介绍
本文提出了一种融合摄像头和LiDAR传感器数据进行行人检测和跟踪的新方法。为了应对自动驾驶场景的挑战,提出了一个集成的跟踪和检测框架。
检测阶段通过将LiDAR流转换为计算上可处理的深度图像来执行,然后开发深度神经网络来识别RGB和深度图像中的行人候选者。为了提供准确的信息,通过使用卡尔曼滤波器融合多模态传感器信息,进一步增强了检测阶段。跟踪阶段是卡尔曼滤波预测和光流算法的组合,用于跟踪场景中的多个行人。
行人跟踪包括两个主要阶段:行人检测以及检测到的行人与当前和过去的估计值相关联。通常,行人跟踪有两个研究方向 - 要么以端到端的方式使用深度学习模型,要么开发混合了深度学习和经典方法的机器学习管道,以实现行人跟踪。
一些值得注意的基于端到端深度学习的行人跟踪方法包括TrackR-CNN ,Tracktor++和JDE ,这些方法是通过增强现有的行人/物体检测器来创建的。很少有端到端的多模态传感器融合机制使用3D LiDAR和摄像头数据进行行人跟踪。由于网络架构复杂,这些方法通常运行时效率低。相反,基于机器学习管道的方法将行人探测器与经典滤波技术相结合,以实现更好的运行时效率。这些方法主要依赖于特定的传感器模态,例如相机数据。尽管如此,这些方法要么具有丰富的特征描述符,要么对环境条件敏感(例如,使用相机时的照明变化)。因此,这些方法对于检测和跟踪行人来说不够强大。
多模态传感器数据的融合可以提高行人检测和跟踪精度:(a)两个预期行人的地面实况边界框,(b)探测器只能检测到相机图像上的一个行人,(c)和激光雷达扫描的相应深度图像上的另一个行人。因此,通过将(b)和(c)中的这些独立结果组合成联合预测,可以获得最佳结果。

为了实现计算上可处理的实时行人跟踪,首先,将LiDAR 3D流转换为2D深度图像,然后通过将这些帧与摄像头图像垂直连接来馈送到行人探测器。最后,卡尔曼滤波器用于融合对串联图像的预测以及当前帧中先前检测到的行人的位置。
重点是使用深度神经网络提高鲁棒性和准确性。虽然这些方法在光线充足的环境中表现出令人满意的性能,但它们很难在夜间,黎明,日出和日落等低光照条件下检测行人。LiDAR可以在这些场景下提供更好的形状特征。由于LiDAR可以提供行人的唯一几何特征,因此推断行人身体部位的上下文感知关系是在复杂场景中区分多个行人的一种方法。
使用LiDAR和相机传感器来补充单个传感器对检测和跟踪性能的限制,可以应用于各种复杂的场景。
简要说明YOLOv5作为行人探测器的工作原理。由于YOLOv5架构与YOLOv4?除了训练过程外,将描述YOLOv4的架构,然后重点介绍训练差异。

数据增强后,增强图像被馈送到网络的骨干中。在主干部分,使用了BottleNeckCSP,这是对DenseNet 的修改。使用BottleNeckCSP提取不同的浅层特征,如边缘,颜色等。在训练期间,主干模块学习这些功能。此外,还使用额外的空间金字塔池化(SPP)块来增加感受场,并从BottleNeckCSP的特征图中分离出最重要的特征。网络的下一部分是颈部部分,其中网络增强了对骨干部分所采用的浅层特征的理解和提取。为此,将使用路径聚合网络 (PANet),该网络包括自下而上的增强路径以及要素金字塔网络 (FPN) 中使用的自上而下的路径。PANet过程对提取的特征进行组合和分析,最后根据模型的目标进行优化。网络的最后一部分是输出,其中模型使用密集预测生成检测结果。密集预测通过组合已分类行人的预测边界框和置信度分数来提供向量。
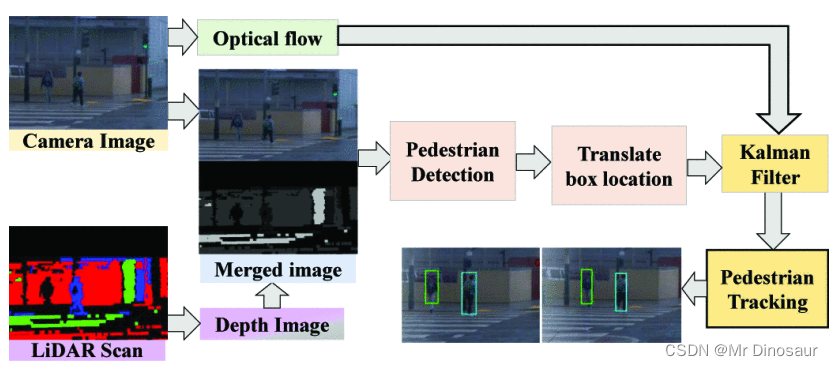
?相机图像及其同步激光雷达扫描是该框架的输入。首先,将LiDAR扫描转换为深度图像,然后与相机图像合并。接下来,合并馈送到行人检测模块中,并通过转换检测到的框位置将输出映射到单相机图像帧中。最后,对于行人跟踪,实现了卡尔曼滤波器,其中输入是这些转换的边界框和输入图像的光流。
从激光雷达扫描到深度图像的转换
将3D LiDAR扫描转换为2D图像空间中的深度图像,LiDAR由一系列注册的3D扫描组成{S1,?S2,?…, St}。每次扫描S,是一个点云,即一组3D点,?St?=?{p1,?p2, …,?pi}和pi?:=?{x, y, z}表示欧几里得坐标,再将3D扫描转换为2D深度图,深度图像的像素值位于灰色或 RGB 色彩空间中。对于灰度图像,我们将网格图中的每个像元值归一化为 0?→?255,以达到已知的最大深度值,因此灰度图像的强度表示深度信息。
先不写了,头大,歇会
520快乐

