����Ŀ¼
- ǰ��
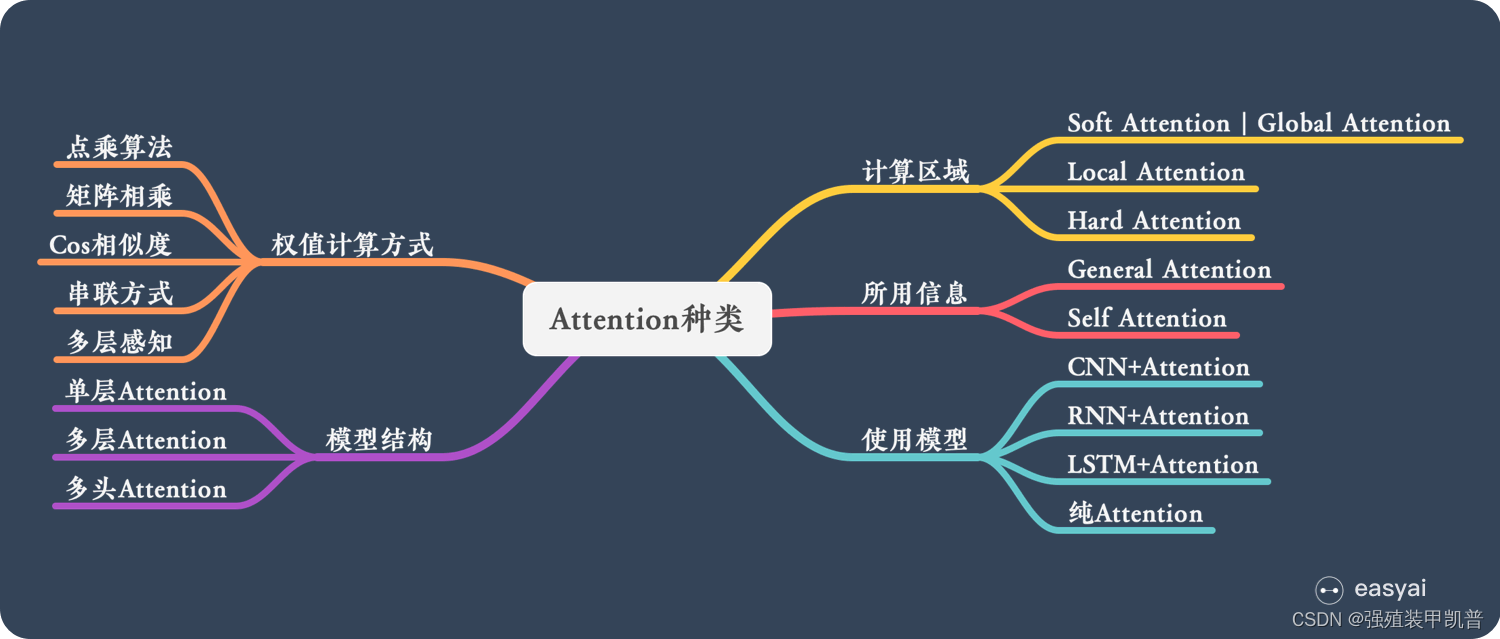
- attention����
- ��ģ�۲�
- [2015.12.5] Deep Attention Recurrent Q-Network
- [ICML2016] Control of Memory, Active Perception, and Action in Minecraft
- [ICLR 2019] Relational Deep Reinforcement Learning
- [NIPS2018] Relational recurrent neural networks
- [GECCO2020] Neuroevolution of Self-Interpretable Agents
- [AAAI2017] Multi-focus Attention Network for Efficient Deep Reinforcement Learning
- ��ģ��ϵ
- [ICML2019] Actor-Attention-Critic for Multi-Agent Reinforcement Learning
- [AAAI2020] Multi-Agent Game Abstraction via Graph Attention Neural Network
- [AAMAS2020] Learning Transferable Cooperative Behavior in Multi-Agent Teams
- [ICLR2020] Graph Convolutional Reinforcement Learning
- [2020.6.9] Qatten: A General Framework for Cooperative Multiagent Reinforcement Learning
ǰ��
�����µ���Ȥ���»����,Ҳ��ӭ�Ƽ���
attention����
attentionԴ��RNN,Ҳ����NLP����,�����ڸ��������кܴ��Ӧ��DZ��,����ʹ��self attention��Transformer�ڸ�������������Ϊ��ͨ��ģ����һ���֡�

��ͳSeq2Seqģ��ʹ�����һ���������״̬��Ϊ�������c,Ҳ���ǽ������ij�ʼ��״̬�����ڽ�����������,��һ���϶���SOS,����Ŀ���ֻ��
y
i
?
1
y_{i-1}
yi?1?,Ҳ������c��
y
i
?
1
y_{i-1}
yi?1?�����,������Ҫ��һ��������������任�õ����ʴ�С������,ֱ�����EOS��ﵽ��Ƚ���(��NLPרҵ,����ָ��)����Ȼdecoder���������������,������RNN��˵��ֻ�������״̬��
Ϊ�����ֲ�ͬ����Ե�ǰ�������Ҫ�̶�,����attention������ǿ���ֶȡ�������soft attentionΪ��:

������Ԥ��
y
i
y_{i}
yi?ʱ,��decoder����״̬
H
i
?
1
H_{i-1}
Hi?1?��encoder���������Ӧ����״̬
[
h
1
,
?
?
,
h
m
]
[h_1,\cdots,h_m]
[h1?,?,hm?]����,�õ�source�˵�j���ʶ�target�˵�i���ʵĶ������
��
i
j
\alpha_{ij}
��ij?,���Ǵ�ͳ���������еĸ���:
��
i
j
=
a
l
i
g
n
(
H
i
?
1
,
h
j
)
\alpha_{ij}=align(H_{i-1},h_j)
��ij?=align(Hi?1?,hj?)
���ǿ��Խ�������Ϊ�����,���Dz�ͬsource�˴ʶ�����target�˵�i���ʵ���Ҫ�ԡ�������Ѱַ����,���洢����<key, value>�洢,����һ��query,���Ǽ��㲻ͬkey����Ҫ�̶�,Ȼ��value��Ȩ��͵õ�query�����������������,��������
H
i
?
1
H_{i-1}
Hi?1?��Ϊquery,
[
h
1
,
?
?
,
h
m
]
[h_1,\cdots,h_m]
[h1?,?,hm?]��Ϊkey,���������:
e
i
j
=
a
(
H
i
?
1
,
h
j
)
e_{ij}=a(H_{i-1},h_j)
eij?=a(Hi?1?,hj?)
����Եļ��㷽ʽ�кܶ�,��������˵����Ȼ��ͨ��softmax�õ�����:
��
i
j
=
exp
?
(
e
i
j
)
��
k
=
1
m
exp
?
(
e
i
k
)
\alpha_{ij}=\frac{\exp(e_{ij})}{\sum_{k=1}^m \exp(e_{ik})}
��ij?=��k=1m?exp(eik?)exp(eij?)?
�����Ǽ�Ȩ��͵õ��µ��ı�����
c
i
c_i
ci?:
c
i
=
��
j
=
1
m
��
i
j
h
j
c_i=\sum_{j=1}^m \alpha_{ij}h_j
ci?=j=1��m?��ij?hj?
��������decoder��������,����ƴ�Ӻ�һ�����硣
��νhard attention���Dz���һ����,Ϊ��ʵ���ݶȵķ���,��Ҫ�������ؿ�������ķ���������ģ����ݶ�,Ӧ��Ҳ������gumble softmax��global softmax��ʹ�����е�
h
j
h_j
hj?,local softmax����Ԥ��һ��source�˶���λ��(aligned position)
p
i
p_i
pi?,Ȼ����ڴ�ѡ��һ������,���ڼ����ı�����
c
i
c_i
ci?��

����self attention�����ھ�������Ԫ��֮��Ĺ�ϵ,q��k��v����source�����Ա任:
s
o
f
t
m
a
x
(
Q
K
?
d
k
)
V
softmax(\frac{QK^{\top}}{\sqrt{d_k}})V
softmax(dk??QK??)V
���Կ�������ʹ�õ����������ԡ�
d
k
d_k
dk?��K��ά��,�����ݶ�ֵ�ȶ�,��ν��scale�������scaling factor
1
d
k
\frac{1}{\sqrt{d_k}}
dk??1?,�����ݶ���ʧ��

��ͷ���Ǻü���,���ƴ�ӹ����Բ㡣
Self Attention������ײ�������г�����������������,��Ϊ�����RNN����LSTM,��Ҫ���������м���,����Զ����������������,Ҫ��������ʱ�䲽�������Ϣ�ۻ����ܽ�������ϵ����,������ԽԶ,��Ч����Ŀ�����ԽС������Self Attention�ڼ�������л�ֱ�ӽ������������������ʵ���ϵͨ��һ�����㲽��ֱ����ϵ����,����Զ������������֮��ľ��뱻��������,��������Ч��������Щ������������,Self Attention�������Ӽ���IJ�����Ҳ��ֱ�Ӱ������á�����self attentionʧȥ�����е�˳����Ϣ��
������Ҫ˵��һ��Ȩֵ���㷽ʽ:

https://zhuanlan.zhihu.com/p/57501837
https://zhuanlan.zhihu.com/p/37601161
https://zhuanlan.zhihu.com/p/97961666
https://zhuanlan.zhihu.com/p/410776234
https://easyai.tech/ai-definition/attention/
��ģ�۲�
[2015.12.5] Deep Attention Recurrent Q-Network
��������:https://arxiv.org/abs/1512.01693

������soft attention��״̬
s
t
s_t
st?��һ���Ӿ�֡,���ڴ˲���D��
m
��
m
m\times m
m��m��feature map,����ת��Ϊһ������
{
v
t
1
,
?
?
,
v
t
L
}
\{v_t^1,\cdots,v_t^L\}
{vt1?,?,vtL?},��������ΪD,L=
m
��
m
m\times m
m��m����״̬
h
t
h_t
ht?��Ϊquery,�ҵ�������ʷ��Ϣ,�ڵ�ǰʱ�䲽Ӧ�ù�ע��Щ������attentionģ��g������ȫ��������,���㷽ʽΪ:

Z�DZ�������,����Ȩ���:

�Ӵ���ʵ������,Qֵ��
h
t
h_t
ht?����һ��ȫ��������õ��ġ�
soft attention�ڲ��ֳ���Ч���á�hard attention��L��������ֻ����һ��,Ч����Խϲ�,������ԡ�
[ICML2016] Control of Memory, Active Perception, and Action in Minecraft
��������:https://arxiv.org/abs/1605.09128

ͨ����������Թ۲���б任,��self attentionһ��,�õ�k��v����ʱ����attention��seq2seq�Ľ�����һ��,��״̬��Ϊquery,��Ѱַ��

Memory Q-Network (MQN)ֱ��ʹ�õ�ǰ�Ĺ۲���Ϊquery,
h
t
=
W
c
e
t
h_t=W_c e_t
ht?=Wc?et?,����
e
t
e_t
et?��CNN�������
Recurrent Memory Q-Network (RMQN)ʹ��LSTM,����������attention��decoder:
[
h
t
,
c
t
]
=
L
S
T
M
(
e
t
,
h
t
?
1
,
c
t
?
1
)
[h_t,c_t]=LSTM(e_t, h_{t-1},c_{t-1})
[ht?,ct?]=LSTM(et?,ht?1?,ct?1?)
Feedback Recurrent Memory Q-Network (FRMQN)����һʱ�̵Ķ��Ľ����
e
t
e_t
et?ƴ��������Ϊ����:
[
h
t
,
c
t
]
=
L
S
T
M
(
[
e
t
,
o
t
?
1
]
,
h
t
?
1
,
c
t
?
1
)
[h_t,c_t]=LSTM([e_t,o_{t-1}], h_{t-1},c_{t-1})
[ht?,ct?]=LSTM([et?,ot?1?],ht?1?,ct?1?)
Q����������� ( h t , o t ) (h_t,o_t) (ht?,ot?),��DRQN��DARQNһ�¡�
FRQMNЧ���ܺ�,�����Ժ�ǿ��
[ICLR 2019] Relational Deep Reinforcement Learning
��������:https://arxiv.org/abs/1806.01830

��DARQN״̬����,Ҳ�Ƕ��feature map,������ÿ��point����entity,ÿ����һ��entity,�ѵ��ɾ���,���ж�ͷattention,��ģentity֮��Ĺ�ϵ,����һ��relational block��������̿��Խ��ж��,������������recurrent,����������deep��
��ѧϰ�ɽ��͵IJ���,������Ч�ʡ�����������������ֶ�����ߡ�
[NIPS2018] Relational recurrent neural networks
��������:https://arxiv.org/abs/1806.01822
�൱�ڶ�LSTM������ħ��,��cell��ɵ�memory,�������һ��,�õ�����������

�����Ƕ�memory�Ĵ���,һ��ʼ���������ʼ��һ��memory����,ÿ����һ��memory��Ȼ��ÿ��ʱ�䲽,����ǰ�����밴��ƴ��,ƴ�Ӻ�ľ������k��v,ƴ��ǰ�ļ���q,����self attention�ķ�ʽ�õ����º��memory,�����ͼ��ģ��A������:

Ȼ����
M
~
+
M
=
M
��
\tilde{M}+M=M'
M~+M=M��,��MLP�õ�
M
��
��
M''
M����,Ȼ��
M
��
+
M
��
��
=
M
^
M'+M''=\hat{M}
M��+M����=M^,��memory�Ĵ������,��״��[memory_slots, memory_size]����Ȼ����������q��k��v���Բ�ͬ����,������ֱ����[M;x]��self attention,����x��n��,���������ĵ���n��ȥ�����ɡ�
������ gating ����,input��һ��MLP��� memory_size,����
x
t
x_t
xt?,����������LSTM����һ��,ֻ��cell״̬�����memory:
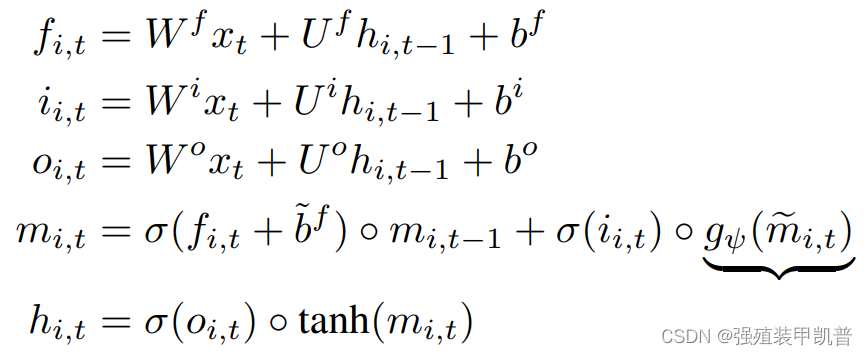
���Կ���
x
t
x_t
xt?Ҫ��memory�е�ÿһ������,������https://github.com/L0SG/relational-rnn-pytorchʱ������ά�Ȳ�һ������ôû��repeat��memory_slots,ԭ����relational_rnn��create_gates������ͨ��gates = gate_memory + gate_inputs�Զ�repeat��,̫ϸ�ˡ����
h
t
h_t
ht?��sizeΪ[batch, memory_slots*memory_size]��
�ڶ�������¶�������Ч��,������Ϊ����ȷ��ģ���佻���Ľ����
[GECCO2020] Neuroevolution of Self-Interpretable Agents
��������:https://arxiv.org/abs/2003.08165
����ѡ���Ե�ע���������һЩ����,������������������������õĸ��š�

ǰ�ڸ�DRRLһ��,����һ����״̬����,����ͨ��q��k�õ�attention�����,ÿ���������patchΪquery,����patch��������Ҫ��,���߽�������Ϊ��patch������patch��ͶƱ,��������൱�ڼ�Ʊ�õ�importance vector,Ȼ��ѡtop k��patch��Ϊ�۲���о��ߡ�
Ч����,�Ƴ�����������Сģ��,����С�Ķ�ʱ�����Ժܺ�,���DZ仯���ʱ����,�����ʵ�����k���⡣
[AAAI2017] Multi-focus Attention Network for Efficient Deep Reinforcement Learning
��������:https://arxiv.org/abs/1712.04603
������Ϊ����ֱ������low-level�ĸ�֪,����Ӧ������entity�����ϵ��

���ȶ�������зָ�,��������������ͼ��,��ֱ�ӷֳɶ��patch��,Ҳ���Ǿֲ�������
Ȼ����������ȡ,���� c i c_i ci?�ǵ�i���ֲ�״̬������,����ͨ��������MLP�õ�,��ƴ���˾ֲ�������index�����������k��v, k i = W k c i k_i=W_k c_i ki?=Wk?ci?, v i = f v ( W v c i ) v_i=f_v(W_v c_i) vi?=fv?(Wv?ci?), f v f_v fv?��leaky ReLU��
������attention,��N��,���ƶ�ͷ��selector
a
n
a_n
an?�ǿ�ѧϰ������,����q,��n��attention������Ȩ�������е�i��Ԫ�صļ��㷽ʽΪ:
A
i
n
=
exp
?
(
a
n
k
i
?
)
��
i
��
exp
?
(
a
n
k
i
��
?
)
A_i^n=\frac{\exp(a_n k_i^{\top})}{\sum_{i'}\exp(a_n k_{i'}^{\top})}
Ain?=��i��?exp(an?ki��??)exp(an?ki??)?
i
��
i'
i���dz�i������оֲ�����,�����Ҳ�̫����,��Ϊ����˵softmax���µ���Ͳ���ȥ��i��Ϊ�˱��ⲻͬ
a
n
a_n
an?�������,�Ӷ�ע�ⲻͬ�ķ���,������������:

R
e
R_e
Re?��������,��Խ��Ȩ��Խ��һ����
R
d
R_d
Rd?�Ǿ�������,ԽСԽ��һ����������ʵ���з���������û��,�����ʼ���Ѿ��㹻�ˡ�
�����Qֵ����,ÿ��attention��Ȩ����v��Ȩ��Ͷ��ܵõ���Ӧ�� h n = �� i h i n v i h_n=\sum_i h_i^n v_i hn?=��i?hin?vi?,ƴ�Ӻ� [ h 1 , ? ? , h N ] [h_1,\cdots,h_N] [h1?,?,hN?]����Qֵ��
����������չ��Э���ֲ��ɹ۲��������ͨ�ų���,�뵥��������������:feature extractionʱ,
a
i
=
W
a
c
i
a_i=W_a c_i
ai?=Wa?ci?,ȷ��ÿ��������IJ�һ��;parallel attentions�����attentive communication:
A
j
i
=
exp
?
(
a
i
k
j
?
)
��
j
��
exp
?
(
a
i
k
j
��
?
)
A_j^i=\frac{\exp(a_i k_j^{\top})}{\sum_{j'}\exp(a_i k_{j'}^{\top})}
Aji?=��j��?exp(ai?kj��??)exp(ai?kj??)?
��������i��j��ע��̶�,j����i,����˵
j
��
j'
j��ҲӦ�ð���j������Qֵ����,��Ҫͨ����Ϣ
h
i
=
��
j
h
j
i
v
j
h_i=\sum_j h_j^i v_j
hi?=��j?hji?vj?���������Լ�����Ϣ
v
i
v_i
vi?,ƴ�Ӻ�
[
h
i
,
v
i
]
[h_i,v_i]
[hi?,vi?]���㡣���߷���ʵ��������ɢ,��������������:
R
=
��
(
a
?
k
?
)
R=\lambda(a\cdot k^{\top})
R=��(a?k?)
�ڵ������峡���¼���ѵ��������Ч�����������峡��������ѵ��,����ΪbaselineҲ�ﵽ������,��������Ч����������Ҫ�ص�����q��һ����ѧϰ������
��ģ��ϵ
[ICML2019] Actor-Attention-Critic for Multi-Agent Reinforcement Learning
��������:https://arxiv.org/abs/1810.02912

������critic�ļܹ�,���Կ�����MADDPG����,���Ǽ���ʽ��,�������ڶ���soft attention��
�������Լ���״̬�Ͷ�������һ��MLP�õ� e i e_i ei?,Ȼ���Լ�����Ϊq,��������Ϊk��v����query������v������������V�����Ա任����leaky ReLU,Ȼ��Ȩֵ��������self attention,ͬ�����Խ��ж�ͷ,���ֱ��ƴ�ӡ�������乲��Ȩ�ؾ��������ͬ��embedding�ռ�,������Ϊcritic����Ҳ���Թ���,��Ϊ��������ֵ�������Ʊ������Ƕ�����ع�,���Ͷ��ڸ��������岻ͬ���й�ͬ������,ѧϰ���Ч��
critic��С�����ص���ʧ�ٽ�̽��:

actor���ݶ�����:

b��baseline��������ɢ����,����������ж�����Qֵ,Ȼ����ݸ���������,���������оͲ�����
a
i
a_i
ai?,���ƻ���ֵ�ķ���,����Ҳ����ôʵ�ֵ���������������,ԭ���ǡ�either estimate the above expectation by sampling from agent i��s policy, or by learning a separate value head that only takes other agents�� actions as input��,�Ҳ��Ǻ�����,�Ҿ���Ӧ�������̬�ֲ��ľ�ֵ�ͷ���ɡ���������������Ķ���,����û����MADDPGһ��ѡ�������е�,��Ϊ������overgeneralization,ʹ�������岻��������������ĵ�ǰ����Э��,��˸��������۲��������ɶ�����
Ч���ܺ�,����������������������ij����¡�
[AAAI2020] Multi-Agent Game Abstraction via Graph Attention Neural Network
��������:https://arxiv.org/abs/1911.10715

����,������i��������
j
��
i
j\neq i
j��?=i��embedding��Ϻ�
(
h
i
,
h
j
)
(h_i,h_j)
(hi?,hj?)����˫��LSTM����˳������,Ȼ��gumble softmax�õ�hard attention
w
h
i
,
j
w_h^{i,j}
whi,j?��
Ȼ����soft attention:
W
s
i
,
j
��
exp
?
(
h
j
?
W
k
?
W
q
h
i
W
h
i
,
j
)
W_s^{i,j}\propto\exp(h_j^{\top}W_k^{\top}W_q h_i W_h^{i,j})
Wsi,j?��exp(hj??Wk??Wq?hi?Whi,j?)
�����Ҿ���Ӧ�ð�
W
h
i
,
j
W_h^{i,j}
Whi,j?Ϊ0��ֱ��ȥ��,������soft attention,��Ϊsoftmax֮���ǻ������Ȩ�ء�

������G2ANet������µ�ͨ�ŷ�����������ʹ��LSTM,����DRQN����������attention��õ�����Ȩ��,�����ν��GNN���Ǽ�Ȩ���:
x
i
=
��
W
h
i
,
j
W
s
i
,
j
h
j
x_i=\sum W_h^{i,j}W_s^{i,j}h_j
xi?=��Whi,j?Wsi,j?hj?
Ȼ�����
(
x
i
,
h
i
)
(x_i,h_i)
(xi?,hi?)�õ�������������Կ�������ʱ���dz�����
W
h
i
,
j
W_h^{i,j}
Whi,j?,��ôȥ��
W
h
i
,
j
=
0
W_h^{i,j}=0
Whi,j?=0��
j
j
j��,
W
s
i
,
j
W_s^{i,j}
Wsi,j?�Ͳ�Ϊ1,�Ҿ�����������ġ�

�������AC�ܹ���,������MAAC����,����
e
i
,
x
i
e_i,x_i
ei?,xi?�ĺ���,�������ڼ���
x
i
x_i
xi?ʱ����һ��hard attention��
Ч����ͦ�õġ�
[AAMAS2020] Learning Transferable Cooperative Behavior in Multi-Agent Teams
��������:https://arxiv.org/abs/1906.01202
���½�������廷��,�Ӻںн�ģΪagent-entityͼ,�����������ʵ�忴����,�ߴ����˴�֮����ͨ��,����������Ŀ�����б仯�����䡣��һ��episode��,�㱣�־�ֹ,����ͬepisode��������仯�����߿��Ǿ��������ͨ�źͲ�����ͨ�š���ϵ���۲춼��ģ��,���ڽ�ģ�۲첿����DRRL����,��˷��ڽ�ģ��ϵ�
ÿ��������ֻ�ܹ۲쵽�Լ��ľֲ�״̬
X
i
X^i
Xi,����λ�ú��ٶ�,Ȼ��õ���������
U
i
=
f
a
(
X
i
)
U^i=f_a(X^i)
Ui=fa?(Xi)�����ڻ�����ʵ��
l
l
l,���ȵõ�embedding
e
i
l
=
f
e
(
X
i
l
)
e_i^l=f_e(X_i^l)
eil?=fe?(Xil?),����
X
i
l
X_i^l
Xil?�����״̬��Ȼ��ͨ��self attention����
e
i
l
e_i^l
eil?,���߳��������Ϊentity message passing,������ϳɹ̶���С�Ļ���embedding
E
i
E^i
Ei��Ȼ��
U
i
U^i
Ui��
E
i
E^i
Eiƴ�ӱ��
h
i
h^i
hi,������������Լ�״̬�ͻ��������⡣

Ȼ���ù����ľ���
W
Q
,
W
K
,
W
V
W_Q,W_K,W_V
WQ?,WK?,WV?����q��k��v,���Լ�����Ϊq,query����������(�����Լ�),����self attention,��Ȩ��ͺ�ͨ��
W
o
u
t
W_{out}
Wout?���Ա任�õ�
V
f
i
V_f^i
Vfi?,Ȼ����
h
i
h^i
hiƴ�Ӻ���з����Ա任�õ��µ�
h
i
h^i
hi�����ҿ��Խ��ж���ͨ��,Ҳ�����ظ�K��,ʹ�ò�ֱ��������������Ҳ��ͨ��,ʵ����Ϊ3���ܵ���˵�е���DRRL���л�������,Ȼ��self attention����ͨ�š�����ʹ��PPOʵ��,������Ϊͨ��Ҳ��decentralized��
Ч���ܺ�,����EMPҪ�ȵ�����ʵ������ƴ��Ч����,�ر�����������Ŀ��ij���,���ӹ۲�ռ�Ĵ�С������Ҫ�����������Zero shot Generalization��,����ͨ�Ż���á�
[ICLR2020] Graph Convolutional Reinforcement Learning
��������:https://arxiv.org/abs/1810.09202
���DGN�������Ǹ�����,��arxiv���ύʱ�俴��ƪ�ύ����,�������Ǹ��������硣DGN����ع�����˵�����Ǹ�Ҫ��ʽ��label�������ʵ��,��ʵӦ���в����С��Ҿ����е�̫�����˰�,����������ͨ�ŵ�����������һ����,��������ѧ�����Ͻ��ɡ���MAACҲ����,����MAAC��soft attention,����ֻ��һ��,������Ҳû�ᡣ

ÿ�ξ������ǽ���һ�ζ�ͷattention,�൱�ڰ�DRRL��relational kernel�����,��ʵ�������Ǹ����Ҳ�Ͷ��˶�ͷ��ÿ����������������,���ƴ�ӡ�������ΪЭ���dz������ҳ��ڵ�,���attentionȨ��Ӧ���ȶ�,���߹̶���������ʱ�䲽���ڽӾ���,ʹ�õ�ǰ�����������ǰ��Ȩ�غ���һ��ʱ�䲽��Ȩ��,Ȼ��ͨ��KLɢ�Ƚ���Լ��,��ʹ��Ŀ����������Ϊ�ӳٸ��µ��¹�ϵ��һ�¡�

m��ͷ,k�Ǿ�����,
��
=
0.03
\lambda=0.03
��=0.03,������Ϊ�ϲ��Ӧ�ø�������ȶ�,���Լ���ϲ����������Ȩ�ء�
ʵ��ʹ��DQN,��������һ������,�����������á�
From Few to More: Large-scale Dynamic Multiagent Curriculum Learning
��������:https://arxiv.org/abs/1909.02790
[2020.6.9] Qatten: A General Framework for Cooperative Multiagent Reinforcement Learning
��������:https://arxiv.org/abs/2002.03939
�ϸ���˵���ܲ���attention,�����û��q��k��v,ֻ�ǽ�������ṹ��������ͨ���Ƶ��õ�
Q
t
o
t
Q_{tot}
Qtot?��
Q
i
Q^i
Qi֮��Ĺ�ϵ:
Q
t
o
t
(
s
,
a
)
��
c
(
s
)
+
��
i
,
h
��
i
,
h
(
s
)
Q
i
(
s
,
a
i
)
Q_{tot}(s,\textbf{a})\approx c(s)+\sum\limits_{i,h}\lambda_{i,h}(s)Q^i(s,a^i)
Qtot?(s,a)��c(s)+i,h��?��i,h?(s)Qi(s,ai)
Ȼ�����soft attention�Ľṹʵ��:

�ö�ͷ��ʾ��ס�Ч��ͦ�õ�,���ڵ���MMDP�Ϸ�����������������ʵQֵ��

