����
�����
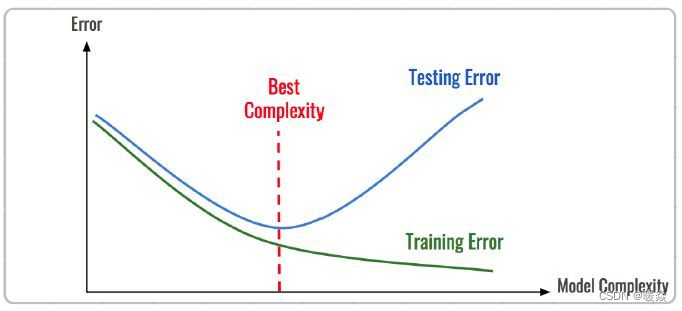
Ƿ���(underfitting):ָ��������ݶ���,ģ�Ͳ������ٻ���ģ�ͽṹ���ڼ�,��������ѧϰ�������еĹ��ɡ���������Ϊ���߹��ڼ�,�����ݵ����������ǿ��
�����(overfitting):����һ������ռ�H,һ������h����H,������������ļ���h������H,ʹ����ѵ��������h�Ĵ����ʱ�h��С,��������ʵ���ֲ���h����h�Ĵ�����С,��ô��˵����h�������ѵ�����ݡ��������Ϊ���߹��ڸ���,����������ǿ��ģ������֤�����Ϻ�ѵ�������ϱ��ֶ��ܺ�,���ڲ��Լ����ϱ��ֺܲ����ڻع������й�������Ϊ:������߹��ڸ���;�ڷ��������й�������Ϊ:���߽߱���ڸ��ӡ�
���������
��Ͻ�����֤����ģ�͵ı���,�ɽ�ȷ�ж���ϳ̶���
��ʵ��ͨ����ѵ�����������(�������)����ģ�͵�ѧϰ�̶ȼ�����������
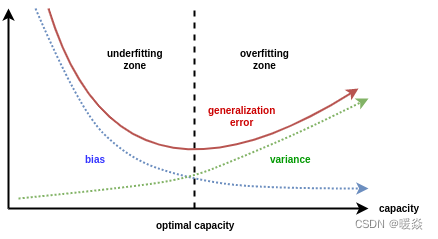
Ƿ���:ѵ�����Ͳ�������ھ��ϸߡ�����ѧ������Ϊ��ƫ��(high bias)��
�ٽ��:����ѵ��ʱ�估ģ���Ӷȵ����Ӷ��½�,����������ŵ��ٽ���,ѵ������½�,�������������
�����:ѵ�����ϵ�,���������ϸߡ�����ѧ������Ϊ�߷���(high variance)��
ͳ��ѧ���á�ƫ��-����ֽ⡱(bias-variance decomposition)������ģ�͵ķ�������:�䷺�����Ϊƫ�����������֮�͡�
�� �� �� �� = �� �� �� ( e r r o r ) = b i a s 2 ( x ) + v a r ( x ) + �� 2 �������=������(error)=bias^2(x)+var(x)+\varepsilon^2 ��������=������(error)=bias2(x)+var(x)+��2
����(��) �������ڵ�ǰ�������κ�ѧϰ�㷨���ܴﵽ�ķ��������½�,���̻���ѧϰ���Ȿ��(�۴���)���Ѷȡ�
ƫ��(Bias) ��ָ�����п��ܵ�ѵ�����ݼ�ѵ����������ģ�͵����ֵ����ʵֵ֮��IJ���,�̻���ģ�͵����������ƫ���С��ģ��Ԥ��ȷ��Խ��,��ʾģ����ϳ̶�Խ�ߡ�
����(Variance) ��ָ��ͬ��ѵ�����ݼ�ѵ������ģ�Ͷ�ͬԤ���������ֵ֮��IJ���,�̻���ѵ�������Ŷ�����ɵ�Ӱ�졣����ϴ�ģ��Ԥ��ֵԽ���ȶ�,��ʾģ��(��)��ϳ̶�Խ��,��ѵ�����Ŷ�Ӱ��Խ��
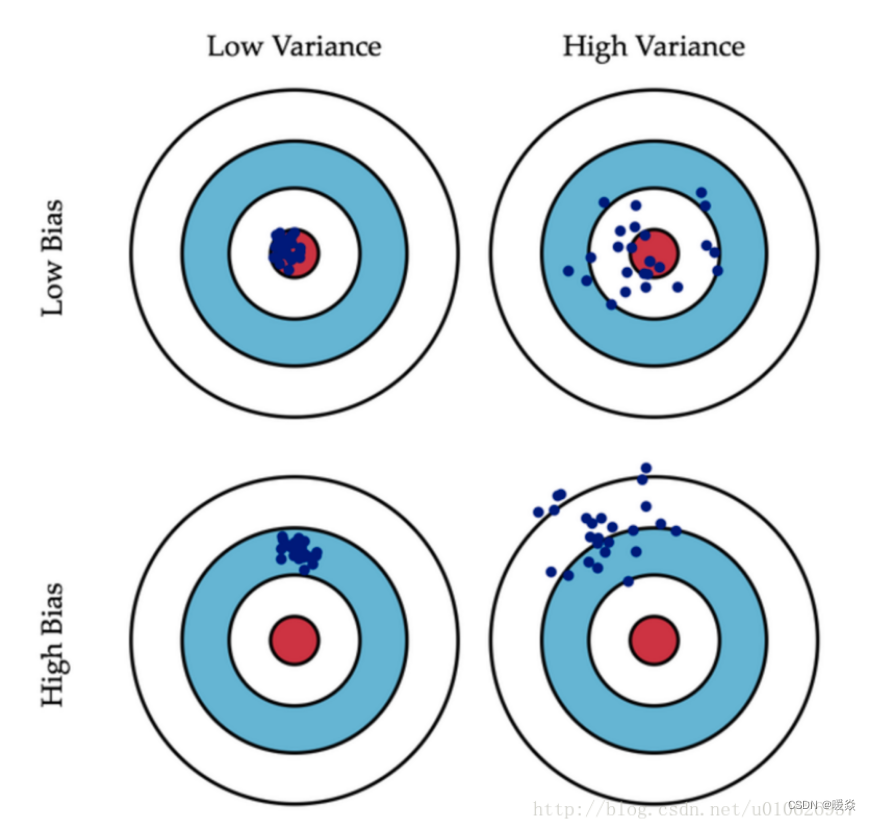
��ƫ��-����ֽ⡱ ˵��,ģ����Ϲ��̵ķ�����������ѧϰ�㷨�����������ݵij�����Լ�ѧϰ���������Ѷ�����ͬ�����ġ�
Ƿ���:ģ��ȷ�Ȳ���(��ƫ��),��ѵ�����ݵ��Ŷ�Ӱ���С(�ͷ���),�䷺��������Ҫ�ɸߵ�ƫ��¡�
�����:ģ��ȷ�Ƚϸ�(��ƫ��),ģ������ѧϰ��ѵ�������Ŷ�������(�߷���),�䷺�������ɸߵķ���¡�
ʲô�ǡ�����ϡ�,����ж�,������ԭ����ʲô? - Ӿ��
Ƿ���ԭ��
����������
���ܻ���������������ģ�Ͳ����ϴ��Ӱ��,����δ������Щ������
����̫��,ģ���Ӷȹ���
�����ԭ��
��ģ����ѡȡ����
����������̫�١�ѡ����������������ǩ�����,����ѡȡ���������ݲ����Դ���Ԥ���ķ������
�����������Ź���
ʹ�û���ѧϰ������,����Ϊ������,�Ӷ�������Ԥ��ķ������
���費����
�����ģ������������,����˵�Ǽ������������ʵ�ʲ���������
����̫��,ģ���Ӷȹ���
����
tree-basedģ��
����tree-basedģ��,��������������splitû�к���������,�п���ʹ�ڵ�ֻ�����������¼�����(event)����¼�����(no event),ʹ����Ȼ��������ƥ��(���)ѵ������,��������Ӧ�������ݼ���
������ģ��
Ȩֵѧϰ��������̫��(Overtraining),�����ѵ�������е�������ѵ��������û�д����Ե�������
BP�㷨ʹȨֵ�����������ڸ��ӵľ����档
ʲô�ǡ�����ϡ�,����ж�,������ԭ����ʲô? - ���˸���
������Ч���Ż�
Ƿ����Ż�
��������ά��:��������ҵ���������,����������������������ռ�,�����������ı�������;
����ģ���Ӷ�:������ģ��ѵ��ʱ�䡢�ṹ���Ӷ�,���Ը��ӷ�����ģ�͵�,������ģ�͵�ѧϰ����;
������Ż�
�����������
��������
��Ѱ�Ҹ���ѵ����������,������ǿ��,�Լ��ٶԾֲ����ݵ�����;
Ǩ��ѧϰ
Ǩ��ѧϰ�Ĺ���ԭ�����ڴ������ݼ�(��ImageNet)��ѵ������,Ȼ����ЩȨ�������������еij�ʼȨ�ء�
����ѡ��
ͨ��ɸѡ����������,������������������������;
���ģ��
����ģ���Ӷȡ�
��ģ�ͽṹ
��������������,����������Ŀ�ȡ�
L1/L2����
ͨ���ڴ��ۺ�������������(Ȩ�������ֵ)��Ϊ�ͷ���,������ģ��ѧϰ��Ȩ�ء�(��չ:ͨ�����������������������������,Ҳ������L2����Ч��)
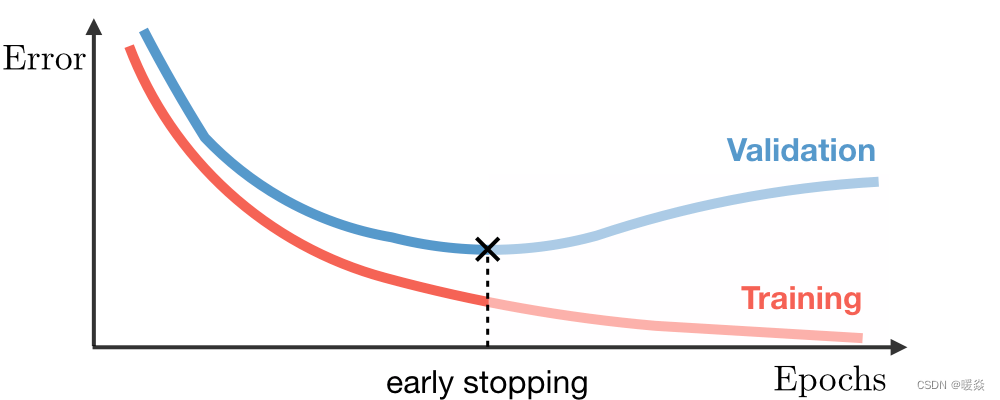
��ǰֹͣ(Early stopping)
ͨ�����������ضϵķ���,������ģ��ѧϰ��Ȩ�ء�
��϶��ģ��
����ѧϰ
�����ɭ��(bagging��)ͨ��ѵ�������зŻس������������ѡ��ѵ�����ģ��,�ۺϾ���,���Լ��ٶԲ�������/ģ�͵�����,���ٷ�����;
Dropout
�������ǰ��������ÿ�ΰ�һ���ĸ���(����50%)����ء���ͣ��һ������Ԫ�����á��������ڶ�������ṹģ��baggingȡƽ������,��ģ�Ͳ�������ijЩ�ֲ�������,�Ӷ��и��÷������ܡ�
Ϊʲô���ɷ�ֹ�����?
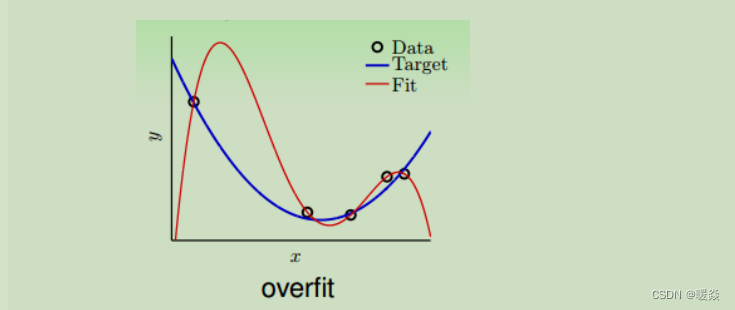
��������������������,���ʹ��һ���߽���ʽ(ͼ�к�ɫ������ʾ),����10��,��Ŀ�꺯��(��ɫ����)������ϡ�������߲����ܴ�,��Ȼ E i n E_in Ei?n��С,���� E o u t E_out Eo?ut�ܴ�,Ҳ������������������
E i n E_in Ei?n:ѧϰ�������ռ��� g ��δ֪��Ŀ�꺯�� f ��ѵ�������ڵ����
E o u t E_out Eo?ut:ѧϰ�������ռ��� g ��δ֪��Ŀ�꺯�� f ��ѵ������������
һ�������취�ǽ��߽���ʽתΪ�ͽ���ʽ,�߽���ʽhypothesis sets������˵ͽ���ʽhypothesis sets��������,��ô�ڸ߽���ʽ�м���һЩ������,ʹ������Ϊ�ͽ���ʽ�����ֺ�������������֮Ϊ���ʶ�����(ill-posed problem)��
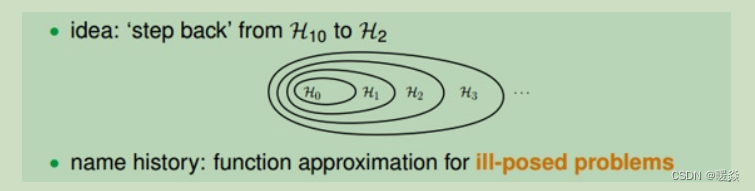
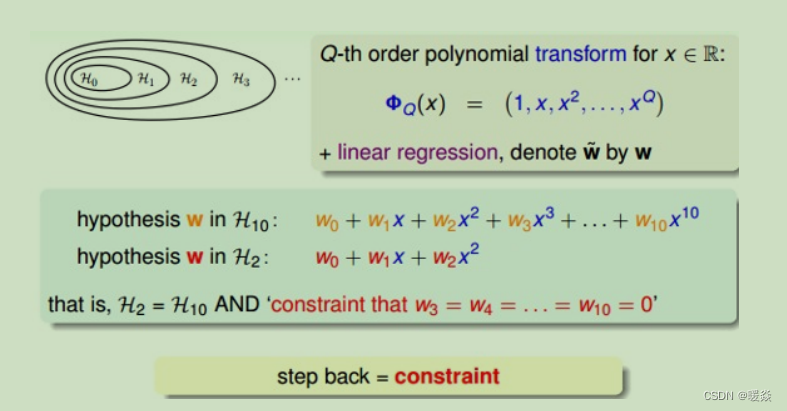
����,�������п��Զ�10����ʽ(
H
1
0
H_10
H1?0)����������
w
i
=
0
,
i
>
2
w_i=0, i>2
wi?=0,i>2,���ɽ�10����ʽת��Ϊ2����ʽ(
H
2
H_2
H2?)��
��,������
w
i
=
0
,
i
>
2
w_i=0, i>2
wi?=0,i>2���ڿ���,�����ʵ��ſ�Լ��(Looser Constraint),ֻ��w��Ϊ0�ĸ���,��10��w��,ֻҪ��8��wΪ0,2��w��Ϊ0���ɡ����ſ�Լ����Ķ���ʽ��Ϊ(
H
2
��
H_2'
H2��?)��

Looser Constraint��Ӧ��hypothesisӦ�ø��ý�һЩ,����ʵ������ҳ�һ��õ�sparse w���� �� q = 0 10 [ [ w q �� 0 ] ] �� 3 \sum_{q=0}^{10}[[w_q\neq 0]] \le 3 ��q=010?[[wq?��?=0]]��3 ��֤����NP-hard����(��Ϊ NP-hard - ��ͨ�ͺ� ��������˭)��
���Ѱ��һ�ָ��������Ŀ��ɵ�������(Softer Constraint)?
��������w=0�ĸ���,���������е�Ȩ��w��ƽ���͵Ĵ�С����������C,����hypothesis sets��Ϊregularized hypothesis set,��Ϊ w t T x n w_t^Tx_n wtT?xn?��������ʽ���������ǿ��Խ�������,�����õ���������������Ȩ��w��Ϊ w R E G w_{REG} wREG? ��
CֵԽ��,���ķ�ΧԽ��,��Խ���ɡ���C�����ʱ��,���������dz�����,�൱��û�м����κ����ơ�����
H
1
0
H_10
H1?0��ͬ��

��������,��loss function����������,��ʹ���µõ����Ż�Ŀ�꺯��h = f+normal,��Ҫ�� f �� normal ����һ��Ȩ��(trade-off),��Ϊmin h=min f+ min normal,������֤ f ��С��ͬʱ��Ҫ��֤ normal ��С���������ԭ��ֻ�Ż�f�������,�ǿ��ܵõ�һ���Ƚϸ���,ʹ��������normal�Ƚϴ�,��ôh�Ͳ������ŵ�,��˿��Կ��������������ý���Ӽ�,���ϰ¿�ķ�굶����,ͬʱҲ�ȽϷ�����ƫ��ͷ���(�����ʾģ�͵ĸ��Ӷ�)������,ͨ������ģ���Ӷ�,�õ���С�ķ������,������ϳ̶ȡ�
�ο�:L1������L2���� - bingo�������� - ֪��
���� w R E G w_{REG} wREG??
�������䡣

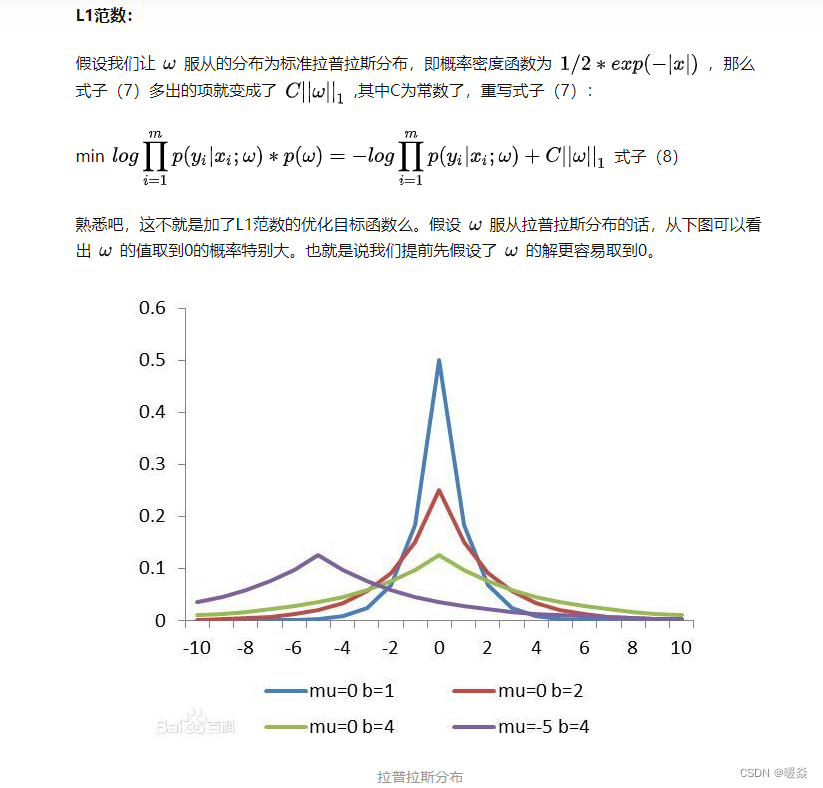
L0����
��L0����������һ����������W�Ļ�,����ϣ��W�Ĵ�Ԫ�ض���0�����仰˵,�ò���W��ϡ��ġ�
L1����
L1����ʽ: E i n + �� �� j �O w j �O E_in+\lambda \sum_j|w_j| Ei?n+����j?�Owj?�O
L1����(ϡ���������(Lasso regularization))
�O �O x �O �O 1 = ( �� i �O x i �O ) ||x||_1=(\sum_i|x_i|) �O�Ox�O�O1?=(��i?�Oxi?�O),���� p �� R , p �� 1 p\in \mathbb R, p\ge1 p��R,p��1��
��ʾ����������Ԫ�ؾ���ֵ֮�͡��ֳ�Ϊϡ���������(Lasso regularization)
������ѧϰ��������ͷ���Ԫ��֮��IJ���dz���Ҫʱ,ͨ����ʹ�� L1 ������ÿ�� x ��ij��Ԫ�ش� 0 ���� ?,��Ӧ�� L1 ����Ҳ������ ?��
L1����Ӧ�ó���
1 L1����Ҳ����������������ѡ��,��Ҫԭ������L1����ʹ�ý϶�IJ���Ϊ0,�Ӷ�����ϡ���(��ϡ��ģ��),��0��Ӧ����������,��������ѡ��������
2 ƽ�� L2 ����Ҳ���ܲ��ܻ�ӭ,��Ϊ����ԭ�㸽��������ʮ�ֻ�������ijЩ����ѧϰӦ����,����ǡ�������Ԫ�غͷ��㵫ֵ��С��Ԫ���Ǻ���Ҫ�ġ�����Щ�����,����ת��ʹ���ڸ���λ��б����ͬ,ͬʱ���ּ���ѧ��ʽ�ĺ���:L1 ������������ѧϰ��������ͷ���Ԫ��֮��IJ���dz���Ҫʱ,ͨ����ʹ�� L1 ������ÿ�� x ��ij��Ԫ�ش� 0 ���� ?,��Ӧ�� L1 ����Ҳ������ ?��
Ϊʲô��ҪȨֵϡ��?
(1)����ѡ��(Feature Selection):
��Ҷ�ϡ�������֮���͵�һ���ؼ�ԭ����������ʵ���������Զ�ѡ��һ����˵,xi�Ĵ�Ԫ��(Ҳ��������)���Ǻ����յ����yiû�й�ϵ���߲��ṩ�κ���Ϣ��,����С��Ŀ�꺯����ʱ����xi��Щ���������,��Ȼ���Ի�ø�С��ѵ�����,����Ԥ���µ�����ʱ,��Щû�õ���Ϣ�����ᱻ����,�Ӷ������˶���ȷyi��Ԥ�⡣ϡ��������ӵ��������Ϊ����������Զ�ѡ��Ĺ���ʹ��,����ѧϰ��ȥ����Щû����Ϣ������,Ҳ���ǰ���Щ������Ӧ��Ȩ����Ϊ0��
(2)�ɽ�����(Interpretability):
��һ��������ϡ���������,ģ�������͡����综ij�ֲ��ĸ�����y,Ȼ�������ռ���������x��1000ά��,Ҳ����������ҪѰ����1000�����ص�������ôӰ�컼�����ֲ��ĸ��ʵġ�������������Ǹ��ع�ģ��:y=w1x1+w2x2+��+w1000x1000+b(��Ȼ��,Ϊ����y����[0,1]�ķ�Χ,һ�㻹�üӸ�Logistic����)��ͨ��ѧϰ,������ѧϰ����w��ֻ�к��ٵķ���Ԫ��,����ֻ��5�������wi,��ô���Ǿ�����������,��Щ��Ӧ�������ڻ������������ṩ����Ϣ�Ǿ��,�����Եġ�Ҳ����˵,���������ֲ�ֻ����5�������й�,��ҽ���ͺ÷������ˡ������1000��wi����0,ҽ�������1000������,��������ϡ�
�ο�:����ѧϰ�еķ�������֮(һ)L0��L1��L2���� - ��������
ϡ��ģ��������ѡ��Ĺ�ϵ
�����ᵽL1��������������һ��ϡ��Ȩֵ����,����������������ѡ��ΪʲôҪ����һ��ϡ�����?
ϡ�����ָ���Ǻܶ�Ԫ��Ϊ0,ֻ������Ԫ���Ƿ���ֵ�ľ���,���õ������Իع�ģ�͵Ĵ�ϵ������0. ͨ������ѧϰ�����������ܶ�,�����ı�����ʱ,�����һ������(term)��Ϊһ������,��ô����������ﵽ�����(bigram)����Ԥ������ʱ,��ô��������Ȼ����ѡ��,�������������Щ�����õ���ģ����һ��ϡ��ģ��,��ʾֻ���������������ģ���й���,����������û�й���,���߹���С(��Ϊ����ǰ���ϵ����0�����Ǻ�С��ֵ,��ʹȥ����ģ��Ҳû��ʲôӰ��),��ʱ���ǾͿ���ֻ��עϵ���Ƿ���ֵ�������������ϡ��ģ��������ѡ��Ĺ�ϵ��
�ο�:����ѧϰ��������L1��L2��ֱ������ - ����������
ΪʲôL1������ʹȨֵϡ��?
��Ϊ���ӵ�L1���������ʧ�������ݶ��½��Ż�������,�ܿ��ܻ��� w i = 0 w_i=0 wi?=0��ȡ�����Ž�,�Ա�δ����L1���������ʧ����,����L1���������ʹ�����Ľ������к������0(��:�������ܶ�ά����ֵΪ0),����L1������ʹȨֵϡ�衣
����ݶ��½��Ż���L1���������ʧ����?
�κεĹ�������,�������Wi=0�ĵط�����,���ҿ��Էֽ�Ϊһ������͡�����ʽ,��ô����������ӾͿ���ʵ��ϡ�衣
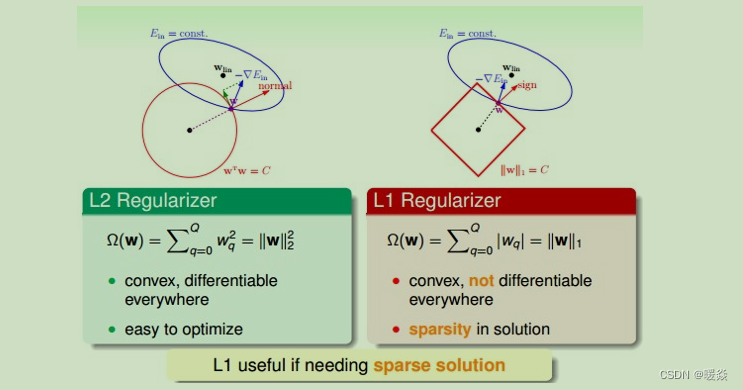
����ͼ����ͼ��ʾ,����ռ�����һ�� w(ͼ����ɫ��),��ɫ��Բ��������С�� E i n Ein Ein ����,��ɫ������ w ������������ �O w 1 �O + �O w 2 �O = C |w_1|+|w_2|=C �Ow1?�O+�Ow2?�O=C����ɫ���ǵȸ��ߡ�
û��������Cʱ:һ��ʹ���ݶ��½��㷨,����ɫ��Բ������w��һֱ���� ? ? E i n -\nabla E_in ??Ei?n�ķ���(w �ݶȵķ�����)�ƶ�(ͼ����ɫ��ͷָʾ�ķ���),��û���������������,w���ջ�ȡ����Сֵ w l i n w_lin wl?in,�����ȵס���λ�á�
����������Cʱ:L1������Ϊw�����ڱ߳�ΪC�ķ����ڼ���߽���,w����ԭ��ľ��벻�ܳ��������ɫ���η�Χ �O �O w �O �O = C ||w||=C �O�Ow�O�O=C���뷽�α�������ֱ������(ͼ�к�ɫ��ͷnormalָʾ�ķ���)��w�ķ���,��Ϊ����������,w�������ź�ɫ��ͷ�����ƶ�,���������,ֻ��λ�ڷ����ϱ�Եλ��,���ŷ��εı��ƶ�������,w���ܵ��� w l i n w_lin wl?in��λ�á����ŵ����Ż�����,ֻҪ ? ? E i n -\nabla E_in ??Ei?n��w�����߷���ֱ,��ô��������֪ʶ, ? ? E i n -\nabla E_in ??Ei?nһ����w�����߷������в�Ϊ��ķ���,��w�������ƶ���ֻ�е� ? ? E i n -\nabla E_in ??Ei?n���ɫ������ƽ�е�ʱ��,�ڷ��α߷�����û�в�Ϊ��ķ�����,Ҳ�ͱ�ʾ��ʱw�ﵽ�����Ž��λ�á�
Ϊʲôw���Ž��λ���� w i = 0 w_i=0 wi?=0��?
����ֻ��һ������Ϊw,��ʧ����Ϊ
L
(
w
)
L(w)
L(w),����L1�������Ϊ:
E
i
n
+
��
��
j
�O
w
j
�O
E_in+\lambda \sum_j|w_j|
Ei?n+����j?�Owj?�O��
����
L
(
w
)
L(w)
L(w)��w=0���ĵ���Ϊ
d
0
d_0
d0?,��
?
L
(
w
)
?
w
�O
w
=
0
=
d
0
\frac{\partial L(w)}{\partial w}|_{w=0}=d_0
?w?L(w)?�Ow=0?=d0?��
��,��L1������ʱ��w=0���ĵ���Ϊ
?
J
L
1
(
w
)
?
w
�O
w
=
0
?
=
d
0
?
��
\frac{\partial J_{L1}(w)}{\partial w}|_{w=0^-}=d_0-\lambda
?w?JL1?(w)?�Ow=0??=d0??��,
?
J
L
1
(
w
)
?
w
�O
w
=
0
+
=
d
0
+
��
\frac{\partial J_{L1}(w)}{\partial w}|_{w=0^+}=d_0+\lambda
?w?JL1?(w)?�Ow=0+?=d0?+����
��֪,���ۺ�����0���ĵ�����һ��ͻ�䡣�� d 0 ? �� d_0-\lambda d0??���� d 0 + �� d_0+\lambda d0?+��,�� d 0 ? �� d_0-\lambda d0??���� d 0 + �� d_0+\lambda d0?+�����,����0������һ����Сֵ�㡣���,��L1���������ʧ�����ݶ��½��Ż�ʱ,�ܿ����Ż����ü�Сֵ����,�� w = 0 w=0 w=0����
��������L1������,����ʹ�����Ľ������к��и����0��
�ο�:L1����Ϊʲô�������ϡ��� - keep_forward
L0����ʵ��ϡ��,Ϊʲô����L0,��Ҫ��L1?
һ����ΪL0���������Ż����(NP������),����L1������L0��������������,��������L0����Ҫ�����Ż���⡣����L0������L1����������ʵ��ϡ��,L1����б�L0���õ��Ż�������Զ����㷺Ӧ�á�
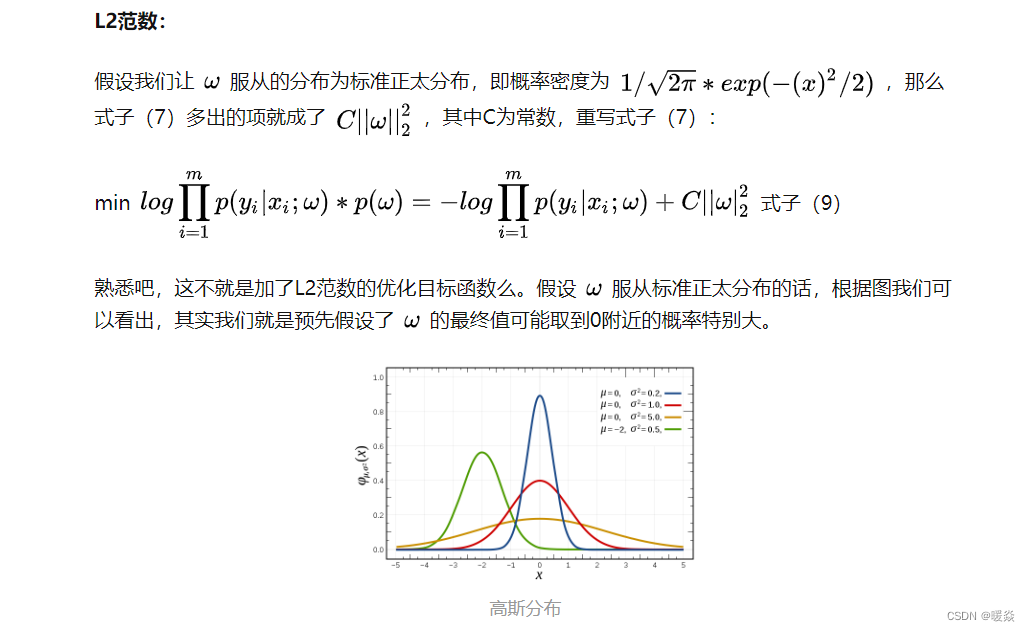
L2����
L2����ʽ: E i n + �� �� j w j 2 E_in+\lambda \sum_jw_j^2 Ei?n+����j?wj2?
L2�����ŵ㼰Ӧ�ó���
1)��ѧϰ���۵ĽǶ���˵,L2�������Է�ֹ�����,����ģ�͵ķ���������
��L2���������ʧ�����Ż����w��ƽ����
2)���Ż�������ֵ����ĽǶ���˵,L2���������ڴ��� condition number���õ�����¾�����������ѵ����⡣
��condition number����һ�仰�ܽ�:conditionnumber��һ������(������������������ϵͳ)���ȶ��Ի������жȵĶ���,���һ�������condition number��1����,��ô������well-conditioned��,���Զ����1,��ô������ill-conditioned��,���һ��ϵͳ��ill-conditioned��,�����������Ͳ�Ҫ̫�����ˡ�
�ο�:����ѧϰ�еķ�������֮(һ)L0��L1��L2���� - ��������
L2����ȱ��
�����ںܶ������,ƽ�� L2 ����Ҳ���ܲ��ܻ�ӭ,��Ϊ����ԭ�㸽��������ʮ�ֻ�����
ΪʲôL2��ԭ�㸽����������?
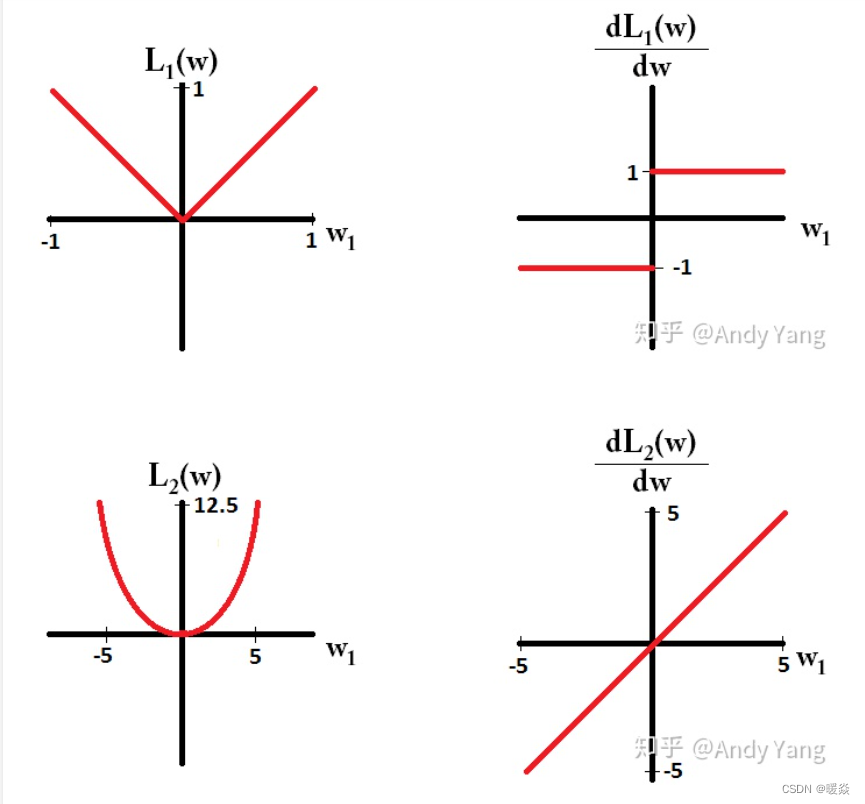

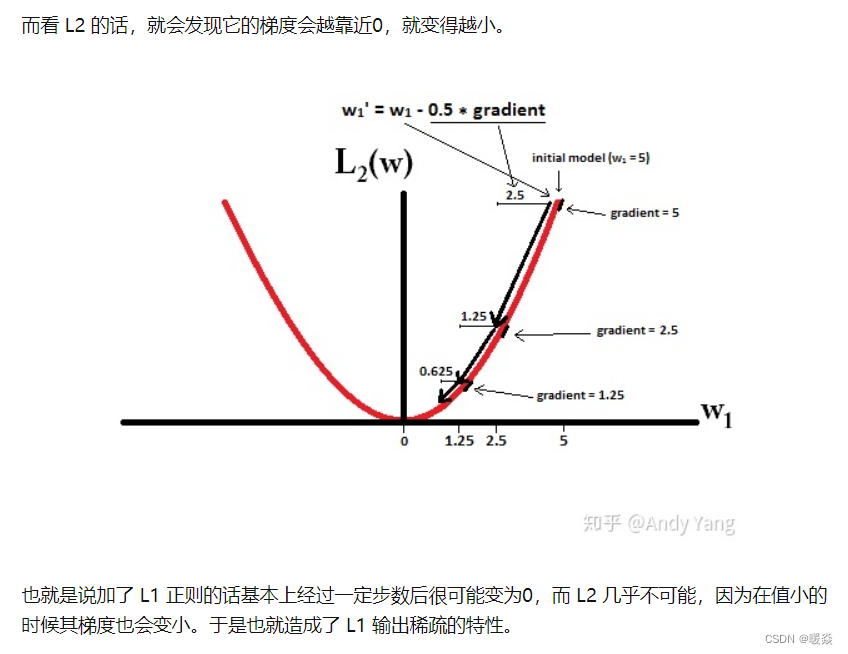
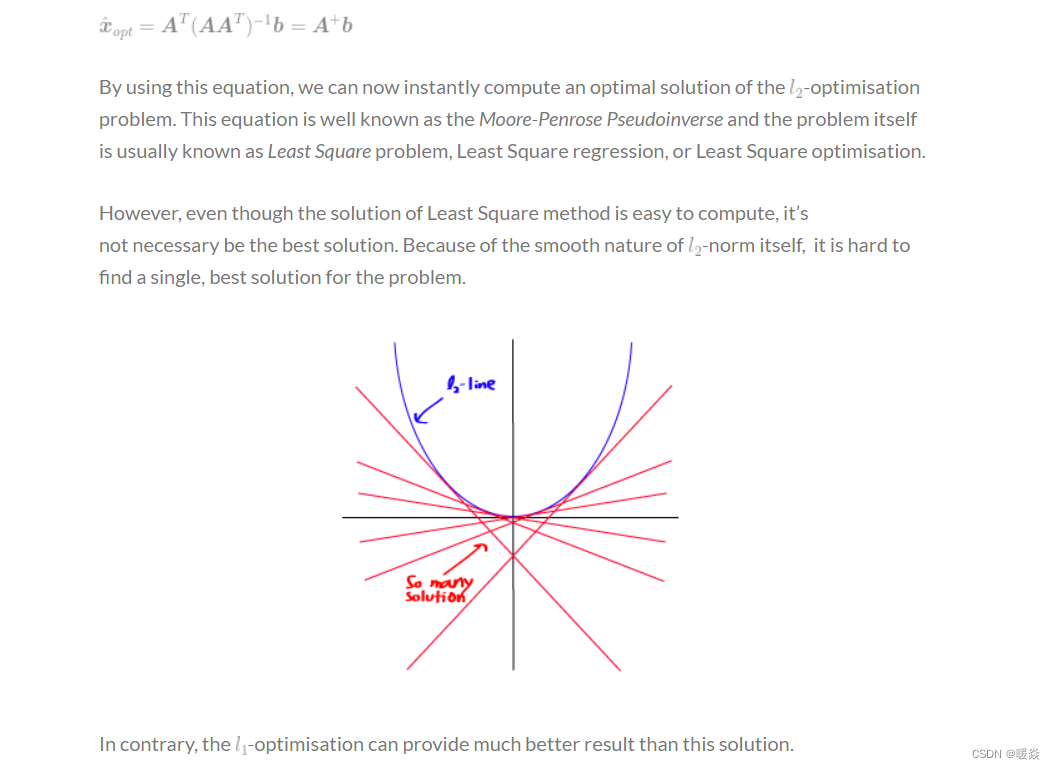
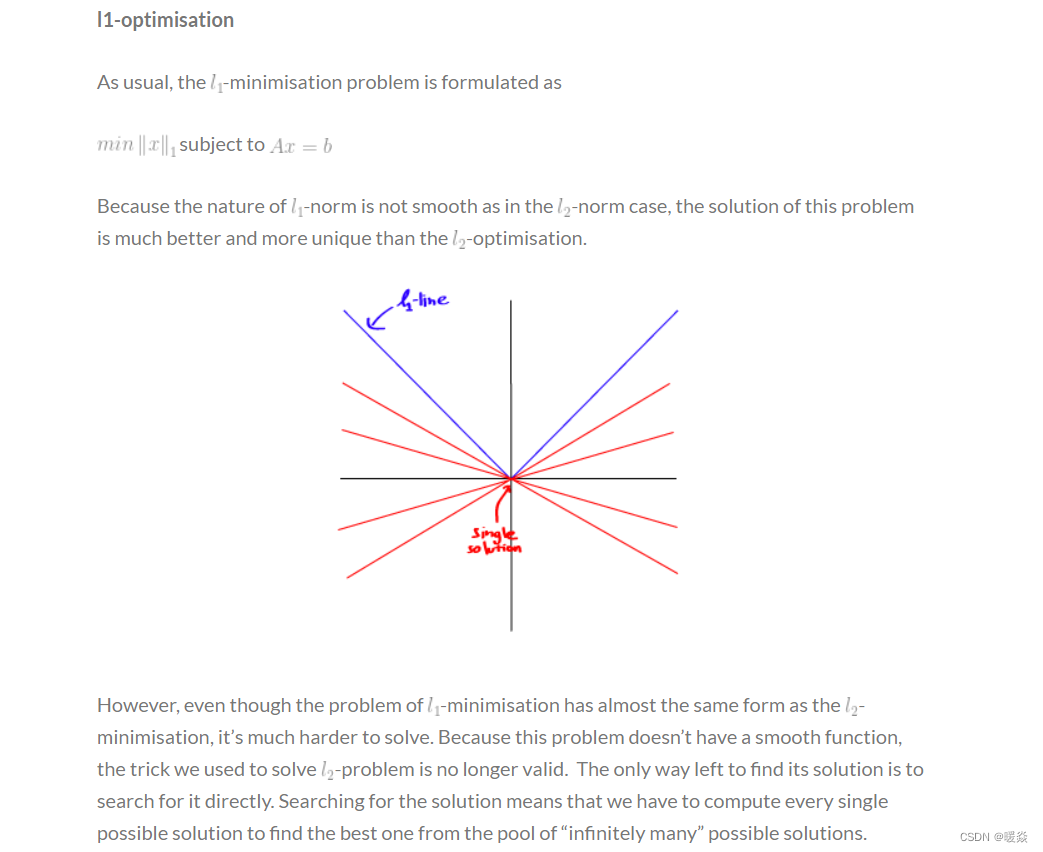

�ο�:l0-Norm, l1-Norm, l2-Norm, �� , l-infinity Norm
Ȩ�س߶�ƫ�Ʋ�����
�����Ѿ�ѵ���õ�һ�����,��������������ܿ��ܲ����,��������ϣ��L2�����ܰ����Ż����ҵ�һ����ò���,����ΪȨ�س߶�ƫ�Ʋ����ԵĴ���,ģ����ȫ�����ҵ�һ���µIJ���,����ԭ��������ģ����ȫ�ȼ�(û��������������),����L2����С(L2������������)��˵����,����L2����ȷʵ��������,��û������ģ�ͷ�������,û�дﵽʹ��L2����ij��ԡ�
L2����û��������ô��?�����ǡ�Ȩ�س߶�ƫ�ơ��ǵĻ� - PaperWeekly������ - ֪��
L2�Ż�������
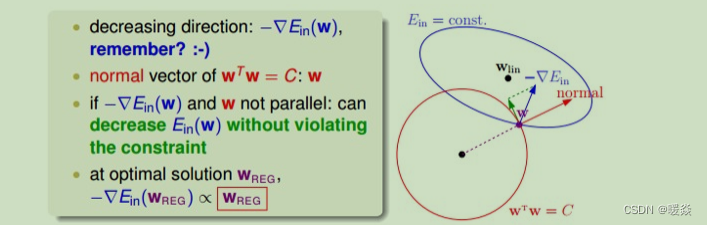
����ͼ��ʾ,����ռ�����һ�� w(ͼ����ɫ��),��ɫ��Բ��������С��
E
i
n
Ein
Ein ����,��ɫԲȦ�� w ������������
û��������Cʱ:һ��ʹ���ݶ��½��㷨,����ɫ��Բ������w��һֱ���� ? ? E i n -\nabla E_in ??Ei?n�ķ���(w �ݶȵķ�����)�ƶ�(ͼ����ɫ��ͷָʾ�ķ���),��û���������������,w���ջ�ȡ����Сֵ w l i n w_lin wl?in,�����ȵס���λ�á�
����������Cʱ:L2������Ϊw�����ڰ뾶Ϊ C \sqrt C C?��Բ��,w����ԭ��ľ��벻�ܳ���Բ�İ뾶,����ͼ�к�ɫԲȦ��ʾ w T w = C w^Tw=C wTw=C ,��w�����뿪��ɫԲ����������ɫ������ֱ������(ͼ�к�ɫ��ͷnormalָʾ�ķ���)��Բ���ߵķ�����,��w�ķ���,��Ϊ����������,w�������ź�ɫ��ͷ�����ƶ�,���������,ֻ��λ��Բ�ϱ�Եλ��,����Բ�����߷����ƶ�(ͼ����ɫ��ͷָʾ�ķ���)������,w���ܵ��� w l i n w_lin wl?in��λ�á����ŵ����Ż�����,ֻҪ ? ? E i n -\nabla E_in ??Ei?n��w�����߷���ֱ,��ô��������֪ʶ, ? ? E i n -\nabla E_in ??Ei?nһ����w�����߷������в�Ϊ��ķ���,��w�������ƶ���ֻ�е� ? ? E i n -\nabla E_in ??Ei?n����ɫ���ߴ�ֱ,�����ɫ������ƽ�е�ʱ��,�����߷�����û�в�Ϊ��ķ�����,Ҳ�ͱ�ʾ��ʱw�ﵽ�����Ž��λ�á�
ΪʲôL2��������ʹȨֵϡ��?
����ֻ��һ������Ϊw,��ʧ����Ϊ
L
(
w
)
L(w)
L(w),����L2�������Ϊ:
E
i
n
+
��
��
j
w
j
2
E_in+\lambda \sum_jw_j^2
Ei?n+����j?wj2?��
����
L
(
w
)
L(w)
L(w)��w=0���ĵ���Ϊ
d
0
d_0
d0?,��
?
L
(
w
)
?
w
�O
w
=
0
=
d
0
\frac{\partial L(w)}{\partial w}|_{w=0}=d_0
?w?L(w)?�Ow=0?=d0?��
��,��L2������ʱ��w=0����ʧ�����ĵ���Ϊ
?
J
L
2
(
w
)
?
w
�O
w
=
0
=
d
0
+
2
?
��
?
w
=
d
0
\frac{\partial J_{L2}(w)}{\partial w}|_{w=0}=d_0+2 *\lambda * w=d_0
?w?JL2?(w)?�Ow=0?=d0?+2?��?w=d0?��
����L2����ʱ,���ۺ�����0���ĵ������� d 0 d_0 d0?,�ޱ仯����������L2������,�õ��Ľ�Ƚ�ƽ��(����ϡ��),������ʹ�����Ľ������к��и����0������ͬ���ܹ���֤���нӽ���0(�����ǵ���0,�������ƽ��)��ά�ȱȽ϶�,����ģ�͵ĸ��Ӷȡ�
ΪʲôL2�����Եõ�ֵ��С��Ȩֵ������ֵΪ0��Ȩֵ?
����ʽ���Կ���ÿ�θ���ʱ,�������ϵ������һ������������������L1 ����ȥһ���̶�ֵ,�����ϵ�������С�������Ϊ 0,���L2������ģ�ͱ�ø���,��ֹ�����,������������ѡ������á�
�ο�:����ѧϰ�е�����(Regularization) - Zero�����
L2���Ὣ���Ž�w*�ķ�����������,ij���������ϴ��ۺ������͵�Խ��,��������ŵij̶�Խ�ߡ�
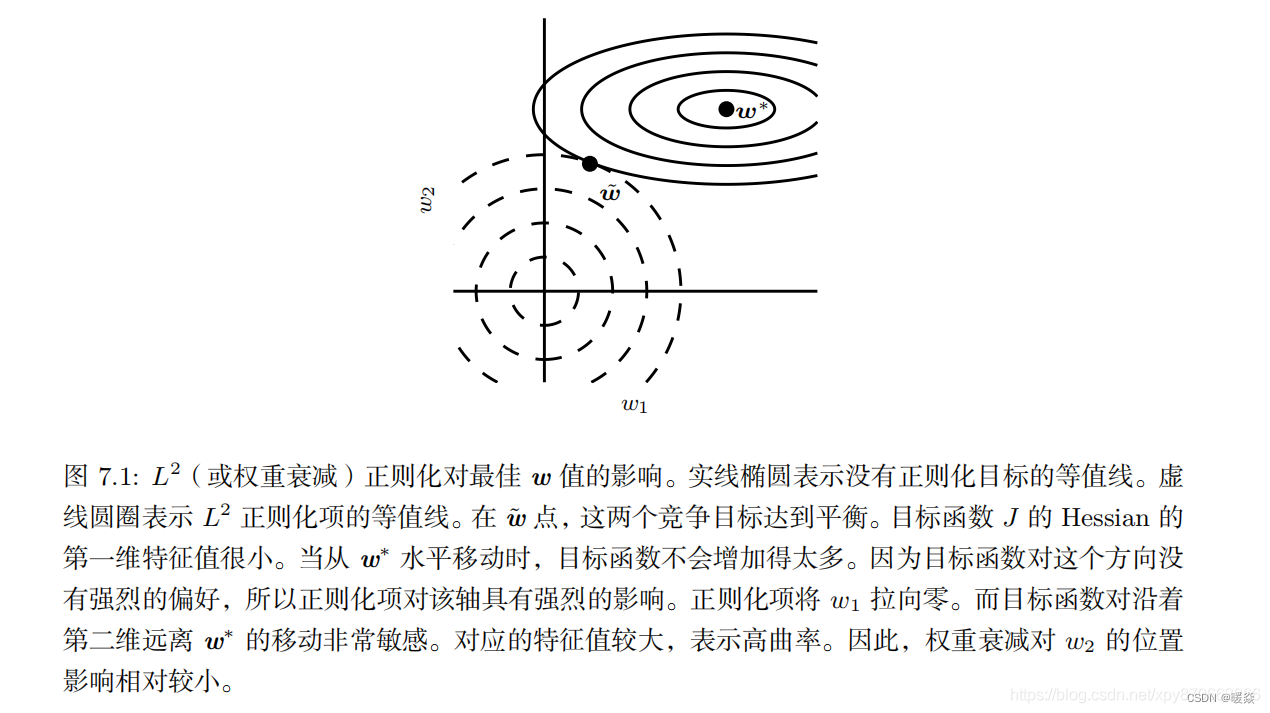

�ο�:�������ԭ�����ݶȹ�ʽ��L1����L2��������Ӧ�ó��� - pyxiea


�ο�:����ѧϰ��������L1��L2��ֱ������ - ����������
Ϊʲô�����ľ���ֵ��С��Ӧ��ģ����?
���Ƕ���ʽ��ϵij���:
�ڵ��������ݼ���ģ��,���ӵ�ģ��Ϊ�˶�ѵ����������ϳ̶ȸ���,��ϵ�����Ҫ���ϵؾ������¶�������ÿһ��ѵ��������,��͵��¶���ʽ�Ľ����Ƚϴ��Ҳ�������ֵ�Ƚϴ�;��֮,����ģ�ͱȽϼ�ʱ,���߾�ƽ��,������ʽ�����Ƚ�С�Ҳ�������ֵҲС�öࡣ
Խ���ӵ�ģ��,Խ�ǻ᳢�Զ����е������������,��������һЩ�쳣������,�����������ڽ�С��������Ԥ��ֵ�����ϴ�IJ���,���ֽϴ�IJ���Ҳ��ӳ�������������ĵ����ܴ�,��ֻ�нϴ�IJ���ֵ���ܲ����ϴ�ĵ�������˸��ӵ�ģ��,�����ֵ��Ƚϴ�
�ο�:�������ԭ�����ݶȹ�ʽ��L1����L2��������Ӧ�ó��� - pyxiea
�ο�:L1��L2������� - zhongrui_fzr
�Ӳ�ͬ�Ƕȿ�L1 L2 ����Ȩֵϡ�����ô�С


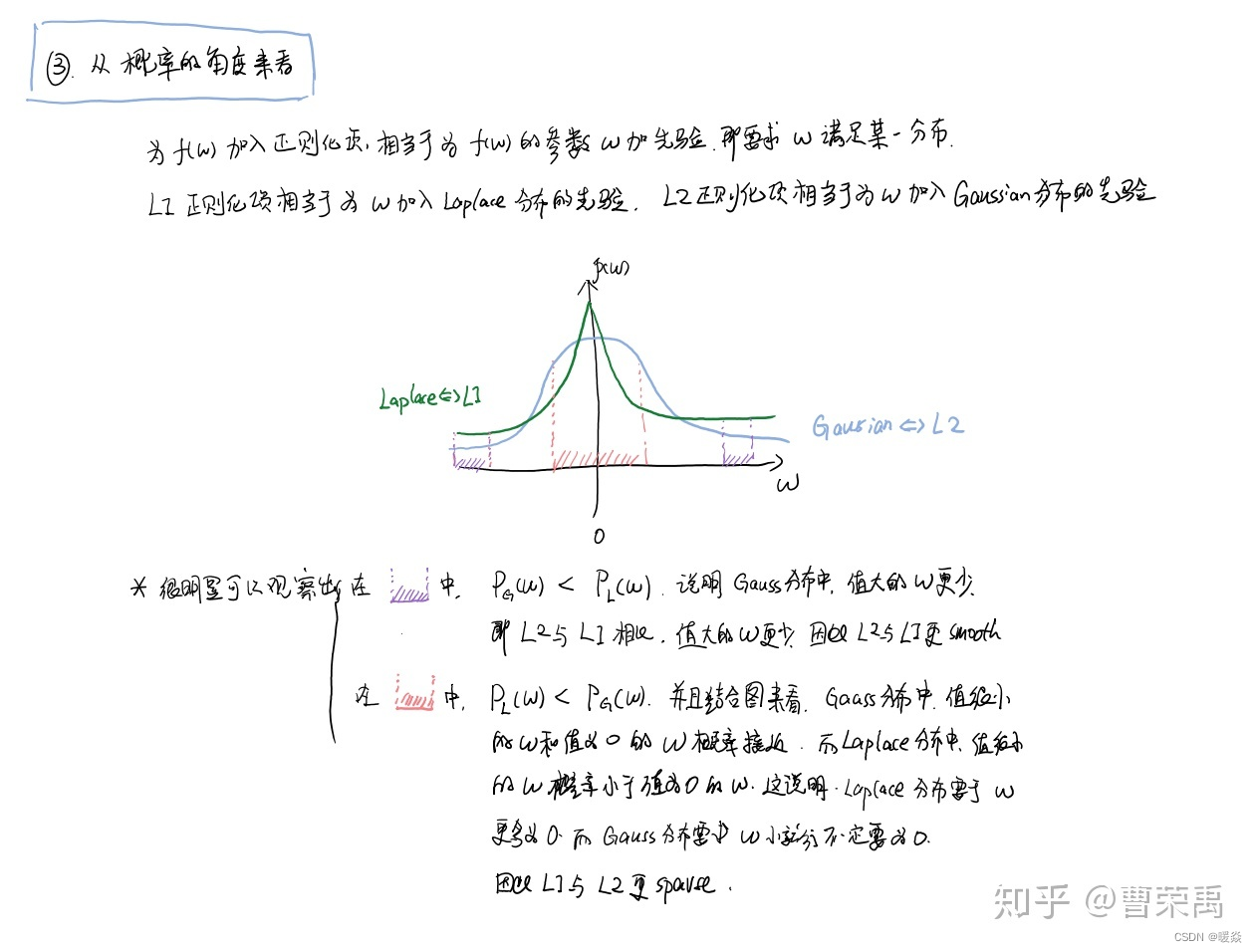
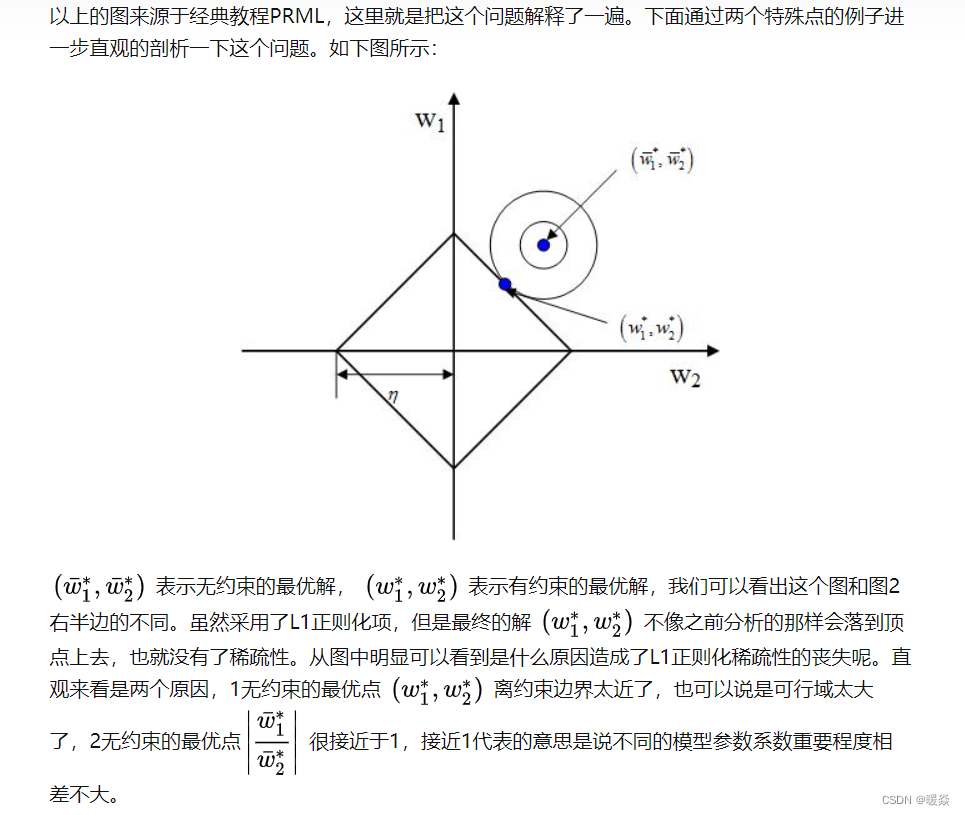
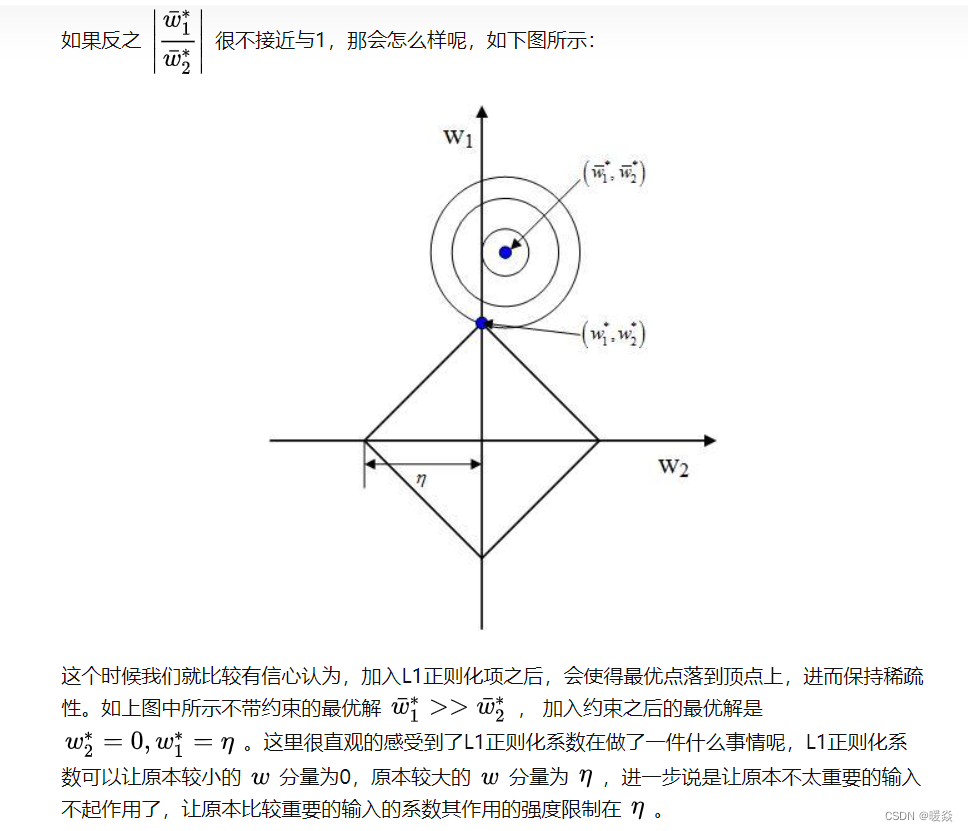
�ο�:l1 ����� l2 Ϊʲô�����ϡ���? - ser jamie�Ļش� - ֪��
�ο�:��ѧ�硿��Լ��ת��Լ��,���������ɳڹ۵��µ�L1����ϡ����̽�� - ���»��������� - ֪��
�ο�:����L1, L2������ȷ���� - ��������� - ֪��
���ʽǶ���ϸ����L1ϡ��Ȩֵ��L2ƽ��Ȩֵ
�ӱ�Ҷ˹ѧ�ɵĹ۵�����������,���ȼ���Ҫ��IJ�������ij������ֲ�,�����Իع�Ϊ����,�ø�˹�ֲ��ļ�����Ȼ���������Իع���

�ο�:L1������L2���� - bingo�������� - ֪��



L1��L2���ĸ��ʽ��� - �������� - ֪��
L1���� vs L2����
����֮�����ܹ�������ϵ�ԭ������,�����ǽṹ������С����һ�ֲ���ʵ����
�ṹ������С��: �ھ��������С���Ļ�����(Ҳ����ѵ�������С��),�����ܲ��ü�ģ��,�Դ���߷���Ԥ�⾫�ȡ�
L1��������loss function�������������ΪL1����,����L1�������õ�ϡ���(0�Ƚ϶�)��L2������loss function�������������ΪL2������ƽ��,����L2���������L1������˵,�õ��Ľ�Ƚ�ƽ��(����ϡ��),����ͬ���ܹ���֤���нӽ���0(�����ǵ���0,�������ƽ��)��ά�ȱȽ϶�,����ģ�͵ĸ��Ӷȡ�
�ο�:L1������L2���� - bingo�������� - ֪��
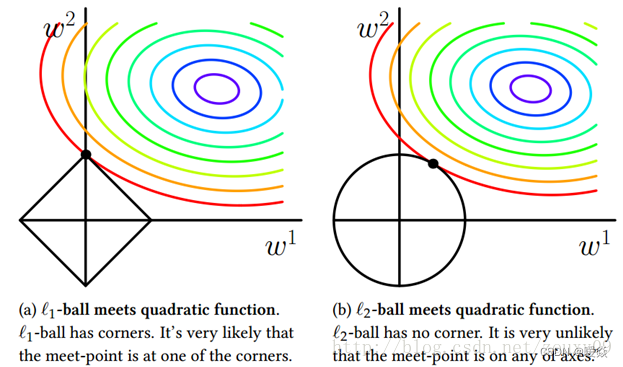
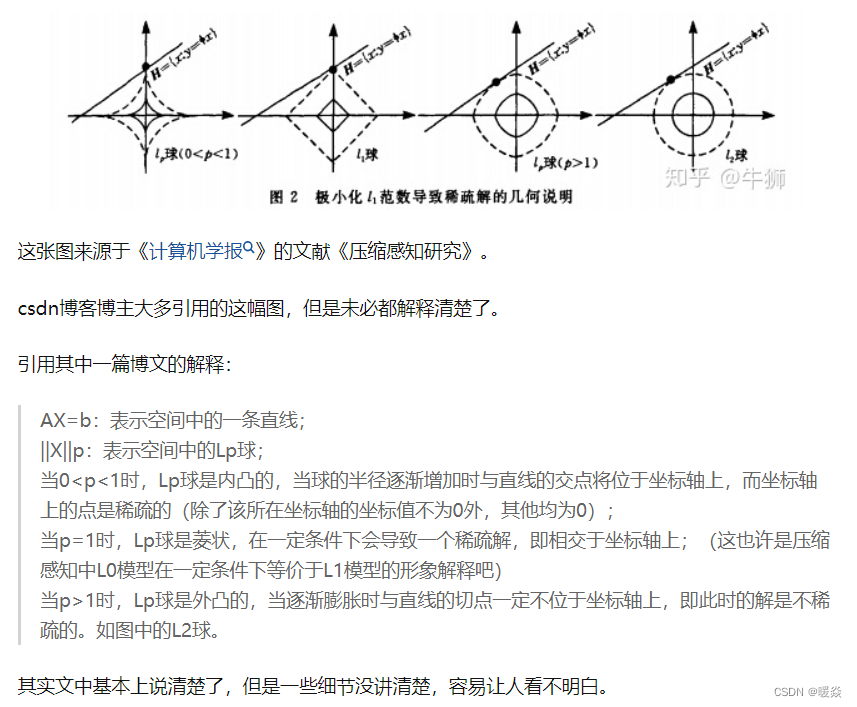
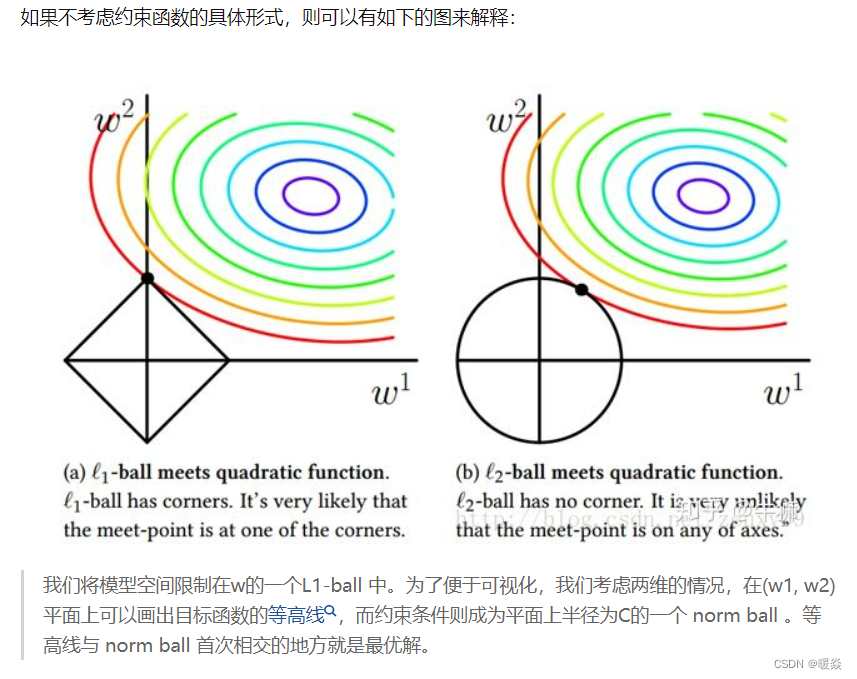
���Կ���,L1-ball ��L2-ball �IJ�ͬ������L1�ں�ÿ���������ཻ�ĵط����С��ǡ�����,��Ŀ�꺯���IJ���߳���λ�ðڵ÷dz���,��ʱ���ڽǵĵط��ཻ��ע��ڽǵ�λ�þͻ����ϡ����,����ͼ�е��ཻ�����w1=0,������ά��ʱ��(����һ����ά��L1-ball ��ʲô����?)���˽ǵ�����,���кܶ�ߵ�����Ҳ�Ǽ��кܴ�ĸ��ʳ�Ϊ��һ���ཻ�ĵط�,�ֻ����ϡ���ԡ�
���֮��,L2-ball ��û������������,��Ϊû�н�,���Ե�һ���ཻ�ĵط������ھ���ϡ���Ե�λ�õĸ��ʾͱ�÷dz�С�ˡ���ʹ�ֱ������������ΪʲôL1-regularization �ܲ���ϡ����,��L2-regularization ���е�ԭ���ˡ�
���,һ�仰�ܽ����:L1�������ڲ�������������,����������������0,��L2��ѡ����������,��Щ��������ӽ���0��Lasso������ѡ��ʱ��dz�����,��Ridge��ֻ��һ�ֹ����ѡ�
Ϊʲô�ݶ��½��ĵ�ֵ������������һ�ν��������Ž�?
���������������ʧ�����ĵ�ֵ�����������ͼ���״��ཻ�ĵط��������Ž⡣���Ǵ�Լ�������Ż����⡣���Բο�:��Լ�������Ż�����
�������䡣
ΪʲôL1��L2ϡ�����þ������ͼΪʲôҪ����Ϊ��ά����?(������⡰L1������L0�������������ơ�?)