最近看到一篇挂arxiv的论文Vision Transformer Adapter for Dense
Predictions,应该是准备发ECCV 22,看了之后简单梳理一下。
1 摘要
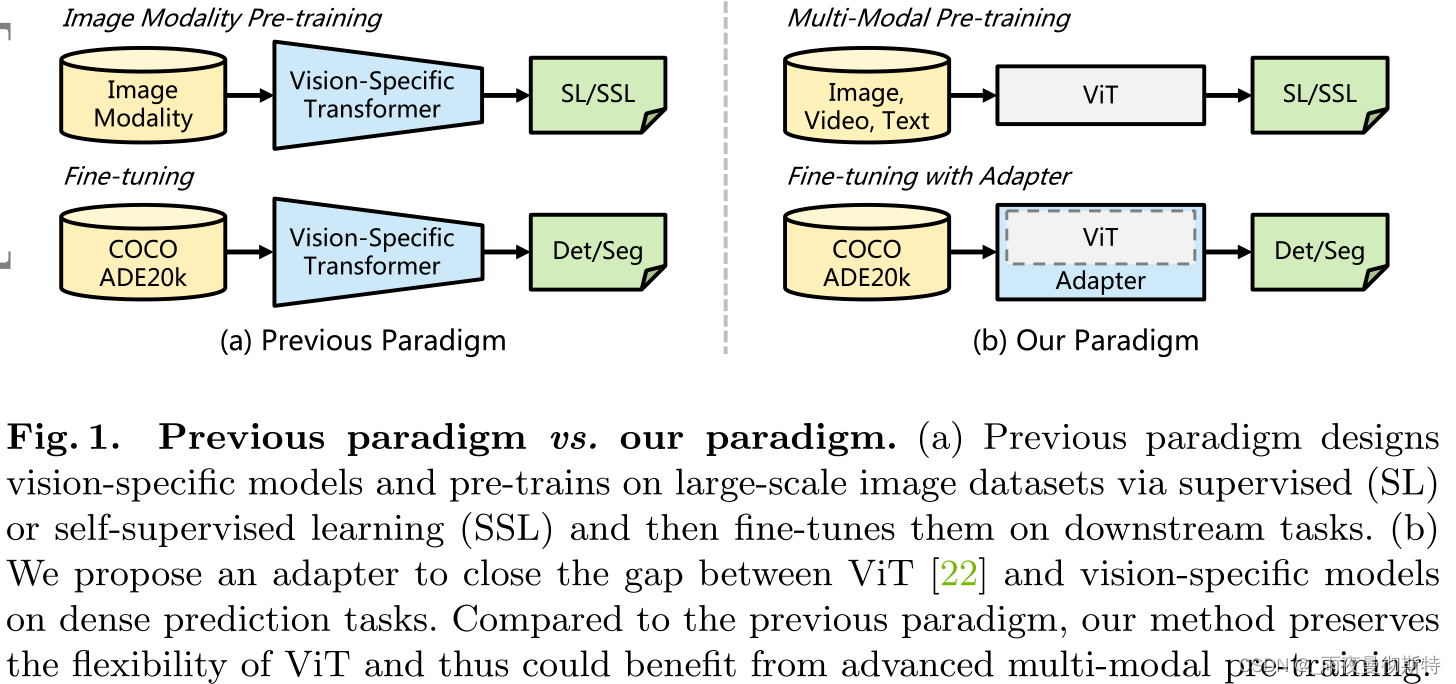
这项工作设计了一个简单而强大的Vision Transformer Adapter,它通过两步弥补了ViT的一些问题,(1)引入ViT缺乏的图像先验信息;(2)通过额外的结构引入归纳偏置来实现与视觉特定模型相当的性能。他们在包括目标检测、实例分割、语义分割等多个子任务上进行了实验,分别获得了COCO目标检测Rank#8,COCO实例检测Rank#4,ADE20K、Cityscapes、COCO-Stuff、PASCAL VOC四个数据集上语义分割的SOTA。(这里第一张图还引入了多模态的概念,鄙人才疏学浅,目前没看懂这篇文章和多模态有什么关系)
2 动机
原始的Transformer没有针对视觉任务设计特定的模块,这使得原始的Transformer相较于专用Transformer没有竞争力。这里的Adapter就是基于这种想法设计一个专用的视觉Transformer(Adapter起源于NLP领域)。具体而言,这篇文章设计了三个模块:(1)一个空间先验模块,用于捕捉空间局部语义(引入CNN,具体是ResNet);(2)一个空间特征注入器(多头注意力);(3)多尺度特征提取器(多头注意力接CFFN)
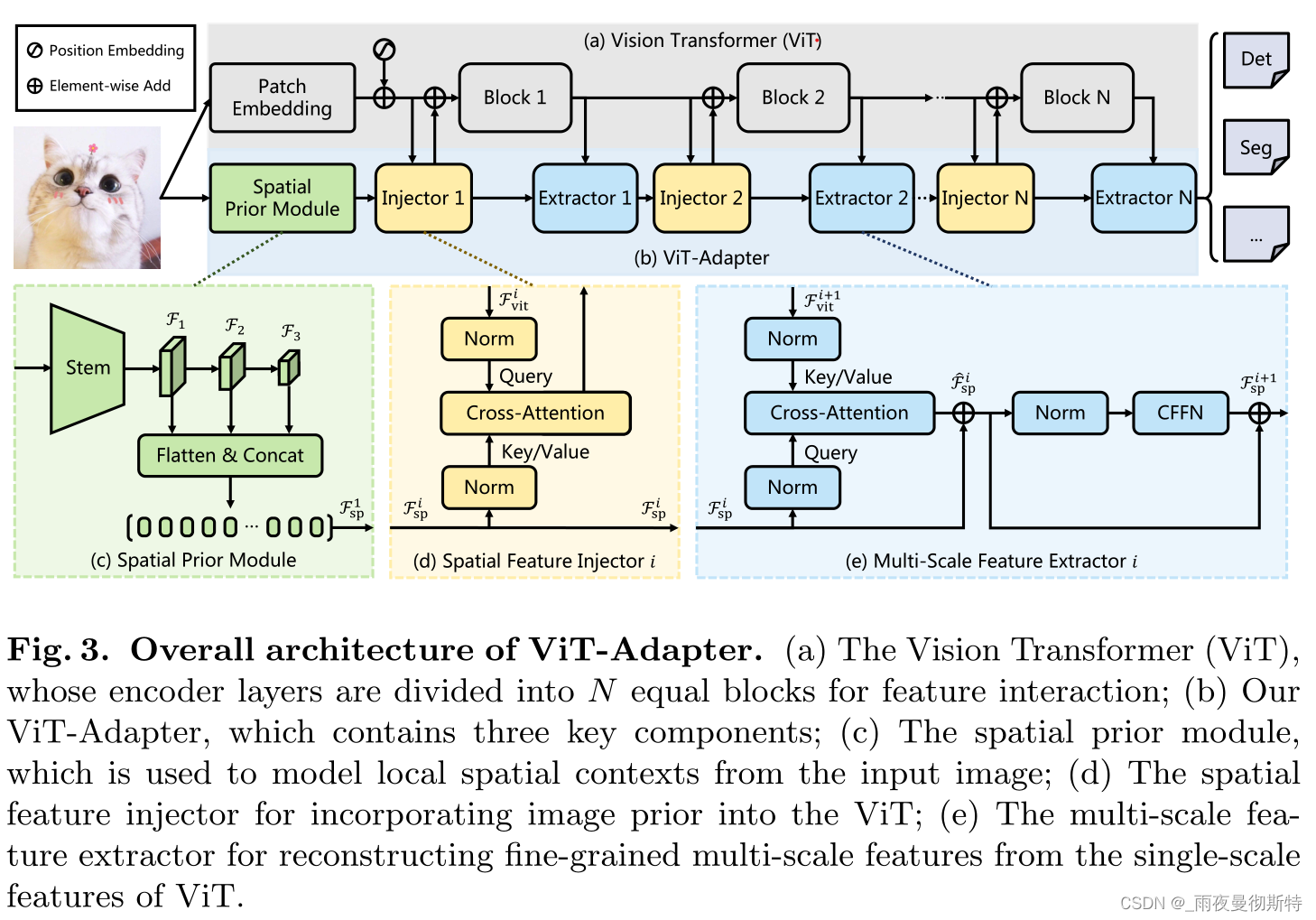
3 方法
3.1 整体框架
对于ViT,输入图像首先被送入补丁嵌入,图像被分成16×16个不重叠的补丁。之后,这些斑块被压扁并投射到D维嵌入中。这里的特征分辨率被降低到原始图像的1/16。最后,嵌入的斑块与位置嵌入一起,通过ViT的L个编码器层。对于ViT-Adapter,首先将输入图像送入空间先验模块。三个目标分辨率(即1/8、1/16和1/32)的D维空间特征将被收集。然后,这些特征图被扁平化并串联起来作为特征交互的输入。具体来说,给定交互次数N,把ViT的变换器编码器平均分成N个块,每个块包含L/N个编码器层。对于第i个块,我们首先通过空间特征注入器向该块注入空间先验因子 F s p i F^i_{sp} Fspi?,然后通过多尺度特征提取器从该块的输出中提取层次特征。经过N次特征交互,得到了高质量的多尺度特征,然后将这些特征分割并重塑为1/8、1/16和1/32三个目标分辨率。最后,我们通过2×2转置卷积对1/8尺度的特征图进行上采样,建立1/4尺度的特征图。通过这种方式,得到了一个与ResNet相似分辨率的特征金字塔,它可以用于各种密集预测任务。
3.2 空间先验模块
这里简而言之就是加入一个ResNet,将提取的特征用作图像先验知识。见图3c。
3.3 特征交互
由于柱状结构,ViT中的特征图是单尺度和低分辨率的,与金字塔结构的变换器相比,导致在密集预测任务中的次优表现[14,21,52,74,75]。为了缓解这个问题,文章提出了两个特征交互模块,在Adapter和ViT之间交流特征图。具体来说,这两个模块是基于交叉注意力的,即空间特征注入器和多尺度特征提取器。如第3.1节所述,我们将ViT的变换器编码器分成N个相等的块,并在每个块之前和之后分别应用提议的两个运算器。
3.3.1 特征提取器
如图框架图d所示,该模块用于向ViT注入空间先验。具体来说,对于转化器的第i块,将输入特征
F
v
i
t
i
F^i_{vit}
Fviti?作为查询,将空间特征
F
s
p
i
F^i_{sp}
Fspi?作为键和值。这里使用多头交叉注意力将空间特征
F
s
p
i
F^i_{sp}
Fspi?注入到输入特征
F
v
i
t
i
F^i_{vit}
Fviti?中,可以表述为公式1
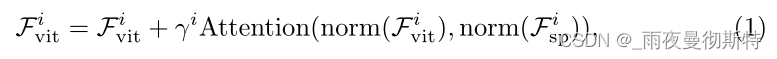
其中,归一化层norm(・)是LayerNorm,而注意层Attention(・)是备选。为了降低计算成本,这里根据经验采用了可变形注意力[85],一种具有线性复杂性的稀疏注意力,来实现注意力层。此外,这里应用一个可学习的向量γi∈RD来平衡注意力层的输出和输入特征
F
v
i
t
i
F^i_{vit}
Fviti?,其初始化为0。这种初始化策略保证了
F
v
i
t
i
F^i_{vit}
Fviti?的特征分布不会因为空间先验的注入而被大幅修改,从而更好地利用了ViT的预训练权重。
3.3.2 多尺度特征提取器
在向ViT注入空间先验后,这里通过将
F
v
i
t
i
F^i_{vit}
Fviti?通过第i块的编码器层,得到输出特征
F
v
i
t
i
+
1
F^{i+1}_{vit}
Fviti+1?。之后,将ViT的特征和空间特征的角色互换。换句话说,这里采用空间特征
F
i
s
p
i
F^i_{isp}
Fispi?作为查询,而输出特征
F
v
i
t
i
+
1
F^{i+1}_{vit}
Fviti+1?作为键和值。这里再一次通过交叉注意力来交互这两个特征,其定义为:
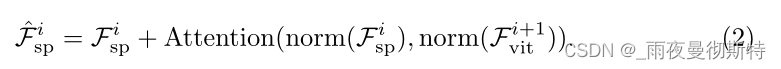
与空间特征注入器一样,在这里使用可变形注意力[85]来减少计算成本。此外,为了弥补固定大小的位置嵌入的缺陷,这里遵循[15,75]在交叉注意层之后引入卷积前馈网络(CFFN)。考虑到效率问题,这里参考文献[56],将CFFN的比例设置为1/4。CFFN层通过深度卷积[13]与零填充来增强特征的局部连续性,可以表示为
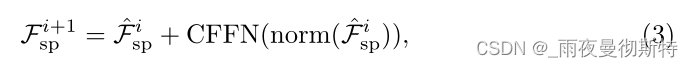
其中,新的空间特征
F
s
p
i
+
1
F^{i+1}_{sp}
Fspi+1?将被用作下一模块中特征交互的输入。
3.4 实验配置
这里为ViT[22]的4个不同变体建立了ViT-Adapter,包括ViTT、ViT-S、ViT-B和ViT-L。对于这些模型,Adapter的参数数分别为2.5M、5.8M、14.0M和23.7M。每种配置的细节都在表1中列出。在实验中,ViT的补丁大小被固定为16。交互次数N被设定为4,这意味着将ViT的编码器层分成4个相等的块进行特征交互。在两个特征交互操作中采用了可变形注意力[85],其中采样点的数量固定为4,注意力头的数量设置为6、6、12和16。在最后一个交互中,三个多尺度特征提取器被堆叠在一起。此外,CFFN的比例设置为1/4,以减少计算开销,即对于4个不同的ViT变体,CFFN的隐藏大小为48、96、192和256。
4 对比实验
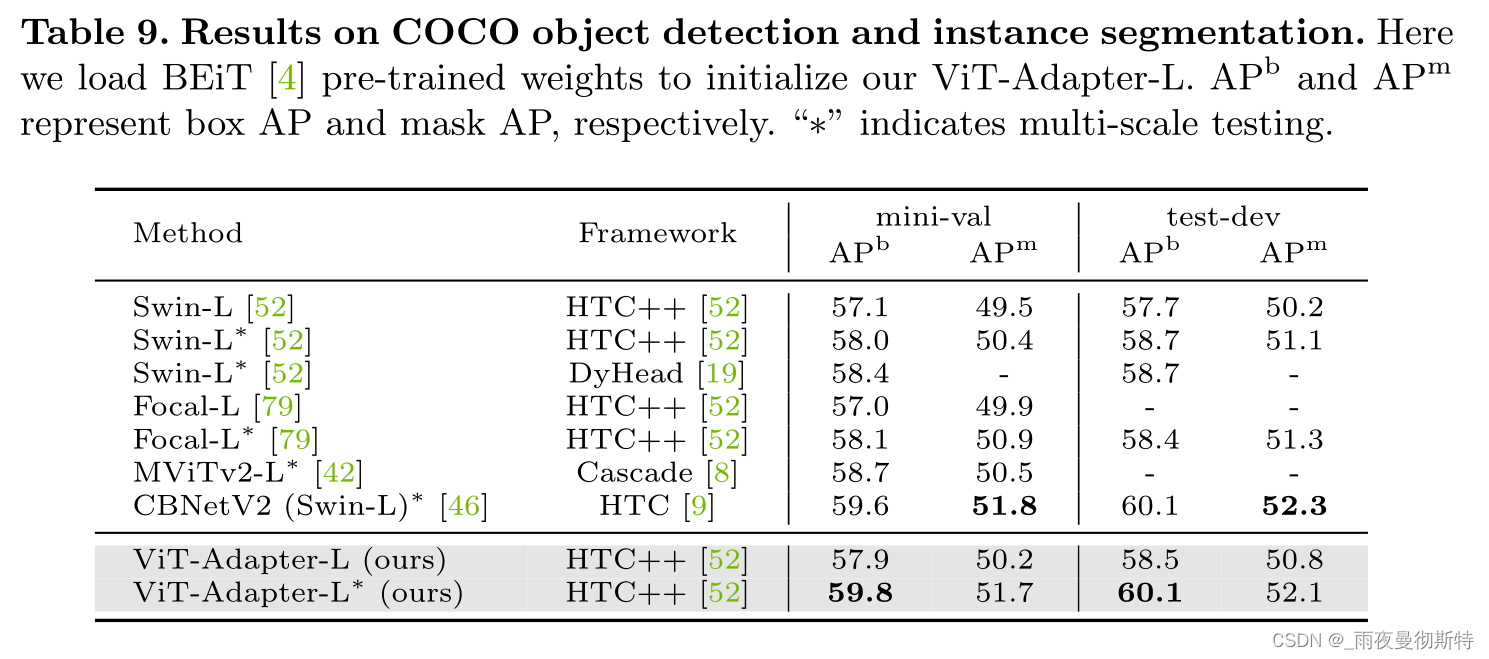
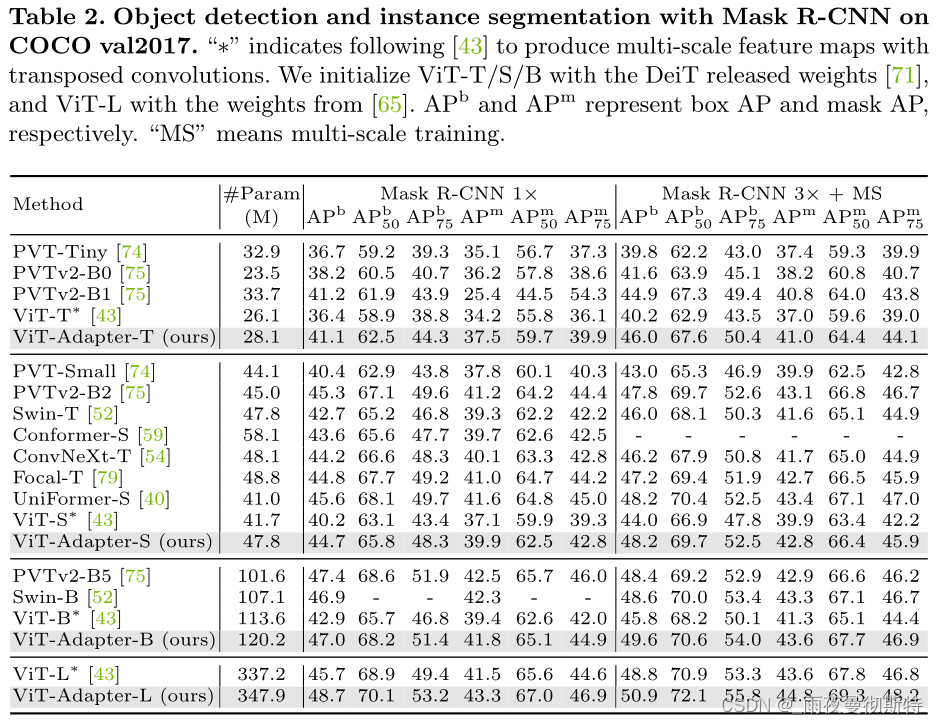
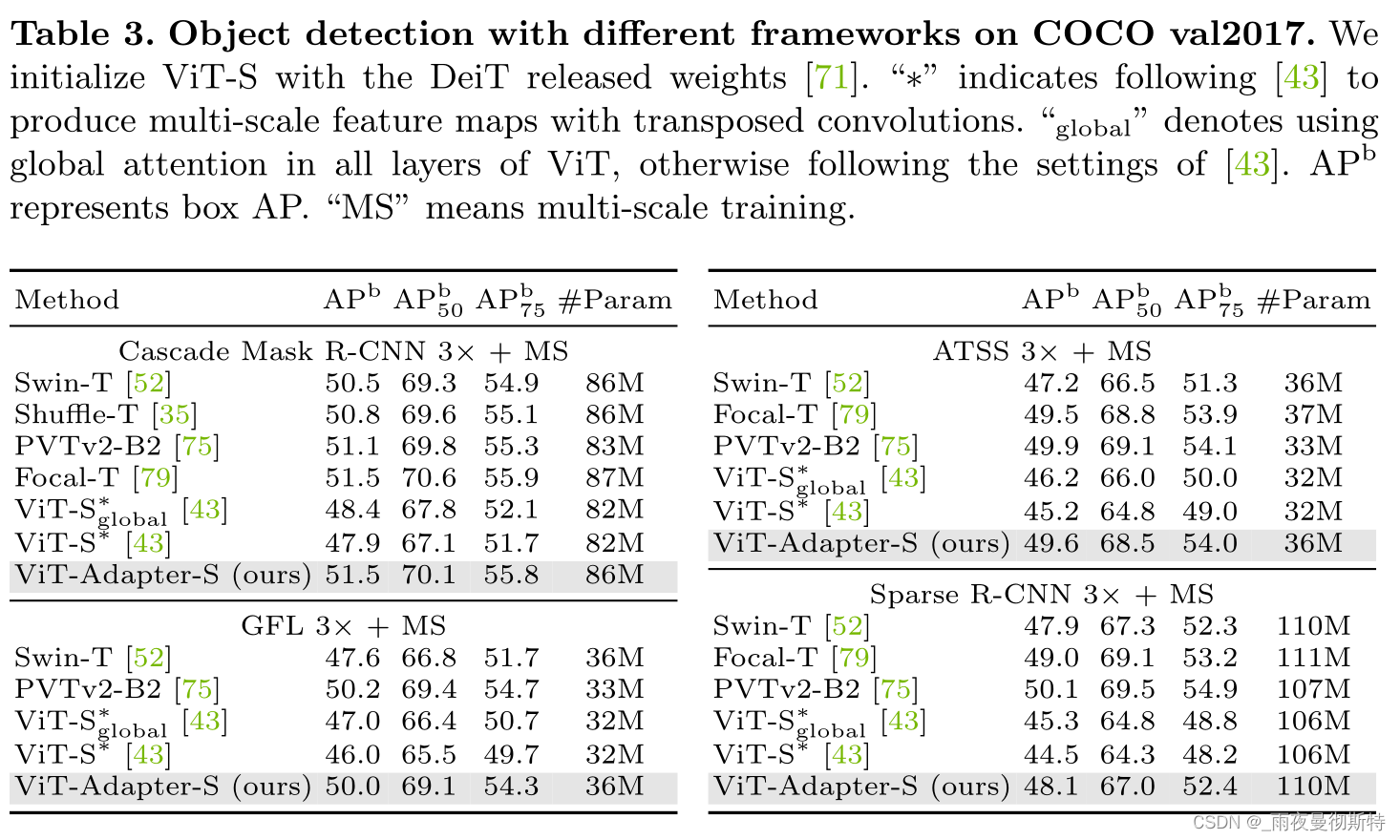
他们在包括目标检测、实例分割、语义分割等多个子任务上进行了实验,分别获得了COCO目标检测Rank#8,COCO实例检测Rank#4,ADE20K、Cityscapes、COCO-Stuff、PASCAL VOC四个数据集上语义分割的SOTA。
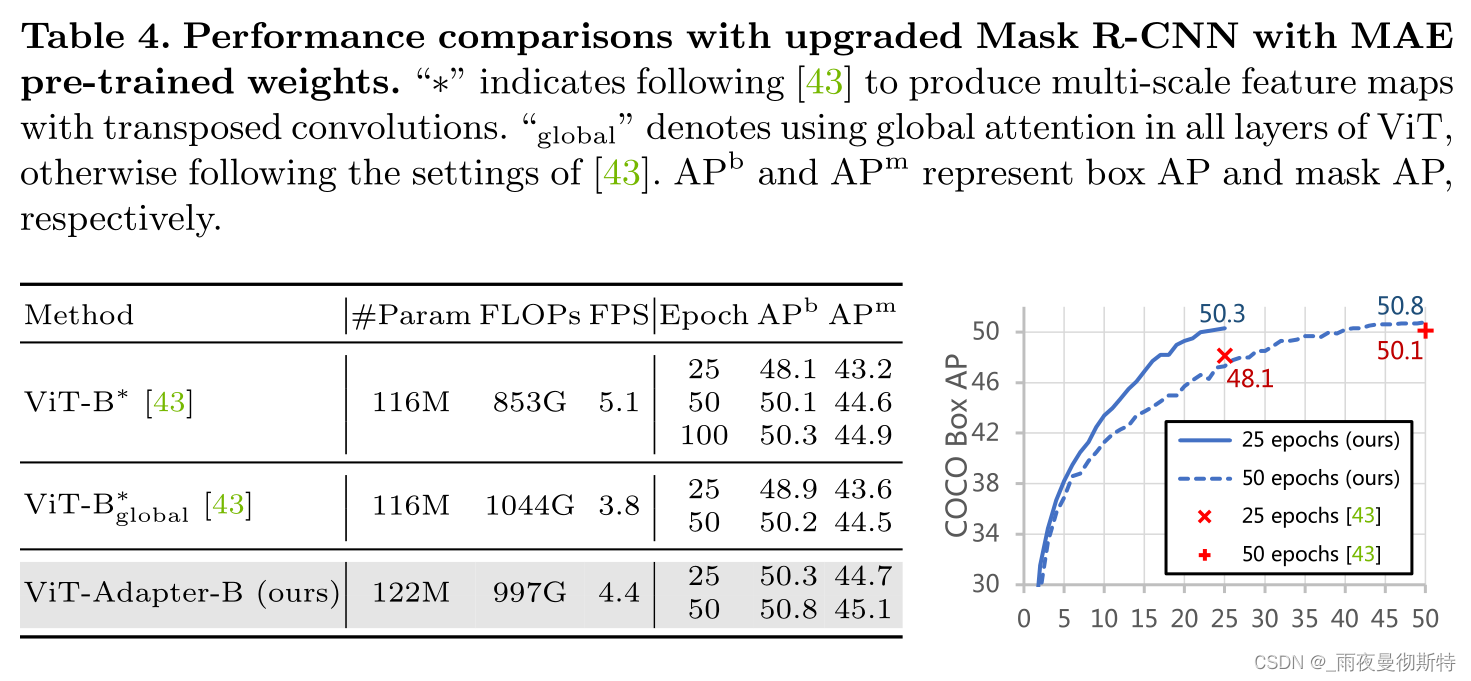
下图与MAE做对比表明收敛速度更快且效果几乎持平
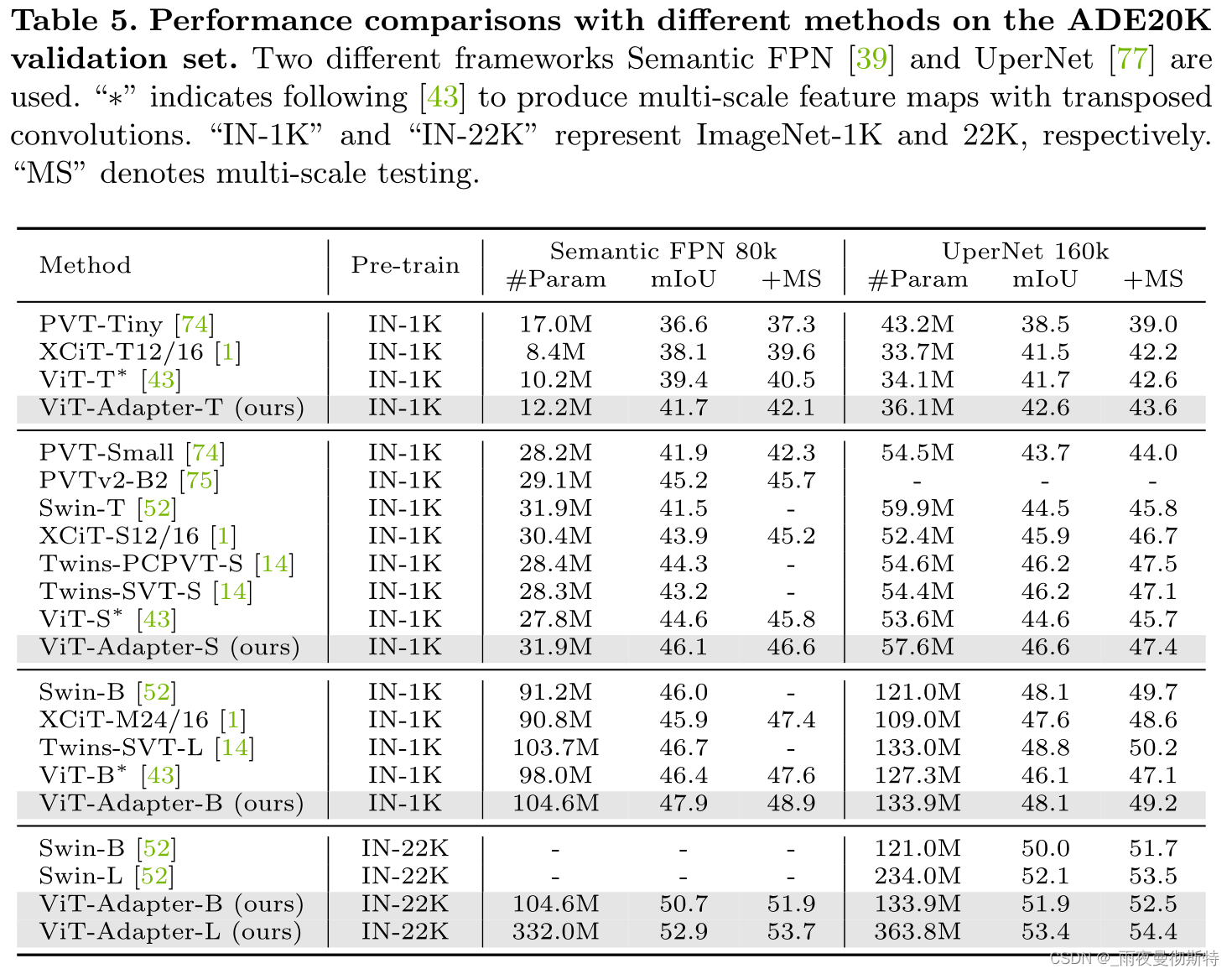
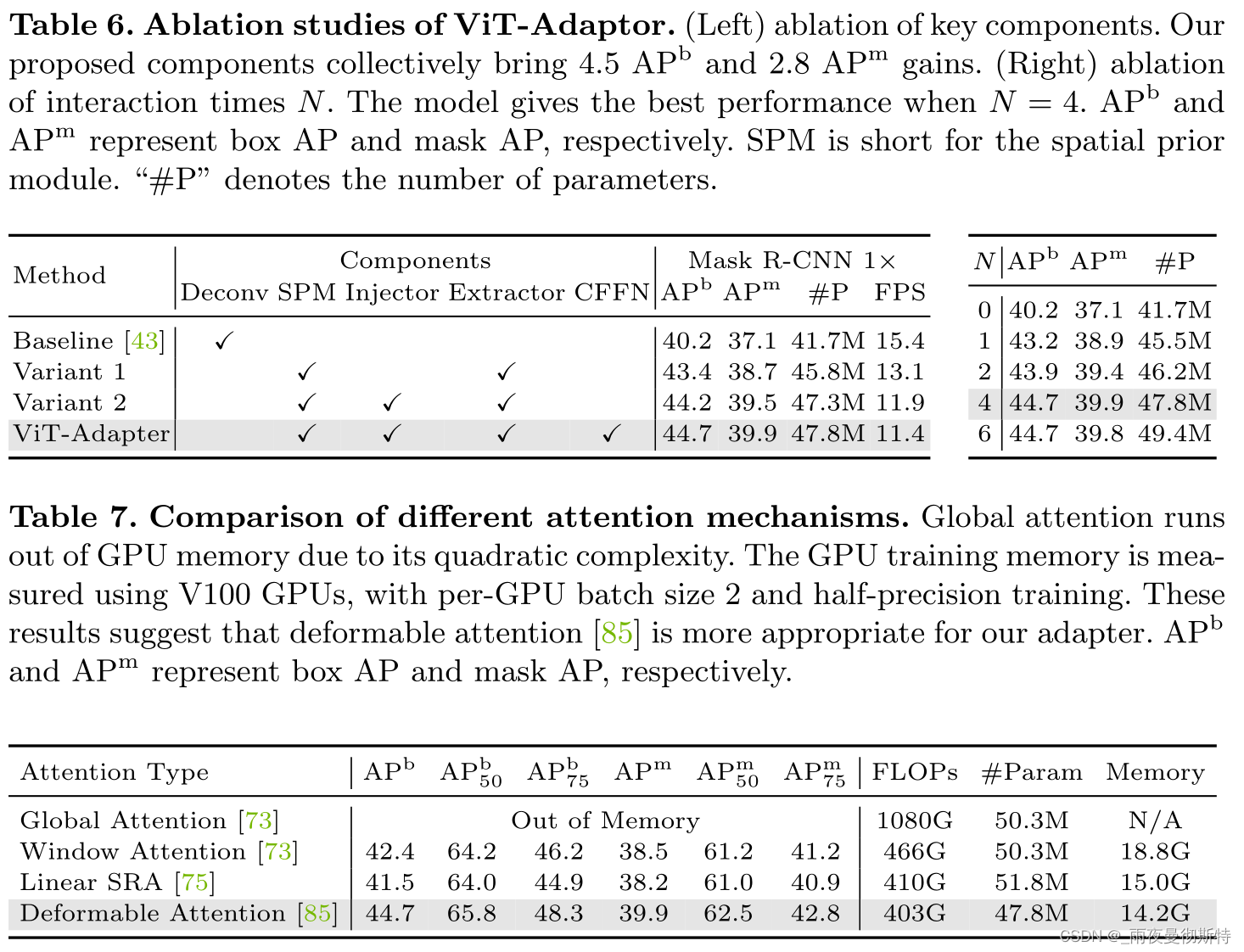
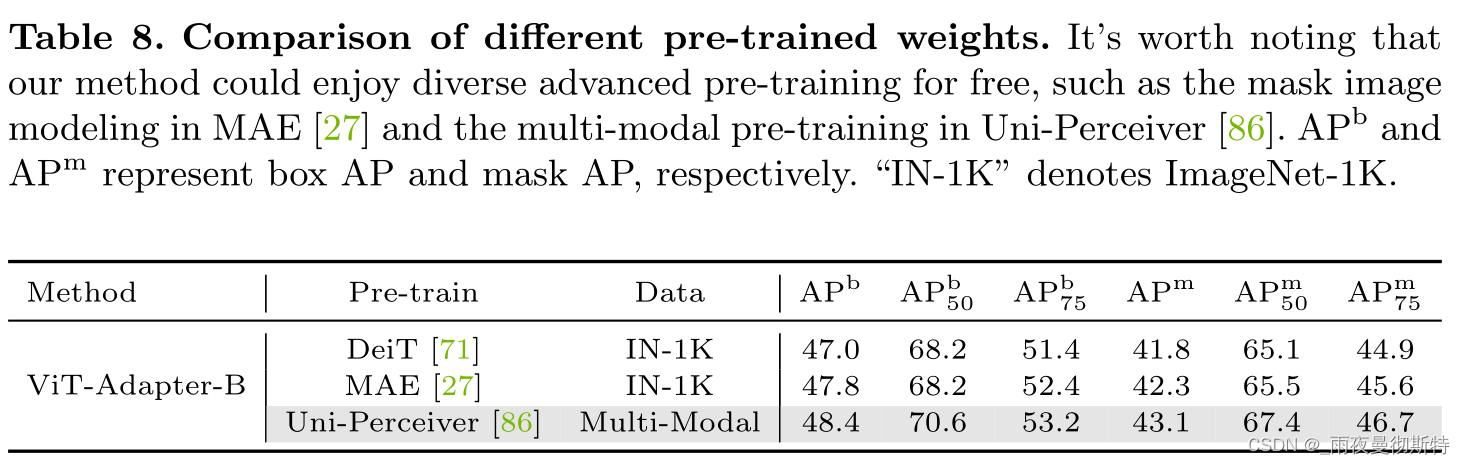
5 消融实验
这里针对超参数、不同注意力机制、不同预训练权重、不同框架进行消融,结果如下。