摘要:
? ? ? 本文提出了一种基于 GAN 的无监督去雾算法来缓解这个问题。 建立了一个基于 GAN 架构的端到端网络,并提供了未配对的干净和朦胧图像,这意味着不需要估计大气光和传输。 所提出的网络由三部分组成:生成器、全局测试鉴别器和局部上下文鉴别器。 此外,应用基于暗通道先验的注意机制来处理不一致的雾度。 使用?RESIDE 数据集进行实验。 大量实验证明了所提出方法的有效性,该方法在很大程度上优于以前最先进的无监督方法。
本文提出了一种具有未配对模糊和清晰图像的生成对抗网络训练。
与其他无监督方法相比,取得了最先进的结果。我们的模型中没有使用循环一致损失,从而更容易训练和收敛模型。
主要贡献:
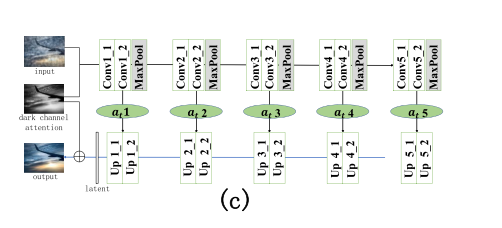
- 提出了一种基于U-net体系结构的端到端生成式对抗网络训练方案。我们使用无监督的模糊清晰图像来训练模型。除了对抗性损失之外,我们还引入了感知损失来评估模糊图像和去雾图像的VGG特征之间的差异。
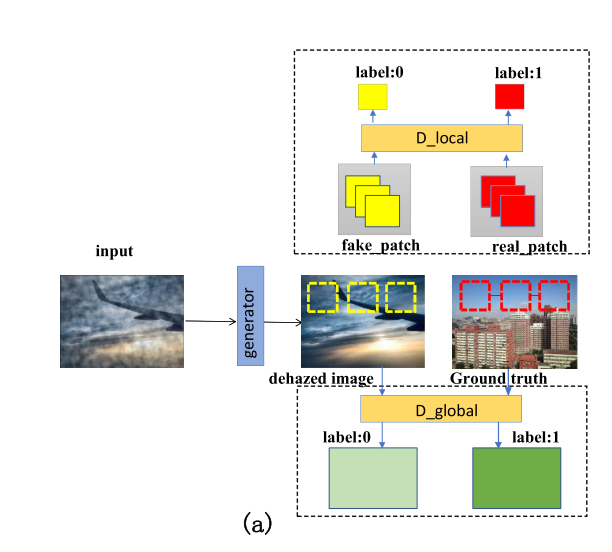
- 我们采用全球-本地鉴别器。全局鉴别器查看整个图像以评估其整体一致性,而局部鉴别器仅查看以完成区域为中心的小区域,以确保生成的补丁的局部一致性。全局-局部鉴别器可以帮助模型处理空间变化的烟雾,并生成更清晰的图像
- 在进一步处理图像中急剧变化的局部区域之前,我们提出了一种受暗通道启发的注意力机制。模糊图像的暗通道图被提取并缩放以与模型中的特征融合。所提出的工作更健壮,可以更好地保留图像的细节。
?提出的方法
? ? ? ? 本文设计了两个鉴别器而不是一个来鉴别生成图像的质量。 全局鉴别器扫描整个图像,局部鉴别器扫描补丁输入以获得高质量的重建。 在此基础上,本文将注意力机制作为网络的函数引入,设计了在各种情况下都能获得满意去雾效果的注意力图。?
????????雾霾区域和浓度通常是局部的且不均匀的,因此我们在去雾方法中引入了注意力机制。 受暗通道可以有效反映面积和浓度的启发,我们提出了暗通道注意机制。 当场景的深度变深时,图像中的雾度会变重,而暗通道图中的值会变大。
? ? ? ? 仅仅引入了一个生成器,没有循环转换过程;同时引入了两个鉴别器进行高质量的重建和一个暗通道注意力图,以在转换过程中关注去雾区域。
单个GAN模型
?????????我们的目标是学习从模糊图像域 X 到去雾图像域 Y 的直接映射,给定训练样本![]() 其中 xi ∈ X 和
其中 xi ∈ X 和 ![]() 其中 yj ∈ Y?。 我们将数据分布表示为
其中 yj ∈ Y?。 我们将数据分布表示为![]() 和
和![]() ?)。 如图 1 所示,我们的模型包括一个映射 G : X → Y,它的鉴别器 D 区分去雾图像 {G(x)} 和 {y}?,其中 {x, y} 指的是模糊和未配对的地面实况图像集。 我们使用 LSGAN 损失作为目标:
?)。 如图 1 所示,我们的模型包括一个映射 G : X → Y,它的鉴别器 D 区分去雾图像 {G(x)} 和 {y}?,其中 {x, y} 指的是模糊和未配对的地面实况图像集。 我们使用 LSGAN 损失作为目标:
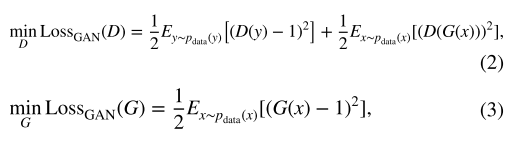
?????????其中 G 试图生成看起来像无雾图像的 G(x),而 D 旨在区分去雾图像 G(x) 和未配对的地面实况样本 y。 ?D 的目标是 D(G(x)) 接近 0,而 G 的目标是接近 1。
注意力机制
??????????受DCP之前的暗通道启发。 在 CycleGAN 中使用暗通道特征。 他们使用暗通道图作为透射,并用大气散射模型恢复图像。 最终映射只发生在最后一层。 在我们的例子中,我们将暗通道图缩放到各种大小,并生成具有每一层特征的元素乘积。
????????暗通道注意力图如下获得:

????????其中![]() 是原始的暗通道方法,Ω(x) 是以x为中心的区域,
是原始的暗通道方法,Ω(x) 是以x为中心的区域,![]() 是颜色通道。与模糊图像相比,暗通道的强度相对较低。因此,对增强系数
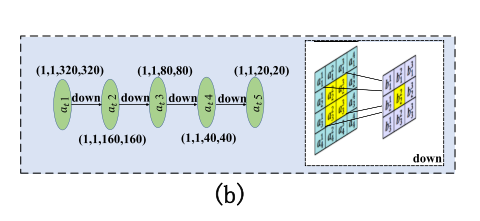
是颜色通道。与模糊图像相比,暗通道的强度相对较低。因此,对增强系数![]() 进行了训练,以使暗通道更适合作为等式(5) 表示。暗通道注意图用maxpooling连续下采样四次,得到不同尺度的特征图,分别为at2、at3、at4和at5,如图b所示。然后将它们作为解码器中的注意初始化因子,在生成网络编码器中乘以maxpooling后的特征图,并添加到解码器中相应比例的上采样特征图,以完成跳过连接。这里使用双线性插值进行上采样。然后进行反卷积以提取特征以完成潜和原始输入,如下所示,以获得最终输出。输出 = 潜在特征 + 注意力 × 输入。?
进行了训练,以使暗通道更适合作为等式(5) 表示。暗通道注意图用maxpooling连续下采样四次,得到不同尺度的特征图,分别为at2、at3、at4和at5,如图b所示。然后将它们作为解码器中的注意初始化因子,在生成网络编码器中乘以maxpooling后的特征图,并添加到解码器中相应比例的上采样特征图,以完成跳过连接。这里使用双线性插值进行上采样。然后进行反卷积以提取特征以完成潜和原始输入,如下所示,以获得最终输出。输出 = 潜在特征 + 注意力 × 输入。?
?整体模型
注意力图缩放过程?
带有注意机制的生成器?
?????????本地鉴别器
?????????去雾时生成器网络中的缩小和放大过程会导致图像质量下降,因此我们构建了两个鉴别器以充分利用上下文和局部上下文。在训练时,全局判别器将重新缩放到 320?×?320 的整个图像作为输入。它由六个卷积层组成,并以一个 512 维的全连接层结束。一切卷积层采用 2 × 2 像素的步幅来降低图像分辨率,同时增加输出滤波器的数量,它们使用 3 × 3 内核。 本地鉴别器具有类似的架构,仅将补丁作为输入。 这些补丁是从整个图像中随机裁剪的 32 × 32 像素。 同时,局部鉴别器有五个卷积层和一个 512 维的全连接层。 全局和局部鉴别器各有一个目标:
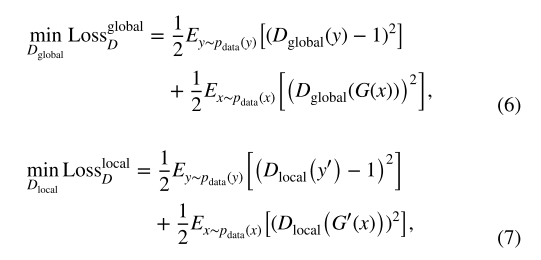
?????????其中 y' 是从未配对的 ground truth 中随机裁剪的补丁,![]() 是 G(x) 的补丁。
是 G(x) 的补丁。
损失函数
?????????仅生成对抗性损失不足以恢复所有纹理信息,因为去雾任务是像素级转换。 各种研究表明,无论是通过监督方法还是无监督方法,都可以在感知损失的帮助下提高去雾图像的质量。 外部数据和预训练模型显着提高了性能。 感知损失可以通过比较 VGG16 不同级别的特征来保留图像结构,VGG16 是一个预训练的分类网络。 感知损失函数可以表示为:
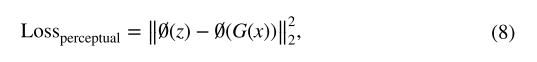
????????其中?是来自第 3 和第 5 池化层的 VGG16 特征提取器。 ?x 是模糊图像样本,z 是对应的清晰图像样本。 考虑到分类网络的光照不变性,模糊图像和去雾图像具有相似的结构。 我们可以看到,重建的图像保留了更高层重建的内容和空间结构,但失去了确切的颜色和纹理。 在我们的无监督模型中,不存在与模糊图像对应的清晰图像样本。 因此,我们使用雾度图像及其相应的去雾图像来制定这种修改后的感知损失。 通过实验对比,我们发现它在这种情况下也是有效的。 我们对整个图像和图像块的感知损失如下:?
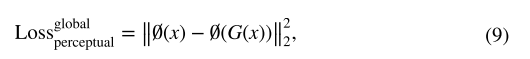
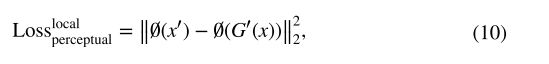
????????其中 x' 是来自 x 的补丁。 总体损失目标是:?
![]()
实验结果
? ? ? ? ?在SOTS上结果

? ? ? ? 在RTTS上结果


