一、概述
这篇文章做的任务是视觉问答。论文的创新点主要在于在使用问题的语义表示作为查询来搜索图像中与答案相关的区域的基础之上,开发了一个多层 SAN(Stacked Attention Networks),在其中多次查询图像以逐步推断答案。
模型的结构图如下:

SAN首先使用问题向量查询第一个视觉注意层中的图像向量,然后将问题向量和检索到的图像向量组合成一个细化的查询向量,在第二个注意层再次查询图像向量。 更高级别的注意力层给出了更清晰的注意力分布,专注于与答案更相关的区域。 最后,我们将来自最高注意力层的图像特征与最后一个查询向量相结合来预测答案。
二、Image Model
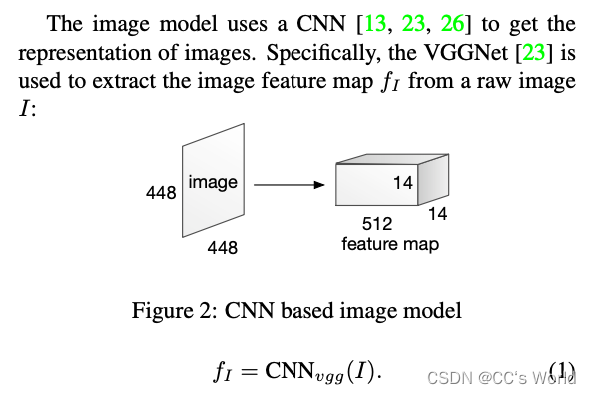
与之前的研究使用最后一个内积层的特征不同,我们从最后一个池化层中选择特征 f I f_I fI?,它保留了原始图像的空间信息。 我们首先将图像重新缩放为 448 × 448 像素,然后从最后一个池化层中获取特征,因此其维度为 512×14×14,如图 2 所示。14 × 14 是区域数 在图像中,512 是每个区域的特征向量的维度。 因此,fI 中的每个特征向量对应于输入图像的 32×32 像素区域。 我们用 fi,i ∈ [0, 195] 表示每个图像区域的特征向量。
然后为了建模方便,我们使用单层感知器将每个特征向量转换为与问题向量具有相同维度的新向量:

三、Question Model
给定问题 q = [q1 , …qT ],其中 qt 是位置 t 处单词的one-hot向量表示,我们首先通过嵌入矩阵
x
t
=
W
e
q
t
x_t = W_eq_t
xt?=We?qt? 将单词嵌入向量空间。 然后对于每个时间步,我们将问题中单词的嵌入向量提供给 LSTM:
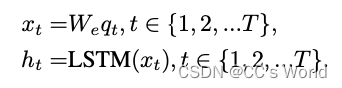
然后将最终的隐藏层作为问题的表示向量,即
v
Q
=
h
T
v_Q = h_T
vQ?=hT? 。
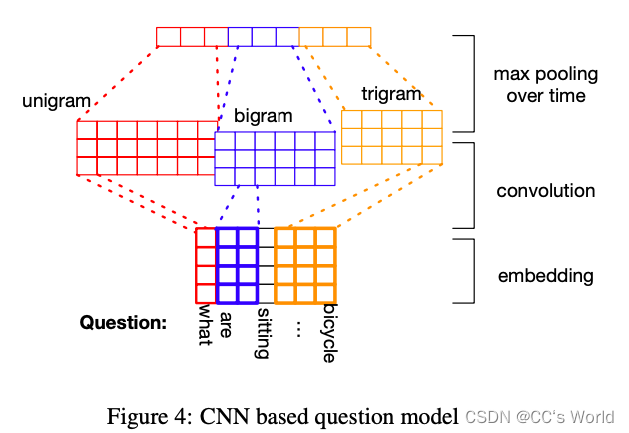
或者可以用CNN来实现:
四、Stacked Attention Networks
给定图像特征矩阵
v
I
v_I
vI? 和问题向量
v
Q
v_Q
vQ?,我们首先通过单层神经网络将它们输入,然后通过 softmax 函数生成图像区域上的注意力分布:
矩阵和向量相加是用了广播机制。
基于注意力分布,我们计算图像向量的加权和?i,每个向量来自一个区域,如等式17所示,然后我们将 ?i 与问题向量 vQ 结合起来,形成一个细化的查询向量 u,如等式18所示。 u 被视为精炼查询,因为它同时编码了问题信息和与潜在答案相关的视觉信息:
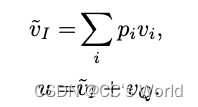
我们使用多个注意力层迭代上述查询注意力过程,每个层都提取更细粒度的视觉注意力信息用于答案预测。 形式上,SAN 采用以下公式:对于第 k 个注意力层,我们计算:

相当于每次迭代的时候更新查询,然后使用新的查询在图像区域上进行注意力。

