Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows
- 发表:2021 ICCV
- idea:主要是想改进transformer在视觉方向的速度。transformer从nlp到cv的挑战:这两个领域之间的差异,比如视觉实体的规模差异很大,图像中的像素与文本中的单词相比分辨率较高。之前的方法在分块中有重叠,导致性能不高,所以作者提出了一种层次变换器,其表示是用移位窗口计算的。移位窗口方案将自我注意计算限制在非重叠的局部窗口上,同时允许跨窗口连接,计算复杂度是线性的,提高了效率,并且能够在很多视觉任务上表现很好。
即之前的VIT是滑动窗口,计算self-attention有重叠,复杂度是二次的;而本篇文章使用的是shift window,每个窗口无重叠,计算是线性的,效率更高。
详细设计
(1)总体框架
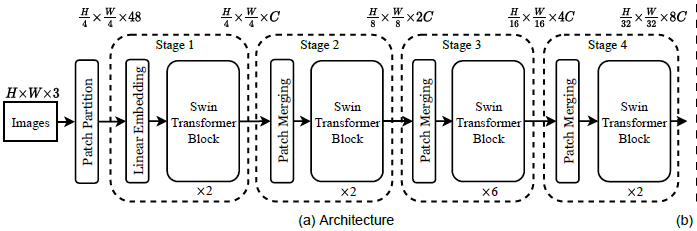
Patch Partition:首先将raw image输入patch splitting module进行分割,每个patch被视为一个token,token的特征是rgb像素值的concatenation。
Linear Embedding:输入到一个embedding layer,将token feature映射到C维
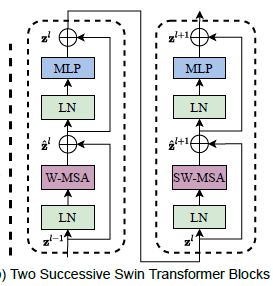
Swin Transformer Block:特征提取,不改变token的数量。Swin Transformer是通过将Transformer块中的标准多头自关注(MSA)模块替换为基于移动窗口的模块构建的,其他层保持不变。
Patch Merging:主要是为了生成层次的特征。concate每组22个相邻patch的特征,并在4C维连接特征上应用线性层。这将token的数量减少了22=4的倍数(分辨率为2下采样),并且输出维度设置为2C
ps:这些Stage共同产生了一种hierarchical representation(层次的表征)。这些stages具有与典型卷积网络相同的特征图分辨率,例如VGG和ResNet。因此,所提出的体系结构可以方便地取代现有方法中用于各种视觉任务的主干网络
(2)Shifted Window based Self-Attention
-
与前VIT比较
之前的将transformer应用到视觉任务中的架构通常都是考虑全局attention,这导致了二次的计算复杂度以及在高分辨率图像上的不合适。复杂度比较如下:
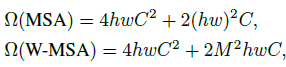
image size: h ? w ? C h*w*C h?w?C -
单层限制
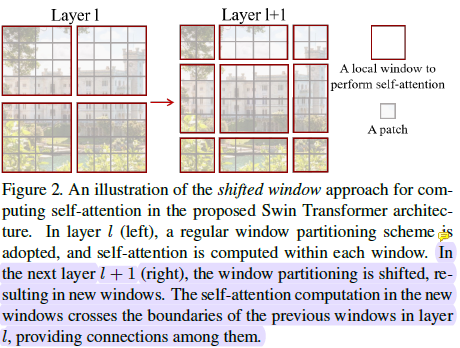
而单层的基于窗口的自我注意模块缺乏跨窗口的连接,这限制了其建模能力。为了在保持非重叠窗口高效计算的同时引入跨窗口连接,我们提出了一种移位窗口划分方法,该方法在连续的swn变换块中交替使用两种划分配置。
- shifted window partition
为了在保持非重叠窗口高效计算的同时引入跨窗口连接,作者提出了一种移位窗口划分方法,该方法在连续的swn变换块中交替使用两种划分配置。第一个module:window size为M*M,从左上开始划分;第二个module:windows沿着h和w移动(M/2,M/2)
计算方式如下:
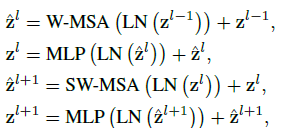
- shifted window的高效批计算
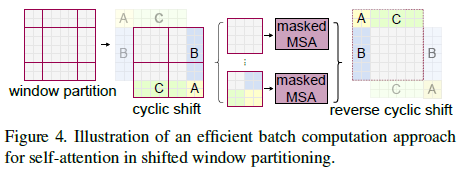
shift window带来一个问题:windows数量会增多(图像边缘一些不完整的windows)。如果仅仅对边缘的windows进行padding会增加计算量。我们提出了一种更有效的批量计算方法,循环向左上方向移动,并在sub-window中使用掩码机制并进行循环shift,这样就保证了windows数量在shitf之后不变。
(3)Relative position bias
在计算self-attention时,对每一个head计算相似度时引入相对位置偏差
B
∈
R
M
2
×
M
2
B∈R^{M^2×M^2}
B∈RM2×M2
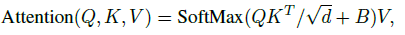
一些纬度的解释
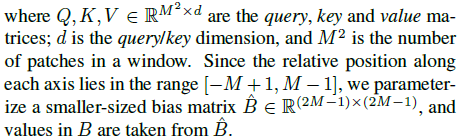
相对位置在[-M+1,M-1]的详细解释Swin Transformer网络结构详解
(4)Swin Transformer Variants

C表示first stage中hidden layers的channel number

