提示:仅仅是学习记录笔记,搬运了学习课程的ppt内容,本意不是抄袭!望大家不要误解!纯属学习记录笔记!!!!!!
文章目录
前言
一、模型拟合度概念介绍与实验
1.测试集的“不可知”悖论
机器学习模型主要通过模型在测试集上的运行效果来判断模型好坏,测试集相当于是“高考”,而此前的模型训练都相当于是在练习,但怎么样的练习才能有效的提高高考成绩,这里就存在一个“悖论”,那就是练习是为了高考,而在高考前我们永远不知道练习是否有效,那高考对于练习的核心指导意义何在?在机器学习领域,严格意义上的测试集是不能参与建模的,此处不能参与建模,不仅是指在训练模型时不能带入测试集进行训练,更是指当模型训练完成之后、观察模型在测试集上的运行结果后,也不能据此再进行模型修改(比如增加神经网络层数)。
机器学习建模的核心目标就是提升模型的泛化能力。而泛化能力指的是在模型未知数据集(没带入进行训练的数据集)上的表现,虽然测试集只能测一次,但我们还是希望有机会能把模型带入未知数据集进行测试,此时我们就需要一类新的数据集――验证集。验证集在模型训练阶段不会带入模型进行训练,但当模型训练结束之后,我们会把模型带入验证集进行计算,通过观测验证集上模型运行结果,判断模型是否要进行调整,验证集也会模型训练,只不过验证集训练的不是模型参数,而是模型超参数。
总的来说,在模型训练和观测模型运行结果的过程总共涉及三类数据集,分别是训练集、验证集和测试集。不过由于测试集定位特殊,在一些不需要太严谨的场景下,有时也会混用验证集和测试集的概念,我们常常听到“测试集效果不好、重新调整模型”等等,都是混用了二者概念,由于以下是模拟练习过程,暂时不做测试集和验证集的区分。在不区分验证集和测试集的情况下,当数据集切分完成后,对于一个模型来说,我们能够获得两套模型运行结果,一个是训练集上模型效果,一个是测试集上模型效果,而这组结果,就将是整个模型优化的基础数据。
2.模型拟合度概念与实验
能够有较好的未知数据的预测效果。但限制模型捕捉总体规律的原因主要有两点:
其一,样本数据能否很好的反应总体规律
如果样本数据本身无法很好的反应总体规律,那建模的过程就算捕捉到了规律可能也无法适用于未知数据。举个极端的例子,在进行反欺诈检测时,如果要基于并未出现过欺诈案例的历史数据来进行建模,那模型就将面临无规律可捕捉的窘境,当然,确切的说,是无可用规律可捕捉;或者,当扰动项过大时,噪声也将一定程度上掩盖真实规律。
其二,样本数据能反应总体规律,但模型没有捕捉到
如果说要解决第一种情况需要在数据获取端多下功夫,那么如果数据能反应总体规律而模型效果不佳,则核心原因就在模型本身了。此前介绍过,机器学习模型评估主要依据模型在测试集上的表现,如果测试集效果不好,则我们认为模型还有待提升,但导致模型在测试集上效果不好的原因其实也主要有两点,其一是模型没捕捉到训练集上数据的规律,其二则是模型过分捕捉训练集上的数据规律,导致模型捕获了大量训练集独有的、无法适用于总体的规律(局部规律),而测试集也是从总体中来,这些规律也不适用于测试集。前一种情况我们称模型为欠拟合,后一种情况我们称模型为过拟合,我们可以通过以下例子进行进一步了解:
#设置随机数种子
np.random.seed(123)
#创建数据
n_dots = 20
x = np.linspace(0, 1, n_dots)
y = np.sqrt(x) + 0.2 * np.random.rand(n_dots) - 0.1
其中,x是一个0到1之间等距分布20个点组成的数组,y等于x开平方根+扰动项,其中np.random.rand(n_dots)是生成了20个在0-1之间均匀分布的点。
y0 = x ** 2
a = np.polyfit(x, y0, 2) #计算得到一个关于x的二次方函数,y=ax**2+bx+c
#根据这个函数,我们可以得到所有的参数值
#print(a)
#[1.00000000e+00 2.18697767e-17 1.61618518e-17]
#用ploy1d逆向构造多项式方程
p = np.poly1d(a)
print(p)
'''
2
1 x + 2.187e-17 x + 1.616e-17
'''
接下来,进行多项式拟合。分别利用1阶x多项式、3阶x多项式和10阶x多项式来拟合y。并利用图形观察多项式的拟合度,首先我们可定义一个辅助画图函数,方便后续我们将图形画于一张画布中,进而方便观察
#创建数据
n_dots = 20
x = np.linspace(0, 1, n_dots)
y = np.sqrt(x) + 0.2 * np.random.rand(n_dots) - 0.1
y0 = x ** 2
a = np.polyfit(x, y0, 2) #计算得到一个关于x的二次方函数,y=ax**2+bx+c
#根据这个函数,我们可以得到所有的参数值
#print(a)
#[1.00000000e+00 2.18697767e-17 1.61618518e-17]
#用ploy1d逆向构造多项式方程
p = np.poly1d(a)
print(p)
'''
2
1 x + 2.187e-17 x + 1.616e-17
'''
def plot_polynomial_fit(x, y, deg):
p = np.poly1d(np.polyfit(x, y, deg))
t = np.linspace(0, 1, 200)
plt.plot(x, y, 'ro')
plt.plot(t, p(t), '-')
plt.plot(t, np.sqrt(t), 'r--')
plot_polynomial_fit(x, y, 3)
plt.show()
对比一下欠拟合、拟合和过拟合的图像
plt.figure(figsize=(18, 4), dpi=200)
titles = ['Under Fitting', 'Fitting', 'Over Fitting']
for index, deg in enumerate([1, 3, 10]):
plt.subplot(1, 3, index+1)
plot_polynomial_fit(x, y, deg)
plt.title(titles[index], fontsize=20)
plt.show()
根据最终的输出结果我们能够清楚的看到,1阶多项式拟合的时候蓝色拟合曲线即无法捕捉数据集的分布规律,离数据集背后客观规律也很远,而三阶多项式在这两方面表现良好,十阶多项式则在数据集分布规律捕捉上表现良好,单同样偏离红色曲线较远。此时一阶多项式实际上就是欠拟合,而十阶多项式则过分捕捉噪声数据的分布规律,而噪声之所以被称作噪声,是因为其分布本身毫无规律可言,或者其分布规律毫无价值(如此处噪声分布为均匀分布),因此就算十阶多项式在当前训练数据集上拟合度很高,但其捕捉到的无用规律无法推广到新的数据集上,因此该模型在测试数据集上执行过程将会有很大误差。即模型训练误差很小,但泛化误差很大。
因此,我们有基本结论如下:
模型欠拟合:训练集上误差较大
模型过拟合:训练集上误差较小,但测试集上误差较大
而模型是否出现欠拟合或者过拟合,其实和模型复杂度有很大关系。我们通过上述模型不难看出,模型越复杂,越有能力捕捉训练集上的规律,因此如果模型欠拟合,我们可以通过提高模型复杂度来进一步捕捉规律,但同时也会面临模型过于复杂而导致过拟合的风险。
二、模型欠拟合实例
首先我们来讨论模型欠拟合时,通过提升模型复杂度提升模型效果的基本方法。当然,从神经网络整体模型结构来看,提升复杂度只有两种办法,其一是修改激活函数,在神经元内部对加权求和汇总之后的值进行更加复杂的处理,另一种方法则是添加隐藏层,包括隐藏层层数和每一层隐藏层的神经元个数。接下来我们通过一些列实验来查看相关效果。
还是多元线性回归的例子,如果是高次项方程,通过简单的线性网络拟合就会出现欠拟合的情况。
#设置随机种子
torch.manual_seed(420)
#创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
#print(features)
#绘制图像查看数据分别
plt.subplot(121)
plt.scatter(features[:, 0], labels)
plt.subplot(122)
plt.scatter(features[:, 1], labels)
plt.show()
我们分别查看一下两个特征和标签之间的关系
#设置随机种子
torch.manual_seed(420)
#创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
#print(features)
train_loader, test_loader = split_loader(features, labels)
#封装好的已经切分好的训练集和测试集
#训练模型
#首先定义简单线性回归模型
class LR(nn.Module):
def __init__(self, in_puts=2, out_puts=1):
super(LR, self).__init__()
self.linear = nn.Linear(in_puts, out_puts)
def forward(self,x):
out = self.linear(x)
return out
#然后执行模型训练
torch.manual_seed(420)
#实例化模型
LR = LR()
train_l = [] #列表容器,存储训练误差
test_l = [] #列表容器,存储测试误差
num_epochs = 20
#执行循环
for epoch in range(num_epochs):
fit(net=LR,
criterion=nn.MSELoss(),
optimizer=optim.SGD(LR.parameters(), lr=0.03),
batchdata=train_loader,
epochs=epoch)
train_l.append(mse_cal(train_loader, LR).detach().numpy())
test_l.append(mse_cal(test_loader, LR).detach().numpy())
#绘制图像,查看MSE变化情况
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.legend(loc=1)
plt.show()
构建一个可以查看训练集和测试集误差表现的函数
#设置随机种子
torch.manual_seed(420)
#创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
#print(features)
train_loader, test_loader = split_loader(features, labels)
#构建新函数
#构建新函数
def model_train_test(model,
train_data,
test_data,
num_epochs=20,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=0.03,
cla=False,
eva=mse_cal):
"""模型误差测试函数:
:param model_l:模型
:param train_data:训练数据
:param test_data: 测试数据
:param num_epochs:迭代轮数
:param criterion: 损失函数
:param lr: 学习率
:param cla: 是否是分类模型
:return:MSE列表
"""
# 模型评估指标列表
train_l = []
test_l = []
# 模型训练过程
for epochs in range(num_epochs):
fit(net=model,
criterion=criterion,
optimizer=optimizer(model.parameters(), lr=lr),
batchdata=train_data,
epochs=epochs,
cla=cla)
train_l.append(eva(train_data, model).detach())
test_l.append(eva(test_data, model).detach())
return train_l, test_l
#测试模型效果
torch.manual_seed(420)
#实例化
LR=LR()
#模型训练
train_l, test_l = model_train_test(LR,
train_loader,
test_loader,
num_epochs = 20,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr=0.03,
cla=False,
eva=mse_cal)
plt.plot(list(range(20)), train_l, label='train_mse')
plt.plot(list(range(20)), test_l, label='test_mse')
plt.legend(loc=1)
plt.show()
然后我们增加模型的复杂度。这里我们构建了一个两层都是线性层的神经网络,并且没有加入激活函数。对于神经网络来说,复杂模型的构建就是Module的叠加,核心需要注意整个传播过程计算流程是否完整。
class LR_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1): # 此处隐藏层设置四个激活函数
super(LR_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden)
self.linear2 = nn.Linear(n_hidden, out_features)
def forward(self, x):
z1 = self.linear1(x)
out = self.linear2(z1)
return out
torch.manual_seed(420)
# 实例化模型
LR1 = LR_class1()
# 模型训练
train_l, test_l = model_train_test(LR1,
train_loader,
test_loader,
num_epochs = 20,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
num_epochs = 20
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.legend(loc = 1)
plt.show()
我们发现,结果没有显著提升,但模型稳定性却有所提升。对于叠加线性层的神经网络模型来说,由于模型只是对数据仿射变换,因此并不能满足拟合高次项的目的。也就是说,在增加模型复杂度的过程中,首先需要激活函数的配合,然后再是增加模型的层数和每层的神经元个数。
三、激活函数性能比较
常用激活函数对比
class LR_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1): # 此处隐藏层设置四个激活函数
super(LR_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden)
self.linear2 = nn.Linear(n_hidden, out_features)
def forward(self, x):
z1 = self.linear1(x)
out = self.linear2(z1)
return out
# Sigmoid激活函数
class Sigmoid_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1, bias=True):
super(Sigmoid_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
out = self.linear2(p1)
return out
#tahn激活函数
class tanh_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1, bias=True):
super(tanh_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.tanh(z1)
out = self.linear2(p1)
return out
# ReLU激活函数
class ReLU_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1, bias=True):
super(ReLU_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.relu(z1)
out = self.linear2(p1)
return out
#实例化模型
torch.manual_seed(420)
LR1 = LR_class1()
sigmoid_model1 = Sigmoid_class1()
tanh_model1 = tanh_class1()
relu_model1 = ReLU_class1()
model_l = [LR1, sigmoid_model1, tanh_model1, relu_model1]
name_l = ['LR1', 'sigmoid_model1', 'tanh_model1', 'relu_model1']
#定义核心参数
num_epochs = 30
lr = 0.03
#定义训练集、测试集MSE存储张量
mse_train = torch.zeros(len(model_l), num_epochs)
mse_test = torch.zeros(len(model_l), num_epochs)
#训练模型
for epochs in range(num_epochs):
for i, model in enumerate(model_l):
fit(net=model,criterion=nn.MSELoss(), optimizer=optim.SGD(model.parameters(), lr=lr), batchdata=train_loader, epochs=epochs)
mse_train[i][epochs] = mse_cal(train_loader, model).detach()
mse_test[i][epochs] = mse_cal(test_loader,model).detach()
#print(mse_train)
#print(mse_test)
#- 绘制图形观察结果
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), mse_train[i], label=name)
plt.legend(loc=1)
plt.title('mse_train')
plt.show()
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), mse_test[i], label=name)
plt.legend(loc=1)
plt.title('mse_test')
plt.show()
激活函数性能简介与应用场景
根据当前的应用实践来看,ReLU激活函数是目前使用面最广、效果也相对更好的一种激活函数,但这并不代表tanh和Sigmoid激活函数就没有应用场景(比如RNN、LSTM模型仍然偏爱tanh和Sigmoid)。不同的激活函数拥有不同的特性,同时激活函数在复杂神经网络中的应用也是需要优化方法支持的,并且伴随着ReLU激活函数的不断应用,目前ReLU已经衍生出了一个激活函数簇,相关内容我们将在下一节详细讨论。
由于模型对比将是优化实验的常规操作,因此考虑将上述过程封装为一个函数:
def model_comparison(model_l, name_l, train_data,test_data,num_epochs=20, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = 0.03, cla = False, eva = mse_cal):
"""模型对比函数:
:param model_l:模型序列
:param name_l:模型名称序列
:param train_data:训练数据
:param test_data:测试数据
:param num_epochs:迭代轮数
:param criterion: 损失函数
:param lr: 学习率
:param cla: 是否是分类模型
:return:MSE张量矩阵
"""
# 模型评估指标矩阵
train_l = torch.zeros(len(model_l), num_epochs)
test_l = torch.zeros(len(model_l), num_epochs)
# 模型训练过程
for epochs in range(num_epochs):
for i, model in enumerate(model_l):
fit(net=model,
criterion=criterion,
optimizer=optimizer(model.parameters(), lr=lr),
batchdata=train_data,
epochs=epochs,
cla=cla)
train_l[i][epochs] = eva(train_data, model).detach()
test_l[i][epochs] = eva(test_data, model).detach()
return train_l, test_l
四、构建复杂神经网络
1.ReLU激活函数叠加
首先是ReLU激活函数的叠加,那么我们考虑添加几层隐藏层并考虑在隐藏层中使用ReLU函数,也就是所谓的添加ReLU层。此处我们在ReLU_class1的基础上创建ReLU_class2结构如下:
class ReLU_class2(nn.Module):
def __init__(self, in_features=2, n_hidden_1=4, n_hidden_2=4, out_features=1, bias=True):
super(ReLU_class2, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden_1, bias=bias)
self.linear2 = nn.Linear(n_hidden_1, n_hidden_2, bias=bias)
self.linear3 = nn.Linear(n_hidden_2, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.relu(z1)
z2 = self.linear2(p1)
p2 = torch.relu(z2)
out = self.linear3(p2)
return out
#接下来,借助model_comparison函数进行模型性能测试
torch.manual_seed(24)
# 实例化模型
relu_model1 = ReLU_class1()
relu_model2 = ReLU_class2()
# 模型列表容器
model_l = [relu_model1, relu_model2]
name_l = ['relu_model1', 'relu_model2']
# 核心参数
num_epochs = 20
lr = 0.03
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
?我们发现,模型效果并没有明显提升,反而出现了更多的波动,迭代收敛速度也有所下降。模型效果无法提升是不是因为模型还不够复杂,如果继续尝试添加隐藏层会有什么效果?
# 构建三个隐藏层的神经网络
class ReLU_class3(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, out_features=1, bias=True):
super(ReLU_class3, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1, bias=bias)
self.linear2 = nn.Linear(n_hidden1, n_hidden2, bias=bias)
self.linear3 = nn.Linear(n_hidden2, n_hidden3, bias=bias)
self.linear4 = nn.Linear(n_hidden3, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.relu(z1)
z2 = self.linear2(p1)
p2 = torch.relu(z2)
z3 = self.linear3(p2)
p3 = torch.relu(z3)
out = self.linear4(p3)
return out
# 构建四个隐藏层的神经网络
class ReLU_class4(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, n_hidden4=4, out_features=1, bias=True):
super(ReLU_class4, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1, bias=bias)
self.linear2 = nn.Linear(n_hidden1, n_hidden2, bias=bias)
self.linear3 = nn.Linear(n_hidden2, n_hidden3, bias=bias)
self.linear4 = nn.Linear(n_hidden3, n_hidden4, bias=bias)
self.linear5 = nn.Linear(n_hidden4, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.relu(z1)
z2 = self.linear2(p1)
p2 = torch.relu(z2)
z3 = self.linear3(p2)
p3 = torch.relu(z3)
z4 = self.linear4(p3)
p4 = torch.relu(z4)
out = self.linear5(p4)
return out
# 创建随机数种子
torch.manual_seed(24)
# 实例化模型
relu_model1 = ReLU_class1()
relu_model2 = ReLU_class2()
relu_model3 = ReLU_class3()
relu_model4 = ReLU_class4()
# 模型列表容器
model_l = [relu_model1, relu_model2, relu_model3, relu_model4]
name_l = ['relu_model1', 'relu_model2', 'relu_model3', 'relu_model4']
# 核心参数
num_epochs = 20
lr = 0.03
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc=4)
plt.title('mse_train')
plt.show()
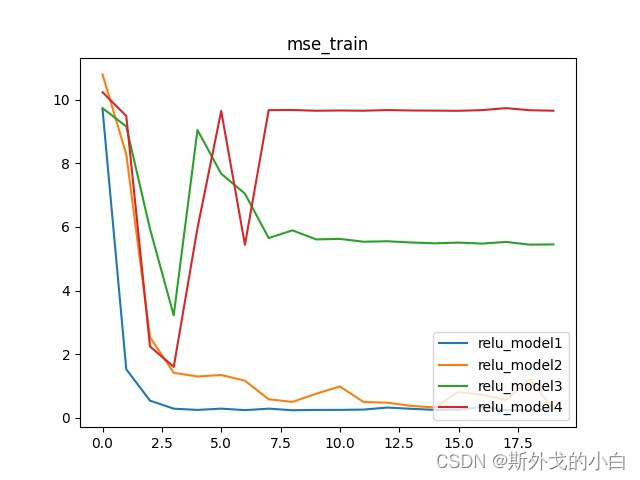
从上图可以看出,随着rule隐藏层的增加,我们的loss不仅没有减小,反而变得不收敛了,此处ReLU激活函数叠加后出现的模型失效问题,也就是Dead ReLU Problem。
2.Sigmoid激活函数叠加
class Sigmoid_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1, bias=True):
super(Sigmoid_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
out = self.linear2(p1)
return out
class Sigmoid_class2(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, out_features=1):
super(Sigmoid_class2, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
z2 = self.linear2(p1)
p2 = torch.sigmoid(z2)
out = self.linear3(p2)
return out
class Sigmoid_class3(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, out_features=1):
super(Sigmoid_class3, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, n_hidden3)
self.linear4 = nn.Linear(n_hidden3, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
z2 = self.linear2(p1)
p2 = torch.sigmoid(z2)
z3 = self.linear3(p2)
p3 = torch.sigmoid(z3)
out = self.linear4(p3)
return out
class Sigmoid_class4(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, n_hidden4=4, out_features=1):
super(Sigmoid_class4, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, n_hidden3)
self.linear4 = nn.Linear(n_hidden3, n_hidden4)
self.linear5 = nn.Linear(n_hidden4, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.sigmoid(z1)
z2 = self.linear2(p1)
p2 = torch.sigmoid(z2)
z3 = self.linear3(p2)
p3 = torch.sigmoid(z3)
z4 = self.linear4(p3)
p4 = torch.sigmoid(z4)
out = self.linear5(p4)
return out
# 创建随机数种子
torch.manual_seed(24)
# 实例化模型
sigmoid_model1 = Sigmoid_class1()
sigmoid_model2 = Sigmoid_class2()
sigmoid_model3 = Sigmoid_class3()
sigmoid_model4 = Sigmoid_class4()
# 模型列表容器
model_l = [sigmoid_model1, sigmoid_model2, sigmoid_model3, sigmoid_model4]
name_l = ['sigmoid_model1', 'sigmoid_model2', 'sigmoid_model3', 'sigmoid_model4']
# 核心参数
num_epochs = 50
lr = 0.03
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
sigmoid激活函数的简单叠加也出现了很多问题,虽然没有像ReLU叠加一样出现大幅MSE升高的情况,但仔细观察,不难发现,对于model1、model2、model3来说,伴随模型复杂增加,模型效果没有提升,但收敛速度却下降的很严重,而model4更是没有收敛到其他几个模型的MSE,问题不小。不过相比ReLU激活函数,整体收敛过程确实稍显稳定,而Sigmoid也是老牌激活函数,在2000年以前,是最主流的激活函数。
此处Sigmoid激活函数堆叠后出现的问题,本质上就是梯度消失所导致的问题。
3.tanh激活函数叠加
class tanh_class1(nn.Module):
def __init__(self, in_features=2, n_hidden=4, out_features=1, bias=True):
super(tanh_class1, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden, bias=bias)
self.linear2 = nn.Linear(n_hidden, out_features, bias=bias)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.tanh(z1)
out = self.linear2(p1)
return out
class tanh_class2(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, out_features=1):
super(tanh_class2, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.tanh(z1)
z2 = self.linear2(p1)
p2 = torch.tanh(z2)
out = self.linear3(p2)
return out
class tanh_class3(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, out_features=1):
super(tanh_class3, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, n_hidden3)
self.linear4 = nn.Linear(n_hidden3, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.tanh(z1)
z2 = self.linear2(p1)
p2 = torch.tanh(z2)
z3 = self.linear3(p2)
p3 = torch.tanh(z3)
out = self.linear4(p3)
return out
class tanh_class4(nn.Module):
def __init__(self, in_features=2, n_hidden1=4, n_hidden2=4, n_hidden3=4, n_hidden4=4, out_features=1):
super(tanh_class4, self).__init__()
self.linear1 = nn.Linear(in_features, n_hidden1)
self.linear2 = nn.Linear(n_hidden1, n_hidden2)
self.linear3 = nn.Linear(n_hidden2, n_hidden3)
self.linear4 = nn.Linear(n_hidden3, n_hidden4)
self.linear5 = nn.Linear(n_hidden4, out_features)
def forward(self, x):
z1 = self.linear1(x)
p1 = torch.tanh(z1)
z2 = self.linear2(p1)
p2 = torch.tanh(z2)
z3 = self.linear3(p2)
p3 = torch.tanh(z3)
z4 = self.linear4(p3)
p4 = torch.tanh(z4)
out = self.linear5(p4)
return out
# 创建随机数种子
torch.manual_seed(42)
# 实例化模型
tanh_model1 = tanh_class1()
tanh_model2 = tanh_class2()
tanh_model3 = tanh_class3()
tanh_model4 = tanh_class4()
# 模型列表容器
model_l = [tanh_model1, tanh_model2, tanh_model3, tanh_model4]
name_l = ['tanh_model1', 'tanh_model2', 'tanh_model3', 'tanh_model4']
# 核心参数
num_epochs = 50
lr = 0.03
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
tanh激活函数叠加效果中规中矩,在model1到model2的过程效果明显向好,MSE基本一致、收敛速度基本一致、但收敛过程稳定性较好,也证明模型结果较为可信,而model3、model4则表现出了和前面两种激活函数在叠加过程中所出现的类似的问题,当然对于tanh来说,最明显的问题是出现了剧烈波动,甚至出现了**“跳跃点”**。
五、神经网络结构选择策略
1.参数和超参数
在机器学习中,参数其实分为两类,其一是参数,其二则是超参数。
一个影响模型的变量是参数还是超参数,核心区别就在于这个变量的取值能否通过一个严谨的数学过程求出,如果可以,我们就称其为参数,如果不行,我们就称其为超参数。典型的,如简单线性回归中的自变量的权重,我们通过最小二乘法或者梯度下降算法,能够求得一组全域最优解,因此自变量的权重就是参数,类似的,复杂神经网络中的神经元连接权重也是参数。但除此以外,还有一类影响模型效果的变量却无法通过构建数学方程、然后采用优化算法算得最优解,典型的如训练集和测试集划分比例、神经网络的层数、每一层神经元个数等等,这些变量同样也会影响模型效果,但由于无法通过数学过程求得最优解,很多时候我们都是凭借经验设置数值,然后根据建模结果再进行手动调节,这类变量我们称其为超参数。 ??
不难发现,在实际机器学习建模过程中超参数出现的场景并不比参数出现的场景少,甚至很多时候,超参数的边界也和我们如何看待一个模型息息相关,例如,如果我们把“选什么模型”也看成是一个最终影响建模效果的变量,那这个变量也是一个超参数。也就是说,超参数也就是由“人来决策”的部分场合,而这部分也就是体现算法工程师核心竞争力的环节。 ??
当然,就像此前介绍的那样,参数通过优化算法计算出结果,而机器学习发展至今,也出现了很多辅助超参数调节的工具,比如网格搜索(grid search)、AutoML等,但哪怕是利用工具调整超参数,无数前辈在长期实践积累下来的建模经验仍然是弥足珍贵的,也是我们需要不断学习、不断理解,当然,更重要的是,所有技术人经验的积累是一个整体,因此也是需要我们参与分享的。
2.神经网络模型结构选择策略
**三层以内:**模型效果会随着层数增加而增加;
**三层至六层:**随着层数的增加,模型的稳定性迭代的稳定性会受到影响,并且这种影响是随着层数增加“指数级”增加的,此时我们就需要采用一些优化方法对输入数据、激活函数、损失函数和迭代过程进行优化,一般来说在六层以内的神经网络在通用的优化算法配合下,是能够收敛至一个较好的结果的;
**六层以上:**在模型超过六层之后,优化方法在一定程度上仍然能够辅助模型训练,但此时保障模型正常训练的更为核心的影响因素,就变成了数据量本身和算力。神经网络模型要迭代收敛至一个稳定的结果,所需的epoch是随着神经网络层数增加而增加的,也就是说神经网络模型越复杂,收敛所需迭代的轮数就越多,此时所需的算力也就越多。而另一方面,伴随着模型复杂度增加,训练所需的数据量也会增加,如果是复杂模型应用于小量样本数据,则极有可能会出现“过拟合”的问题从而影响模型的泛化能力。当然,伴随着模型复杂度提升、所需训练数据增加,对模型优化所采用的优化算法也会更加复杂。也就是说,六层以内神经网络应对六层以上的神经网络模型,我们需要更多的算力支持、更多的数据量、以及更加复杂的优化手段支持。
因此,对于大多数初中级算法工程师来说,如果不是借助已有经典模型而是自己构建模型的话,不建议搭建六层以上的神经网络模型。而关于通用优化方法,将在下一节开始逐步介绍。
另外,值得一提的是,经验是对过去的一般情况的总结,并不代表所有情况,同时也不代表对未来的预测。同时,上述规则适用于自定义神经网络模型的情况,很多针对某一类问题的经典深度学习架构会有单独的规则。
3.激活函数使用的单一性
同时,对于激活函数的交叉使用,我们需要知道,通常来说,是不会出现多种激活函数应用于一个神经网络中的情况的。主要原因并不是因为模型效果就一定会变差,而是如果几种激活函数效果类似,那么交叉使用几种激活函数其实效果和使用一种激活函数区别不大,而如果几种激活函数效果差异非常明显,那么这几种激活函数的堆加就会使得模型变得非常不可控。此前的实验让我们深刻体会优化算法的必要性,但目前工业界所掌握的、针对激活函数的优化算法都是针对某一种激活函数来使用的,激活函数的交叉使用会令这些优化算法失效。因此,尽管机器学习模型是“效果为王”,但在基础理论没有进一步突破之前,不推荐在一个神经网路中使用多种激活函数。

