目标检测经典知识点汇总(一):RPN
前言
有一些非常经典的应用于目标检测的理论知识,虽然之前看论文有看到过,但后面再次碰到又会忘记具体细节,因此值得记录下来。
一、Region Proposal Network (RPN)
RPN网络在2016年于Faster RCNN文章中首次被任少卿、何凯明等人提出来。
目标检测按照检测方法可以被归类为one-stage和two-stage方法。针对于two-stage方法,主要可分为目标定位和分类两个细分任务。而对图像分类又是属于最基础的传统卷积的方法。因此,如何对目标正确定位是一个比较棘手的问题。
传统的目标的定位的方法有如下:
-
使用滑动窗口进行图像检测。优点:能确保检测窗口覆盖到每一个目标。缺点:需要在图像的每个像素点均进行滑动,且需要多尺度的窗口进行滑动,而大多数滑动窗口都不包含对应的目标,造成不必要的计算。
-
使用RCNN中采用的selective search方法。它的思想是只选择有潜在目标的区域, 抛弃掉大部分没有目标的区域。 因此极大地减少了无用功, 提高了检测的效率。 常用的方法是利用图像中的颜色, 纹理, 形状等特征对图像进行分割。但是,因为selective search独立于分类网络,使用的是传统的先验信息,无法实现端到端的训练,因此同样也会导致目标检测速度较慢,实时性较差。
因此,为克服以上缺陷,Region Proposal Network (RPN)网络诞生。从如下图结果来看,其在目标检测准确率和性能上均有效果明显的提升。(属于Double win,没有牺牲性能来换取准确率)
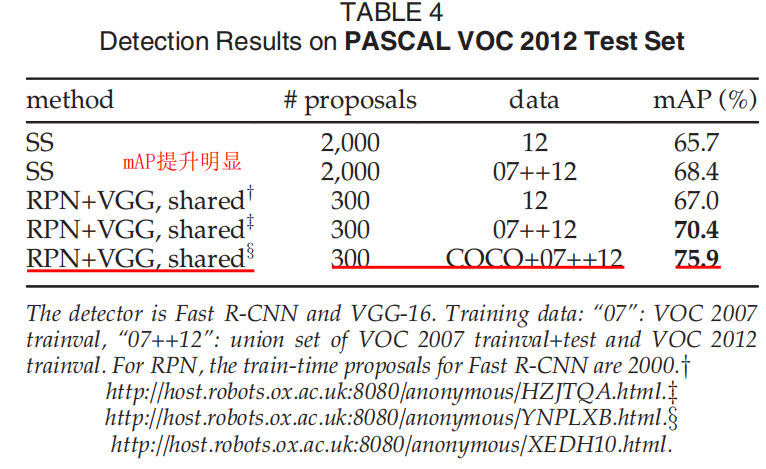

RPN原理讲解
RPN原理非常简单,如上图,通俗来讲,输入是卷积神经网络从原始图像提取到的特征图(feature map),通过在特征图逐像素生成anchor,再对anchor进行回归偏移(位置及尺寸修正)和分类(二分类,判断是否包含object),来确定最终的候选区域(region proposal)。
其中,图像尺寸
H
×
W
×
3
H \times W \times 3
H×W×3,特征图尺寸
H
f
×
W
f
×
C
f
H_f \times W_f \times C_f
Hf?×Wf?×Cf?,特征图长宽尺寸远小于原始图像尺寸,因此相比于原始图像,feature map生成的anchor数目更少。
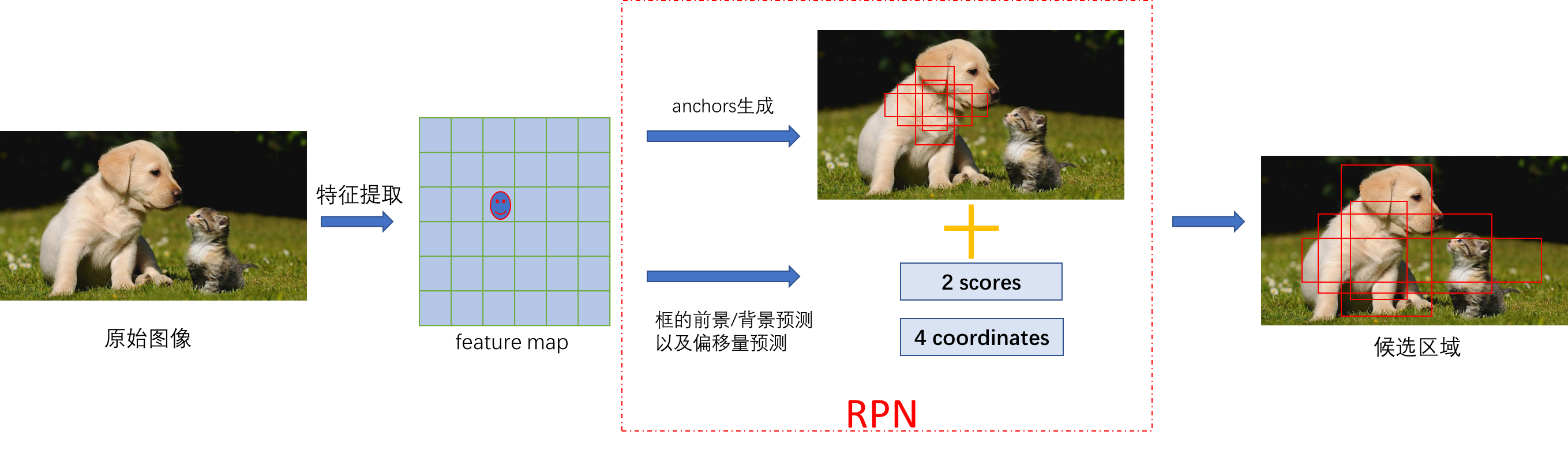
RPN在目标检测中的应用(Faster RCNN为例)
Faster RCNN模型主要分为如下四部分,如图
- 第一部分为conv layers,用基础的卷积神经网络来提取feature maps
- 第二部分为Region Proposal Network,RPN网络用于生成region proposals。
- 第三部分为RoI pooling,该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- 第四部分为classifier,利用proposal feature maps判别proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
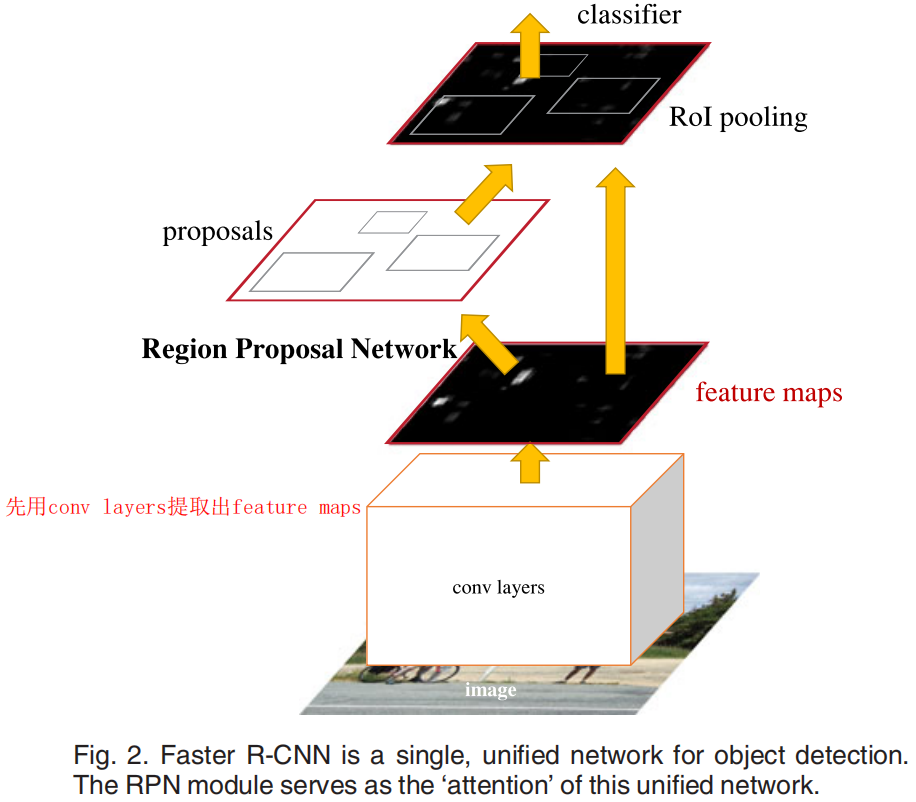
1. Conv layers
conv layers用于从图像中提取出feature maps。以VGG-16作为backbone进行举例。
将原始图像的尺寸由
P
×
Q
P\times Q
P×Q resize为
M
×
N
M\times N
M×N,经过conv layers,得到Feature map。
Feature map相对应尺寸为
M
16
×
N
16
×
512
\frac{M}{16} \times \frac{N}{16} \times 512
16M?×16N?×512,
假定 M=800 N=600,则feature map尺寸为
50
×
38
×
512
50\times 38\times 512
50×38×512
2. RPN
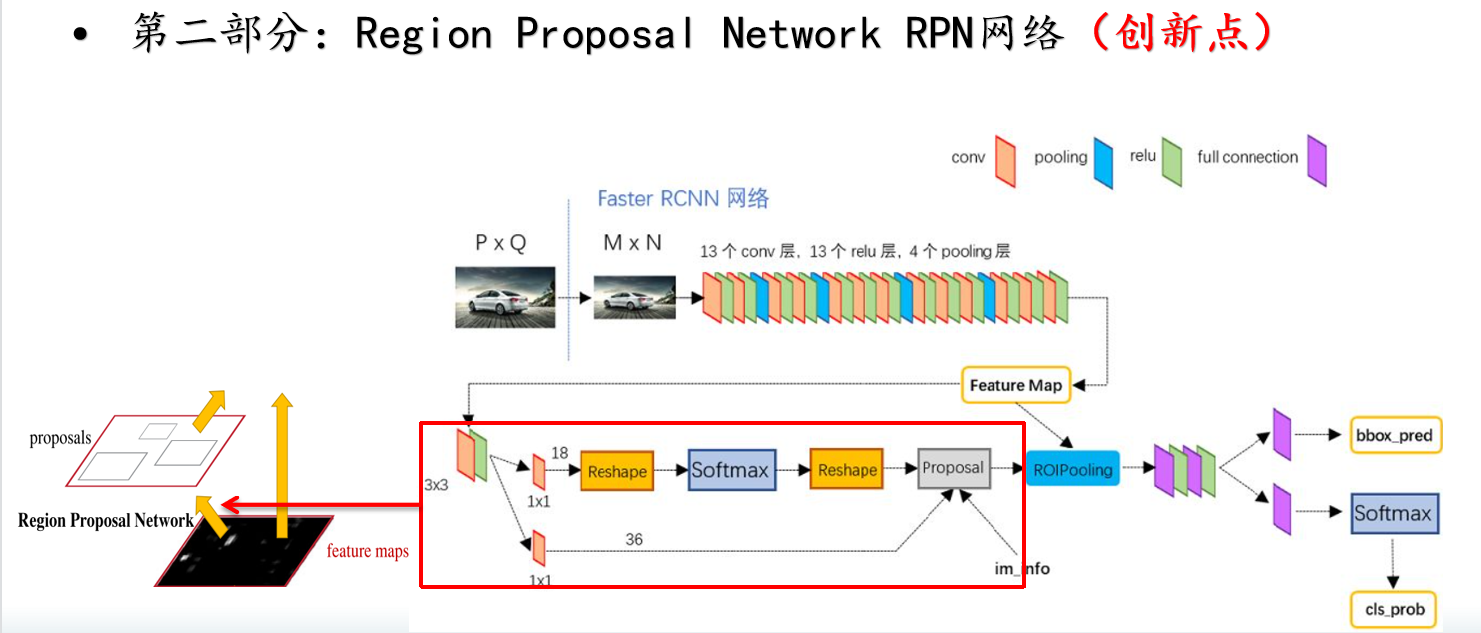
如图,RPN网络有两个分支,分别用于box的回归(reg layer)和分类(cls layer):
- 针对cls layer(上面的分支),经过全卷积后维度为50x38x18 => 50x38x9x2,逐像素通过softmax分类anchors获得positive和negative分类。(二分类,positive表示anchor内有object的概率)
- 针对reg layer(下面的分支),经过全卷积后维度为50x38x36 => 50x38x9x4,逐像素计算对于anchors的bounding box regression偏移量,以获得精确的proposal。
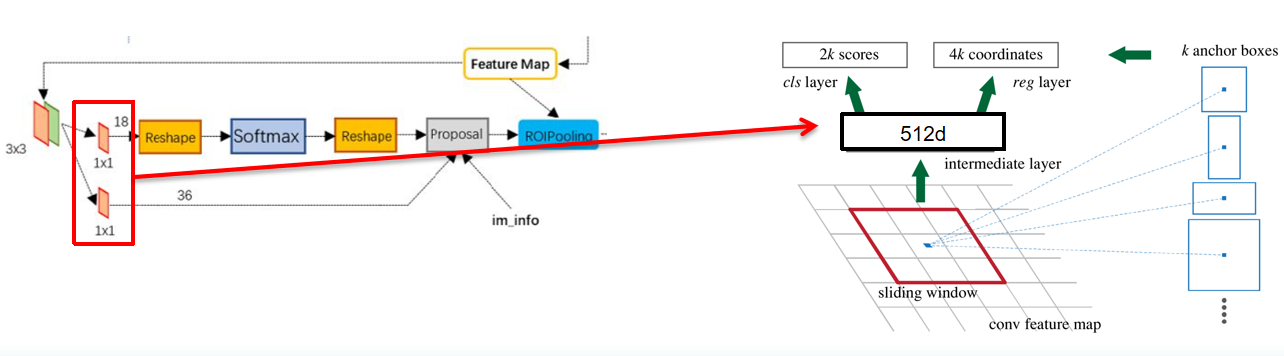
如图,全卷积目的为调整通道数,调整目的如下:
- 9表示9个anchor,由3个不同scale和不同的ratio组成的anchor,3*3=9。
- 2k scores:每个anchor要分positive 和 negative 。
- 4k coordinates:每个anchor要有x,y,w,h对应的4个偏移量来确定其位置。
且一共会生成Anchor数目: c e i l ( 800 / 16 ) ? c e i l ( 600 / 16 ) ? 9 = 50 ? 38 ? 9 = 17100 ceil(800/16)*ceil(600/16)*9=50*38*9=17100 ceil(800/16)?ceil(600/16)?9=50?38?9=17100
Proposal层,RPN网络的最后一步为经过Proposal层,如上图所示,
RPN网络有两个分支,分别用于box的回归(reg layer)和分类(cls layer)
Proposal层负责综合positive anchors和对应bounding box regression偏移量来获取proposals,同时剔除太小和超出边界的proposals。
Proposal层输入为:
- anchors分类器的结果positive 与 negative的得分情况
- bbox regression 得到的偏移量d_x,d_y,d_w,d_h
- 图像信息,im_info=[M, N, scale_factor] ,scale_factor为图像从PxQ到MxN变换比例。
Proposal层处理步骤:
- 生成anchors,利用输入的偏移量进行bbox regression
- 按照positive 相对应的softmax score进行排序,提取(e.g.6000)个anchors,得到修正位置后的positive anchors(<=6000个)
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界
- 剔除小尺寸的anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression)
- 最后剩余的对应的bbox reg的偏移量(e.g. 300)结果作为proposal输出
至此已经得到相对应的proposal,检测工作(RPN)已完成,之后对提取出的proposal进行分类。
如何训练RPN?
如何训练RPN网络,需要从两方面入手:
根据分支1,如何判定anchor是positive or negative?
根据分支2,如何对anchor的偏移量进行回归?
针对训练阶段如何通过ground truth判定anchor是positive or negative的问题,做出如下讨论:
- ground-truth box和anchors具有最高IoU的anchor,认定该anchor为positive
- 当anchor和任意的ground-truth box的IoU>0.7,此时认定anchor为positive
也就是说,一个ground truth box可能对应多个positive anchors ,且条件1是为了防止有的ground-truth box没有IoU>0.7的情况而没有anchor和其相对应,确保ground truth box一定有其对应的anchor。
此外,对于不是positive的anchor,当anchor和所有的ground-truth box的IoU小于0.3,则认定为negative。
L_cls损失函数如下:
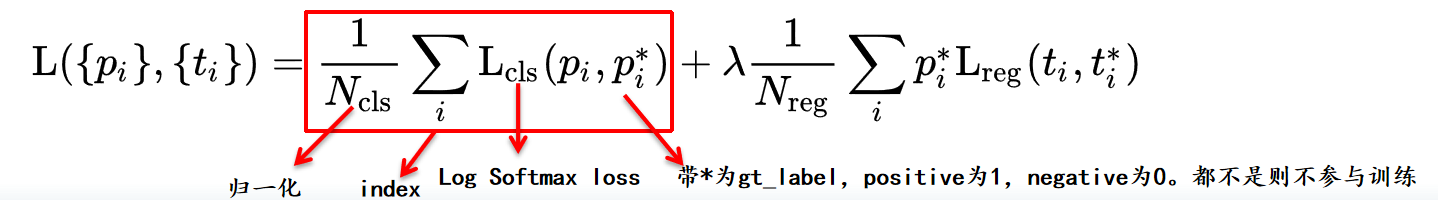
注:根据上述判定条件,依据ground truth得到的为gt_label,及
p
i
?
p_i^*
pi??,且positive =1;negative=0。那些既不是positive也不是negative的anchor,对训练不造成影响。
p
i
p_i
pi?是通过分支1(cls_layer)经过softmax得到的score。
针对判定anchor偏移量回归的问题,定义如下:
t
i
t_i
ti?:为包含4个偏移量的向量,
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx?,ty?,tw?,th?
L
r
e
g
=
R
(
t
i
,
t
i
?
)
L_{reg}=R(t_i,t_i^*)
Lreg?=R(ti?,ti??),R为smooth_L1函数。
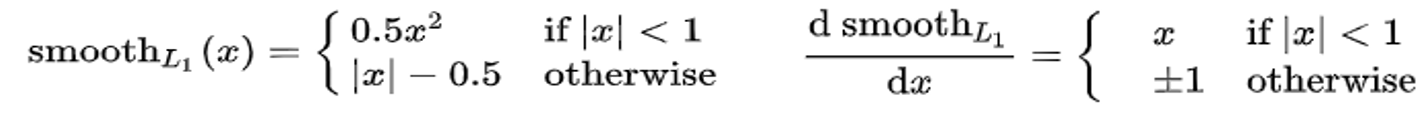
smooth L1在x较小时,对x的梯度也会变小,而在smooth L1很大时,对x的梯度的绝对值达到上限1,也不会太大以至于破坏网络参数。
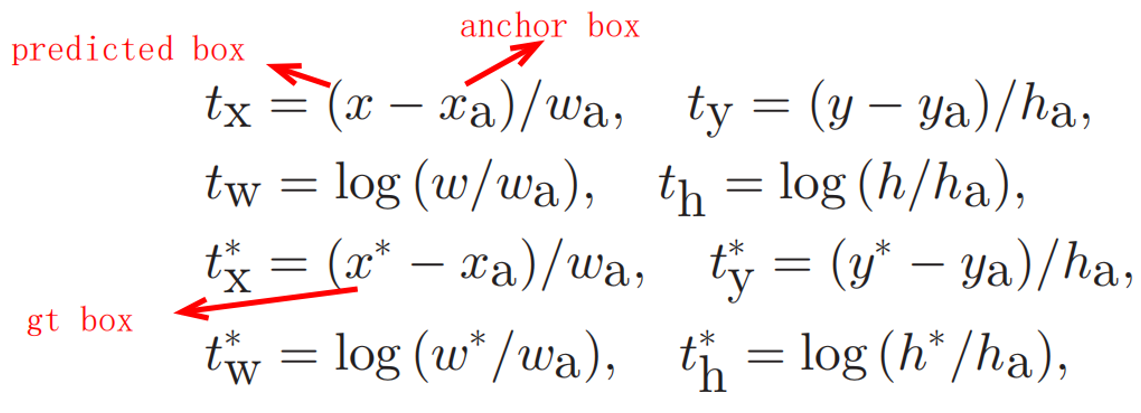
计算
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx?,ty?,tw?,th?及
t
x
?
,
t
y
?
,
t
w
?
,
t
h
?
t_x^*,t_y^*,t_w^*,t_h^*
tx??,ty??,tw??,th??方式如上,整体Loss函数如下。

确定了损失函数后,则RPN网络可以用随机梯度下降法进行端到端的训练。
但因为anchors的positive和negative数目差距较大,因此在对每张图进行训练时,随机选取256个anchors,且确保positive和negative比例为1:1。若positive anchors数目不够,则用negative anchors替代。
针对conv layer的初始参数,则采用在ImageNet上预训练的权重参数作为初始化。
3.ROI pooling
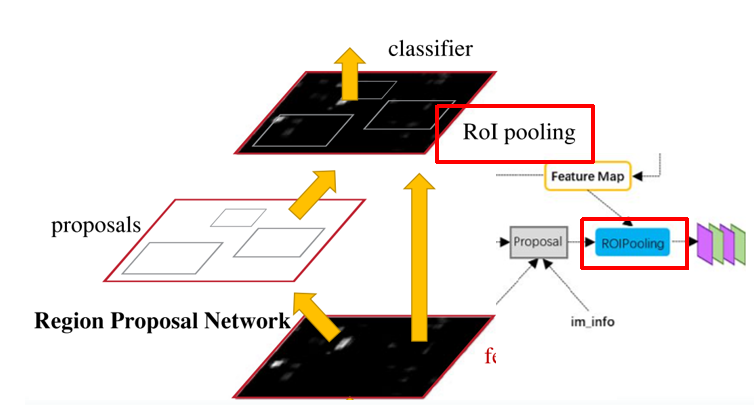
截至目前,已经利用RPN提取出相对应的proposal,之后对proposal进行分类,在分类前,需要先根据proposal给出的候选框来提取出原图像feature map的proposal区域特征。
RoI Pooling层则负责收集proposals,并依据proposal计算出proposal feature maps,送入后续网络。
RoI Pooling有两个输入:RPN网络提取出的proposals 和 卷积网络提取的feature maps
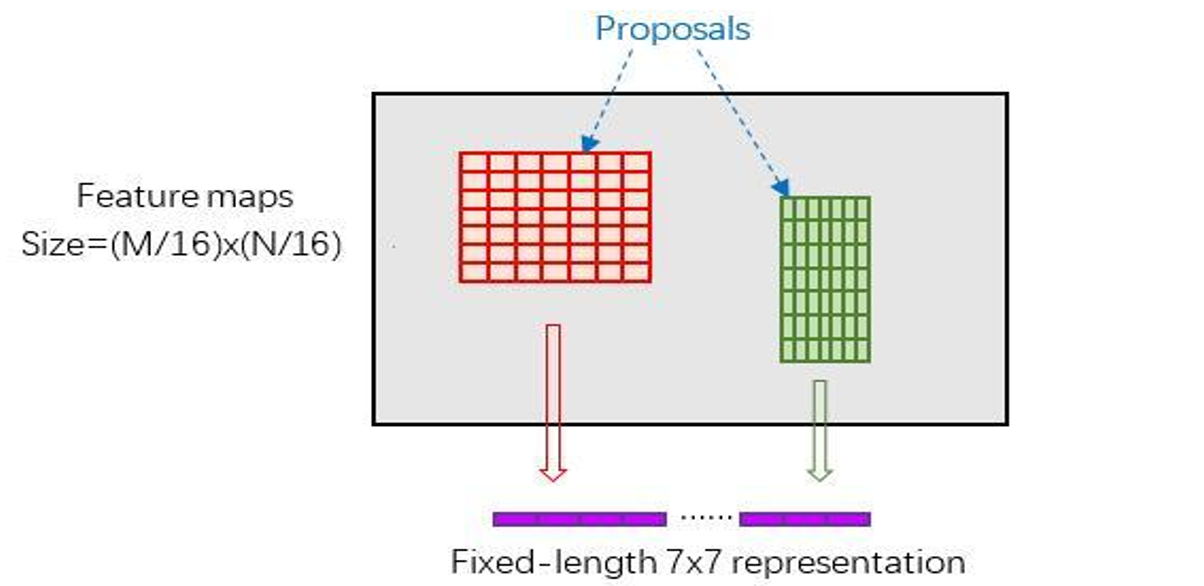
RoI Pooling步骤:
- 将proposal映射到feature map的尺度,即从MxN映射到M/16xN/16,spatial_scale: 0.0625 # 1/16
- 将proposal映射到feature map内的区域划分为
p
o
o
l
e
d
w
×
p
o
o
l
e
d
h
pooled_w \times pooled_h
pooledw?×pooledh?尺寸(7x7)的网格
注:不同size的区域统一划分成7x7的网格,同一区域每个网格内尺寸相同。 - 对网格进行max pooling处理,得到固定尺寸
p
o
o
l
e
d
w
×
p
o
o
l
e
d
h
pooled_w \times pooled_h
pooledw?×pooledh?(7x7)
的proposals feature maps,实现固定长度的输出。
4.Classifier
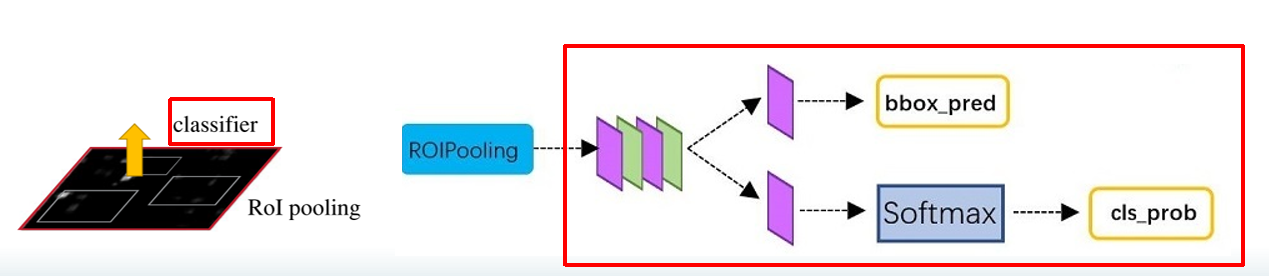
此时已经提取出的固定尺寸的proposal feature maps(7x7),最后用分类器分类即可。
Classifier利用RoI pooling获得的proposal feature maps(7x7),
通过fully connect层与softmax计算每个proposal具体属于哪个类别(如人,车,电视等),输出cls_prob概率向量;
同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
Faster RCNN整个训练框架图
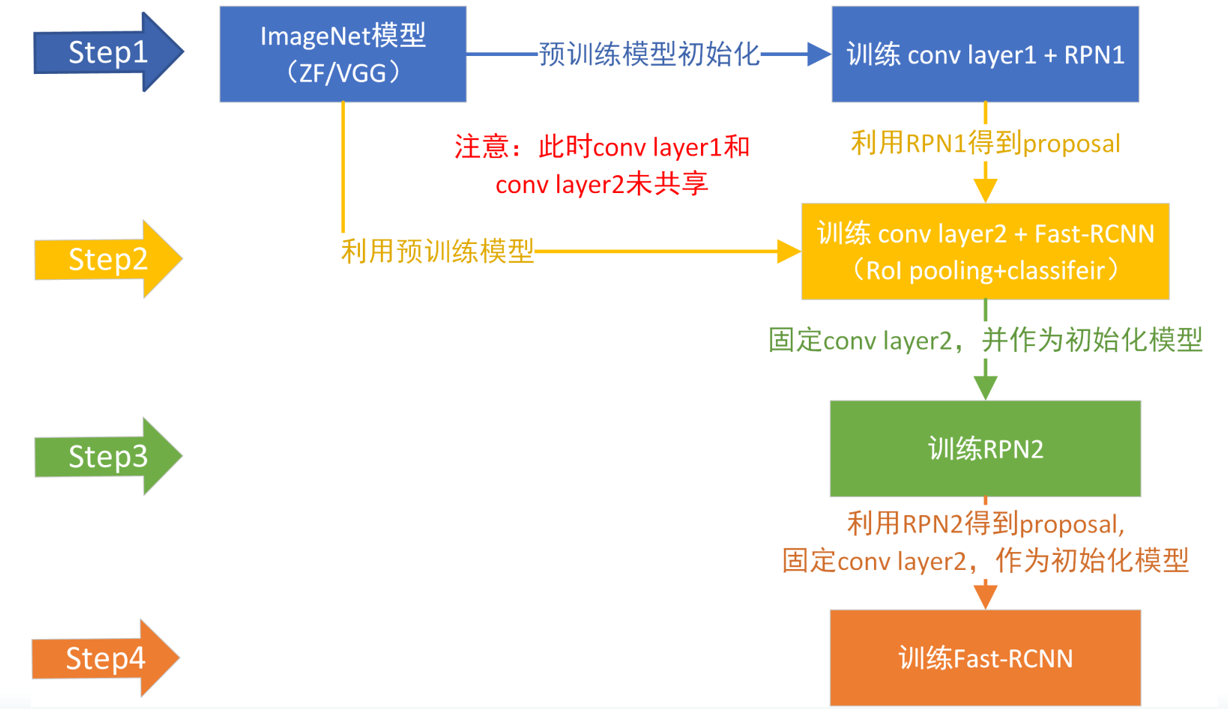
总结
可以看到,Faster-RCNN的创新点最主要就在RPN网络。同时,RPN网络可以被单独拿出来使用,用于提取图像中可能存在目标的Proposal(和selective search方法一样)。
RPN的用途可能不仅限于此(Faster-RCNN),因为其在框选候选区域的时候并没有考虑到目标物的真实类别,因此,也有一些其它利用RPN的方法。例如做开放世界的目标检测,及不再受限于类别限制,如
V
i
L
D
[
2
]
ViLD^{[2]}
ViLD[2]
D
e
t
P
r
o
[
3
]
DetPro^{[3]}
DetPro[3]等方法。
同时,也有更多意想不到的利用RPN的方式等待去发掘。
参考
[1] Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans Pattern Anal Mach Intell, 39(6), 1137-1149. https://doi.org/10.1109/TPAMI.2016.2577031
[2]Gu, X., Lin, T.-Y., Kuo, W., & Cui, Y. (2021). Open-vocabulary Object Detection via Vision and Language Knowledge Distillation. arXiv:2104.13921. Retrieved April 01, 2021, from https://ui.adsabs.harvard.edu/abs/2021arXiv210413921G
[3]Zhou, X., Girdhar, R., Joulin, A., Krahenbuhl, P., & Misra, I. (2022). Detecting Twenty-thousand Classes using Image-level Supervision.
补充思考:
一、为什么用RoI Pooling,不直接resize进行分类?
问:卷积神经网络训练分类问题必须要求输入图像的尺寸固定(因为存在全连接网络),提取出proposal后,可以用RoI pooling得到7x7固定的proposal feature maps,也可以resize得到固定的proposal,两者区别?
答:先对于传统的CNN(如AlexNet和VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的vector or matrix。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:
- 从图像中crop一部分传入网络
- 将图像warp成需要的大小后传入网络
但是crop与warp破坏图像原有结构信息,两种办法的示意图如图,可以看到无论采取那种办法都不好,要么crop后破坏了图像的完整结构,要么warp破坏了图像原始形状信息。

