参考
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
https://d2l.ai/
1 从最基础的神经网络开始
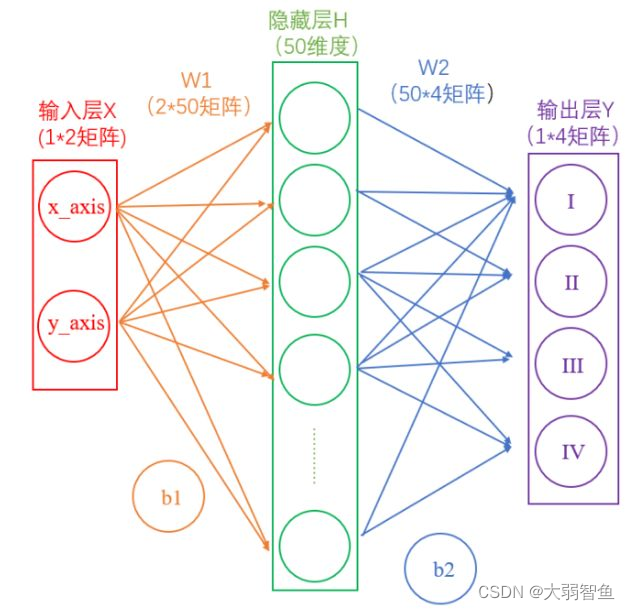
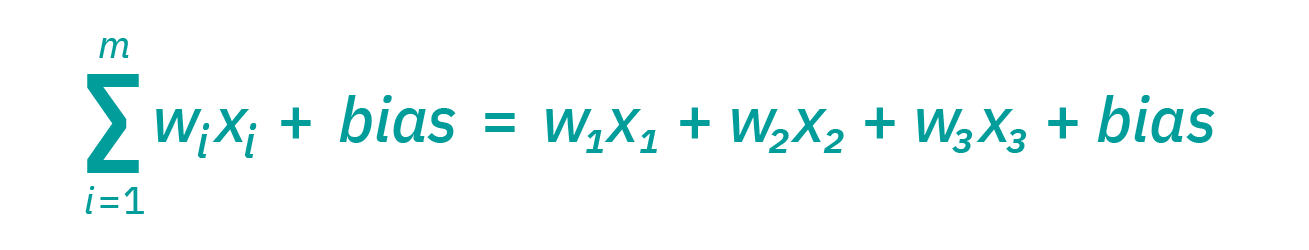
H = X × W 1 + b 1 Y = H × W 2 + b 2 = > Y = ( X × W 1 + b 1 ) × W 2 + b 2 H = X\times W_1 + b_1 \\ Y = H\times W_2 + b_2 \\ =>Y = (X\times W_1+b_1)\times W_2 +b_2 H=X×W1?+b1?Y=H×W2?+b2?=>Y=(X×W1?+b1?)×W2?+b2?
为了增加非线性,引入激活函数,
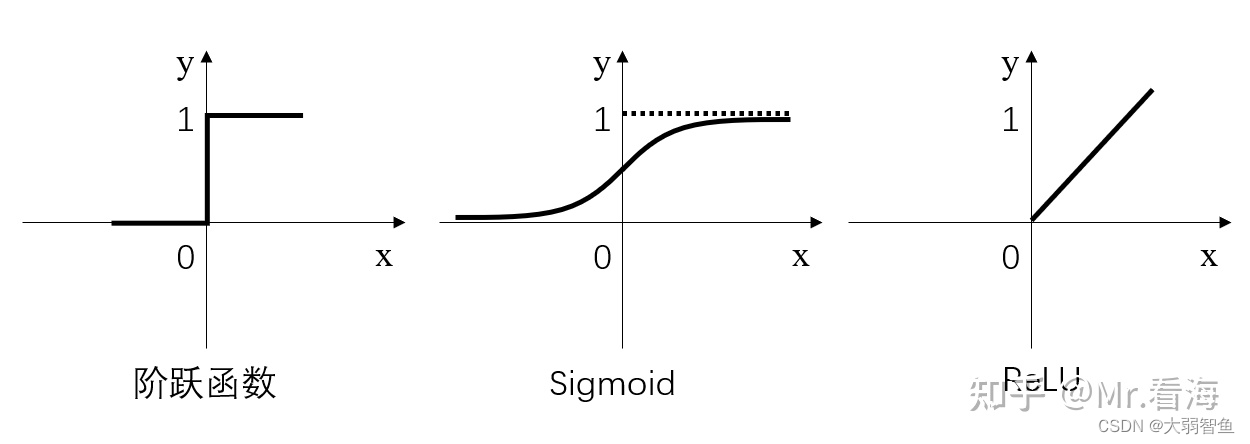
比较基础的是
S
i
g
m
o
i
d
(
x
)
=
1
1
+
e
?
x
Sigmoid(x) = \frac{1}{1+e^{-x}}
Sigmoid(x)=1+e?x1?,现在最常用的是
R
e
l
u
(
x
)
=
{
x
x
>
0
0
x
≤
0
Relu(x)=\begin{cases} x & x > 0 \\ 0 & x \leq 0 \end{cases}
Relu(x)={x0?x>0x≤0?
要输出几个值,就设置几个输出神经元,输出的正规化的常用softmax运算
S
i
=
e
i
∑
j
e
j
S_i=\frac{e^i}{\sum_j e^j}
Si?=∑j?ejei?
为什么不直接用各自数值的比呢?因为加了一个指数操作后可以起到扩大差异的作用。
深度学习一般是有监督的学习,也就是说需要知道样本的标签是什么。也就是说,我们的训练样本应该是
[
X
,
Y
]
[X,Y]
[X,Y],通过我们的网络
f
(
)
f()
f(),可以得到
Y
^
=
f
(
X
)
\hat{Y}=f(X)
Y^=f(X),这样我们就有了目标样本
Y
Y
Y和预测
Y
^
\hat{Y}
Y^,显然两者的距离越近越好。
那么如何衡量两个的距离,常用的方式有:MSE(均方误差),Cross Entropy Error(交叉熵损失)。
知道了我们目前的模型在一批数据下的表现与我们的目标差了多远,这个多远可以用一个数值来衡量,然后就可以使用反向传播进行梯度下降法更新网络参数就好。当然,现在的工具封装的都很好,我们不需要手动实现具体的这些步骤,只要不断调用系统提供的函数就好。后面会给出代码讲解。
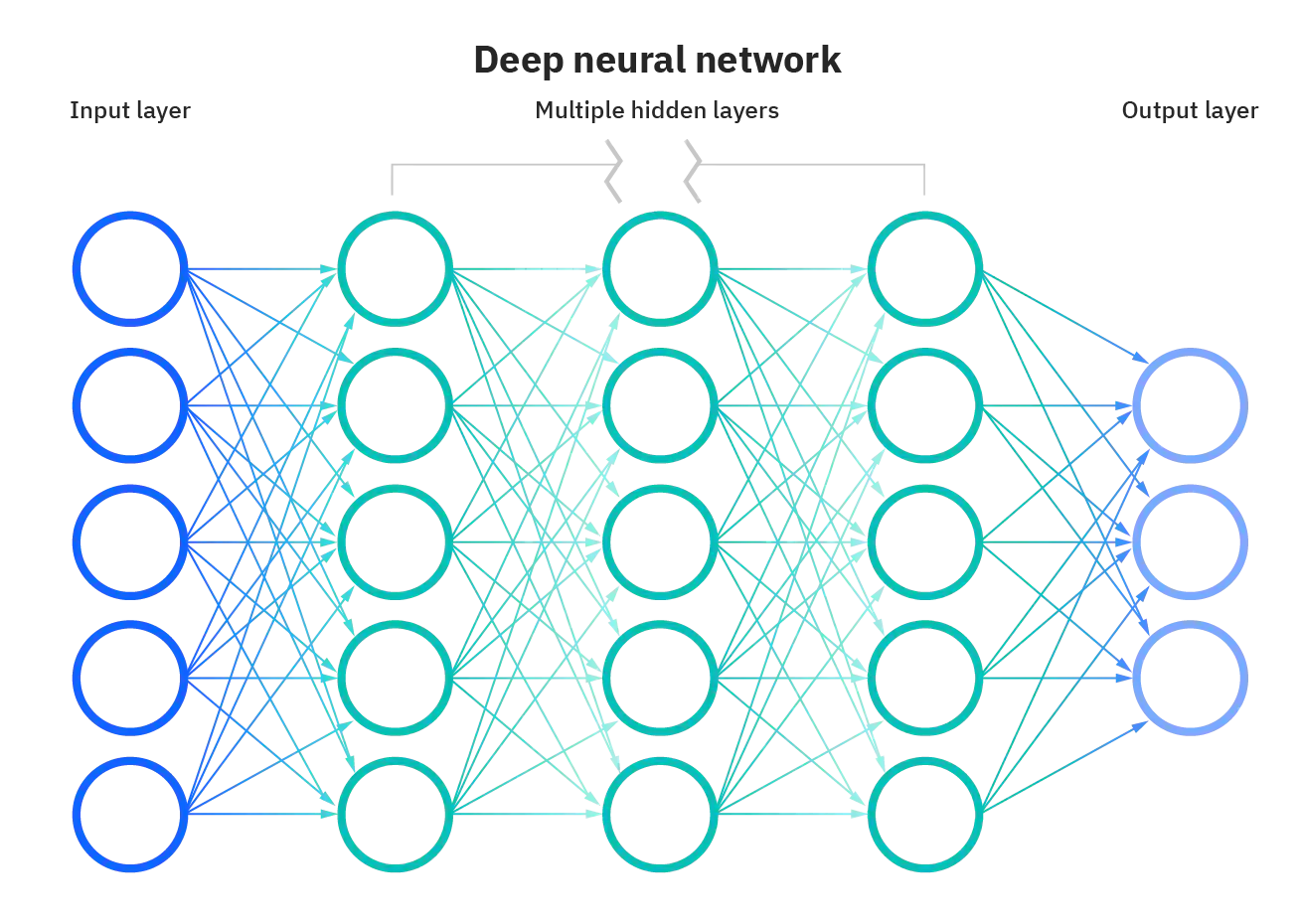
上面讲解的就是普通的一个神经网络的训练过程,那么什么是深度学习,深度的意思就是说隐藏层很多。
2 LeNet
它是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像 [LeCun et al., 1998]中的手写数字。 当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。 LeNet被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字。 时至今日,一些自动取款机仍在运行Yann LeCun和他的同事Leon Bottou在上世纪90年代写的代码.
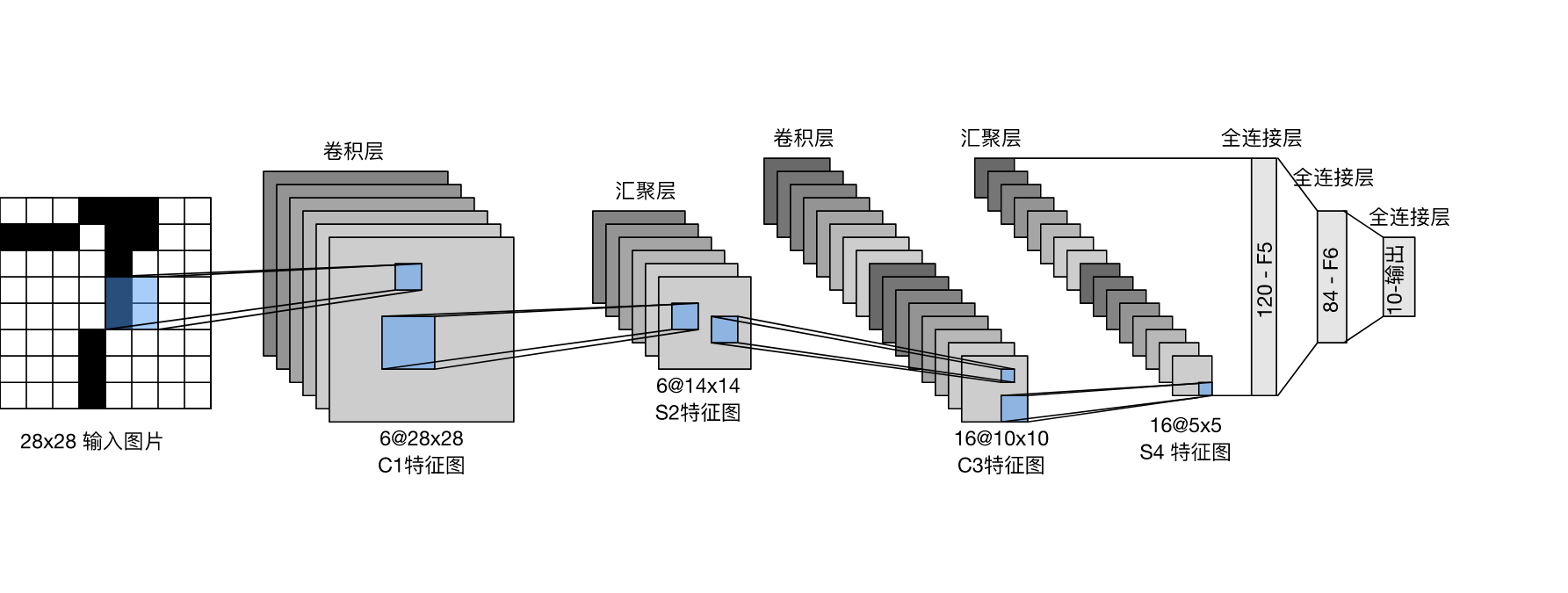
图片的数据格式
一张图片就是多个矩阵。对于一张尺寸为高和宽 100 × 100 100\times100 100×100的图片,比较常用的格式是RGB格式,也就说这张图片有三个通道,分别是红色通道,绿色通道,蓝色通道,每个通道上是 100 × 100 100\times 100 100×100的矩阵。矩阵上的每个值都是在[0,255]之间。也就是说,一张图片的数据形状是 3 × H × W 3\times H\times W 3×H×W,那一个批量的数据大小就是 B a t c h × 3 × H × W Batch \times3\times H\times W Batch×3×H×W. 也就是说,图片就是一堆数字罢了。
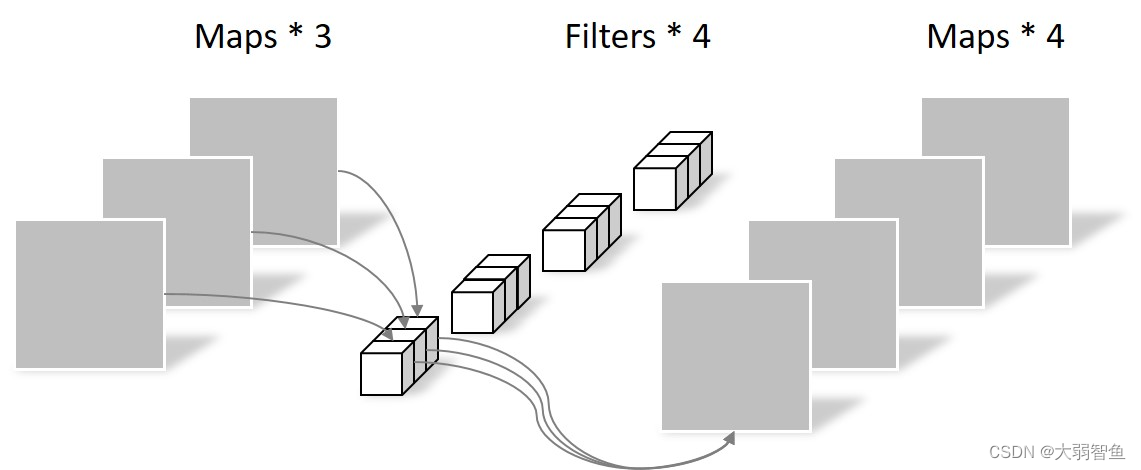
卷积运算
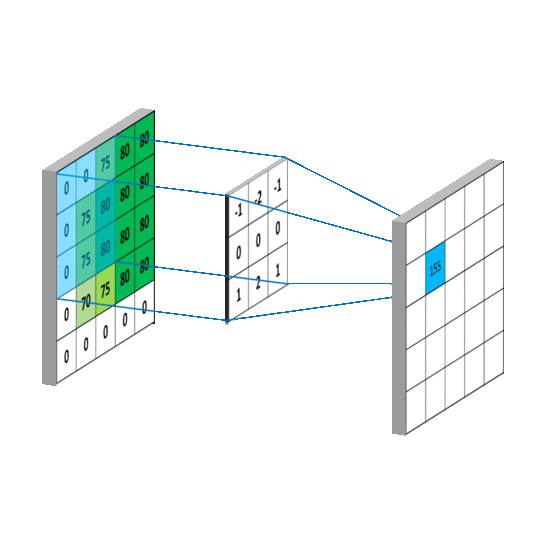
输入输出都是一个通道
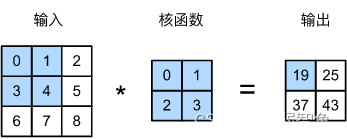
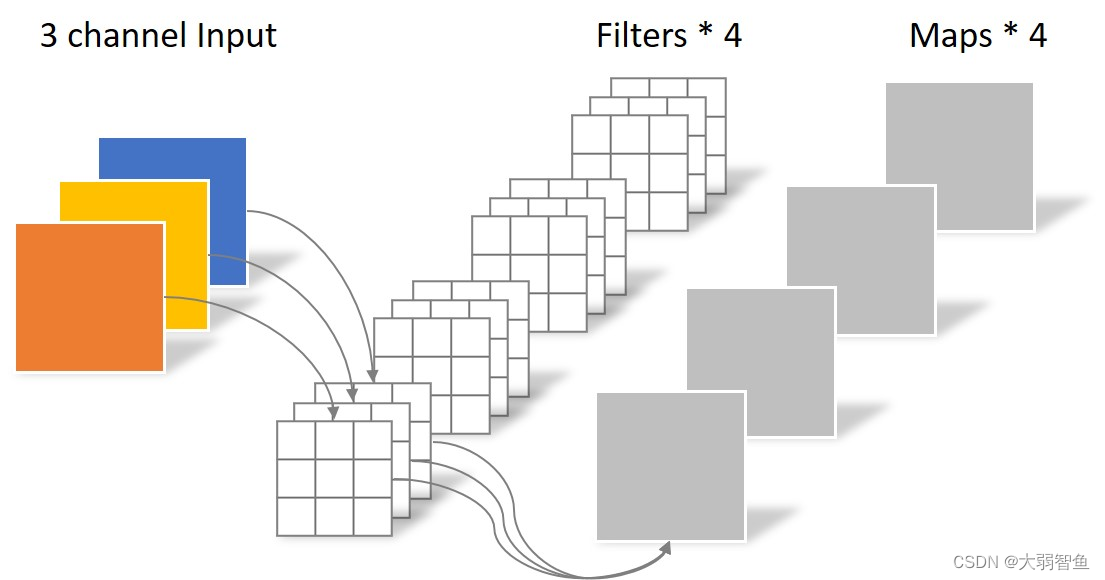
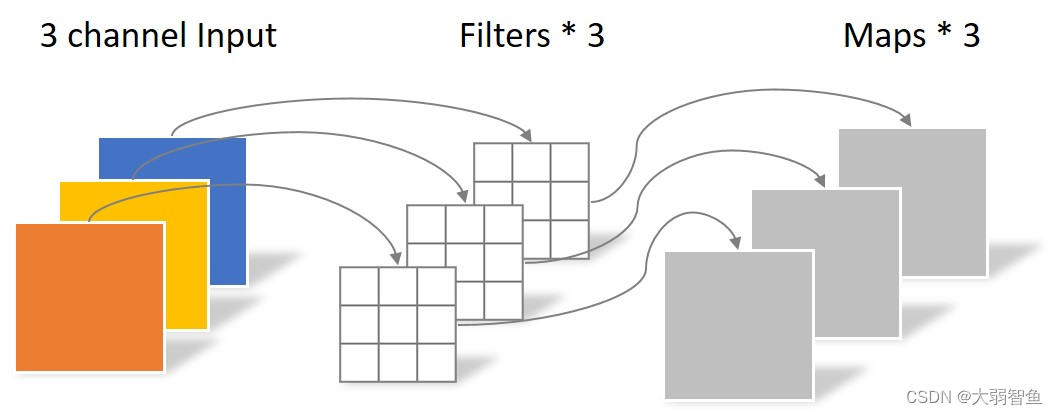
输入两个通道,输出一个通道
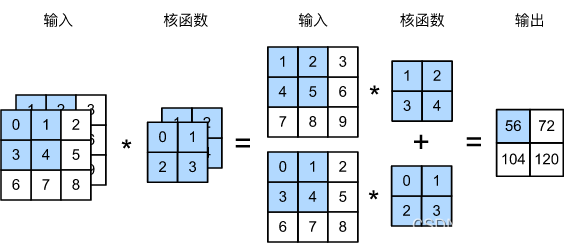
输入三个通道,输出两个通道。

池化层、汇聚层
不改变通道,改变尺寸。
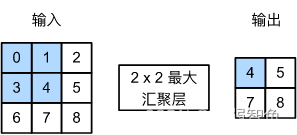
3 Pytorch是目前最主流的深度学习框架
其他用的最多的就是tensorflow,keras
4 AlexNet
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)。
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
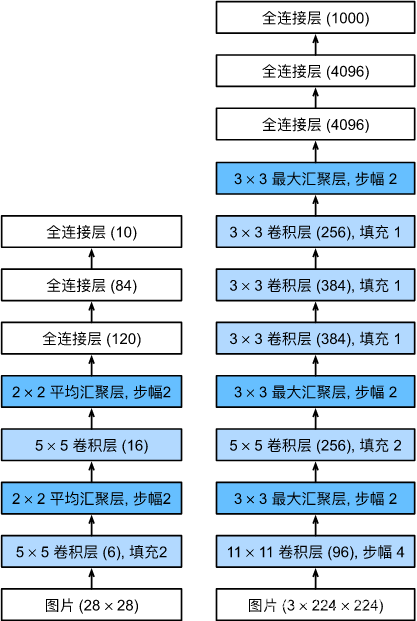
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。 首先,AlexNet比相对较小的LeNet5要深得多。 AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。 其次,AlexNet使用ReLU而不是sigmoid作为其激活函数。 下面,让我们深入研究AlexNet的细节。
5 VGG
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。
牛津大学的视觉几何组(visualgeometry group)
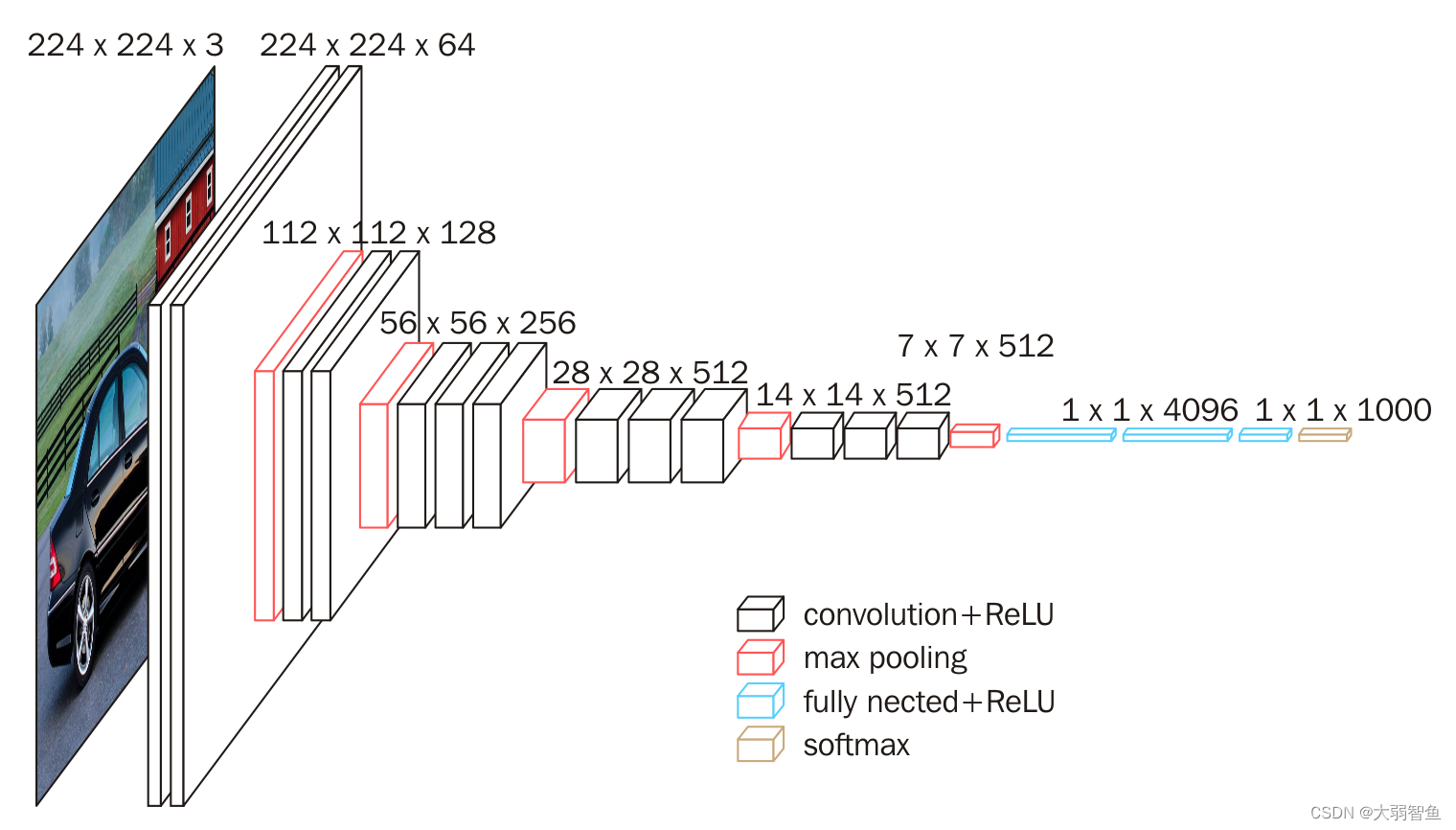
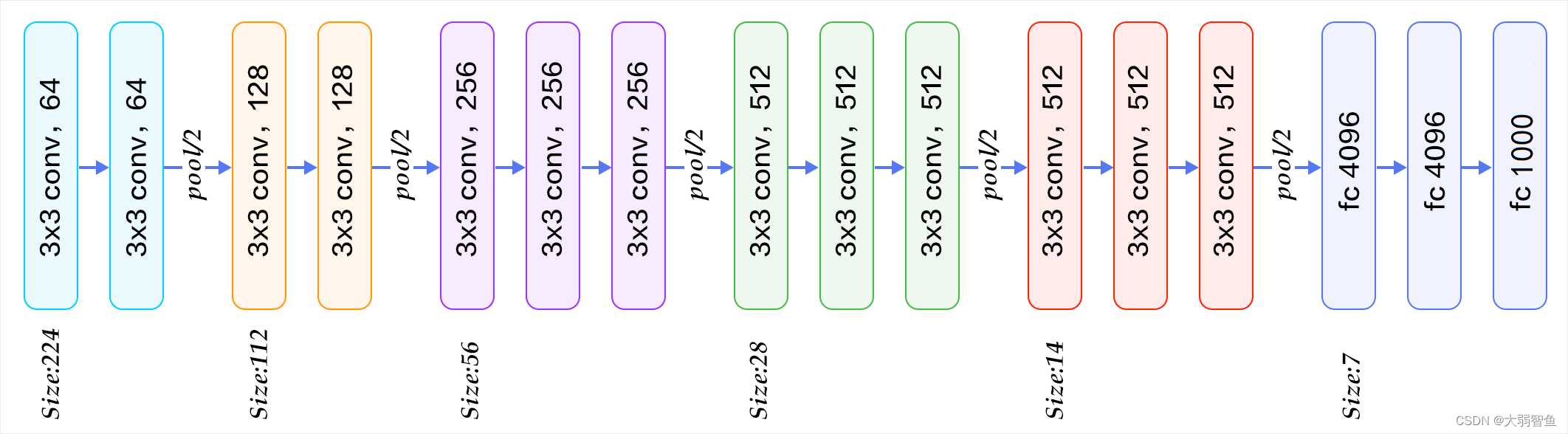
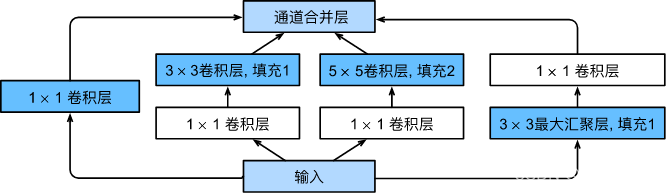
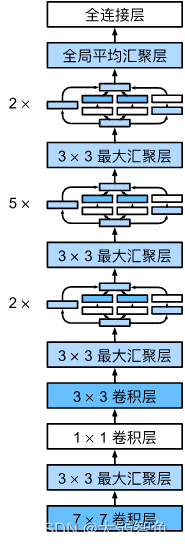
6 GoogLeNet 含并行连结的网络
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。
7 ResNet 残差网络
按理说,较深的网络肯定会比较浅的网络性能,最差的情况深网络也不应该比浅网络性能差。如果浅网络是
f
(
x
)
f(x)
f(x),那么加深这个网络就会得到
g
(
f
(
x
)
)
g(f(x))
g(f(x)),在
g
(
x
)
g(x)
g(x)为恒等函数的情况下,两者应该是相等的。但目前网络具体表现上并不是这样,过深的网络性能甚至会下降很多。这篇文章之前的解释是梯度消失和梯度爆炸。

但何凯明觉得很多正则化处理方式已经可以很大程度上的避免了这个问题,那是为什么深的网络会退化呢?
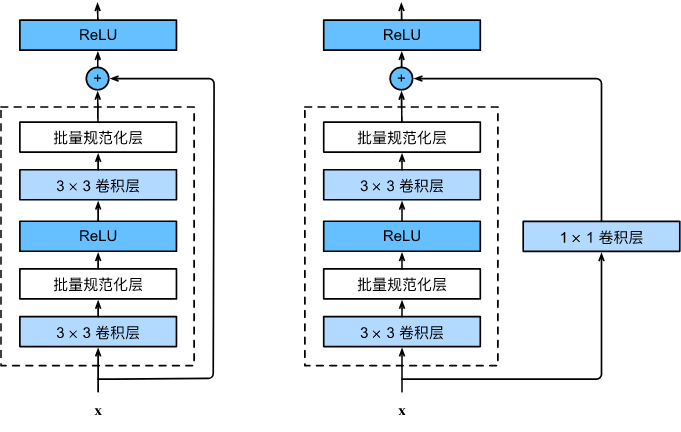
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
8 MobileNet
这篇论文是谷歌在2017年提出了,专注于移动端或者嵌入式设备中的轻量级CNN网络。该论文最大的创新点是,提出了深度可分离卷积(depthwise separable convolution)
简单来说,MobileNet v1就是将常规卷积替换为深度可分离卷积的VGG网络。
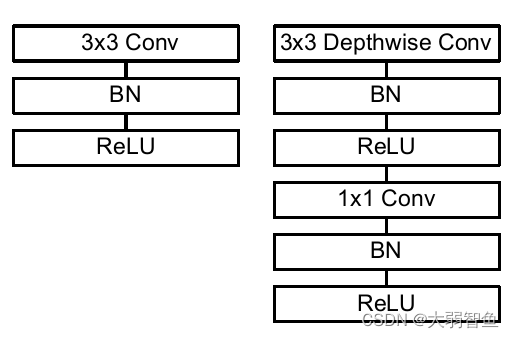
depthwise卷积(DW卷积)
Pointwise卷积
简单来说就是用
1
×
1
1\times 1
1×1的卷积核
降低参数数量,深度可分离卷积的参数约是常规卷积的三分之一。
MobileNet v1的特色就是深度可分离卷积,但研究人员发现深度可分离卷积中有大量卷积核为0,即有很多卷积核没有参与实际计算。是什么原因造成的呢?v2的作者发现是ReLU激活函数的问题,认为ReLU这个激活函数,在低维空间运算中会损失很多信息,而在高维空间中会保留较多有用信息。
既然如此,v2的解决方案也很简单,就是直接将ReLU6激活换成线性激活函数,当然也不是全都换,只是将最后一层的ReLU换成线性函数。具体到v2网络中就是将最后的Point-Wise卷积的ReLU6都换成线性函数。v2给这个操作命名为linear bottleneck,这也是v2网络的第一个关键点。
9 DenseNet 稠密网络


10 常见迁移学习的方式
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层。(微调Fine-Tune)
11 语义分割里程碑之作FCN
语义分割

转置卷积
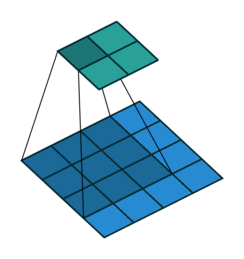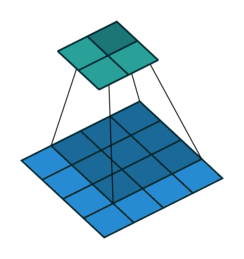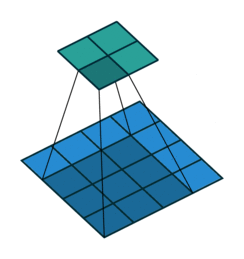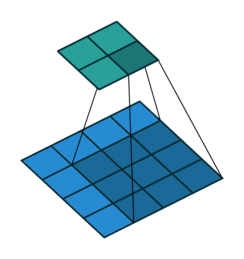 
FCN全卷积网络
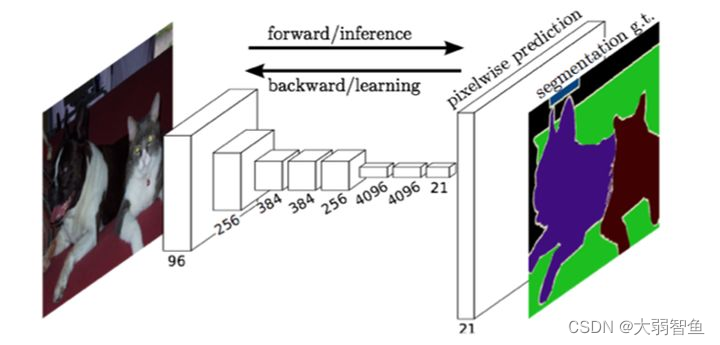
也就是说,前面提取特征部分的网络就是backbone,是深度学习的上游任务;要做语义分割,只要修改下游任务就可以。
12 循环神经网络
文本的编码
I love USTC!
每个单词要用数字表示,一个样本就是一句话,一句话是多个单词。
假设每个人单词的编码长度是固定的,每个单词用128个数进行编码,那么一批样本的shape就是
B
×
s
e
q
l
e
n
×
w
o
r
d
_
e
m
b
e
d
i
n
g
B\times seq_len \times word\_embeding
B×seql?en×word_embeding
再处理数据时要做填充操作。
H
t
=
?
(
X
t
W
x
h
+
H
t
?
1
W
h
h
+
b
h
)
.
\mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h).
Ht?=?(Xt?Wxh?+Ht?1?Whh?+bh?).
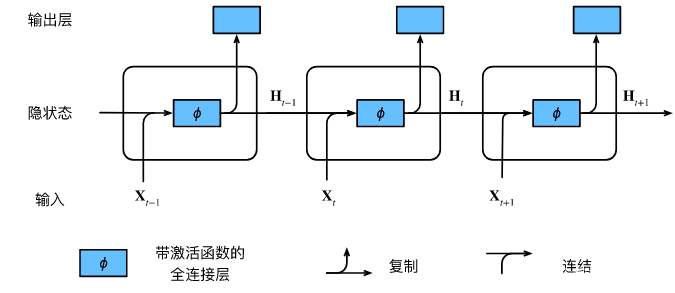
门控卷积网络单元GRU
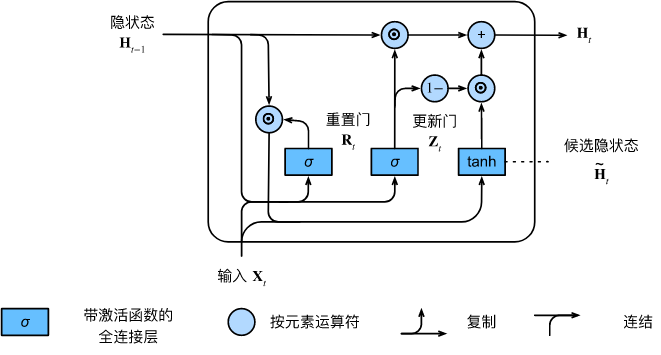
长短期记忆网络 LSTM
Long short-term memory
注意英语
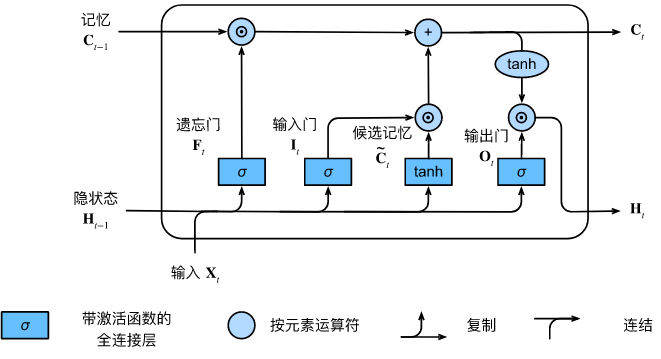
现在说循环神经网络一般默认是LSTM
代码演示
13 序列到序列seq to seq
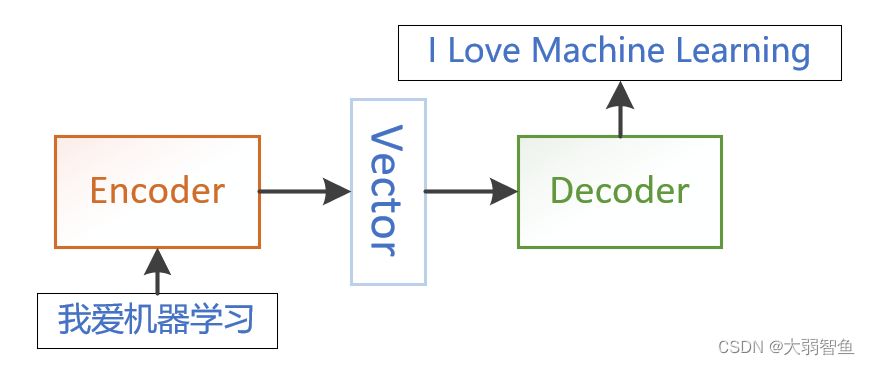
是一种多对多的模型,可以被建模到很多领域。
14 Attention Is All You Need
https://jalammar.github.io/illustrated-transformer/
广义的transformer是以注意力机制为主的各种网络,狭义的transformer就是有编码器、解码器的结构的网络。
15 ViT视觉transformer
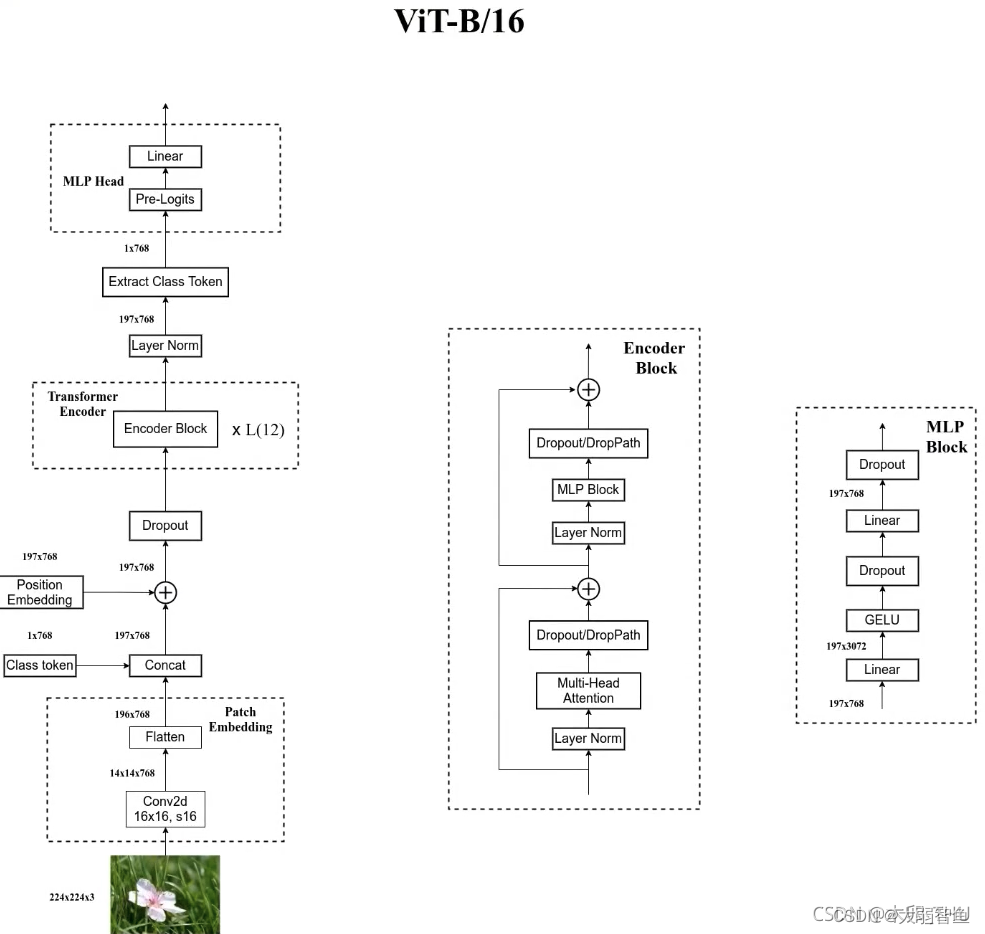
transformer在越来越多的图像任务中也开始起作用。

