Abstract
结肠镜检查是一个黄金标准,但高度依赖操作者。自动息肉分割可以最大限度地减少漏诊率,并在早期阶段及时治疗结肠癌。即使有为这项任务开发的深度学习方法,但息肉大小的变化会影响模型的训练,从而将其限制在训练数据集中大多数样本的大小属性上,可能会给不同大小的息肉提供次优结果。在这项工作中,我们在训练过程中以文本注意力的形式利用与尺寸相关和息肉数量相关的特征。我们引入了一个辅助的分类任务,对基于文本的嵌入进行加权,使网络能够学习额外的特征表征,能够明显适应不同大小的息肉,并能够适应有多个息肉的情况。我们的实验结果表明,与最先进的分割方法相比,这些增加的文本嵌入提高了模型的整体性能。我们探索了四个不同的数据集,并提供了针对具体尺寸的改进意见。我们提出的文本引导的注意力网络(TGANet)可以很好地概括不同数据集中不同大小的息肉。
I. Network Architecture
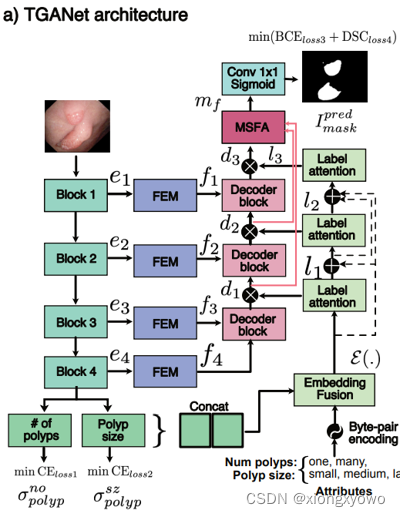
本文的息肉分割网络算是比较复杂的一类。具体来说,主要引入了以下几个模块:
接下来我们分别对其分析。
II. Encoder
采用预训练的resnet50作为backbone(而非息肉分割任务中常见的res2net)。需要注意的是,本文似乎去掉了resnet最后一个encoder block;此外,该encoder还承担了两个额外的任务。一个是二分类,判断图像中息肉的数量(单个/多个);另一个是三分类,判断图像中息肉的大小(小,中,大)。
不过,本文并未阐明监督分类任务所需的标签从何获得,笔者猜测可能需要人工标注,感兴趣的读者可以研究其开源代码进行分析。
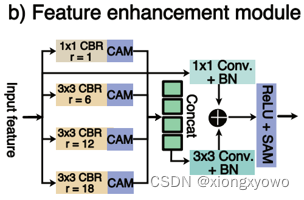
III. Feature Enhancement Module
对encoder获得的特征进行进一步的增强处理。这一模块可以说是非常常见了,基本每个做分割的都要设计个类似attention的东西处理特征:
IV. Label Attention
该模块是本文思想的核心。具体来说,是文中的这一部分:
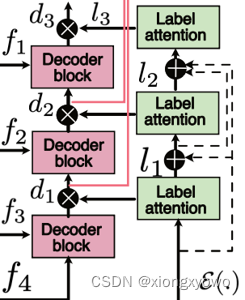
结构事实上比较复杂,因此我们这里只介绍思想。首先引入一个语义类别(Semantic Class)的概念,即,如果对息肉执行一个分类任务,那么各图像大致可以分为五类:单息肉,多息肉,小息肉,中息肉,大息肉。这一类别可以通过上文的分类获得。现在,实际上就出现了一个隐含的类别不均衡问题。如果一个模型在大息肉上表现很好,但在小息肉上表现不佳,可能有多种原因,比如说小息肉的特征比较难学,又或者小息肉的样本数量很小…那这个时候,我们就可以利用attention思想,对这种"目前学习不足"的特征进行重点学习,从而提升整体的性能。之前获得的个图像样本的语义类别统计信息就可以为这一过程提供指导,此所谓"Text-Guided Attention"。
V. Multi-Scale Feature Aggregation
也算是分割任务中十分经典的多级特征融合,这里不进行赘述:

VI. Experiment
需要注意的是,本文所用的数据集和"主流息肉分割论文"并不相同,为Kvasir-SEG,CVCClinicDB,BKAI,Kvasir-Sessile。注意Kvasir-Sessile实际上是Kvasir-SEG的一个子集,因此实际上只用了三个数据集。此外,对比的方法也为较旧的方法,作为一篇2022年的论文,并未对比21年的sota息肉分割方法。

