CNN - nn.Conv1dʹ��
һ��Conv1d �����趨
torch.nn.Conv1d(in_channels, "����ͼ���е�ͨ����"
out_channels, "����������ͨ����"
kernel_size, "�����˵Ĵ�С"
stride, "�����IJ�����Ĭ��ֵ:1"
padding, "���ӵ������������䡣Ĭ��ֵ:0"
dilation, "�ں�Ԫ��֮��ļ�ࡣĬ��ֵ:1"
groups, "������ͨ�������ͨ����������������Ĭ��ֵ:1"
bias, "If True,��������ӿ�ѧϰ��ƫ�Ĭ��:True"
padding_mode "'zeros', 'reflect', 'replicate' �� 'circular'. Ĭ��:'zeros'"
)
in_channels ( int ) �C ����ͼ���е�ͨ����
out_channels ( int ) �C ����������ͨ����
kernel_size ( int or tuple ) �C �����˵Ĵ�С
stride ( int or tuple , optional ) �C �����IJ�����Ĭ��ֵ:1
padding ( int , tuple��str , optional ) �C ���ӵ������������䡣Ĭ��ֵ:0
dilation ( int or tuple , optional ) �C �ں�Ԫ��֮��ļ�ࡣĬ��ֵ:1
groups ( int , optional ) �C ������ͨ�������ͨ����������������Ĭ��ֵ:1
bias ( bool , optional ) �C If True,��������ӿ�ѧϰ��ƫ�Ĭ��:True
padding_mode (�ַ���,��ѡ) �C ��zeros��, ��reflect��, ��replicate����circular��. Ĭ��:��zeros��
����Conv1d ��������Լ�������ά��
input �C
(
minibatch
,
in_channels
,
i
W
)
(\text{minibatch} , \text{in\_channels} , iW)
(minibatch,in_channels,iW) (����С, ���ݵ�ͨ����, ���ݳ���)
output �C
(
minibatch
,
out_channels?
,
i
W
)
(\text{minibatch} , \text{out\_channels } , iW)
(minibatch,out_channels?,iW) (����С, ������ͨ����, ������)
���������:(n - k + 2 * p ) / s + 1
k: �����˴�С,p: ʹ�ñ߽����,s: ������
��������: ( in_channels , k e r n e l _ s i z e , out_channels? ) (\text{in\_channels} , kernel\_size, \text{out\_channels }) (in_channels,kernel_size,out_channels?)
����:out_channelsά��,���������˵ĸ���,������ȡ��ά������
����Conv1d �������
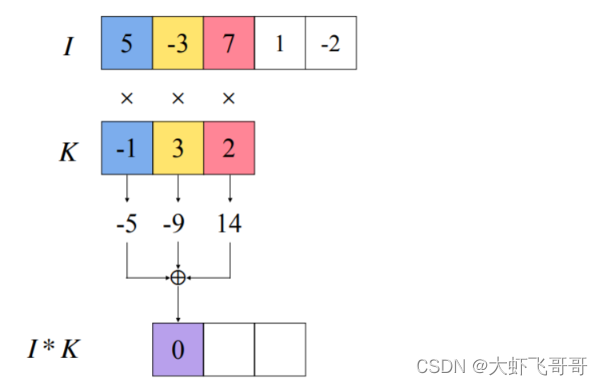
1. ����һ:in_channels=1, out_channels=1
�����������: ����ͨ��:1, ���ͨ��:1,������:1 * 3 * 1,����:1,���:0
����: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 5
import torch
import torch.nn as nn
input = torch.randn(1, 1, 5)
conv = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=0)
out = conv(input)
��һ�ξ�����������:
���ղ�����������ƶ�����:
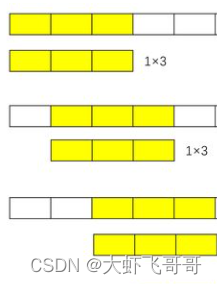
���: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 3
����:

2. ���Զ�:in_channels=1, out_channels=2
�����������: ����ͨ��:1, ���ͨ��:2, ������:1 3 2 (���� 13,��ȡ��ά���� )*, ����:1,���:0
����: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 5
import torch
import torch.nn as nn
input = torch.randn(1, 1, 5)
conv = nn.Conv1d(in_channels=1, out_channels=2, kernel_size=3, stride=1, padding=0)
out = conv(input)
���: ����С:1, ���ݵ�ͨ����:2, ���ݳ���: 3
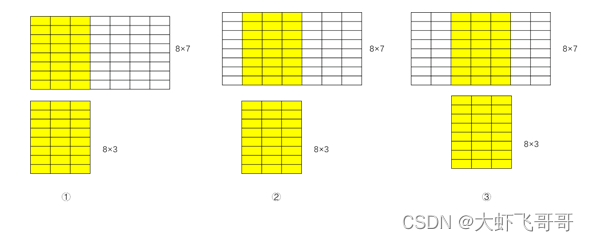
3. ������:in_channels=8, out_channels=1
�����������: ����ͨ��:8, ���ͨ��:1, ������:8 * 3 * 1 , ����:1,���:0
����: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 7
import torch
import torch.nn as nn
input = torch.randn(1, 8, 7)
conv = nn.Conv1d(in_channels=8, out_channels=1, kernel_size=3, stride=1, padding=0)
out = conv(input)
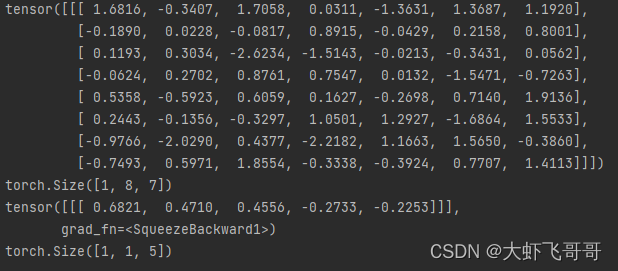
���: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 5
3. ������:in_channels=8, out_channels=2
�����������: ����ͨ��:8, ���ͨ��:1, ������:8 * 3 * 2 , ����:1,���:0
����: ����С:1, ���ݵ�ͨ����:1, ���ݳ���: 7
import torch
import torch.nn as nn
input = torch.randn(1, 8, 7)
conv = nn.Conv1d(in_channels=8, out_channels=2, kernel_size=3, stride=1, padding=0)
out = conv(input)
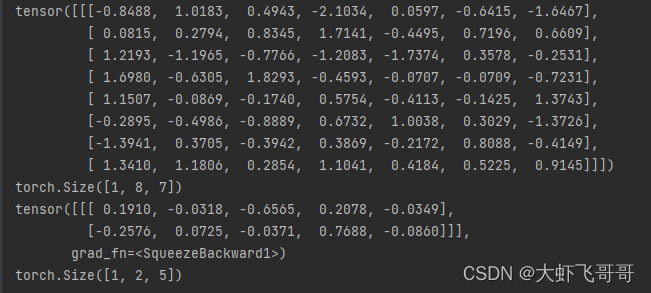
���: ����С:1, ���ݵ�ͨ����:2, ���ݳ���: 5
�ġ�Conv1d ���ı��е�Ӧ�� �C TextCNN
����:Convolutional Neural Networks for Sentence Classification
ģ�Ϳ������ͼ��ʾ��
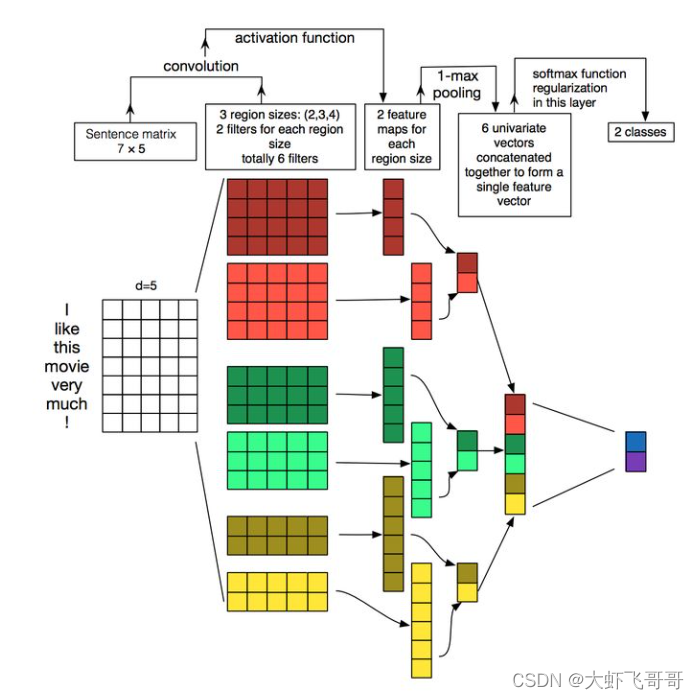
����������Ҫ�Ծ��ӽ��з��ࡣ������ÿ�������� n ά��������ɵ�,Ҳ����˵��������СΪ m*n,����mΪ���ӳ��ȡ� �� pytorch ��,�������Ҿ���,���Ҫ������ά�ȵ���,��(n, m)�� (������ά��, ���ӳ���)
����ͼ��ʾ:����ά����:(5, 7):
import torch
import torch.nn as nn
input = torch.randn(1, 5, 7)
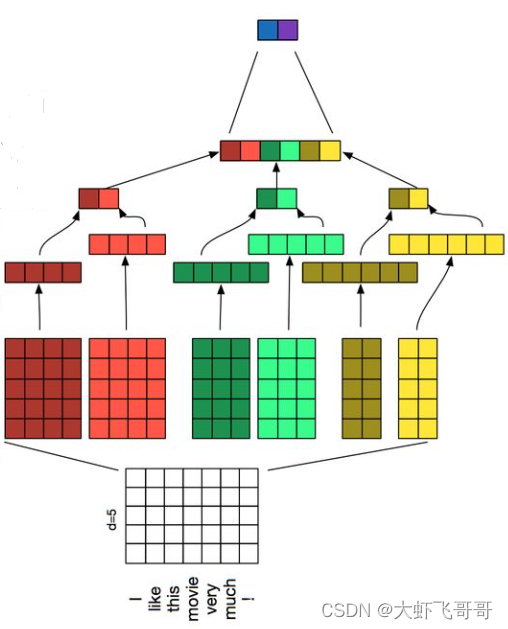
CNN��Ҫ�������������о�������,�����ı�����,�е�������N-gram����ȡ����ʼ�ľֲ�����ԡ�ͼ�й������� kernel_size �ľ���,�ֱ���2,3,4,ÿ�� kernel_size ��������filter(ʵ��ѵ��ʱfilter������ܶ�)���ڲ�ͬ�ʴ���Ӧ�ò�ͬfilter,���յõ�6���������������
�� kernel_size = 4 ��:�������� (5, 4)
import torch
import torch.nn as nn
input = torch.randn(1, 5, 7)
conv = nn.Conv1d(in_channels=5, out_channels=1, kernel_size=4, stride=1, padding=0)
out = conv(input)
���:

Ȼ���ÿһ������������ػ�������ƴ�Ӹ����ػ�ֵ,���յõ�������ӵ�������ʾ,��������������������������з���,��������������̡�

