ʹ��CV2,skimage,PIL����ͼ�����ͼ���ǩ���ݼ��ķ���
1)����һ:����opencv-python������ͼ���ǩ���ݼ�
2)������:����scikit-image������ͼ���ǩ���ݼ�
3)������:����PIL.Imageͼ����������ͼ���ǩ���ݼ�
Ŀ��:���ն���ʹ��CV2,skimage,PIL������ͼ�����(ͼ��+��ǩ)���ݼ��ķ���
- ѧϰ���ݼ���������,ͼ��Ԥ������������ͬͼ����Դ���Ԥ�����������в�ͬ��
- ѧ�����Լ������ݼ����ģʽ�淶��,�Ժ�����ݼ�������������������
- ����������ȷ�����ݼ�,�����ú���ѵ��ʹ���е���Ӧ��,��ÿһ���ֽڻ����ķ���
- ����ʹ�ò�ͬͼ���,�����治�ص�,�ɱ������ݻ���,������w,h,c�Ļ��ҡ�
- ���ڲ���ģʽ������������������ͼ���ǩ���ݼ��������ӿڡ�
��ʾ:д�����º�,Ŀ¼�����Զ�����,������ɿɲο��ұߵİ����ĵ�
����Ŀ¼
ǰ��
ǰ������һƪ������װ�ؼ������㷨�IJ���,��Ϊ�ص����㷨ģ����,�������ݼ���һ�����ıȽϴֲڡ��������������ݼ����������,����,������ƪ�����ص����һ�����ݼ���
���Ľ��ṩ�����������ݼ��ķ���������Ҳο���
�ؼ������㷨�����ݼ�������ģ��Ļ�������requirements.txt
python==3.7
numpy
pandas
pillow
opencv-python
scipy
scikit-image
pytorch==1.5.1
torchvision
���ݼ�ͼ��-��ǩ: Ŀ¼�ͱ�ǩ���ݽṹ
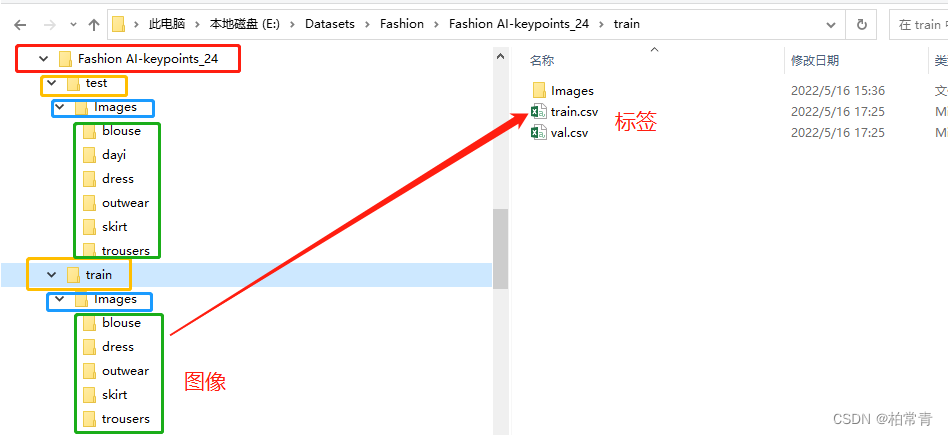
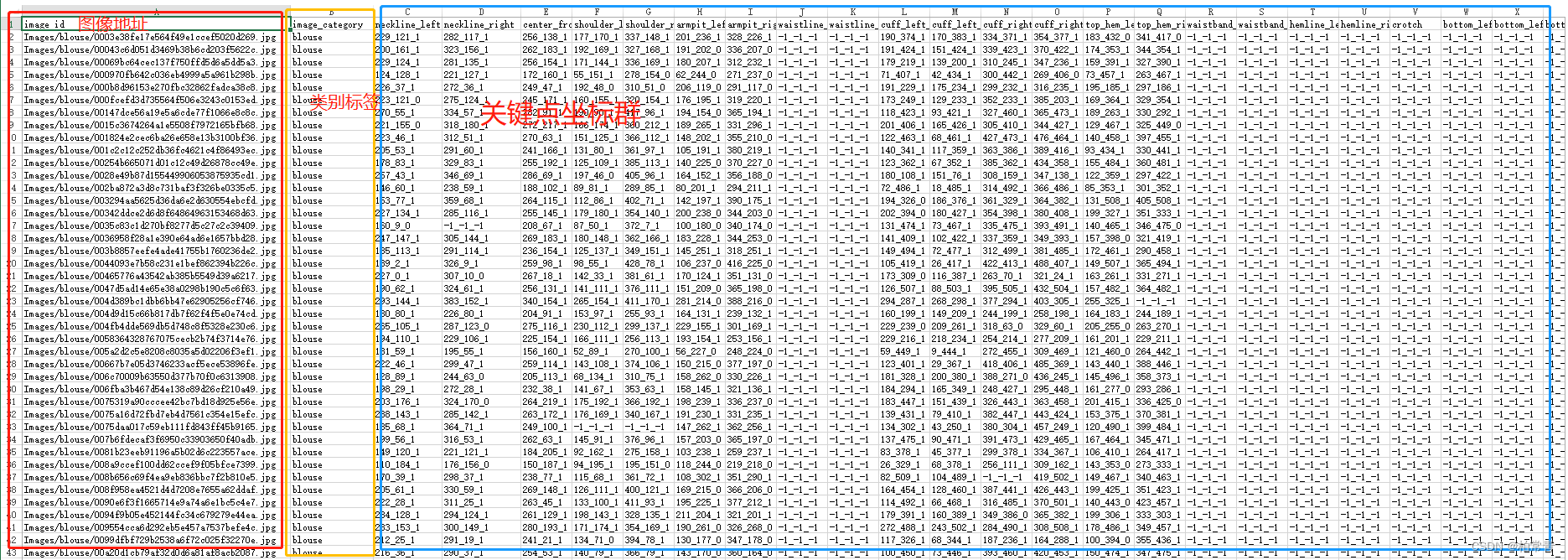
csv�ļ�
��ʾ:�����DZ�ƪ������������,�������ͼ���ǩ���ݼ����ɷ������ܽӿ�
һ���ṩ�����������ݼ��ķ����ܽӿ�
���ò���ģʽ������ݼ��ӿ�:
����:dataset_design_patterns.py
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 10:42
# @Author : Hyan Tan
# @File : dataset_design_patterns.py
import os
from abc import abstractmethod, ABCMeta
import numpy as np
import pandas as pd
import cv2
from skimage import io, transform, draw
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from transformation import RandomAdd, ImageResize, RandomCrop, RandomFlip, RandomRotate, Distort
# ------�������ݼ�------�������
class KeyPointsDataSet(Dataset):
"""��װ-����-�ؼ���Ⱥ������ݼ�"""
def __init__(self, root_dir=r'E:/Datasets/Fashion/Fashion AI-keypoints_24/train/', image_set='train',
transforms=None):
"""
��ʼ�����ݼ�
:param root_dir: ����Ŀ¼(.csv��images�ĸ�Ŀ¼)
:param image_set: trainѵ��,val��֤,test����
:param transforms(callable,optional):ͼ��任-��ѡ
��ǩ�����ļ���ʽΪcsv_file: ��ǩcsv�ļ�(����:ͼ����Ե�ַ-category����-��ǩcoordination����)
"""
super(KeyPointsDataSet, self).__init__()
self._imgset = image_set
self._image_paths = []
self._labels = []
self._cates = [] # ��ǩ:��װ���
self._csv_file = os.path.join(root_dir, image_set + '.csv') # csv��ǩ�ļ���ַ
self._categories = ['blouse', 'outwear', 'dress', 'trousers', 'skirt', ]
self._root_dir = root_dir
self._transform = transforms
self.__getFileList() # ͼ��ַ�б��ͱ�ǩ�б�
def __getFileList(self):
file_info = pd.read_csv(self._csv_file)
self._image_paths = file_info.iloc[:, 0] # ͼ���ַ�ڵ�һ��
self._cates = file_info.iloc[:, 1] # �ڶ���,��װ����:blouse,trousers,skirt,dress,outwear
if self._imgset == 'train': # ֻ��ѵ������֤�б�ǩ,����û�б�ǩ��
landmarks = file_info.iloc[:, 2:26].values # panda��DataFrame���ݵĶ�ȡ
for i in range(len(landmarks)):
label = []
for j in range(24):
plot = landmarks[i][j].split('_')
coor = []
for per in plot:
coor.append(int(per))
label.append(coor)
self._labels.append(np.concatenate(label))
self._labels = np.array(self._labels).reshape((-1, 24, 3))
else:
self._labels = np.ones((len(self._image_paths), 24, 3)) * (-1)
def __len__(self):
return len(self._image_paths)
# ---�������ݼ�������---ͨ��cv2��ȡͼ������---�������1
class DatasetByCv(KeyPointsDataSet):
def __getitem__(self, idx):
label = self._labels[idx]
image = cv2.imread(os.path.join(self._root_dir, self._image_paths[idx]), cv2.IMREAD_COLOR)
imgSize = image.shape # cv2��ȡ����ͼ���������� BGR H W C
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
if self._transform:
image = self._transform(image)
afterSize = image.shape
# bi = np.array(afterSize[0:2]) / np.array(imgSize[0:2])
# ����(x,y)��������w,h��ͼ����h,w,c�ĸ�ʽ,���Դ˴�������
bi = np.array((afterSize[1], afterSize[0])) / np.array((imgSize[1], imgSize[0]))
label[:, 0:2] = label[:, 0:2] * bi # ͼ�������任,����ͬ������
image = image.astype(np.float32)
# image = image.transpose((2, 0, 1))
return image, label, category
# ---�������ݼ�������---ͨ��Skimage��ȡͼ������---�������2
class DatasetBySkimage(KeyPointsDataSet):
def __getitem__(self, idx):
label = np.asfortranarray(self._labels[idx]) # (x, y, ����)=(��,��,������)
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
img_id = self._image_paths[idx]
img_id = os.path.join(self._root_dir, img_id)
image = io.imread(img_id) # (��,��,ͨ����)= (h, w, c)
imgSize = image.shape[0:2] # ԭʼͼ�����
if self._transform:
# image = self._transform(image) # self._transform�˴�������
image = transform.resize(image, output_shape=(256, 256)) # ʹ��skimage���Դ�transform
else:
image = transform.resize(image, output_shape=(256, 256)) # ʹ��skimage���Դ�transform
afterSize = image.shape[0:2] # ���ź�ͼ��Ŀ���
bi = np.array((afterSize[1], afterSize[0])) / np.array((imgSize[1], imgSize[0]))
label[:, 0:2] = label[:, 0:2] * bi
return image, label, category
# ---�������ݼ�������---ͨ��PIL.Image��ȡͼ������---�������3
class DatasetByPIL(KeyPointsDataSet):
def __getitem__(self, idx):
img_id = self._image_paths[idx]
img_id = os.path.join(self._root_dir, img_id)
image = Image.open(img_id).convert('RGB') # [3, 256, 256](ͨ����,��,��)= (c, h, w)
imgSize = image.size # ԭʼͼ�����
label = np.asfortranarray(self._labels[idx]) # (x, y, ����)=(��,��,������)
category = self._categories.index(self._cates[idx]) # 0,1,2,3,4
if self._transform:
image = self._transform(image) # ����torch.Size([3, 256, 256])
afterSize = image.numpy().shape[1:] # ���ź�ͼ��Ŀ���
else:
image.resize((256, 256)) # ʹ��resize
afterSize = (256, 256) # ���ź�ͼ��Ŀ���
bi = np.array(afterSize) / np.array(imgSize)
label[:, 0:2] = label[:, 0:2] * bi
return image, label, category
# ------�ܽӿ�------
class Content(object):
def __init__(self, root_dir, image_set='train', strategy='cv2', outsize=256):
"""
:param root_dir: ����Ŀ¼
:param image_set: train,val,test
:param strategy: cv2,skimage,pil
:param outsize:
"""
self.root_dir = root_dir
self.img_set = image_set
self.strategy = strategy
self.outsize = outsize
self._transform = None
self.set_transform()
self._data = None
self.crate_dataset()
def set_transform(self):
train_transform = None
val_transform = None
test_transform = None
if self.strategy == 'cv2':
train_transform = transforms.Compose([
ImageResize(size=self.outsize),
])
val_transform = train_transform
test_transform = transforms.Compose([
ImageResize(size=288),
RandomCrop(in_size=288, out_size=self.outsize), # ����ü�,���Կ���,��֤Ҳ������
RandomFlip(), # �����ת
RandomRotate(), # �����ת
Distort() # ����
])
if self.strategy == 'pil' or self.strategy == 'skimage':
# ѵ������֤������transform���任
train_transform = transforms.Compose([
transforms.Resize([self.outsize, self.outsize]), # ��ͼƬresize
transforms.ToTensor(), # ��ͼ��תΪTensor,���ݹ�һ���˚G!img.float().div(255)
])
val_transform = train_transform
# ���Լ�����test_transform���任
test_transform = transforms.Compose([
transforms.Resize([288, 288]), # ��ͼƬresizeΪ256*256
transforms.RandomCrop(self.outsize), # ����ü�,����ʱ�ޱ�ǩ
transforms.RandomHorizontalFlip(), # ˮƽ��ת
transforms.ToTensor(), # ��ͼ��תΪTensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ����
])
if self.img_set == 'train':
self._transform = train_transform
elif self.img_set == 'val':
self._transform = val_transform
elif self.img_set == 'test':
self._transform = test_transform
def crate_dataset(self):
if self.strategy == 'cv2':
self._data = DatasetByCv(self.root_dir, self.img_set, self._transform)
if self.strategy == 'skimage':
self._data = DatasetBySkimage(self.root_dir, self.img_set, self._transform)
if self.strategy == 'pil':
self._data = DatasetByPIL(self.root_dir, self.img_set, self._transform)
def get_dataLoader(self, batch_size=2, shuffle=False, num_workers=4, drop_last=True):
return DataLoader(self._data,
batch_size=batch_size,
shuffle=shuffle,
# num_workers=num_workers,
drop_last=drop_last
)
if __name__ == "__main__":
data_root = r'E:/Datasets/Fashion/Fashion AI-keypoints_24/train/' # �����ļ���:����train��test
num_workers = 4
content = Content(root_dir=data_root, image_set='train', strategy='pil', outsize=256)
train_loader = content.get_dataLoader()
print(len(train_loader))
for i_batch, data in enumerate(train_loader):
img, label, category = data
img, label, category = img.numpy(), label.numpy(), category.numpy() # 'torch.Tensor'����ֱ����ʾ,��Ҫת����io�ܴ�����numpy�����ʽ��
print(img.shape, label.shape, category)
# showImageAndCoor(img[0], label[0])
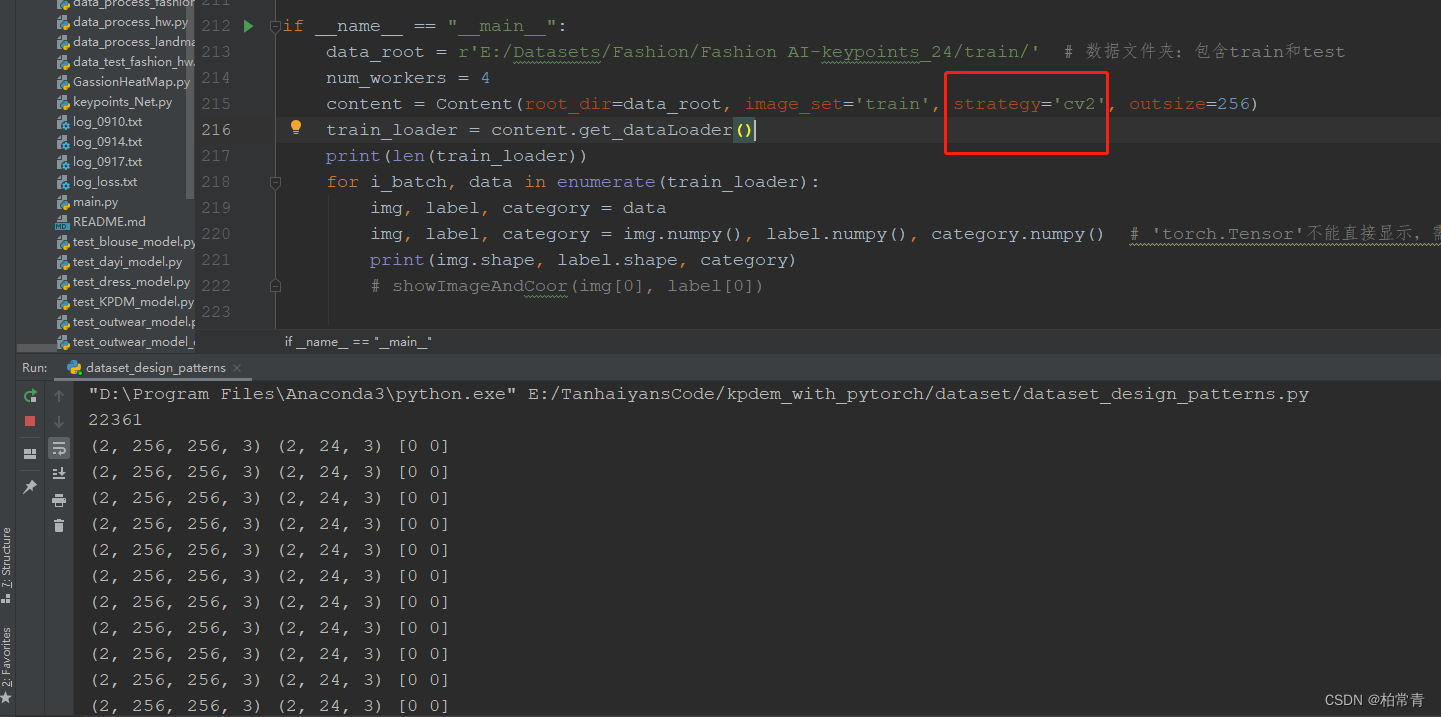
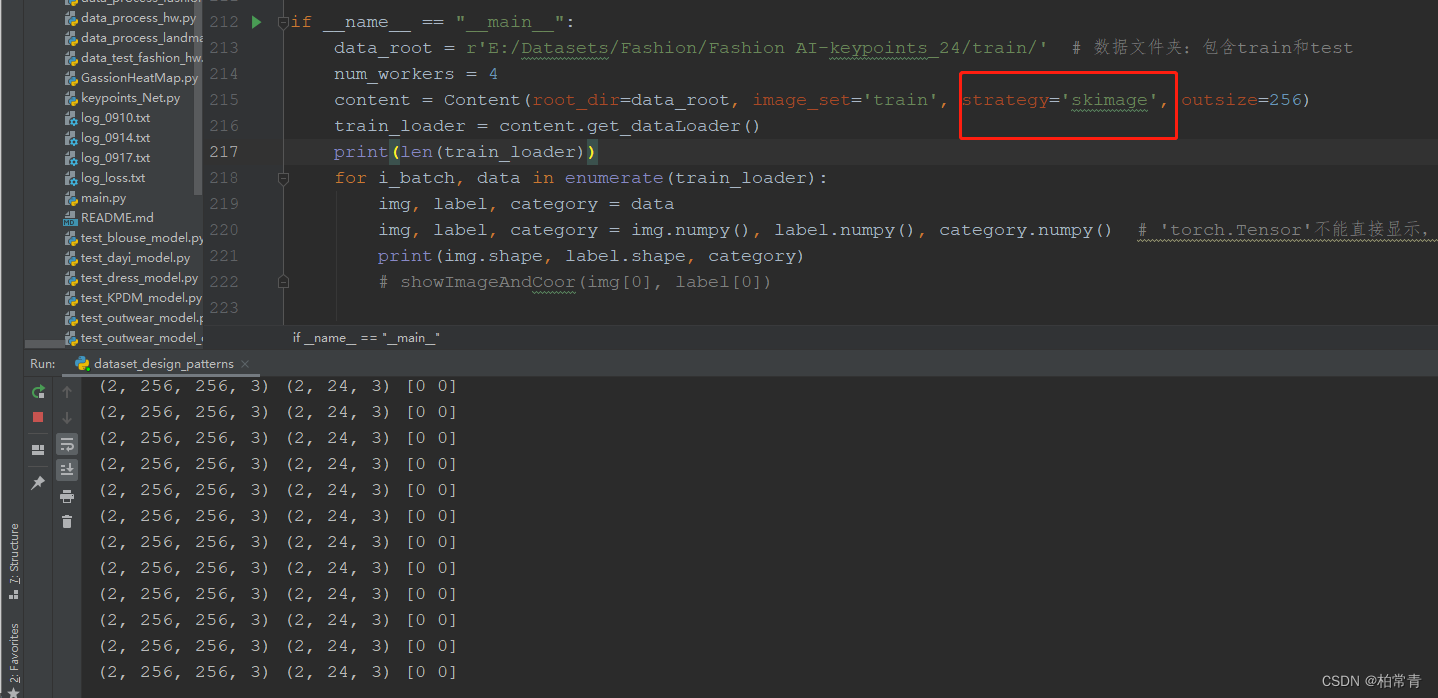
ѡ��ͬ�IJ���,�������ݼ��IJ��Խ��
1.ѡ��opencvͼ����������ͼ���ǩ���ݼ�
2. ѡ��skimageͼ����������ͼ���ǩ���ݼ�
3. ѡ��PIL.Imageͼ����������ͼ���ǩ���ݼ�
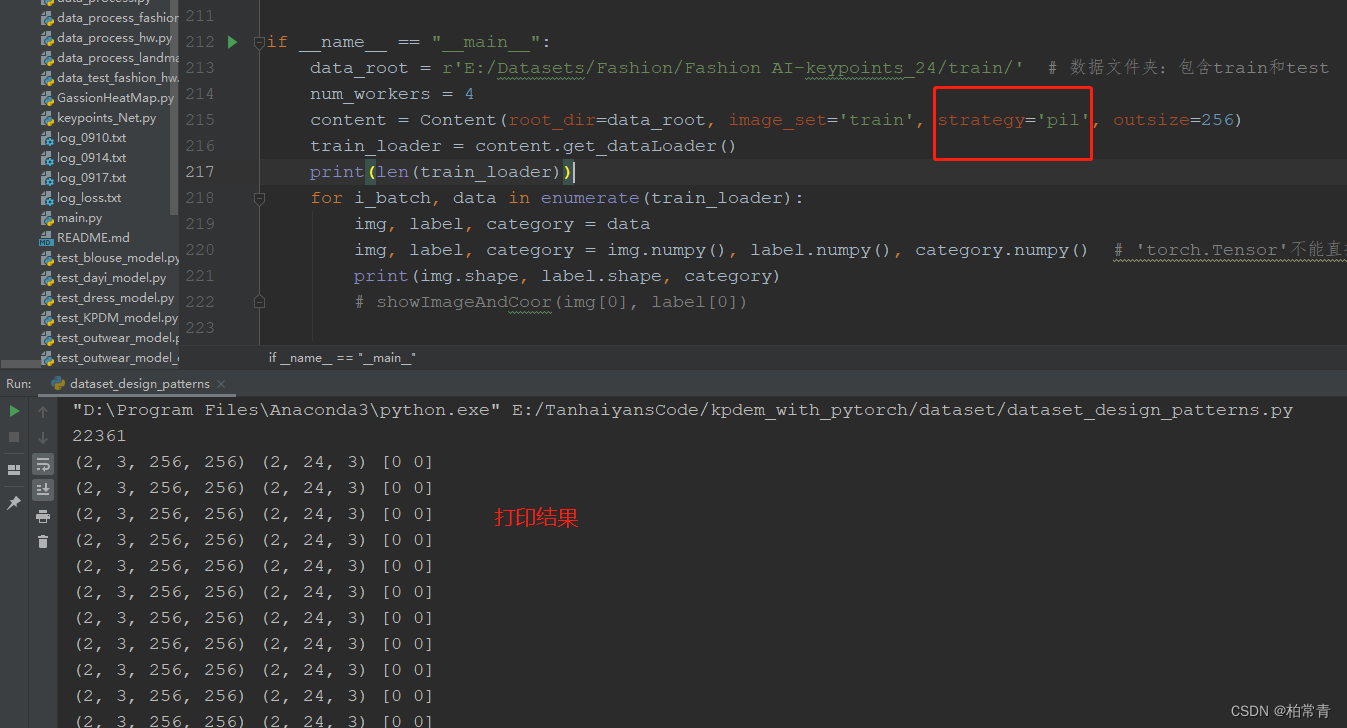
��������opencv-python������ͼ���ǩ���ݼ�
1)����һ:����opencv-python������ͼ���ǩ���ݼ�
��������scikit-image������ͼ���ǩ���ݼ�
2)������:����scikit-image������ͼ���ǩ���ݼ�
�ġ�����PIL.Imageͼ����������ͼ���ǩ���ݼ�
3)������:����PIL.Imageͼ����������ͼ���ǩ���ݼ�
�塢�ܽ�
�����������ݼ�������ÿһ�����ݡ�����Ҫ;�������ģʽд����,�����ҳɳ�������!
- 13�����ģʽ����
���ģʽ�Ķ���:Ϊ�˽���������ϵͳ����Ҫ���ظ�����Ʒ�װ��һ���һ�ִ���ʵ�ֿ��,����ʹ�ô������������չ�͵���
�ĸ�����Ҫ��:ģʽ����,����,�������,Ч�� - ��עÿһ��������ע������,�����ҵ�����ͽ�����⡣

