文章目录
一、NLP文本情感分析概述
通过算法去判断一段文本、评论的情感偏向,从而快速地了解本文原作者的主观情绪。情感分析的结果可以用于舆情监控、信息预测,或用于判断产品的口碑,进而帮助生产者改进产品。(例如:获取一个直播所有评论,为评论标记正负面,然后判断这次直播的效果)。
具体应用还有,电商商品的评论中,差评与提交的文字是否相匹配,如果一个差评匹配的文字情感分析为积极,这种评论的参考价值较低,我们就可以将其展示排序放在偏后面。还有问卷调查中,上万分内容的情感分析。
目前腾讯云和阿里云都有情感分析的API,但目前也只能做到返回正面、中性和反面三种,还不能做到准确判断情绪等级,如将消极评价分为10个等级,如特别消极、消极…,我们可以通过调用这些API,快速得到结果。
目前,网络上有正负面开源语料库,可以用其训练模型。
二、文本情感分析难点
- 文本特征较难提取,文字讨论的主题可能是人、商品、事件
- 文本较难规范化
- 词与词之前有联系,关联关系纳入模型中不容易
- 不带情感色彩的停用词会影响文本情感打分,‘打开天窗说亮化’
- 中文复杂,一个词在不同语境下可能表达完全不一样的情感含义,夏天能穿多少穿多少。
- 不同语义差别巨大,比如‘路上小心点’
- 否定词的存在‘我其实不是很喜欢你’
- 互联网新词‘SKR’
- 多维情绪识别(发烧友,喜欢级等,对情绪评级)目前还没有完美的方案
三、具体方法与实现步骤
1、情感词典
第一种方法是通过句子中是否包含正负面词汇去判断这句话是积极的还是消极的,但在中文的语言环境中会存在一些问题,所以目前情感分析基本不会采用此种方法。根据已有的词典,对不同的词定义情感,具体例子如下:

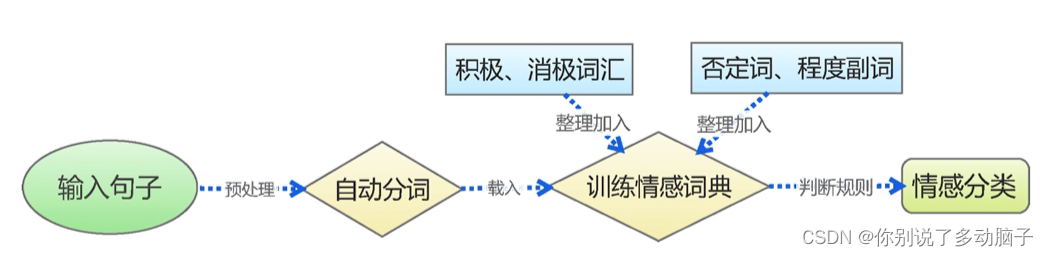
这种方法主要有如下缺点:
- 质量良好的中文情感词典非常少
- 不带情感的停用词会影响情感打分
- 中文博大精神,词性的多变影响准确性
- 无法结合上下文分析情感
2、高纬向量模型
1》概述
这一模型结合机器学习或深度学习算法,通过网络公开语料库或者个人预料数据,进行模型的训练。首先,将正负面预料分词,然后将分词词汇映射到高维向量空间中,将词语向量化(此处也用到神经网络训练),然后用向量化后的数据进行模型的训练。最后,将需要预测的数据放入训练好的模型并得出结果。
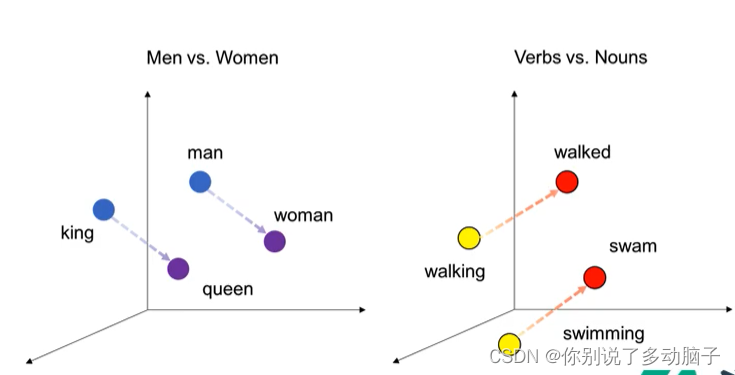
优势:
- 解决了多维语义问题;
- 可利用强大的机器学习,深度学习模型
2》具体步骤如下:
1) jieba分词
通过python中jieba分词库,对预料进行分词。jieba分词是国内分词技术做的比较好的库,其创立的目的起初是为搜索引擎分词检索功能创立。
2) Word2Vec介绍(核心:浅层神经网络相关)
腾讯有词向量包,腾讯词向量包本质上就是腾讯提供的一个 词语->向量 一一对应的数据包。(这样可以避免实时数据的改变所造成的,每一条数据都会对向量维度造成影响)。
-
google出品
-
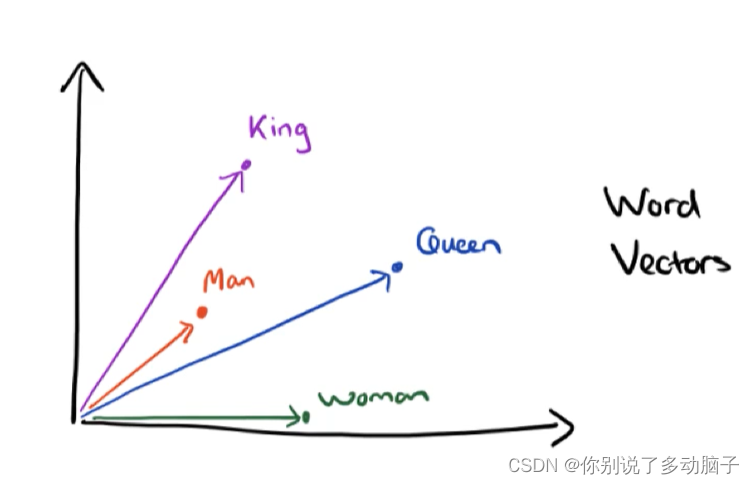
利用高维向量表征词语
-
把相近的词语放在相近的位置
-
语料库输入,输出向量空间
3)情感分析模型
根据特征值的情感分析模型包括很多,如SVM模型、朴素贝叶斯模型、KNN模型
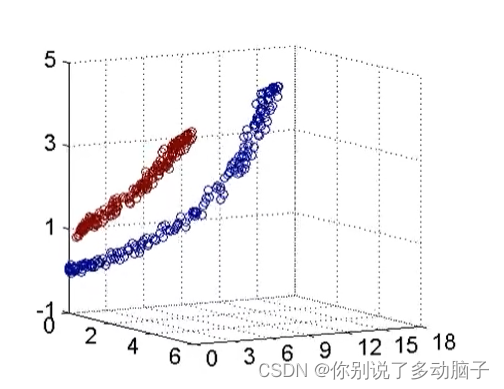
a、SVM模型
-
有词向量就可以使用相关模型进行情感分析
-
机器学习SVM:二维分类,小数据集效果好
import jieba
import numpy as np
import pandas as pd
neg = pd.read_excel('data/neg.xls',header=None) # 读取负面语句库
pos = pd.read_excel('data/pos.xls',header=None) # 读取正面语句库
# 对正负面语料库中每一个句子进行分词
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x))
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x))
x = np.concatenate((pos['words'],neg['words'])) # 将分好词的语料库进行合并(x变量的预处理部分)
y = np.concatenate((np.ones(len(pos)),np.zero(len(neg)))) # 将添加每个正负面预料的负面判定,积极判定为1,消极判定为0
from gensim.models.word2vec import Word2Vec
w2v = Word2Vec(size=300, min_count=10) # size是维度,min_count是表示某一词最少出现的次数(才被计入)
w2v.build_vocab(x) # 建立高维向量空间
w2v.train(x, total_examples=w2v.corpus_count, epochs=w2v.iter) #训练高维向量空间下,词转为词向量的值(底层也是包括一些神经网络的训练)
w2v.wv['我'] # 查看以下‘我’这个字的词向量是什么
# 到目前位置,上面步骤只是得到每个词的向量,没有计算出每个句子的向量,于是下面部分,将每个每个词向量相加合并得到每个句子的向量
def total_vec(words):
vec = np.zeros(300).reshape(1,300)
for word in words:
try:
vec += w2v.wv[word].reshape((1,300))
except KeyError:
continue
return vec
vectrain_vec = np.contatenate([total_vec(words) for words in x]) # 将所有句向量合并为数组
from sklearn.externals import joblib
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
model = SVC(kernel='rbf',verbose=True) #‘rbf’为其中一种核方法
model.fit(train_vec,y) #训练模型
上面内容包括模型的训练过程,也可以直接导入训练好的模型进行运算,如下:
model = joblib.load('data/svm_model.pkl') # pkl是一个二级制python保存文件
def total_vec(words):
#读取 Word2Vec 模型
w2v = Word2Vec.load('data/w2v_model.pkl')
vec np.zeros(300).reshape((1,300))
for word in words:
try:
vec += w2v.wv[word].reshape((1,300))
except KeyError:
continue
return vec# 对实验楼评论进行情感分析
def svm_predict():
#读取实验楼评论
df = pd.read_csv("comments.csv")
#读取支持向量机模型
model =joblib.load('data/svm_model.pkl')
comment_sentiment =[]
for string in df['评论内容']:
#对评论分词
words = jieba.lcut(str(string))
words_vec =total.vec(words)
result = model.predict(words_vec)
comment_sentiment.append('积极' if int(result[0]) else '消极')
# 实时返回积极或消极结果
if int(result[0]) == 1:
print(string, '【积极】')
else:
print(string, '【消极】')df =pd.read_csv('comments.csv')
svm_predict()
b、LSTM模型
LSTM模型:设计一个记忆细胞,具备选择性记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。(而RNN算法是想把所有信息都记住,不管是有用的信息还是没用的信息)
- 神经网络模型LSTM:记忆能力,挑选必要的信息进行传递
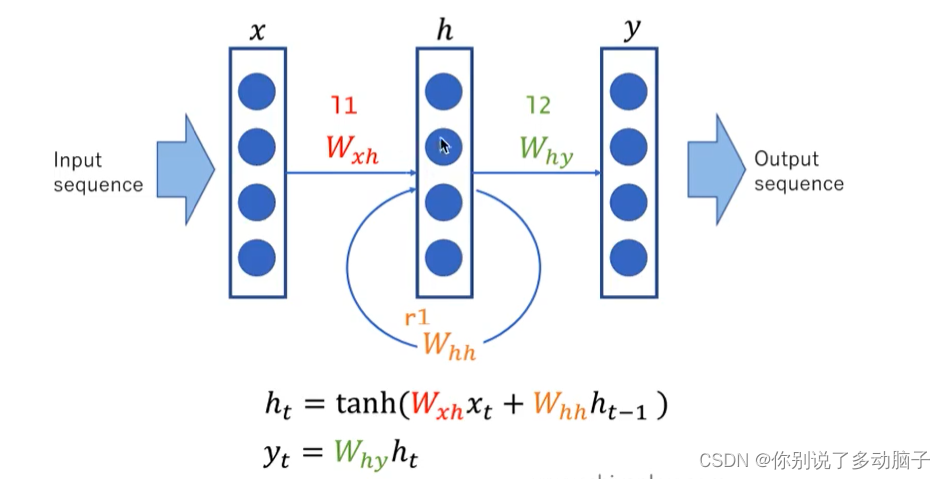
import torch
rnn = torch.nn.LSTM(10,20,2)
input = torch.randn(5,3,10)
h0 = torch.randn(2,3,20)
c0 = torch.randn(2,3,20)
output,(hn,cn) = rnn(input, (h0,c0))
四、调用百度API第三方服务
可以直接用sdk,调用sentimentClassify,需要百度云申请的账号。
baidu-aip模型是基于购物消费类数据训练的,所以如果适用场景不是模型的训练场景那么便可能不适用。
# pip install baidu-aip
import aip
client_appid = ''
client_ak = ''
client_sk = ''
mt_txt = ''
my_nlp = aip.nlp.sentimentClassify(client_appid, client_ak, client_sk)
print(my_nlp.sentimentClassify(my_txt))
参考资料:
https://zhuanlan.zhihu.com/p/83496936
https://www.bilibili.com/video/BV16t411d7ZY?spm_id_from=333.337.search-card.all.click
图片来源:上述视频和https://www.bilibili.com/video/BV1sa411m7m9?spm_id_from=333.1007.top_right_bar_window_history.content.click

