����CNN��һЩ˼��-2022
ǰ��
����(2022)CVPR����ƪ����CNN����������ӡ�����,��Ϊ���Dz�Լ��ͬ��ʹ���˸���ľ�����:
֮ǰ�����Լ����о�������Ҳ�����˴������,ȷʵЧ���ܺ�,��Ȼ,�������Դ� �C �õ���
�ع˾���,��˵����һ�ֶ�˼�Ȩ������Ӧ�˲�(�Ǵ�ͳͼ���˲��㷨������),����IJ�����ͨ�������������������ġ�������CNN��չ̫����,��ż���˵ľ���(2 x 2������3 x 3)����ȿɷ��������shift��λ�������ز������ľ������ſؾ����ȵȡ�����Transformers������,����ʹ�þ�������λ�ñ���IJ����� ����Ͳ�һһ�о���,����Ȥ�İٶȼ��� - -
��֮ǰд��һƪ�����ز�������˼�� �����ز�������һЩ˼��-2022 ���������ԵĹ���
�������о��˼�ƪ����,������һ������ (������ʾ:���ĶԳ�ѧ�߲��Ǻ��Ѻ�)
����1:Ϊʲô֮ǰ�����������ô������?����2:�������Ϊʲô��ôwork?
CNN (Neural Computation 1989)
����1: Backpropagation applied to Handwritten zip code recognition
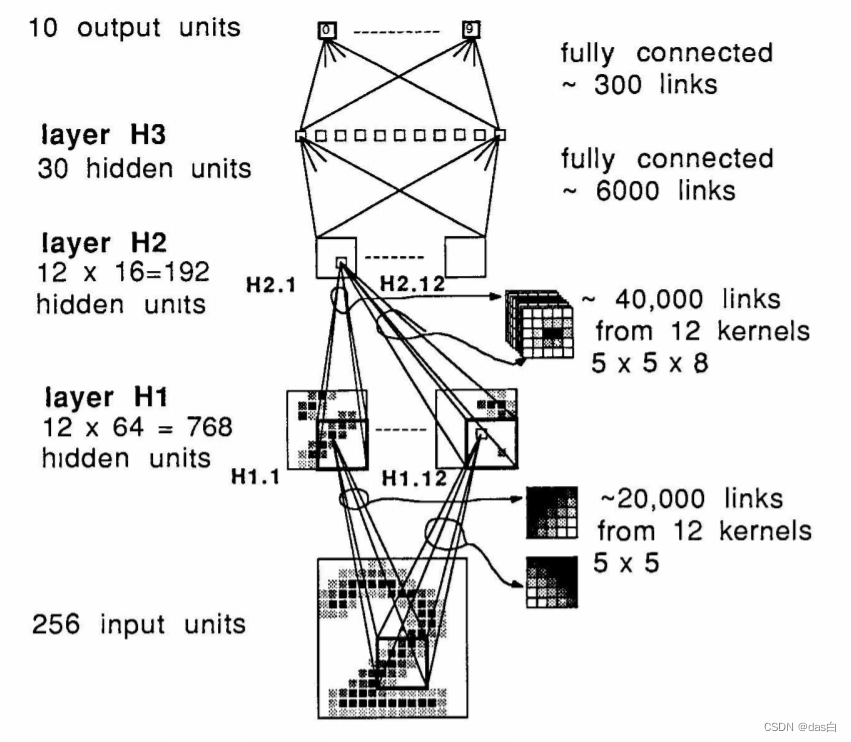
�����������������,��ԭʼ�ľ�����
�����ڵĽǶ�����(2022��)��ʵ���ǿռ����ͨ����ļ�Ȩ���
���� (ICLR 2022) 2:Deep Neural Nets: 33 years ago and 33 years from now
��˹��AI�ܼ���IJ���,������˼,������LeCun 33��ǰ�������硣
��ƪ���¸��ҵĸо�:�ִ����ѧϰ������work�Ļ���������ǿ(dropout)�������������
������˵��������û��,���Dz��߱������� ��Щֻ���ض����ݼ���Ч �C ���˹۵�,��ϲ����
��Ȼ,��Щ������������������ijһ�������
MobileNets (CVPR 2017) DConv
����3: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
��ԭʼ�ľ�����ͬ,��ȿɷ���ľ���ֻ��ͨ����ļ�Ȩ���,ʹ�õ�����Կռ����������н���
��ȿɷ���ľ���Ӧ�õĺܹ�,��Ϊ��Ŀ����ǵ�
�ܿ�ϧ�����ٶ����˵�(��GPU��),��Ϊԭʼ��һ���������滻����������������(DConv + ���)
Shift (CVPR 2018) SConv
����4: Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
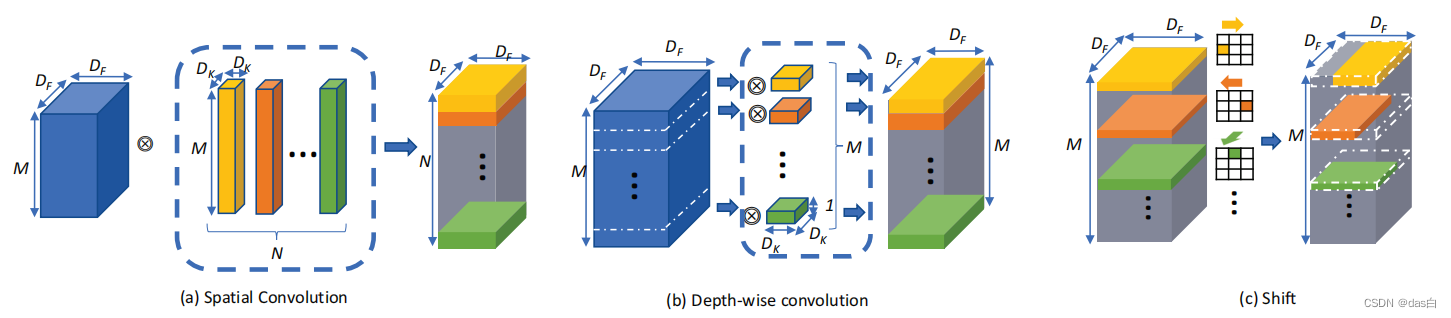
����ȿɷ���Ļ�����,ʹ�ü�ͼ����λ�����пռ��������Ľ���(����ʵ���漰���ײ���)
����˵����ȿɷ�������ļ�ǿ��,ȷʵ�Ѳ��������˺ܶ�,����ȷ��Ҳ���ɱ�����½���
ʵ�ʲ���Ļ�Ӧ�û������(������Խ����½���ȷ��) ����������ĺ�����Shift ,�����DConv
����ɲο�5:���¾���������ơ���Shift��������
ConvNet (CVPR 2022)
����4: A ConvNet for the 2020s
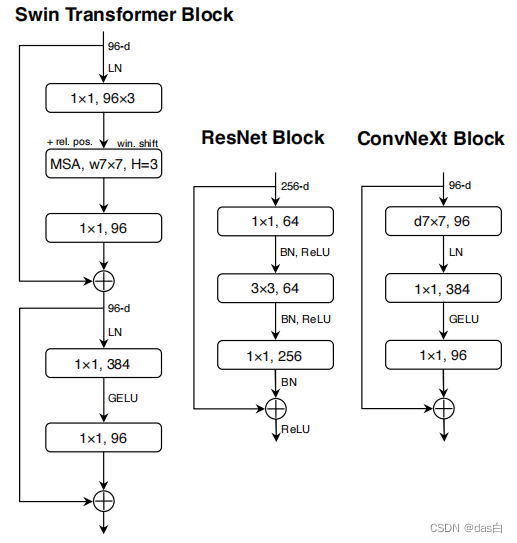
�����µļ���(������ǿ����һ����DConv�ȵ�)���ӵ���ResNet,Ҳ���Դﵽ�ܺõ�Ч��
����ĸĶ�ֻ��Block,�ײ��ǵ�����,��ƪ���¸������������˺ܴ�����
Large Kernel:31x31(CVPR 2022)
����6: Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
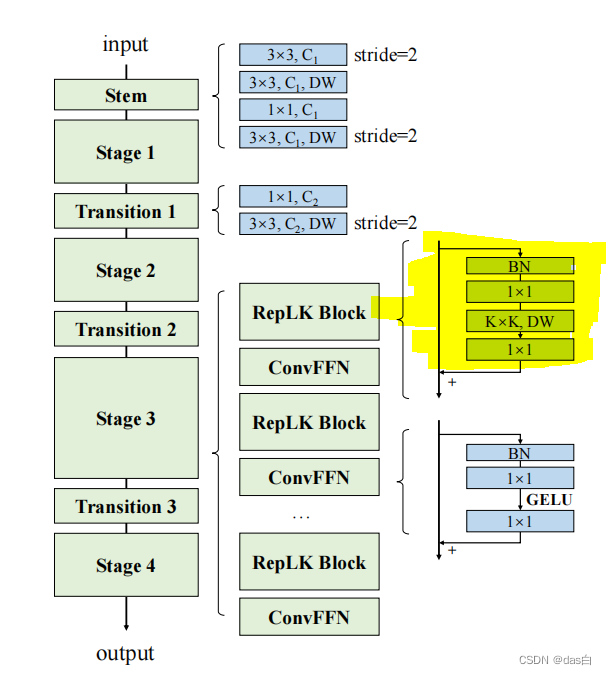
��Stage3��ʹ�õĴ������(Ҳ��DConv),ͬ������GELU�����
��ô��ľ�������δ�ײ�,Ӧ��Ч������̫��
�ܽ�
���ò�˵ 7:Money is all you need ������,Խ�����о�,Խ�о��õ��豸������ ���Կ�����֤�Լ����뷨
�������MLP������Ҳ�ܶ� �����ϻ��Ǽ�Ȩ���(��������) �о�ʹ�þ���Ҳ��ʵ�� �C ���˸о�
����һЩ��ע�����������ϵ�����
- ����10:ACmix:��ע�����;������ں� �ȵ�
��ǿ���ߵ��˽���
���ʲ���
����1:Ϊʲô֮ǰ�����������ô������?`
- �ܹ��Ķ�֪��,ʵ����ռGPU,�����ٶ���,Ч��Ҳ��һ����(���ܵ���û��λ)
- �Ƚ���Ӳ���豸�Ǵ�����˵�xxx����,Ŀǰʹ�ô������Ҳ���ڳػ�֮��� ��Ϊ����GPU�ڴ�ռ����
Ҳ����һ��ʼʹ�ô������Ч��Ҳ����?Ҳ�����ڴ�ͼ����(���ػ�)�ô�ľ����˽������һ���ȶ�����?
����2:�������Ϊʲô��ôwork?
- ˵ʵ��,����!!!!!!!!!!!
- �о�Transformers��������ע����ʹ�õ�ͼ���Ͼͺ����,ȷ��ÿһ��ͼ��ע����Ȩ�ش�ĵط��������������ĵĵط���?���� - ��ѧ ���ǵ���ʹ����ע�����ͺ�����,�Ͼ�ֻ��λ�ñ���
- ֻ���ǻ���ǰ�˵�ʵ�龭��,������������� �Ҽǵ�VIT��ʹ����Ԥѵ��Ч������ȥ��,����Ҳ�����ںܴ����������˵,����(С�ĺ�)��һ������ ʹ�ô�ľ����˿��Խ�һ������������ (
��ͳͼ���˲�����ʹ�ô�Ĵ���Ч����һ��) - ˽��Ϊ��Ȩ��ͻ���DZ������,��ô��������ɽ����Ե���ͷ�ʽ��δ����չ��һ������ �C
���˸о�
���⻰:���ɷ��ϳػ�������,�ײ�ȷʵ����Ч
�����Ժ����ž����ķ�չ���ѳػ���������,�ػ���ͼ���Ǻܷ���IJ���,���dzػ������������ݽṹ�����Ѻ� - -

