正则化知识其实是深度学习领域较为基础的知识点,初入此门的时候受限于正则化三个字的逼格,一直不求甚解;后期虽然了解但也仅限于L1和L2范数而已。恰巧上周在谢毅博士的课上旁听,讲到过拟合相关知识,后续和捷文讨论transformer内部的dropout为何还广泛使用,由此总结下正则化相关内容。
1、何为正则化
首先看百度百科的一部分解释:正则化就是对最小化经验误差函数上加约束,这样的约束可以解释为先验知识(正则化参数等价于对参数引入先验分布)。约束有引导作用,在优化误差函数的时候倾向于选择满足约束的梯度减少的方向,使最终的解倾向于符合先验知识(如一般的l-norm先验,表示原问题更可能是比较简单的,这样的优化倾向于产生参数值量级小的解,一般对应于稀疏参数的平滑解)。
直观的理解就是在原来的解方程上添加新的约束,使得方程解向我们希望的方向迭代。对应在深度学习领域,就是在函数模型较为复杂,对训练样本过拟合时,通过正则化手段添加新的约束,使得权重向我们希望的稀疏化方向演进,进而缓解模型的过拟合问题。
2、过拟合和欠拟合
机器学习中,我们都希望训练的模型拥有较强的模型泛化性,泛化性是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的训练集以外的数据也能给出合适的输出,该能力称为泛化能力。(泛化能力代表了训练好的模型对于未知样本输出的解释能力)
泛化能力差的原因可能是欠拟合和过拟合。
欠拟合:模型对训练和预测样本表现都很差,对训练样本的一般特征都还没学好。这个问题很容易暴露,通过loss曲线或者在训练集上的测试很容易看出来。
过拟合:当模型过度地学习训练样本中的细节与噪音,把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,这样就会导致泛化性能的下降,以至于模型在新的数据上表现很差。可能的原因是:特征维度过多、模型假设过于复杂、参数过多、训练数据过少、噪声过多。针对过拟合问题其实是比较难以察觉的,因为在已有的训练数据上有非常好的表现,而且loss等侦测手段的表现也难以观察出异常。
一副很经典的用来说明拟合状况的图:
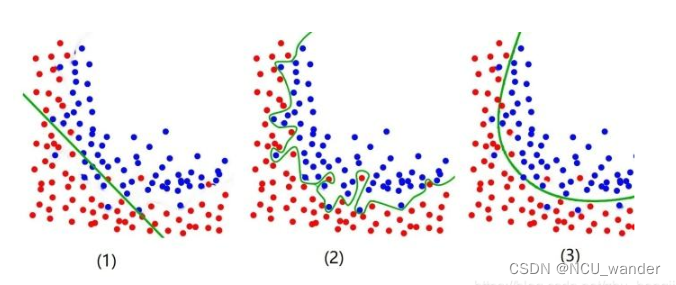
一般而言,针对过拟合问题,有如下解决手段:
- dropout:深度学习中最常用的正则化技术是dropout,随机的丢掉一些神经元。
- 数据增强,比如将原始图像翻转、平移、拉伸,从而是模型的训练数据集增大。数据增强已经是深度学习的必需步骤了,其对于模型的泛化能力增加普遍有效,但是不必做的太过,将原始数据量通过数据增加增加到2倍可以,但增加十倍百倍就只是增加了训练所需的时间,不会继续增加模型的泛化能力了。
- 提前停止(early stopping):就是让模型在训练的差不多的时候就停下来,比如继续训练带来提升不大或者连续几轮训练都不带来提升的时候,这样可以避免只是改进了训练集的指标但降低了测试集的指标。
- 批量正则化(BN):就是将卷积神经网络的每层之间加上将神经元的权重调成标准正态分布的正则化层,这样可以让每一层的训练都从相似的起点出发,而对权重进行拉伸,等价于对特征进行拉伸,在输入层等价于数据增强。注意正则化层是不需要训练。
- L1、L2正则化
3、Dropout
在正则化内容之前,可以说一点关于dropout的内容;目前CNN领域对dropout使用趋势是逐渐下降的,但是翻看transformer模型会发现有很多关于dropout的运用。
dropout在卷积CNN领域使用越来越少可以说是多方面因素共同造成:
- dropout对卷积层的正则化的作用很小
由于卷积层只有很少的参数,他们本身就不需要多少正则化(例如3*3 kernel本来权重就很少)。另外卷积核编码的是空间的关系,也就是相邻像素之间包含的信息是高度相关的,这也导致了dropout的失效。 - dropout所擅长的正则化慢慢的过时
由1,dropout可以发挥较大作用的领域是全连接层这样的参数量巨大的layer,对于全连接层部分确实需要考虑过拟合。但是目前深度学习领域中,全连接层被替代废弃的现象较为严重。 - 广泛使用的BN部分解决了CNN网络的过拟合问题
相对的,目前transformer领域有较多的linear层的存在,所以可以看到源代码中有比较多的dropout存在。
4、正则化
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。

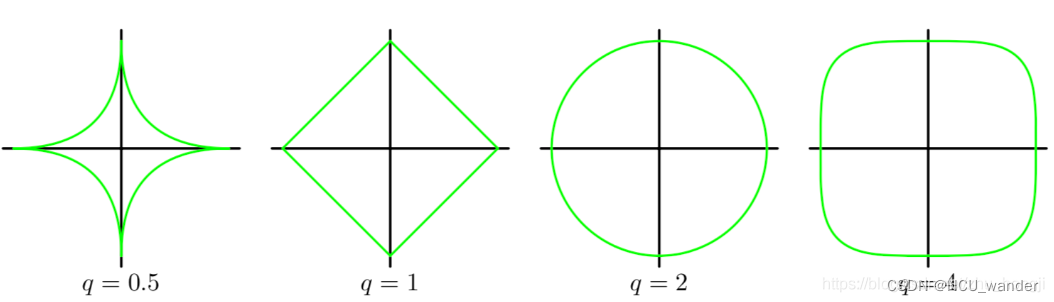
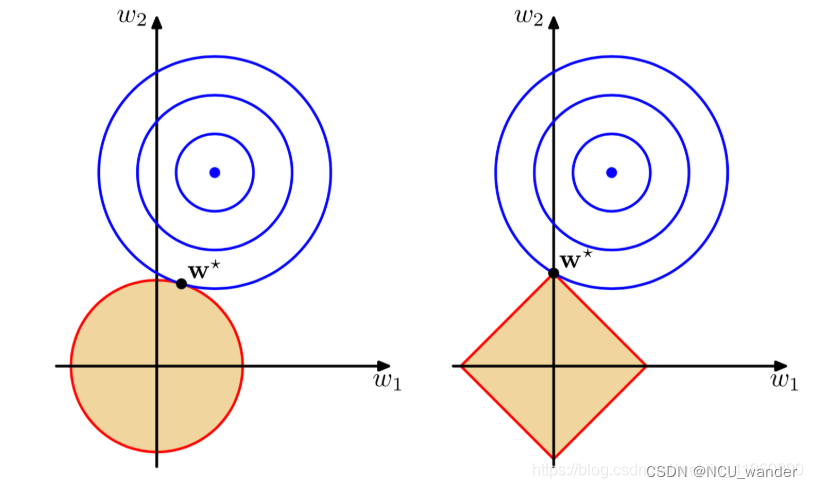
为什么要放这三张图呢?第一张图是范数的定义,大学高等数学有;第二张图是函数范数的图像,可以从图像方面加深理解;第三张图比较好,是一张假定的原有损失函数等高线(蓝色)和添加的正则化项(红图),此时loss函数的问题演变为求解两个颜色图最小值的问题,而这个值通在很多情况下是两个曲面相交的地方。顺便还可以看到二次正则项的优势,处处可导,方便计算;损失函数的梯度下降本身就是自等高线上逐渐向下的过程。

红字部分很好的解释了为什么L1可以起到稀疏化作用,而L2只是接近于0;因为0.01的平方项时0.0001,平方项缓和了数值下降的幅度,因此我们一般说L1带来了显著的权重稀疏化的作用。
正则化的影响
正则化后会导致参数稀疏,一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能常可能产生过拟合了。
另一个好处是参数变少可以使整个模型获得更好的可解释性。且参数越小,模型就会越简单,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。

