前言:
之前看了云朵dalao的一篇关于关键词提取的文章,其中介绍的 Yake 模型采用了大写词、词位置、全文词频、上下文关系、句间词频等 5 个指标,计算候选词得分。感觉设计上较直观、易解释,但原 yake 库不支持中文,于是笔者便抄公式劣改了一番。
一、对中文复刻版 iyake_cn
原 yake 库的核心公式不多赘述,可浏览原文了解。由于中文没有像英文单词大写这样的特征,笔者只采用了后 4 个指标,我们来逐个实现一下。
1、前置准备
中文文本中也可能含有英语单词,可以先准备好两份停用词列表,读入成集合,这样在过滤停用词时可以大幅提高效率。可先行过滤掉数字,以及单个字的分词。
def get_stopwords(txt_file):
return set([line.strip() for line in open(txt_file, 'r', encoding='utf-8').readlines()])
stopwords = get_stopwords('english.txt').union(get_stopwords('chinese.txt'))
clean_str = re.sub(r'[0-9]', '', content) # content 为传入的原始文本
jb_lst = [w for w in jieba.lcut(clean_str) if len(w) > 1]
jb_lst = [w for w in jb_lst if w not in stop]
再准备好唯一词,即候选词列表,以便对每个候选词进行独立评分。
uni_lst = list(set(jb_lst))
uni_lst.sort(key=jb_lst.index) # 固定顺序唯一词
2.词位置指标 T_pos
依照越靠前的句子越重要的理念,词出现的位置也体现其重要程度。原 yake 库设计的是分析候选词所在的句子,用该句子在全文中的位置中位数来计算。笔者考虑既可以用词所在的句子,也可以用词本身在全文中的位置。也就是说 get_pos_lst() 可以传入分词列表(前文的 jb_lst),也可以传入分句列表(见下文)。之后获取单个候选词在分词或分句列表中出现的所有位置,再计算位置中位数。在计算 T_pos 指标时,用的是二次 log 对数做归一化,为避免开头的词必然成为关键词的情形,将全文词位置(索引)从 1 开始计算。
def get_pos_lst(words_lst): # 分词的位置列表
return list(zip(words_lst, range(1, len(words_lst)+1)))
def get_T_pos(pos_lst, word): # 单个词的T_pos指标
_lst = [i[1] for i in pos_lst if word in i[0]]
_lst.sort()
half = len(_lst) // 2
median = (_lst[half] + _lst[~half]) / 2
return log2(log2(median+2))
绘制 y = log2(log2(2+x)) 的图像,可见词位置越靠前,T_pos 分越低(Yake 模型中候选词最终得分越低,则越重要,T_pos 作为分子)。
from matplotlib import pyplot as plt
from math import log2
x = [i for i in range(0, 11)]
y = [log2(log2(2 + i)) for i in x]
plt.plot(x, y)
plt.show()

3、全文词频指标 TF_norm
词频是最直观的指标,出现越多的词越重要,TF_norm 作为 Yake 模型分母。可先用字典记录候选词的词频,再计算均值、标准差、最值等。原 yake 库采用词频与均值、方差之和的比值,作为归一化的 TF_norm 得分结果,笔者增加了经典的 max-min 归一化做对比。
def words_count(words_lst):
counts_dict = {}
for word in words_lst:
counts_dict[word] = counts_dict.get(word, 0) + 1
return counts_dict
wc_dic = words_count(jb_lst)
mean_tf = sum(wc_dic.values())/len(uni_lst) # 词频均值
std_tf = np.std(list(wc_dic.values())) # 词频标准差
max_tf = max(list(wc_dic.values()))
min_tf = min(list(wc_dic.values()))
# w 为某一个候选词
TF_norm = wc_dic.get(w)/(mean_tf + std_tf) # yake版归一化
TF_norm = (wc_dic.get(w)-min_tf) / (max_tf-min_tf) # max-min归一化
4、上下文关系指标 T_Rel
候选词的前后文中出现越多不同的词,其重要程度越低,T_Rel 作为各指标的调和项。笔者以 10 为窗口大小计算候选词向左(前文)和向右(后文)共现的唯一词的个数。
def related_content(words_lst, word, size=10): # 单个词的T_Rel指标
split_lst = ' '.join(words_lst).split(word)
left_lst = split_lst[:-1]
right_lst = split_lst[1:]
DL = 0
for i in left_lst: # 从 word 出现的每个地方往左取 size 个词,计算不重复词数
left_words = i.split(' ')[-2: -2-size: -1]
DL += len(set(left_words))
DR = 0
for i in right_lst: # 从 word 出现的每个地方往右
right_words = i.split(' ')[1: size+1]
DR += len(set(right_words))
return DL/len(left_lst)+DR/len(right_lst)
进而计算候选词的 T_Rel 指标。
DL_RL = related_content(jb_lst, w)
T_Rel = 1 + DL_RL * wc_dic.get(w)/max(wc_dic.values())
5、句间词频指标 T_sentence
句间词频指的是包含候选词的句子数量,T_sentence 作为 Yake 模型的分母,以候选句数量和句子总数的比值作为该指标得分结果。可以按中文常见标点符号作为句子分割标志,得到分句列表,再统计候选句数量。
split_content = re.split(r'[,。?!]', clean_str)
len_content = len(split_content)
SF_dic = {}
for w in uni_lst:
for sentence in split_content:
if w in sentence:
SF_dic[w] = SF_dic.get(w, 0) + 1
t_sentence_scores = [(i[0], i[1]/len_content) for i in list(SF_dic.items())]
6、总分(重要性) S_t
重要性 S_t 以 T_pos 为分子,TF_norm、T_sentence 为分母,T_Rel 调和计算,adjust 为原 Yake 模型中的大写指标的替代,笔者设置为 0 或 1 进行效果比较。最终 S_t 结果越小,表示候选词越重要。
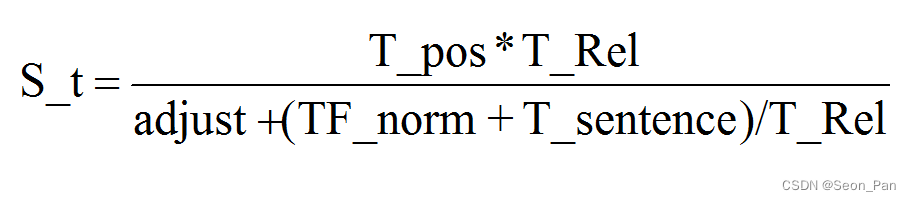
二、关键词提取测试
1、方法封装
笔者将算分流程封装成 get_S_t(),包含多个可配置项,见注释。
get_S_t(content, stop=None, pos_type='s', tf_normal='yake', adjust=1)
# stop:停用词列表(集合)
# pos_type:位置指标类型,'s'为按分句,'w'为按分词
# tf_normal:全文词频指标归一化方式,'yake'为原版,'mm'为 max-min
# adjust:分母调整值
该函数返回一个 DataFrame 形式的评分表,按候选词原始位置排序,见下表。

增加一个取词器,传入评分表,默认返回 10 个关键词,按总分 S_t 升序。
def get_key_words(df_scores, top=10, sort_col='s_t', ascend=True): # 获取关键词列表,默认前10个,升序
df = df_scores.sort_values(sort_col, ascending=ascend)
key_words = df['word'].to_list()
return key_words[:top]
对每个文本都试验一下 8 种参数组合的提取效果,并与纯词频排名得到的高频词做对比。
df = None
for a in [0, 1]:
for p in ['s', 'w']:
for n in ['yake', 'mm']:
df = get_S_t(txt, stop=stopwords, pos_type=p, tf_normal=n, adjust=a) # txt 为传入的文本
words = get_key_words(df)
print(f'{a}_{p}_{n}', words)
hot_words = get_key_words(df, sort_col='fre', ascend=False)
print('hot_words', hot_words)
2、初步测试
短文本用例,摘自云朵君原文部分:
它是一种轻量级、无监督的自动关键词提取方法,它依赖于从单个文档中提取的统计文本特征来识别文本中最相关的关键词。该方法不需要针对特定的文档集进行训练,也不依赖于字典、文本大小、领域或语言。Yake 定义了一组五个特征来捕捉关键词特征,这些特征被启发式地组合起来,为每个关键词分配一个分数。分数越低,关键字越重要。
输出:
0_s_yake [‘轻量级’, ‘监督’, ‘自动’, ‘分数’, ‘提取’, ‘越低’, ‘关键字’, ‘分配’, ‘统计’, ‘起来’]
0_s_mm [‘分数’, ‘提取’, ‘轻量级’, ‘监督’, ‘自动’, ‘越低’, ‘关键字’, ‘特征’, ‘文本’, ‘关键词’]
0_w_yake [‘轻量级’, ‘监督’, ‘自动’, ‘分数’, ‘越低’, ‘关键字’, ‘提取’, ‘分配’, ‘起来’, ‘统计’]
0_w_mm [‘分数’, ‘轻量级’, ‘提取’, ‘监督’, ‘自动’, ‘越低’, ‘关键字’, ‘特征’, ‘文本’, ‘分配’]
1_s_yake [‘轻量级’, ‘监督’, ‘自动’, ‘提取’, ‘越低’, ‘统计’, ‘关键字’, ‘分数’, ‘识别’, ‘相关’]
1_s_mm [‘轻量级’, ‘监督’, ‘自动’, ‘提取’, ‘统计’, ‘越低’, ‘关键字’, ‘识别’, ‘相关’, ‘分数’]
1_w_yake [‘轻量级’, ‘监督’, ‘自动’, ‘越低’, ‘关键字’, ‘分数’, ‘分配’, ‘提取’, ‘统计’, ‘起来’]
1_w_mm [‘轻量级’, ‘监督’, ‘自动’, ‘越低’, ‘关键字’, ‘分数’, ‘分配’, ‘提取’, ‘统计’, ‘起来’]
hot_words [‘特征’, ‘关键词’, ‘文本’, ‘提取’, ‘依赖于’, ‘文档’, ‘分数’, ‘组合’, ‘定义’, ‘五个’]
再以云朵君的原文全文做测试,补充值为 1 时,核心主题自然语言和作者云朵都提取出来了,莫非效果不错?其实是因为这两个词都出现在全文开头,且其上下文中包含除停用词外的词极少,虽然词频指标不佳,但仍被提升了重要性。输出如下:
0_s_yake [‘自然语言’, ‘分句’, ‘显式’, ‘NLP’, ‘TFIDF’, ‘word’, ‘分值’, ‘Python’, ‘list’, ‘场景’]
0_s_mm [‘word’, ‘en’, ‘关键’, ‘分句’, ‘显式’, ‘keyword’, ‘分值’, ‘Python’, ‘Keyword’, ‘特征’]
0_w_yake [‘自然语言’, ‘分句’, ‘word’, ‘显式’, ‘分值’, ‘list’, ‘TFIDF’, ‘multi’, ‘NLP’, ‘数组’]
0_w_mm [‘en’, ‘word’, ‘关键’, ‘分句’, ‘显式’, ‘keyword’, ‘分值’, ‘BERT’, ‘Keyword’, ‘keybert’]
1_s_yake [‘自然语言’, ‘云朵’, ‘场景’, ‘NLP’, ‘用于’, ‘语料库’, ‘加权’, ‘任务’, ‘语言’, ‘缺点’]
1_s_mm [‘自然语言’, ‘云朵’, ‘场景’, ‘用于’, ‘加权’, ‘语料库’, ‘NLP’, ‘任务’, ‘语言’, ‘缺点’]
1_w_yake [‘自然语言’, ‘云朵’, ‘场景’, ‘任务’, ‘语料库’, ‘en’, ‘加权’, ‘检验’, ‘检查’, ‘缺点’]
1_w_mm [‘自然语言’, ‘云朵’, ‘场景’, ‘任务’, ‘语料库’, ‘加权’, ‘en’, ‘检验’, ‘缺点’, ‘检查’]
hot_words [‘单词’, ‘关键字’, ‘文本’, ‘关键词’, ‘提取’, ‘keywords’, ‘短语’, ‘text’, ‘候选’, ‘文档’]
作者指定关键词:关键字提取、关键短语提取、Python、NLP、TextRank、Rake、BERT
以朱自清的《背影》做测试,不尽如人意。输出如下:
0_s_yake [‘二年’, ‘忘记’, ‘冬天’, ‘差使’, ‘交卸’, ‘一半’, ‘祸不单行’, ‘相见’, ‘行李’, ‘再能’]
0_s_mm [‘一半’, ‘丧事’, ‘相见’, ‘行李’, ‘惦记着’, ‘徐州’, ‘南京’, ‘橘子’, ‘祖母’, ‘茶房’]
0_w_yake [‘二年’, ‘忘记’, ‘冬天’, ‘一半’, ‘相见’, ‘再能’, ‘行李’, ‘差使’, ‘交卸’, ‘不知’]
0_w_mm [‘一半’, ‘相见’, ‘丧事’, ‘行李’, ‘惦记着’, ‘橘子’, ‘南京’, ‘徐州’, ‘黑布’, ‘茶房’]
1_s_yake [‘二年’, ‘忘记’, ‘冬天’, ‘差使’, ‘交卸’, ‘祸不单行’, ‘奔丧’, ‘打算’, ‘跟着’, ‘满院’]
1_s_mm [‘二年’, ‘忘记’, ‘冬天’, ‘差使’, ‘交卸’, ‘祸不单行’, ‘跟着’, ‘打算’, ‘奔丧’, ‘满院’]
1_w_yake [‘二年’, ‘忘记’, ‘冬天’, ‘差使’, ‘交卸’, ‘祸不单行’, ‘打算’, ‘跟着’, ‘再能’, ‘奔丧’]
1_w_mm [‘二年’, ‘忘记’, ‘冬天’, ‘差使’, ‘交卸’, ‘祸不单行’, ‘打算’, ‘跟着’, ‘奔丧’, ‘满院’]
hot_words [‘父亲’, ‘看见’, ‘橘子’, ‘铁道’, ‘背影’, ‘茶房’, ‘终于’, ‘北京’, ‘一日’, ‘丧事’]
由此可发现,词位置指标的影响太大,文本开头的词若其词频小,意味着没有与其他词共现的机会,将导致其上下文关系指标失衡,从而使整体得分偏低,重要性异常高。如此对长文本的开头便有要求,如果没有概述类的描述文本,将会使第一个段落中靠前的词成为全篇关键词。并且,对散文的适用性不高。
用更长的文本试试,以笔者毕业论文做测试,将标题下的学院、姓名、摘要提取了,显然效果很差,还不如高频词,当然,也受停用词不完善的影响。输出如下:
0_s_yake [‘工程学院’, ‘姓名’, ‘摘要’, ‘形状’, ‘水盆’, ‘key’, ‘导航页’, ‘信号’, ‘窗体’, ‘诊断’]
0_s_mm [‘形状’, ‘水盆’, ‘key’, ‘导航页’, ‘信号’, ‘设置’, ‘窗体’, ‘程序’, ‘查找’, ‘诊断’]
0_w_yake [‘水盆’, ‘key’, ‘形状’, ‘导航页’, ‘信号’, ‘窗体’, ‘盆地’, ‘查找’, ‘孤立’, ‘QImage’]
0_w_mm [‘水盆’, ‘形状’, ‘key’, ‘导航页’, ‘信号’, ‘查找’, ‘设置’, ‘窗体’, ‘孤立’, ‘演化’]
1_s_yake [‘工程学院’, ‘姓名’, ‘摘要’, ‘各个领域’, ‘广泛’, ‘尤为重要’, ‘利于’, ‘引导’, ‘临床’, ‘疾病’]
1_s_mm [‘工程学院’, ‘姓名’, ‘摘要’, ‘各个领域’, ‘广泛’, ‘尤为重要’, ‘利于’, ‘临床’, ‘疾病’, ‘外科手术’]
1_w_yake [‘工程学院’, ‘姓名’, ‘摘要’, ‘广泛’, ‘各个领域’, ‘尤为重要’, ‘利于’, ‘引导’, ‘临床’, ‘外科手术’]
1_w_mm [‘工程学院’, ‘姓名’, ‘摘要’, ‘广泛’, ‘各个领域’, ‘尤为重要’, ‘利于’, ‘临床’, ‘外科手术’, ‘疾病’]
hot_words [‘图像’, ‘分割’, ‘算法’, ‘区域’, ‘阈值’, ‘像素’, ‘水平’, ‘灰度’, ‘实现’, ‘种子’]
3、尝试优化
分析评分表发现,T_pos 和 T_rel 的影响较大,符合前文推测。TF_norm 作为关键词指标有足够的代表性,其权重可不调整。那么优化方向就是使 T_pos 和 T_rel 更平衡。

首先将 T_pos 的归一化方法改成 log10(log10(10 + x))+1,减少排在前面的词的影响。

一个词出现次数越多,也越容易与其他词共现,词频指标无法在总分上拉回 T_Rel 值过大时造成的影响,试用唯一词数做分母缩放 DL_RL。
T_Rel = 1 + DL_RL * wc_dic.get(w)/len(uni_lst) # max(wc_dic.values())
再测试一下,似乎改善了其中 6 种组合的效果,仍有 2 种使用 max-min 的组合有问题。
0_s_yake [‘阈值’, ‘像素’, ‘种子’, ‘水平’, ‘区域’, ‘灰度’, ‘算法’, ‘工具’, ‘分割’, ‘图像’]
0_s_mm [‘阈值’, ‘像素’, ‘种子’, ‘区域’, ‘水平’, ‘灰度’, ‘算法’, ‘分割’, ‘工具’, ‘图像’]
0_w_yake [‘阈值’, ‘像素’, ‘种子’, ‘水平’, ‘区域’, ‘灰度’, ‘算法’, ‘工具’, ‘函数’, ‘分割’]
0_w_mm [‘阈值’, ‘像素’, ‘种子’, ‘区域’, ‘水平’, ‘灰度’, ‘算法’, ‘分割’, ‘工具’, ‘图像’]
1_s_yake [‘阈值’, ‘种子’, ‘像素’, ‘工具’, ‘灰度’, ‘水平’, ‘分水岭’, ‘函数’, ‘医学’, ‘选择’]
1_s_mm [‘工程学院’, ‘摘要’, ‘姓名’, ‘广泛’, ‘各个领域’, ‘引导’, ‘临床’, ‘疾病’, ‘外科手术’, ‘重构’]
1_w_yake [‘阈值’, ‘种子’, ‘函数’, ‘像素’, ‘工具’, ‘水平’, ‘灰度’, ‘分水岭’, ‘医学’, ‘轮廓’]
1_w_mm [‘工程学院’, ‘姓名’, ‘摘要’, ‘广泛’, ‘各个领域’, ‘临床’, ‘引导’, ‘外科手术’, ‘疾病’, ‘重构’]
hot_words [‘图像’, ‘分割’, ‘算法’, ‘区域’, ‘阈值’, ‘像素’, ‘水平’, ‘灰度’, ‘实现’, ‘种子’]
4、性能测试
对 1000 份平均 300 字的文本进行提取共用时 13 秒。
df = pd.read_excel('test.xlsx')
start = time()
df['关键词'] = df['内容'].apply(
lambda x: get_key_words(get_S_t(x, stop=stopwords)))
print(time()-start)
12.777400016784668
四、小结
作为练习,笔者模仿 Yake 完成的 iyake_cn 模型在一定程度上实现了提取关键词的目标,它还可在全文词频归一化方式、上下文关系窗口大小、句子分割标志选取、补足分母的指标(adjust)等方面进行调参测试,并在整体计算上优化。此外,虽然 iyake_cn 比单纯的高频词提取效果要好,但停用词的维护依然是很重要的一环。
笔者已将 iyake_cn 上传至 pypi,使用pip install iyake-cn即可拆箱使用(未做边界检查,或存在 BUG ),也可直接查看完整源码,最终可用参数:
get_S_t(content, only_cn=False, stop=None, pos_type='s', median_fn=None, tf_normal='yake', adjust=1, r_size=10)
# content:原始文本
# only_cn:True 则是纯中文分析,若文本中含英文词汇将被过滤
# stop:停用词列表(集合)
# pos_type:位置指标类型,'s'为按分句,'w'为按分词
# median_fn:可传入位置中值处理函数,例如 lambda x: log2(log2(x+2)),x为 T_pos 中的 median
# tf_normal:全文词频指标归一化方式,'yake'为原版,'mm'为 max-min
# adjust:分母调整值
# r_size:上下文关系指标的窗口大小
get_key_words(df_scores, top=10, sort_col='s_t', ascend=True, p=None)
# df_scores:get_S_t()返回值
# top:提取数量
# sort_col:提取依据列
# ascend:依据列的排序方式
# p:指定单个词性的关键词,如 'a'为形容词、'v'为动词、'n'为名词等
用例:
from iyake_cn import get_S_t, get_key_words, get_stopwords
# from iyake_cn import cn_stopwords, en_stopwords ## 也可导入预置的停用词集合
txt = '作为练习,笔者模仿 Yake 完成的 iyake_cn 模型在一定程度上实现了提取关键词的目标,它还可在全文词频归一化方式、上下文关系窗口大小、句子分割标志选取、补足分母的指标(adjust)等方面进行调参测试,并在整体计算上优化。此外,虽然 iyake_cn 比单纯的高频词提取效果要好,但停用词的维护依然是很重要的一环。'
df = get_S_t(txt, stop=get_stopwords('mystopwords.txt'))
words = get_key_words(df)
print(words)
words = get_key_words(df, p='v')
print(words)
[‘练习’, ‘笔者’, ‘一环’, ‘模仿’, ‘维护’, ‘Yake’, ‘用词’, ‘效果’, ‘模型’, ‘高频词’]
[‘练习’, ‘模仿’, ‘维护’, ‘提取’, ‘分割’, ‘选取’, ‘补足’, ‘调参’, ‘计算’]

