文章目录
Character-Level Language Modeling with Deeper Self-Attention deep transformer的修正优化
deep transformer的修正优化
摘要
- transformer结构能更好地适应长段语言文字序列。效果优于RNN循环神经网络,transformer能够在任意距离上传播信息,而RNN需要逐步进行传播信息
- transformer新增三个辅助损失:
1)intermediate sequence positions 中间序列位置
2)from intermediate hidden representations 中间序列的隐藏状态 hidden state
3)target positions multiple steps in the future 目标loss
论文
base transformer model

character transformer network 基础构造如上图所示,上图中,用历史已知数据t0、t1、t2、t3,从而预测t4,特殊的构造能够保证整个数据信息保持left-to-right的方向,只采用历史数据
Auxiliary Losses 辅助loss
由于本文的整体模型在10层以后会收敛速度慢且精度较差,所以加入三个辅助loss,且在训练中,辅助loss以衰减权重加入到总loss
-
Multiple Positions 多位置
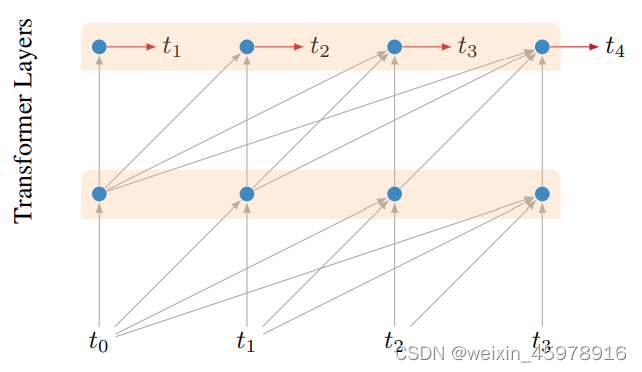
不仅仅将最终预测t4进行loss计算,也将中间预测,t0预测的t1、t0+t1预测的t2、t0+t1+t2预测的t3,t0+t1+t2+t3预测的t4,四个预测都会计算与真实值的loss。 -
Intermediate Layer Losses 中间隐藏层loss
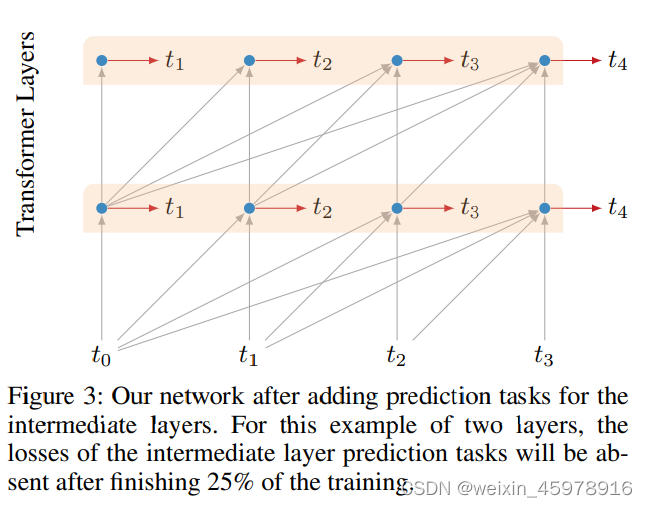
层次越低,加到总loss的权重学校,从而训练的要求也越少,且与训练的epoch有关,随着训练的不断进行,当训练达到一半的过程后,隐藏层的loss不再加入迭代 -
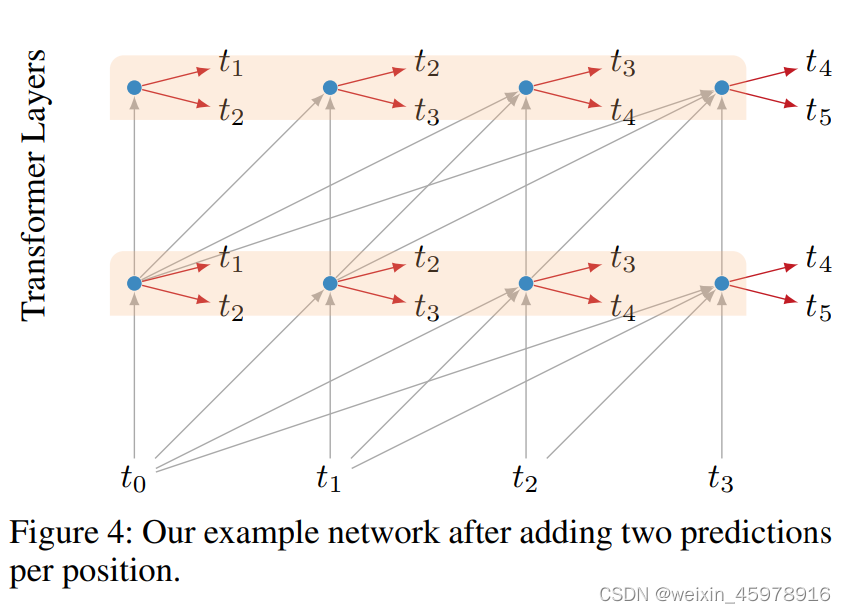
Multiple Targets
将预测值增加为两个数值,并乘以0.5进行预测值计算
Positional Embeddings 时间位置embedding的方法
主要对时间序列进行embedding,将时间序列变为512长度的embedding vector

