ЁАЙіЙіГЄНЖЋЪХЫЎ,РЫЛЈЬдОЁгЂалЁБЁЃНќРДЖСЁЖШ§ЙњбнвхЁЗ,КіШЛЯыПДПДЕНЕзФФЮЛгЂалдкЪщжаЬсЕНЕФзюЖр,гкЪЧОЭЯыгУЗжДЪЫуЗЈЪЕЯжвЛЯТЁЃ
ЭјЩЯвВШЗЪЕгаЯрЙиЕФАИР§,зїЮЊВЮПМ,здМКгжжиаДВЂгХЛЏСЫвЛБщЁЃ
ЫМТЗ
- ЯТдиЁЖШ§ЙњбнвхЁЗtxtЮФЕЕ
- ЪЙгУjiebaЗжДЪЫуЗЈЖдЮФЕЕНјааЗжДЪДІРэ
- НЋЗжДЪНсЙћЬпГ§ЭЃгУДЪЁЂБъЕуЗћКЯЁЂЗЧШЫУћЕШ
- ДЪЦЕЭГМЦЁЂВЂХХађ
- ПЩЪгЛЏеЙЪО
ЮЪЬт
АДееЩЯУцЕФЫМТЗНјааМђЕЅЪЕЪЉЪБ,ВщПДНсЙћЛсЗЂЯжМИИіЮЪЬт
- Ућзж
- Ш§ЙњШЫЮягаУћЁЂзжЁЂКХЕШ,ЛЙгаЦфЫћЕФвЛаЉБ№ГЦ,ШчЁАЯрИИЁБЁЂЁАВмАЂТїЁАЁЂСѕЛЪЪхЁБ,вЊЯыАьЗЈЭГвЛГЩвЛИіШЫ
- ДЪад
- БШШчЁАдЛЁБЁЂЁАДѓЪЄЁБЕШЗЧШЫУћЕФДЪВЛЪЧЮвУЧашвЊЭГМЦЕФ
- ЗжДЪ
- вЛаЉШчЁАПзУїдЛЁБЁЂЁАаўЕТЮЪЁБЁЂЁАВйДѓХЁБжЎРрЕФДЪУЛгаБЛЗжИюПЊ
- ИЩШХДЪ
- ЗжДЪКѓЛсГіЯжЯёЁАжюЙЋЁБЁЂЁАЦыЩљЁБЁЂЁААрЪІЛиЁБЕШУїЯд,ЕЋЪЧЫуЗЈЮоЗЈХаЖЯЕФЗЧШЫУћДЪгя,ИЩШХХХађНсЙћ
ЫљвдЖдетаЉЧщПівЊНјааЬиЪтДІРэЁЃ
гХЛЏ
- еыЖдУћЁЂзжЁЂКХЕФЮЪЬтНјааУЖОйХаЖЯЁЃЭјЩЯЕФАИР§жаДѓЖрВЩгУШч
w.word == 'аўЕТ'етжжЕШКХХаЖЯ,ЕЋЖдгк ЁАаўЕТЫьЁБЁЂЁАВйФЫЁБЕШЗжДЪВЛзМШЗЧщПіУЖОйВЛзуЁЃБШШчЮвУЧдкЮФБОРяЭГМЦЁАВйЁБзжга2800ЖрИі,ЛљБОЖМЪЧжИДњВмВй,ЖјгУАЂТїЁЂУЯЕТЁЂВмиЉЯрЕШУЖОйЕШКХХаЖЯЪБ,зюжеЭГМЦЕФЁАВмВйЁБДЪЦЕжЛга1000ЖрИі,ЫљвдЮвВЩгУЕФЪЧАќКЌХаЖЯ,МД'Вй' in w.wordЁЂ'УЯЕТ' in w.wordЁЃ - ДЪадЬпГ§ЁЃЭЈЙ§w.flagНЋnr(ШЫУћ)ЭтЕФЦфЫћДЪадЬпГ§Еє,етвЛВНКмЖрАИР§жаЪЧЗХдкШЫЮяУћзжКХЕФХаЖЯЧА,ЕЋЪЧЁАаўЕТЁБЛсБЛЕБГЩx(ЮДжЊДЪад),етбљОЭЛсЩйЫуКмЖраеУћ,ЫљвдЮвЗХдкСЫШЫЮяУћзжХаЖЯКѓ,дйЬпГ§ЮоЙиДЪадЁЃ
- ЖдгкДЪадЮЊnrЕЋЪЧЗЧШЫУћЕФДЪ,дђашвЊдкЭЃгУДЪЕФЛљДЁЩЯ,діМгвЛеХЬпГ§ИЩШХДЪЕФздЖЈвхЮФМў
НсЙћ
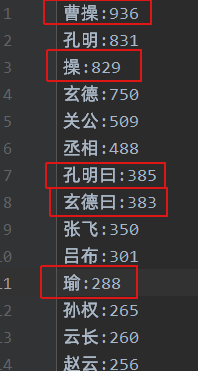
ОЙ§вдЩЯДІРэКѓ,ЛљБОХХГ§СЫИЩШХ,зюКѓОЭЪЧМЄЖЏШЫаФЕФЪБПЬ,ФЧУДЫВХЪЧТоЙсжааФжаЕФФЯВЈЭђФи?
ЕБЕБЕБЕБ,ФЧОЭЪЧетЮЛЁАПЩАЎЕФМщалЁБЁЊЁЊВмВйЁЃ
ВмВй:3014
СѕБИ:2689
жюИ№СС:2103
Йиг№:1047
ТРВМ:868
жмшЄ:660
ЫОТэмВ:643
дЌЩм:544
еХЗЩ:505
ТГЫр:465
едзгСњ:433
ТэГЌ:358
ЫяШЈ:351
ЖзП:342
ЮКбг:322
НЊЮЌ:302
ЛЦжв:190
СѕБэ:156
ХгЕТ:122
еХСЩ:117
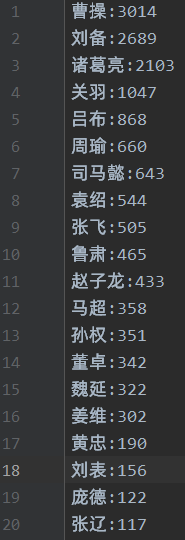
дйРДвЛеХРЗчЕФШ§ЙњДЪдЦ

ЫЕУї:ИУДІРэНсЙћжЛЖдХХУћППЧАЕФСѕБИЁЂжюИ№ССЁЂВмВйЁЂЙиг№ЁЂеХЗЩЁЂТРВМЁЂЫОТэмВЕШШЫЮяЕФЗжДЪНсЙћНјааСЫгХЛЏ(МћДњТы),ЦфЫћжюШчЮКбгЁЂХгЭГЁЂХгЕТЕШВЛгАЯьЕквЛХХУћЕФШЫЮя,УћЁЂзжЁЂКХЮЪЬтЮДНјааЯъЯИДІРэЁЃ
ИНДњТы
import jieba.posseg as pseg
import jieba
import re
import matplotlib.pyplot as plt
import codecs
# ДЪдЦ
import wordcloud
import imageio
# ЖЈвхжївЊШЫЮяЕФИіЪ§
keshihuaTop=10 # ПЩЪгЛЏШЫЮяЭМШЫЪ§
mainTop = 100 # ШЫЮяДЪдЦЭМШЫЮяЪ§
peopleTop=10 # ШЫЮяЙиЯЕЭМ
# ЛёШЁЭМЪщЪ§Он
def get_book(file_path):
fn = open(file_path,encoding='utf-8')
stringdata = fn.read()
fn.close()
return stringdata
# ЮФБОДІРэ
def bookdata_process(bookdata):
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"')
book_str = re.sub(pattern,'',bookdata)
print('ЮФБОдЄДІРэЭъГЩ')
return book_str
# ЛёШЁЭЃгУДЪ
def stop_word_list(file_path):
stopwords = [line.strip() for line in open(file_path,'r',encoding='utf-8').readlines()]
return stopwords
# ЛёШЁДЪЦЕ
count = {}
# ЛёШЁДЪЦЕ
def getWordTime(txt,stopWordList,wordFlagList):
jieba.load_userdict("prepare/userword.txt")
cutfinal = pseg.cut(txt)
for w in cutfinal:
if w.word == None or w.word in stopWordList:
continue
elif 'СѕаўЕТ' in w.word or 'аўЕТ' in w.word or 'СѕдЅжн' in w.word or'БИ' in w.word or 'ДѓЖњдє' in w.word \
or 'ЯШжї' in w.word or 'СѕЛЪЪх' in w.word or 'ЛЪЪх' in w.word or 'ДѓЖњ' in w.word or 'аўЕТЙЋ' in w.word \
or 'ККжаЭѕ'in w.word or 'СѕБИ' in w.word:
real_word = 'СѕБИ'
elif 'ПзУї' in w.word or 'ЮдСњ' in w.word or 'ЮдСњЯШЩњ' in w.word or'СС' in w.word or 'ЮфКю' in w.word \
or 'ЮфЯчКю' in w.word or 'жюИ№иЉЯр'in w.word or 'ЯрИИ' in w.word or 'жюИ№ПзУї' in w.word or 'жюИ№СС' in w.word:
real_word = 'жюИ№СС'
elif 'ВмУЯЕТ' in w.word or 'ВмЙЋ' in w.word or 'Вмдє' in w.word or'Вй' in w.word or 'ВмиЉЯр' in w.word \
or 'ВмВй'in w.word or 'ЮКЙЋ'in w.word or 'ЮКЭѕ' in w.word or 'АЂТї'in w.word or 'ВмАЂТї' in w.word \
or 'УЯЕТ' in w.word or 'ВйОќ' in w.word:
real_word = 'ВмВй'
elif 'ЙидЦГЄ' in w.word or 'дЦГЄ' in w.word or 'ЙиЖўвЏ' in w.word or'ЙиЙЋ' in w.word or 'ЙиНЋОќ' in w.word \
or 'УРїзЙЋ'in w.word or 'ККЪйЭЄКю' in w.word or 'ЙидЦ' in w.word or 'ЙиФГ' in w.word:
real_word = 'Йиг№'
elif 'еддЦ' in w.word or 'згСњ' in w.word or 'ГЃЩН' in w.word or 'едНЋОќ' in w.word:
real_word = 'едзгСњ'
elif 'еХвэЕТ' in w.word or 'Ш§Ем' in w.word or 'вэЕТ' in w.word or 'еХвэ' in w.word:
real_word = 'еХЗЩ'
elif 'ТРЗюЯШ' in w.word or 'ЗюЯШ' in w.word or 'ВМ' in w.word or 'ТРНЋОќ' in w.word or 'Ш§аеМвХЋ' in w.word:
real_word = 'ТРВМ'
elif 'зП' in w.word or 'жйгБ' in w.word or 'ЖРЯдє' in w.word:
real_word = 'ЖзП'
elif 'шЄ' in w.word or 'ЙЋшЊ' in w.word or 'жмРЩ' in w.word:
real_word = 'жмшЄ'
elif 'жйДя' in w.word or 'ЫОТэжйДя' in w.word or 'мВ' in w.word:
real_word = 'ЫОТэмВ'
elif 'СѕОАЩ§' in w.word or 'ОАЩ§' in w.word:
real_word = 'СѕБэ'
elif 'ГЌ' in w.word or 'УЯЦ№' in w.word or 'ТэУЯЦ№' in w.word:
real_word = 'ТэГЌ'
elif 'АЂЖЗ' in w.word:
real_word = 'Сѕьј'
elif 'жйФБ' in w.word or 'ЮтЭѕ' in w.word or 'ЮтжїЫяШЈ' in w.word:
real_word = 'ЫяШЈ'
elif 'дЌБОГѕ' in w.word or 'БОГѕ' in w.word or 'Щм' in w.word:
real_word = 'дЌЩм'
elif 'Ыр' in w.word or 'згОД' in w.word or 'згОД' in w.word:
real_word = 'ТГЫр'
elif 'ВЎдМ' in w.word:
real_word = 'НЊЮЌ'
elif 'шЖ' in w.word:
real_word = 'ЙЋЫяшЖ'
elif (len(wordFlagList)>0 and w.flag not in wordFlagList):
# print(w.word + w.flag)
continue
else:
real_word = w.word
count[real_word] = count.get(real_word,0) + 1
# ЗжДЪЩњГЩШЫЮяДЪЦЕ(аДШыЮФЕЕ)
def writeWordResult(items,sinkPath,topN):
with codecs.open(sinkPath, "w", "utf-8") as f:
if len(items) < topN:
topN = len(items)
for i in range(topN):
word, count = items[i]
f.write("{}:{}\n".format(word, count))
# ЩњГЩДЪдЦ
def creat_wordcloud(excludes):
bg_pic = imageio.imread('prepare/sanguo.jpg')
wc = wordcloud.WordCloud(font_path='prepare/simhei.ttf',
background_color='white',
width=1000, height=800,
stopwords=excludes,# ЩшжУЭЃгУДЪ
max_words=500,
mask=bg_pic # maskВЮЪ§ЩшжУДЪдЦаЮзД
)
# ДгЕЅДЪКЭЦЕТЪДДНЈДЪдЦ
wc.generate_from_frequencies(count)
# БЃДцЭМЦЌ
wc.to_file('output/Ш§ЙњбнвхДЪдЦ_ШЫУћ.png')
# ЯдЪОДЪдЦЭМЦЌ
plt.imshow(wc)
plt.axis('off')
plt.show()
if __name__ == '__main__':
excludes = stop_word_list("prepare/exclude.txt")
stopwordlist = stop_word_list("prepare/tingyong.txt") + excludes
bookdata = get_book("prepare/sgyy.txt")
txt = bookdata_process(bookdata)
# ЩшжУДЪад--nr:ШЫУћ
# аўЕТЛсБЛЪЖБ№ЮЊЮДжЊДЪад(x)
# ССЁЂВйЛсБЛЪЖБ№ЮЊЖЏДЪ(v)
# дЦЛсБЛЪЖБ№ЮЊЕиУћ(ns)
wordFlagList = {'nr'}
getWordTime(txt,stopwordlist,wordFlagList)
items = list(count.items())
# НјааНЕађХХСа ИљОнДЪгяГіЯжЕФДЮЪ§НјааДгДѓЕНаЁХХађ
items.sort(key=lambda x: x[1], reverse=True)
sink_path = "output/sanguo_word_count.txt"
writeWordResult(items,sink_path,300)
creat_wordcloud(excludes)
ЯрЙиИНМўЯТди
sgyy.txt Ш§ЙњбнвхtxtЮФМў
excludes.txt ИЩШХДЪЮФМў
tingyong.txt ККгяЭЃгУДЪ
sanguo.jpg Ш§ЙњДЪдЦЕзЭМ
simhei.ttfзжЬхПЩЕНЕчФдC:\Windows\FontsзжЬхПтЯТздааИДжЦ

