Python--ǿ��--Day01
🧸������б�,�ֵ�,�����и�������ɸѡ����?
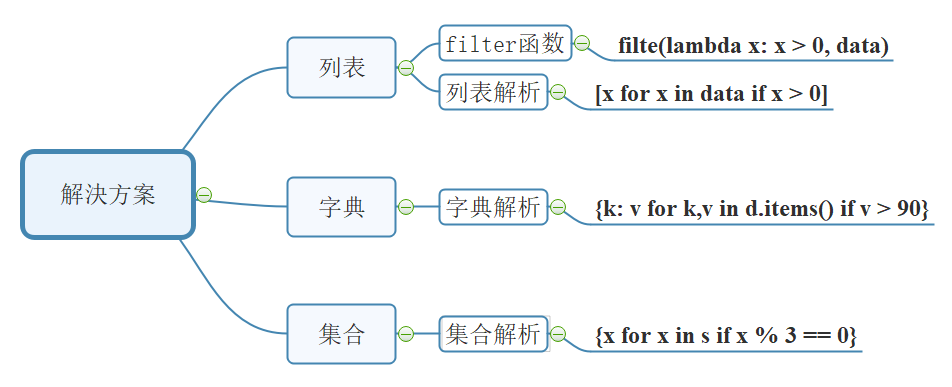
🎈��Ŀ1:�б������C�����б��в��ĸ���
import timeit
from random import randint
data = [randint(-10, 10) for _ in range(10)]
print(data)
# ��Ŀ1:�����б��в��ĸ���
# ����1 ʹ��filter + lambda
r = filter(lambda x: x >= 0, data)
print(list(r))
# ����2 �����
r2 = [x for x in data if x >= 0]
print(r2)
# ʹ�ü�ʱ�� ��������ʱ��
print(timeit.timeit("filter(lambda x: x >= 0, data)", 'from __main__ import data'))
print(timeit.timeit("[x for x in data if x >= 0]", 'from __main__ import data'))
🎈��Ŀ2:�ֵ�����C�����б�ѧ���ɼ�����90��
# �����б�ѧ���ɼ�����90��
from random import randint
student_id_and_score = {x: randint(60, 100) for x in range(20200001, 20200021)}
print(student_id_and_score)
# �ֵ����
r = {k: v for k, v in student_id_and_score.items() if v > 90}
print(r)
🎈���Ͻ���:
# ���Ͻ���
from random import randint
data = [randint(0, 20) for _ in range(10)]
s = set(data)
print(s)
r = {x for x in s if x % 3 == 0}
print(r)
🧸���ΪԪ���е�ÿ��Ԫ������,��߳���Ŀɶ���?

# ���� 1 ����һϵ����ֵ����
# ʹ�ò���ķ���
NAME, AGE, SEX, EMAIL = range(4)
student = ('Jim', 16, 'male', 'jim123@gmail.com')
print(student[0]) # Jim ���������±�ķ�ʽ�����˳���Ŀɶ���,0,1,2...����
print(student[NAME]) # Jim
# ���� 2
from collections import namedtuple
# ��һ��������������,�ڶ���������Ӧ������
Student = namedtuple('Student', ['name', 'age', 'sex', 'email'])
s = Student('Jim', 16, 'male', 'jim123@gmail.com')
print(s.name) # Jim
print(isinstance(s, tuple)) # True ˵��s���������͵�һ������
🧸���ͳ��������Ԫ�س��ֵ�Ƶ��?

from random import randint
from collections import Counter
import re
# ��1
data = [randint(0, 20) for _ in range(30)]
print(data)
# ���� 1
# �����ֵ�
c = dict.fromkeys(data, 0)
# print(c)
for i in data:
c[i] += 1
print(c)
# ���� 2
# ʹ��collections�µ�Counter����
c2 = Counter(data)
print(c2)
print(c2.most_common(3)) # [(6, 4), (4, 4), (16, 4)]
# ��2
# ���д�Ƶͳ��
f = open(r'D:\test.txt', encoding='utf-8').read()
# print(f)
# print(re.split('\W+', f))
c3 = Counter(re.split('\W+', f))
print(c3)
print(c3.most_common(5))
# [('the', 14), ('to', 9), ('in', 9), ('of', 8), ('used', 6)]
🧸��θ����ֵ���ֵ�ô�С,���ֵ��е�������?

from random import randint
# ��������ɼ���
stu_score = {x: randint(60, 100) for x in 'xyzabc'}
print(stu_score)
print(sorted(stu_score))
# ��ü�
print(stu_score.keys())
# ���ֵ
print(stu_score.values())
# ���ճɼ��ߵ���С��������
# 1.ʹ��zip����
z = zip(stu_score.values(), stu_score.keys())
z1 = list(z)
print(sorted(z1))
# 2.sorted�е�key
print(stu_score.items())
z2 = sorted(stu_score.items(), key=lambda x: x[1])
print(z2)
🧸��ο����ҵ�����ֵ�Ĺ�����(key)?

from functools import reduce
from random import randint, sample
# ������Աabcdefg
# sʹ��sampleȡ��
print(sample('abcdefg', 3))
s1 = {i: randint(1, 4) for i in sample('abcdefg', randint(3, 6))}
s2 = {i: randint(1, 4) for i in sample('abcdefg', randint(3, 6))}
s3 = {i: randint(1, 4) for i in sample('abcdefg', randint(3, 6))}
print(s1)
print(s2)
print(s3)
# 1.ʹ��forѭ��
r = []
for k in s1:
if k in s2 and k in s3:
r.append(k)
print(r)
# 2.ʹ�ü��ϲ���
r2 = s1.keys() & s2.keys() & s3.keys()
print(list(r2))
# ʹ��map��reduce
rm = map(dict.keys, [s1, s2, s3])
print(list(rm))
r3 = reduce(lambda x, y: x & y, map(dict.keys, [s1, s2, s3]))
print(r3)
🧸������ֵ䱣������?
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-5jYg3zcw-1653276902215)(https://raw.githubusercontent.com/kurry0123/Py-learn-imgs/main/img/202205231134740.png)]
# 🧸������ֵ䱣������?
# 1. ����
d = {}
d['Jim'] = (1, 35)
d['Leo'] = (2, 45)
d['Bob'] = (3, 50)
for i in d: print(i)
# ʹ��OrderedDict
from collections import OrderedDict
d2 = OrderedDict()
d2['Jim'] = (1, 35)
d2['Leo'] = (2, 45)
d2['Bob'] = (3, 50)
for i in d2: print(i)
# ģ��ϵͳ
from time import time
from random import randint
from collections import OrderedDict
players = list('ABCDEFGH')
stat_time = time()
l = len(players)
d = OrderedDict()
for i in range(l):
print('������,����ύ:')
input() # �൱�����ʱ��������,û����һ�ν���һ�˽���,��ջ
# ��ջ
p = players.pop(randint(0, l-1 - i))
end_time = time()
sum_time = end_time - stat_time
print(i + 1, p, sum_time)
d[p] = (i+1, sum_time)
print('='*20)
for k in d:
print(k, d[k])
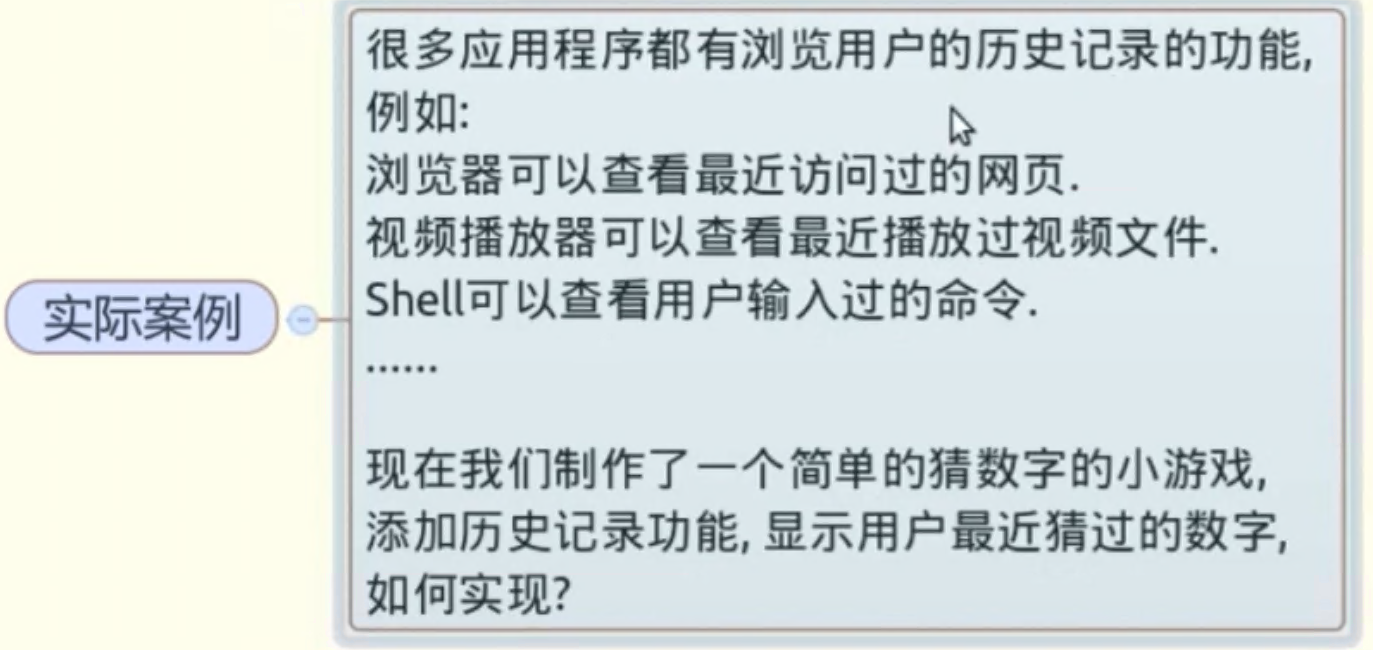
🧸���ʵ���û�����ʷ��¼����:
🎈pickle��ʹ��:
# pickle
import pickle
from collections import deque
q = deque([[20, 10, 50, 60, 70]])
print(q)
# �洢
pickle.dump(q, open('history_demo', 'wb'))
q2 = pickle.load(open('history_demo', 'rb'))
print(q2)
������Ϸʵ��:
from random import randint
from collections import deque
import pickle
N = randint(0, 100)
history = deque([], 5)
def guss(k):
if k == N:
print('Right')
return True
if k < N:
print('%s is less-than N' %k)
else:
print('%s is greater-than N'%k)
return False
while True:
line = input('Please input a number:')
if line.isdigit():
k = int(line)
history.append(k)
pickle.dump(history, open('history', 'wb'))
if guss(k):
break
elif line == 'history' or 'h?':
print(list(history))
print(pickle.load(open('history', 'rb')))

