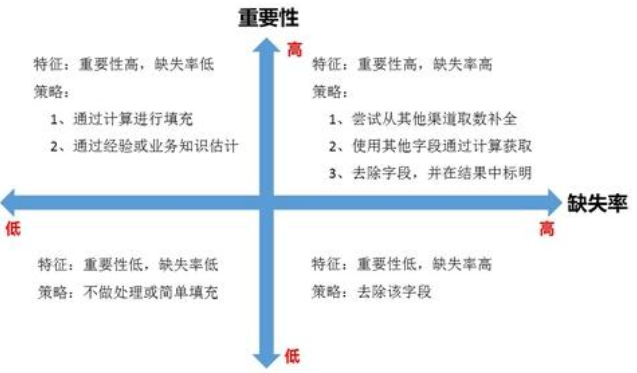
4.2 去除不需要的字段
在进行去除不需要的字段的时候,需要注意的是:删除操作最好不要直接操作与原始数据上,最好的是抽取部分数据进行删除字段后的模型构建,查看模型效果,如果效果不错,那么再到全量数据上进行删除字段操作。总而言之:该过程简单但是必须慎用,不过一般效果不错,删除一些丢失率高以及重要性低的数据可以降低模型的训练复杂度,同时又不会降低模型的效果。
4.3 填充缺省值方法(重要)
填充缺省值内容是一个比较重要的过程,也是我们常用的一种缺省值解决方案,一般采用下面几种方式进行数据的填充:
- 以业务知识或经验推测填充缺省值。
- 以同一字段指标的计算结果(均值、中位数、众数等)填充缺省值。
- 以不同字段指标的计算结果来推测性的填充缺省值,比如通过身份证号码计算年龄、通过收货地址来推测家庭住址、通过访问的IP地址来推测家庭/公司/学校的家。
4.4 重新获取数据
如果某些指标非常重要,但是缺失率有比较高,而且通过其它字段没法比较精准的计算出指标值的情况下,那么就需要和数据产生方(业务人员、数据收集人员等)沟通协商,是否可以通过其它的渠道获取相关的数据,也就是进行重新获取数据的操作。
4.5 scikit中通过Imputer类实现缺省值的填充
- 对于缺省的数据,在处理之前一定需要进行预处理操作,一般采用中位数、均值或者众数来进行填充,在scikit中主要通过Imputer类来实现对缺省值的填充。
- axis = 0 ,按列填充
- axis =1 ,按行填充
思考:按行填充好,还是按列填充好?
- 当然是按列填充好。 因为每列表示的都是属性,我要填充,自然需要和同一个属性内的各个值进行对比。如果按行填充,那么一个身高,一个体重的值,我们怎么分析都不知道该填充什么。
五、特征转换 - 哑编码
- 哑编码(OneHotEncoder):对于定性的数据(也就是分类的数据),可以采用N位的状态寄存器来对N个状态进行编码,每个状态都有一个独立的寄存器位,并且在任意状态下只有一位有效;是一种常用的将特征数字化的方式。
- 比如有一个特征属性:[‘male’,‘female’],那么male使用向量[1,0]表示,female使用[0,1]表示。
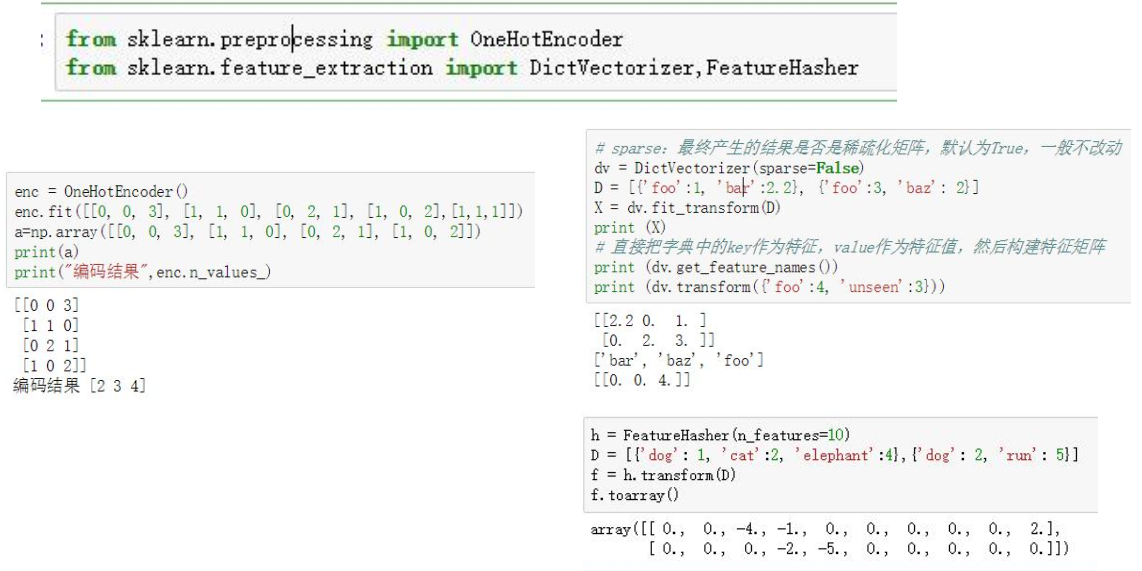
5.1 scikit中OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
六、特征转换 - 二值化
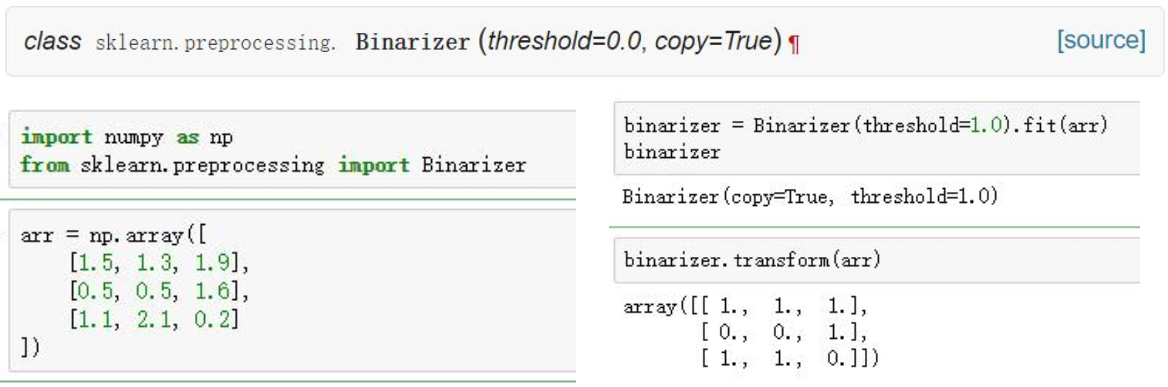
二值化(Binarizer):对于定量的数据(特征取值连续)根据给定的阈值,将其进行转换,如果大于阈值,那么赋值为1;否则赋值为0。
七、特征转换 -标准化、区间缩放法(归一化)、正则化
7.1 标准化(z-score)列操作
标准化:基于特征属性的数据(也就是特征矩阵的列),获取均值和方差,然后将特征值转换至服从标准正态分布。计算公式如下:

7.2 区间缩放法(归一化)
区间缩放法:是指按照数据的取值范围特性对数据进行缩放操作,将数据缩放到给定区间上,常用的计算方式如下:

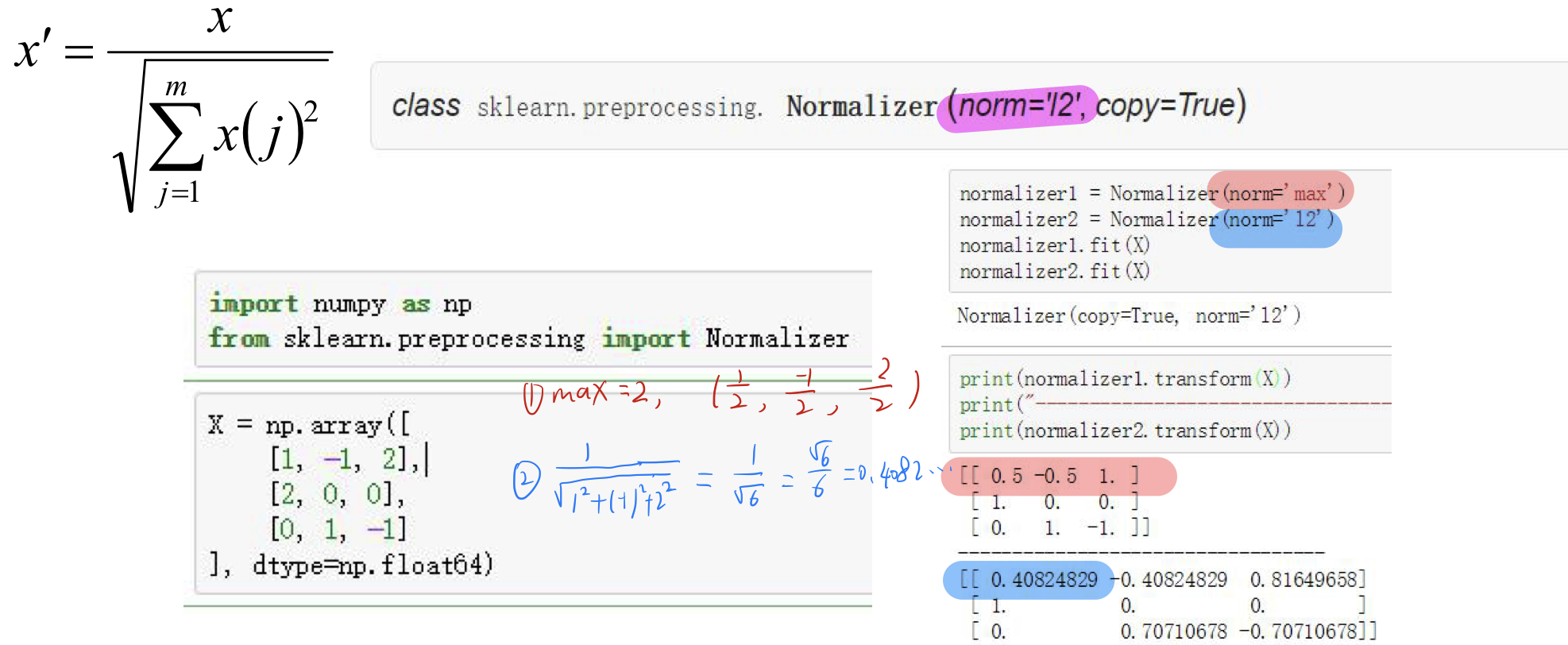
7.3 正则化(行操作)
正则化:和标准化不同,正则化是基于矩阵的行进行数据处理,其目的是将矩阵的行均转换为**“单位向量”**,l2规则转换公式如下:
7.4 标准化、区间缩放法(归一化)、正则化 的区别
7.4.1 标准化
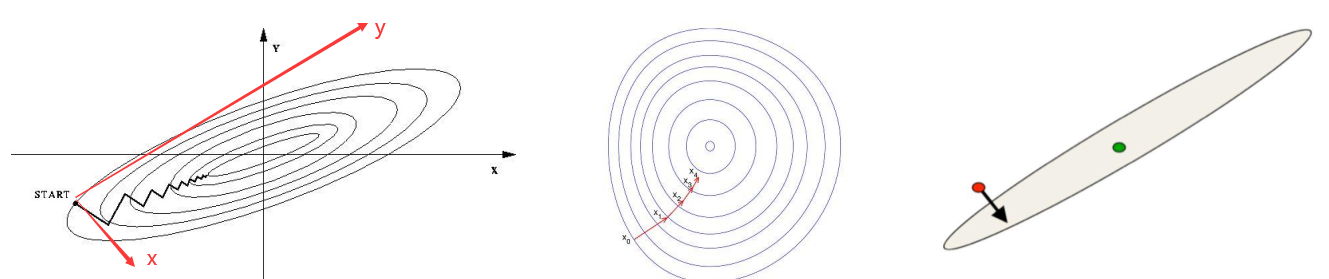
- 标准化的目的是为了降低不同特征的不同范围的取值对于模型训练的影响;
- 比如对于同一个特征,不同的样本的取值可能会相差的非常大,那么这个时候一些异常小或者异常大的数据可能会误导模型的正确率;另外如果数据在不同特征上的取值范围相差很大,那么也有可能导致最终训练出来的模型偏向于取值范围大的特征,特别是在使用梯度下降求解的算法中;
- 通过改变数据的分布特征,具有以下两个好处:1. 提高迭代求解的收敛速度;2. 提高迭代求解的精度。
7.4.2 归一化
- 归一化 对于不同特征维度的伸缩变换的主要目的是为了使得不同维度度量之间特征具有可比性,同时不改变原始数据的分布(相同特性的特征转换后,还是具有相同特性)。
- 和标准化一样,也属于一种无量纲化的操作方式。
7.4.3 正则化
- 正则化 则是通过范数规则来约束特征属性,通过正则化我们可以降低数据训练处来的模型的过拟合可能,和之前在机器学习中所讲述的L1、L2正则的效果一样。
- 在进行正则化操作的过程中,不会改变数据的分布情况,但是会改变数据特征之间的相关特性 。
7.4.4 备注
- 广义上来讲,标准化、区间缩放法、正则化都是具有类似的功能。在有一些书籍上,将标准化、区间缩放法统称为标准化,把正则化称为归一化操作。
- 如果面试有人问标准化和归一化的区别:标准化会改变数据的分布情况,归一化不会,标准化的主要作用是提高迭代速度,降低不同维度之间影响权重不一致的问题。
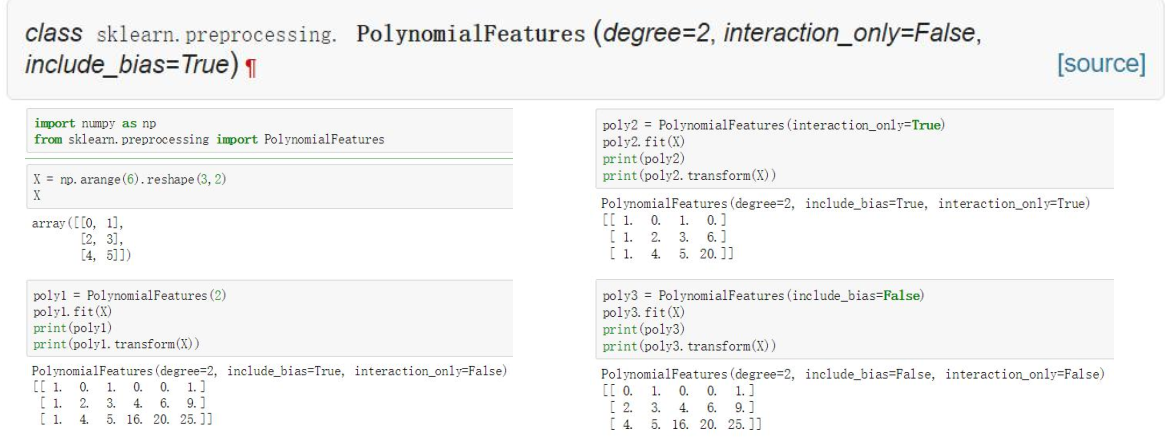
八、特征转换―数据多项式扩充变换
- 多项式数据变换主要是指基于输入的特征数据按照既定的多项式规则构建更多的输出特征属性
- 比如输入特征属性为[a,b],当设置degree为2的时候,那么输出的多项式特征为[1, a, b, a^2, ab,b^2]
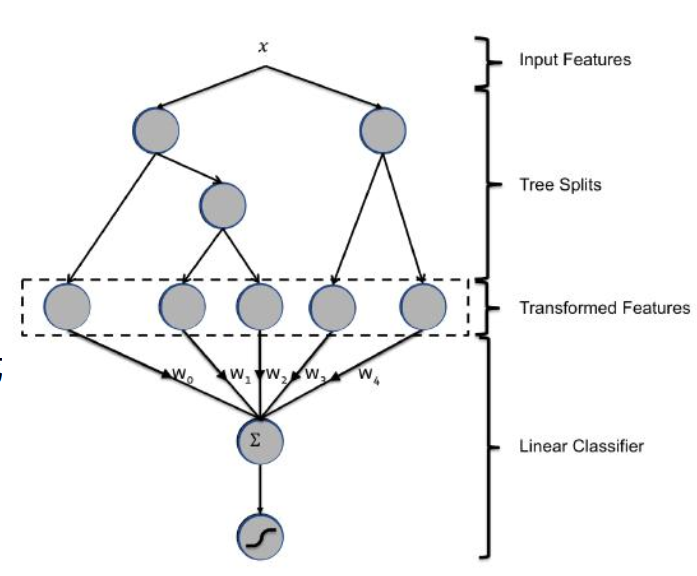
8.1 GBDT/RF+LR
- 认为每个样本落在决策树的每个叶子上就表示属于一个类别,那么我们可以进行基于GBDT或者随机森林的维度扩展,经常我们会将其应用在GBDT将数据进行维度扩充,然后使用LR进行数据预测,这也是我们进行所说的GBDT+LR做预测。
- 先通过GBDT,将原来样本中的维度进行扩展,然后将新生成的特征放到逻辑回归或线性回归中进行模型构建。