阅读目标
- 寻找原型与偏差之间的关系
- 了解原型学习的方法然后pick one
阅后回答
摘要
动机:消除数据冗余、发现数据结构、提高数据质量
方法:通过寻找一个原型集来表示目标集,以从样本空间进行数据约简
分类:按照监督方式):分为无监督、半监督和全监督;按照模型设计,分为基于相似度、行列式点过程、数据重构和低秩逼近
概念和意义
概念:设有源集
X
X
X和目标集
Y
Y
Y,目标是从
X
X
X中找到一个原型集
Ω
\Omega
Ω,使得
Ω
\Omega
Ω能够最大程度地保持目标集
Y
Y
Y所蕴含的信息,如下图:
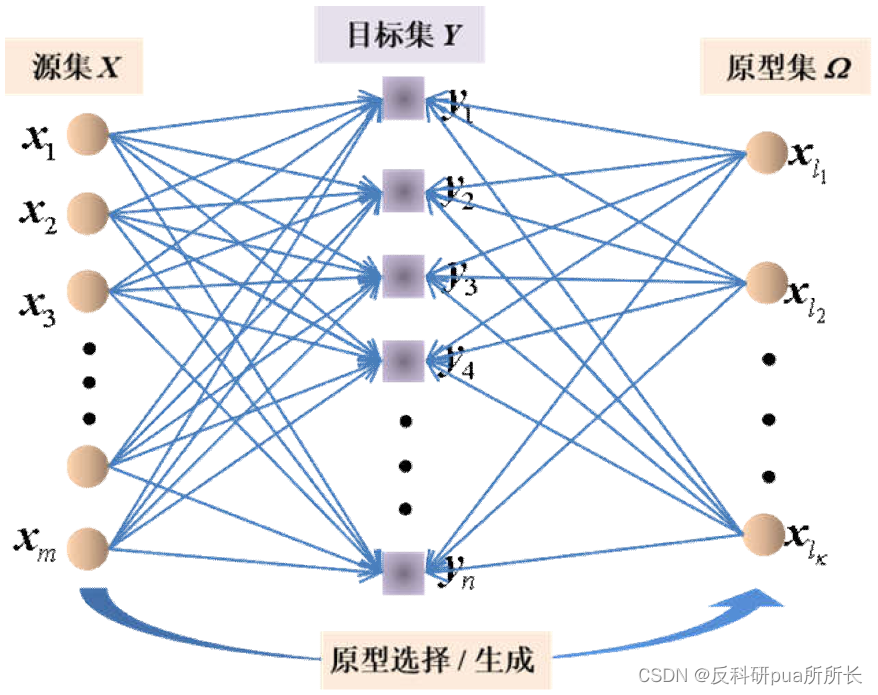
直接看概念和图示较难理解,可以结合这个例子:相簿更新系统,摄影集是源集 X X X,用户的初选照片担任目标集 Y Y Y,我们的目标是从源集中找到最符合用户原始收藏习惯的照片,即原型集 Ω \Omega Ω
那么目标集就可以看作是为我们寻找原型提供依据的身份,在实际应用中,目标集和原型集应该有着更相似的物理意义,但同时应该指出,很多任务中的目标集和源集是一样的,因为我们更多时候找不到原型的依据,这时原型学习就很像是无监督学习中的聚类学习,但聚类和原型学习是不一样的,区别是:
- 聚类学习中,我们更关注目标集的语义信息;但原型学习的概念更广,我们希望原型可以不仅表示目标集的语义信息,还能表示目标集的结构或容量等信息;从这种意义上讲,原型学习可以视为一种细粒度的聚类问题
- 原型学习获得的原型数量是灵活变化的,而聚类需要提前预设要聚几类
原型学习的方法
按照是否使用了语义信息约束原型的生成,可以分为无监督、半监督和全监督方法:
| 监督方式 | 介绍 | 方法 | 应用 | 参考文章 |
|---|---|---|---|---|
| 无监督 | 大部分工作使用的方法 | k-DPPs | 通常被用来选择视频序列的关键帧 | K-dpps: fixed-size determinantal point processes. |
| 最大割准则和最大边缘相关准则 | 原型集内元素间的关联性对于面向时序数据的视觉应用十分重要 | The use of MMR, diversity-based reranking for reordering documents and producing summaries. | ||
| 半监督 | 当用户不仅需要代表性的子集且希望了解它们是什么 | Joint representative selection and feature learning: a semi-supervised approach. | ||
| 全监督 | 当能够获得数据的语义信息时(如图像分类算法) | 基于浅层模型的原型学习 | 通常用来约简k-NN、SVM等推理算法的训练数据 | RSVM: Reduced support vector machines. |
| 深度学习的原型学习 | 学习表征、增强模型泛化能力 | Robust classification with convolutional prototype learning. |

