目录
最近在做CSDN文库标签的分类,文库的数据比博客数据要短一些,特征比较分散,时间紧任务重,走标注流程是肯定来不及了,没有标注数据做分类的话还需要下一番功夫了,作为一名算法工程师,在详细分析数据之后,还是能能发现了一些可以尝试的方案,于是乎,开整。
文库下载同博客一样,有用户自定义的标签,但是这个标签是根据用户主观意念打上去的,由于用户的认知/知识水平不一致,或者是出于其他目的,自定义的标签是不能直接用来使用的,即是一种弱标注的数据。直接把他们丢进分类器里面效果是不会得到保证的,需要做一些处理,将弱标注数据进行过滤,变成强标注数据。
分析现有数据
对数据仓库中的数据进行统计,分析发现数据具有以下几个特征:
1、标签数据分布不均匀。根据用户自定义标签和标题进行关键字的搜索得到数据的大体分布。
2、用户自定义标签质量参差不齐。
3、每条数据有标题和描述字段,描述字段有的是真的描述,有的就是将标题复制了一遍。不是所有的数据都具有有效的分类特征,很多软件类下载资源标题和描述都是一个英文文件名,例如:webcampic.zip。
4、数据跨度大。各行各业的数据都有涉及,要想分类器能覆盖所有的数据,现有的标签需要扩展。

解决方案
1、对于数据不均匀,根据数据的覆盖度,将有数据的标签挑选出来,至少能覆盖60-70%的数据即可,这部分标签数据构建模型预测来解决标签问题,剩下的30-40%配置同义词的方式来解决。
2、用户标签质量不高,可以使用特征选择的方式挑选出每个标签的特征词汇,根据这些特征词汇来对语料进行过滤。
3、尽可能把有特征的数据字段那出来协助分类,标题/用户标签/描述/文件名等,若是可以解析出文件的内容,也是一个非常有用的特征。
4、对于现有标签没有覆盖的领域,需要业务运营端扩展一下现有的标签体系。这个就没有办法了,需要其他团队协助完成。
初始语料集构建
对于使用分类器预测的标签,每个标签标注1-2个同义词,在数据库里面对用户自定义标签和标题搜索出包含标签同义词的数据,每个标签抽取大约3000条。
对内容进行清洗,去掉换行,大写转小写,全角转半角等,以及分词,分词之前将标签同义词加入用户自定义词典,标签同义词就是人工挑选的特征词,加入分词词典避免分词不对造成特征丢失。分词采用的是jieba中文分词工具,使用jieba分词有几点需要注意,如果是使用hanlp或者其他中文分词工具的请忽略。
1、英文自定义词问题。在有英文自定义词的时候,其会将一个完整的英文拆开,例如:将vr加入自定义词典,后面分词如果遇到vrrp/vrilog等包含vr的词,就会被拆成vr和rp,vr和ilog。最好是不要将英文加入分词词典,如果有其他的解决方案也欢迎留言交流讨论。
def _add_user_dict(self):
"""将tag加入自定义词典"""
for tag in self._tag_dict:
# 纯英文字符不加词典
if not tag.isalpha():
self.tag_classify_helper.add_word(tag)
for word in self._tag_similar_dict:
if not word.isalpha():
self.tag_classify_helper.add_word(word)2、自定义如果包含空格等特殊字符,需要在import后加以下代码。
# 解决自定义词中有空格或者特殊字符分不出来的问题
jieba.re_han_default = re.compile('([\u4E00-\u9FD5a-zA-Z0-9+#&\._% -]+)', re.U)3、可以利用jieba的多进程加速分词速度,分词对cpu的利用还是蛮高,这里电脑有多少核就填写多少个进程吧。
jieba.enable_parallel(4) # 多进程或者利用进程池实现定制化的多进程切词方式:
def _simple_cut(self, line):
id, tag, content = line[0], line[1], line[2]
seg_list = self.tag_classify_helper.word_cut(content)
seg_data = " ".join(seg_list)
new_line = str(id) + "\t" + str(tag) + "\t" + seg_data
return new_line
def _cut_data(self, processes=4):
"""对语料进行分词"""
new_data = []
pool = Pool(processes)
data_list = []
with open(self._download_data_selected_path) as file:
for line in file:
id, tagstr, content = line.strip().split("\t")
data_list.append((id, tagstr, content))
new_data = pool.map(self._simple_cut, data_list)
with open(self._download_data_seg_path, "w") as file:
file.writelines([line + "\n" for line in new_data])
return True清洗后的数据是这样的:

特征选择过滤语料
以前在使用机器学习方法做文本分类的时候,都是需要手动挑选调整特征的,常用特征选择方法有词频逆文档频率(TF-IDF)、卡方检验(Chi-square)、信息增益法(Information Gain)
1、词频逆文档评率
怎么衡量一个词对于一个文档的重要性呢?在当前文档里面出现次数越多(TF),但是在其他文档中出现(IDF)越少,代表词对文档越重要。

其中,对于某个标签t来说,N表示样本文本数据集中标注了该标签t的文本数据的数量,m表示出现了标签t的文本数据的数量,tf表示标签下面博文出现词t的频次。
def stat_word_count(self, path, tags_words_dict, word_set):
with open(path) as file:
count = 0
for line in file:
count += 1
if count % 10000 == 0:
logger.info(count)
id, tags, context = line.strip().split("\t")
words = context.split(" ")
count_dict = dict()
for word in words:
word_set.add(word)
if word in count_dict:
count_dict[word] += 1
else:
count_dict[word] = 1
for word in count_dict:
for tag in tags.split(","):
if tag not in tags_words_dict:
tags_words_dict[tag] = dict()
if word not in tags_words_dict[tag]:
tags_words_dict[tag][word] = 1
else:
tags_words_dict[tag][word] += 1
def compute_tfidf(self, tags_words_dict, word_set):
tag_words_tfidf_dict = dict()
logger.info(f"tags_words_dict size:{len(tags_words_dict)}")
for word in word_set:
d = len(tags_words_dict)
count = 0
for tag in tags_words_dict:
if word in tags_words_dict[tag]:
count += 1
for tag in tags_words_dict:
if tag not in tag_words_tfidf_dict:
tag_words_tfidf_dict[tag] = dict()
if word not in tags_words_dict[tag]:
continue
tag_words_tfidf_dict[tag][word] = tags_words_dict[tag][word] * math.log(d/count)
return tag_words_tfidf_dictTFIDF计算简单,在大规模语料上面计算速度较快,但是对于低频词处理的不够好。
2、信息增益
信息增益衡量的是特征对于分类系统整体的重要性,即对特征的出现对于整体不确定性减小的程度的表示。

信息增益据说效果是最好的,但是其挑选的特征是全局特征,不是本地特征(每个类别有自己的特征集合),不符合我们现在的场景。
3、卡方检验
统计学假设检验的思想,即假设词与类别不相关,利用卡方公式计算出CHI值,值越大表示假设越不成立,词与类别越相关。先看混淆矩阵,:
| 属于K | 不属于K | 总?计 | |
| 不包含t | A | B | A+B |
| 不包含t | C | D | C+D |
| 总?数 | A+C | B+D | ?????N |
t表示词,K表示类别,N表示训练集中全部文档数目;
A表示属于K且包含t的文档数目;
B表示不属于K包含t的文档数目;
C表示属于K不包含t的文档数目;
D表示不属于K不包含t的文档数目。
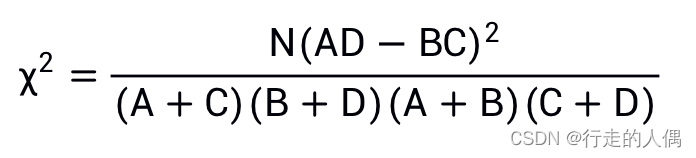
公式中N,A+C和B+D对同一类别文档中的所有词来说都是一样的,更多时候我们只做特征挑选而不会在意具体的值,则公式可以进行化简:
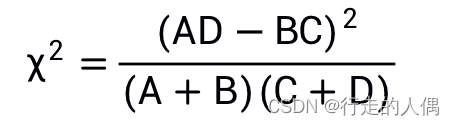
def _choice_feature_word(self, data, tags, min_count=5,topN=1000):
"""特征词挑选,这里采用卡方检验"""
feature_words_dict = dict()
# 先统计所有词
all_words_dict = set()
for seg_words in data:
for word in seg_words:
if word in all_words_dict:
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
# 对每一个类别统计计算chi值
for tag in set(tags):
tag_words_map = dict()
chi_words = []
feature_words_dict[tag] = dict()
for word in all_words_dict:
# 指定最小频数
if all_words_dict[word] < min_count:
continue
chi_A = 0
chi_B = 0
chi_C = 0
chi_D = 0
for index, seg_words in enumerate(data):
category = tags[index]
if tag == category and word in seg_words:
chi_A += 1
elif tag == category and word not in seg_words:
chi_C += 1
elif tag != category and word in seg_words:
chi_B += 1
elif tag != category and word not in seg_words:
chi_D += 1
chi = math.pow(chi_A * chi_D - chi_B * chi_C, 2) / \
(chi_A + chi_B)*(chi_C + chi_D)
tag_words_map[word] = chi
for word, value in sorted(tag_words_map.items(), key=lambda item: item[1], reverse=True):
if len(feature_words_dict[tag]) < topN:
feature_words_dict[tag][word] = value
else:
break
return feature_words_dict根据特征选择算法可以挑选出每个类别topn个特征词,然后根据语料包含特征词的位置和数量判定语料的标签是否正确,不正确是否可以纠正等等操作。可以将乱打的标签过滤掉。
训练模型
模型依然选择前面做博客标签分类时使用的多标签分类器,这里就不再详细讲解了,博客里面有详细的源码。大约训练20个batch可以收敛。条件允许可以将每个batch的结果保存起来,综合评估在测试集上面的准确率和召回率来选择模型。
缺失标签数据处理
对于分类器没有覆盖的数据,就会打不上标签,这里采用配置标签同义词与word2vec扩展同义词的方式从标题和用户自定义标签抽取标签,根据词出现的个数,位置,类型(标题,用户自定义标签,摘要,文件名)来给予不同的权重。
总结
作为一个快速版本,在覆盖度和准确率方面已经具有一定效果,但是如果对召回和准确率有很高的要求,还需要不断迭代优化,最好是有人工标注的数据。
经验来说,有几个需要值得注意的地方:
1、标签多义词的情况,最好通过分类器来解决,例如:“容器”类别。
2、加分类器标签时,一个类数据最好覆盖全,例如:包含“小说”关键字的有“小说”和“小说阅读器”,训练语料只加其中一种就会导致分类器学习不到全部特征而导致分类不准确。
3、分类器的选择对结果有一定影响,因为涉及到了特征工程,选一个近年一直有更新的中文分词器,当然有条件的最好能自己写一个,毕竟现在开源的分词器也很多。
4、做分类器语料很重要很重要很重要,有条件可以多挖掘一下语料。

