Masked Autoencoders for Point Cloud Self-supervised Learning
ժҪ
- ���: NLP��CV�е�Masked AutoencoderӦ�úܳɹ�
- ����: �����д��ھֲ���Ϣȱʧ���ܶȲ����ȵ�����
- ����: ʹ��Masked Autoencoder���е����Լලѧϰ
- ϸ��:
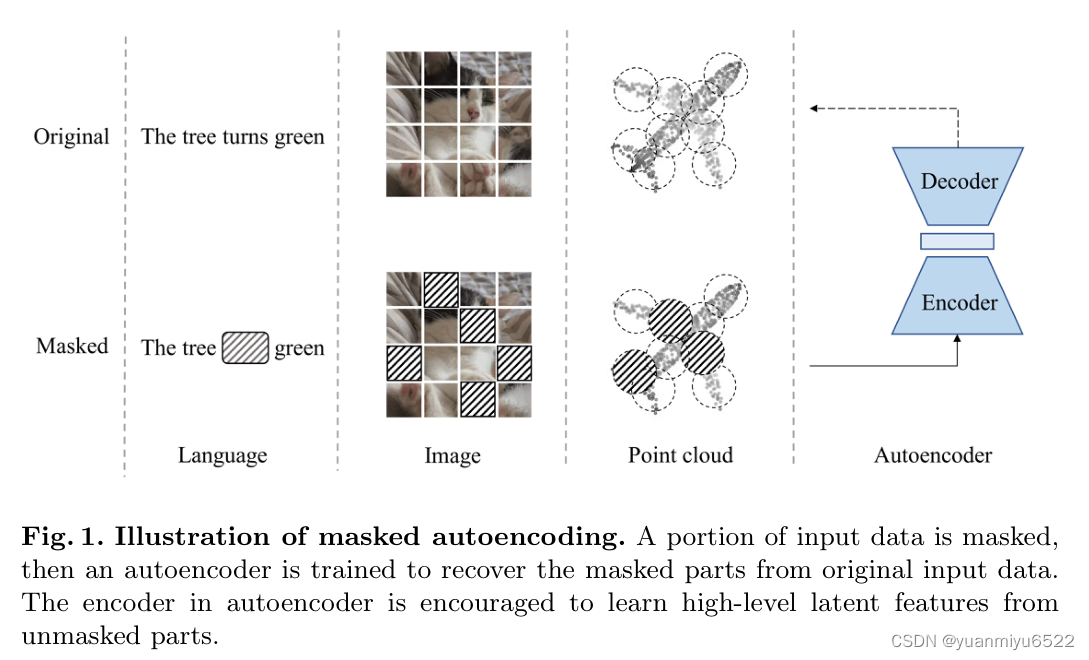
�ٽ�����ĵ��ƻ��ֳɲ�����ĵ��ƿ�,�Խϸߵı��� mask ��Щ��
��ʹ�û���autoencoder�ı�transformer����Щδ��mask�Ŀ���ѧϰ��ά����,�Ӷ��ؽ���mask�ĵ��ƿ顣���и�transformer���жԳ���ƺ�shifting mask tokens���� - ����: https://github.com/Pang-Yatian/Point-MAE
1.����
- NLP ����> BERT
- CV ����> MAE
- Point cloud ����> Point-MAE
- ���ǵ����Ƶ����ݼ���Խ�С,ʹ��masked autodecoder��Ϊ�Լලѧϰ�������Խ��transformer��Ҫѵ��������������⡣
- Ŀǰ���������ڵļ�������:
��ȱ��һ��ͨ�õ�Transformer�ܹ�
������mask tokens��λ��embedding����ȱʧ�ֲ���Ϣ
�۵��ƾ����ܶȲ����ȵ�����
Point-MAE��Ҫ������һ��point cloud masking��embedding module��an autoencoder ,��Ҫ��������Ϊ:
- ������Ʊ�����Ϊ������ĵ��ƿ�,��Щ���ƿ��Խϸߵı�����mask
- Autoencoder��unmask������ѧϰ��ά��ʽ����,����������ռ����ؽ���mask�ĵ��ƿ�
- Autoencoder������������Ҫ����Transformer blocksΪ����,�����öԳ�ʽ��encoder-decoder�ṹ
- encoderֻ����unmasked���ƿ�
- ����decoder���������encoded tokens �� mask tokens
- shifting mask tokens��������decoder���Ժ���Ҫ,�ȿ��Խ�ʡ������,�ֿ��Ա���λ����Ϣй¶,���ܹ���߾�ȷ��

3. Point-MAE
3.1 Point Cloud Masking and Embedding
Point Patches Generation
ͨ��Farthest Point Sampling(FPS) �� K-Nearest Neighborhood (KNN) �㷨�����ƻ���Ϊ������ĵ��ƿ顣����һ�����
p
p
p����ĵ���
X
i
��
R
p
��
3
X^{i} \in \mathbb{R}^{p \times 3}
Xi��Rp��3,����FPS������
n
n
n����,��Ϊ�������ĵ�
C
T
CT
CT���������ĵ�,����ÿ�����
P
P
P,KNNѡ��
k
k
k������ڵ�:
C
T
=
F
P
S
(
X
i
)
,
C
T
��
R
n
��
3
P
=
K
N
N
(
X
i
,
C
T
)
,
P
��
R
n
��
k
��
3
\begin{aligned} C T=F P S\left(X^{i}\right), & C T \in \mathbb{R}^{n \times 3} \\ P=K N N\left(X^{i}, C T\right), & P \in \mathbb{R}^{n \times k \times 3} \end{aligned}
CT=FPS(Xi),P=KNN(Xi,CT),?CT��Rn��3P��Rn��k��3?
ÿ��������궼ͨ�������ĵ���й�һ��,����������
Masking
���ǵ����ƿ���ܻ��ص�,�ֱ����Щ�����mask����mask��������Ϊ m m m,masked�鱻��ʾΪ P g t �� R m n �� k �� 3 P_{g t} \in \mathbb{R}^{m n \times k \times 3} Pgt?��Rmn��k��3,ʵ�����, m = 60 % ? 80 % m=60\%-80\% m=60%?80%ʱ,���ǹ��������ܸ��á�
Embedding
��������mask tokensΪ T m �� R m n �� C T_{m} \in \mathbb{R}^{m n \times C} Tm?��Rmn��C ,���� C C CΪembedding��ά�ȡ�
����unmasked point patches,���������͵�PointNet����embedding��unmasked point patches P v �� R ( 1 ? m ) n �� k �� 3 P_{v} \in \mathbb{R}^{(1-m) n \times k \times 3} Pv?��R(1?m)n��k��3��embedding�� visible tokens�Ĺ��̿�������ʽ��ʾ:
T v = Point ? N e t ( P v ) , T v �� R ( 1 ? m ) n �� C . T_{v}=\operatorname{Point} N e t\left(P_{v}\right), \quad T_{v} \in \mathbb{R}^{(1-m) n \times C} . Tv?=PointNet(Pv?),Tv?��R(1?m)n��C.
���ǵ����ƿ���ͨ����һ�������ʾ��,����embedding token����,�ṩ���ĵ��λ����Ϣ�DZ�Ҫ�ġ�Position Embedding (PE)��һ���ķ�������ͨ��һ����ѧϰ��MLP�����ĵ������embedding������һ��ά���ϡ�������encoder��decoder���ֱ�ʹ����PE��
3.2 Autoencoder��s Backbone
Autoencoder��Backbone����ȫ���ڱ���Transformer��,������һ���Գ�ʽ��encoder-decoder��ơ�Autoencoder�����һ�������һ����Ԥ��ͷ������ؽ�Ŀ�ꡣ
Encoder-decoder
�����е�encoder�����ű���Transformer blocks,����visible tokens T v T_v Tv?���б���,encoded tokens����Ϊ T e T_e Te?������,ÿ��Transformer block�ж������positional embeddings,�ṩλ����Ϣ��
�����е�decoder��encoder����,���ǰ����Ÿ��ٵ�Transformer blocks,���������encoded tokens
T
e
T_e
Te?��masks tokens
T
m
T_m
Tm?,��decoder��ÿ��Transformer block��Ҳ����positional embeddings,Ϊÿ��tokens�ṩλ����Ϣ��decoder�����Ϊdecoded mask tokens
H
m
H_m
Hm?,����
H
m
H_m
Hm?���뵽��������Ԥ��ͷ��,encoder-decoder�Ľṹ���Ա�ʾΪ:
T
e
=
Encoder
?
(
T
v
)
,
T
e
��
R
(
1
?
m
)
n
��
C
H
m
=
Decoder
?
(
concat
?
(
T
e
,
T
m
)
)
,
H
m
��
R
m
n
��
C
\begin{gathered} T_{e}=\operatorname{Encoder}\left(T_{v}\right), \quad T_{e} \in \mathbb{R}^{(1-m) n \times C} \\ H_{m}=\operatorname{Decoder}\left(\operatorname{concat}\left(T_{e}, T_{m}\right)\right), \quad H_{m} \in \mathbb{R}^{m n \times C} \end{gathered}
Te?=Encoder(Tv?),Te?��R(1?m)n��CHm?=Decoder(concat(Te?,Tm?)),Hm?��Rmn��C?
��encoder-decoder�ṹ��,��mask tokens��������decoder��,�����ǽ�encoder���������decoder��,����������Ŀ��ǵ�:
- ��������mask�ı��ʱȽϴ�,��mask tokensת�Ƶ�decoder���ܹ�����ؼ�������tokens������
- ��mask tokensת�Ƶ�decoder�п��Թ���ر���й¶λ����Ϣ,ʹencoder�ܹ����õ�ѧϰDZ��������
Prediction Head
��ʹ��һ��ȫ������ΪԤ��ͷ,��decoder�õ����
H
m
H_{m}
Hm?,prediction head�Ὣ��ͶӰΪһ������,���������ά�Ⱥ͵��ƿ������ȫ��������ͬ��Ȼ���ٸ�һ��reshape����:
P
p
r
e
=
?Reshape?
(
F
C
(
H
m
)
)
,
P
p
r
e
��
R
m
n
��
k
��
3
P_{p r e}=\text { Reshape }\left(F C\left(H_{m}\right)\right), \quad P_{p r e} \in \mathbb{R}^{m n \times k \times 3}
Ppre?=?Reshape?(FC(Hm?)),Ppre?��Rmn��k��3
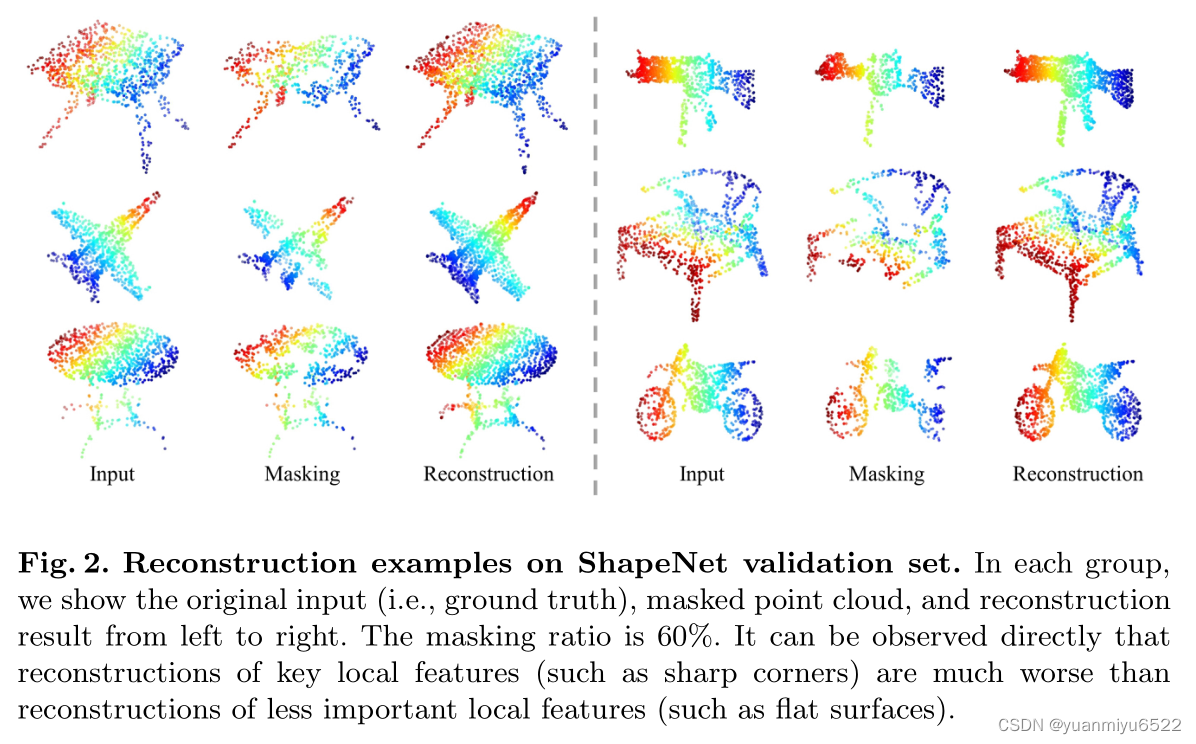
3.3 Reconstruction Target
���ĵ��ؽ�Ŀ���ǻָ�ÿ����mask���ƿ��е�����ꡣ����Ԥ��ĵ��ƿ�
P
pre?
P_{\text {pre }}
Ppre??��ground truth
P
g
t
P_{g t}
Pgt?,ͨ��
l
2
l_2
l2?��Chamfer Distance �����ؽ���ʧ:
L
=
1
�O
P
p
r
e
�O
��
a
��
P
p
r
e
min
?
b
��
P
g
t
��
a
?
b
��
2
2
+
1
�O
P
g
t
�O
��
b
��
P
g
t
min
?
a
��
P
p
r
e
��
a
?
b
��
2
2
L=\frac{1}{\left|P_{p r e}\right|} \sum_{a \in P_{p r e}} \min _{b \in P_{g t}}\|a-b\|_{2}^{2}+\frac{1}{\left|P_{g t}\right|} \sum_{b \in P_{g t}} \min _{a \in P_{p r e}}\|a-b\|_{2}^{2}
L=�OPpre?�O1?a��Ppre?��?b��Pgt?min?��a?b��22?+�OPgt?�O1?b��Pgt?��?a��Ppre?min?��a?b��22?
4.ʵ��
- ��ShapeNetѵ�����϶�ģ�ͽ���Ԥѵ��
- �ڲ�ͬ����������������Ԥѵ��ģ��,����object classification, few-shot learning �� part segmentation
- ablation study
���������� p = 1024 p=1024 p=1024,����Ϊ n = 64 n=64 n=64�����ƿ�,��KNN�㷨��, k = 32 k=32 k=32,��autoencoder��,encoder�а�����12��Transformer block,decoder�а�����4��Transformer block,ÿ��Transformer block��384������ά�Ⱥ�6��ͷ��Transformer block�е�MLP��������Ϊ4��
4.1 Pre-training Setup
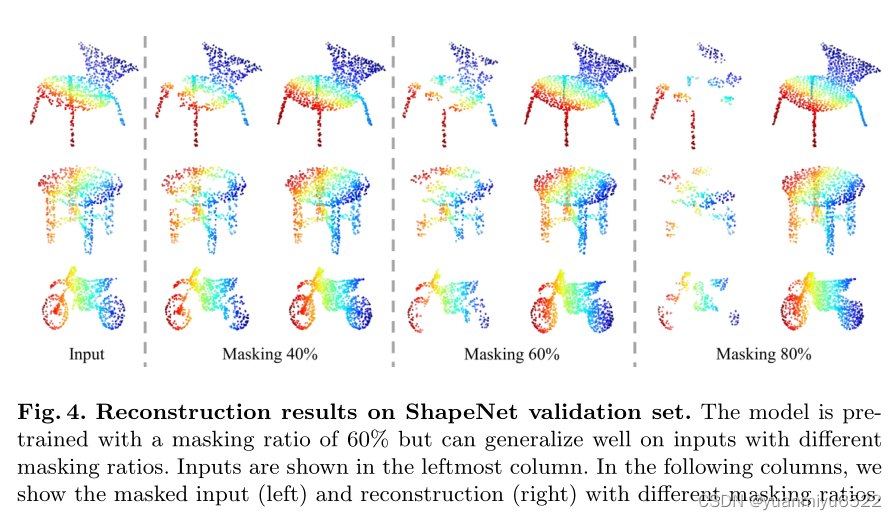
4.2 Downstream Tasks
Object Classification on Real-World Dataset
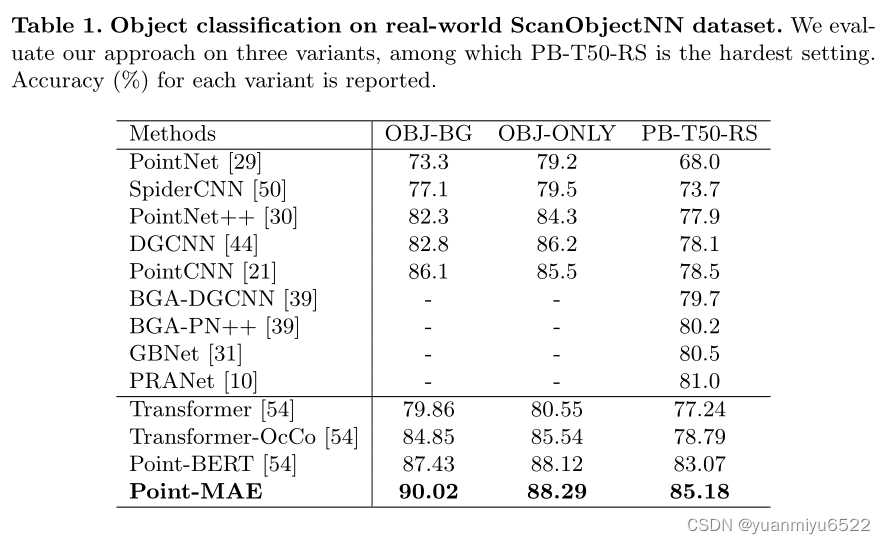
Object Classification on clean objects dataset
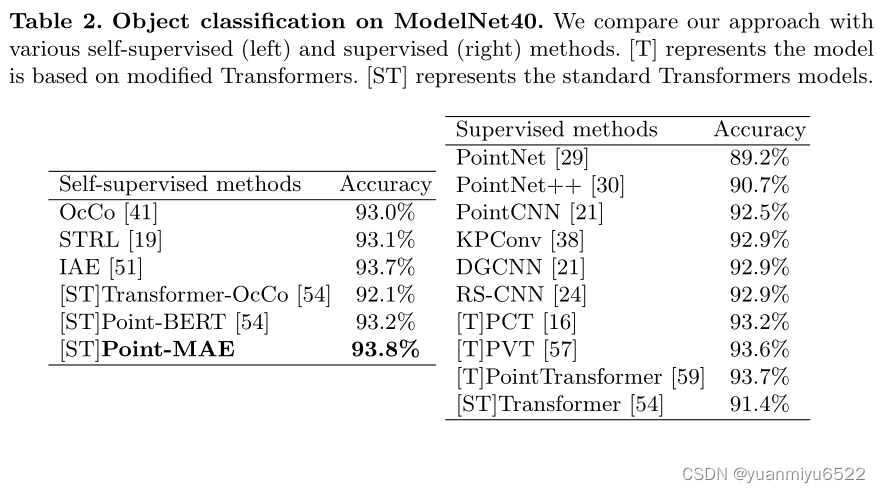
Few-shot Learning
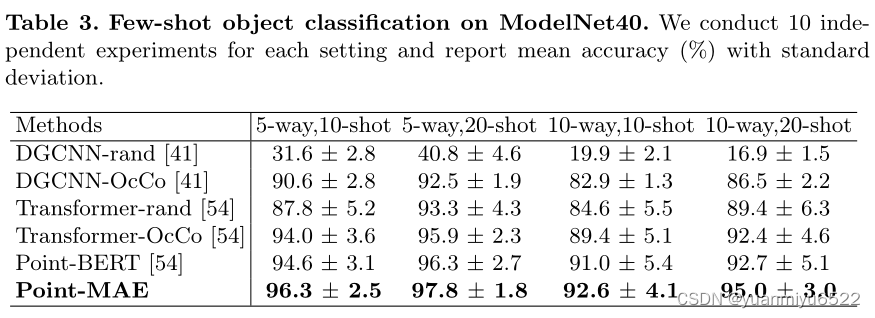
Part Segmentation
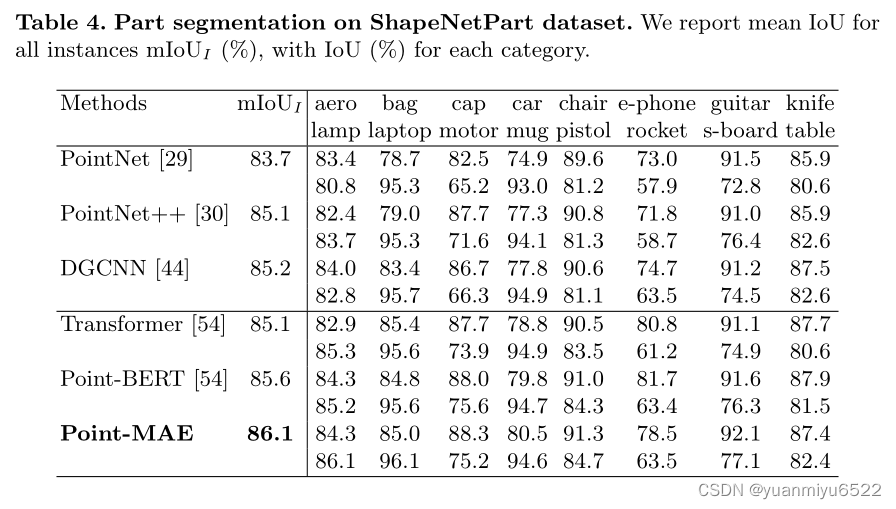
4.3 Ablation Study
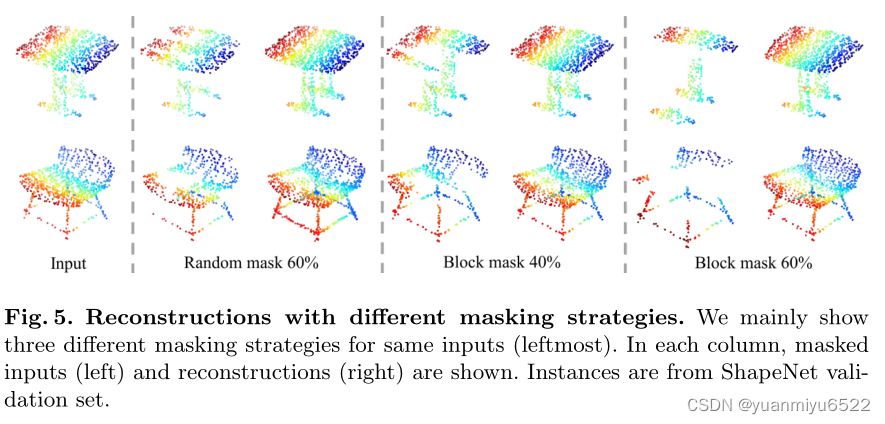
Masking Strategy
- block masking�����Կ�Ϊ��λ����mask
- random masking�������mask��