БОЦЊЪЧБШНЯМђЕЅЕФЛљДЁИХФю,ИеШыУХЕФХѓгбПЩФмЪЧашвЊЕФЁЃ

|

|
ЪзЯШ,ЮвУЧвЊНщЩмЯТетШ§ИіИХФюЁЃ
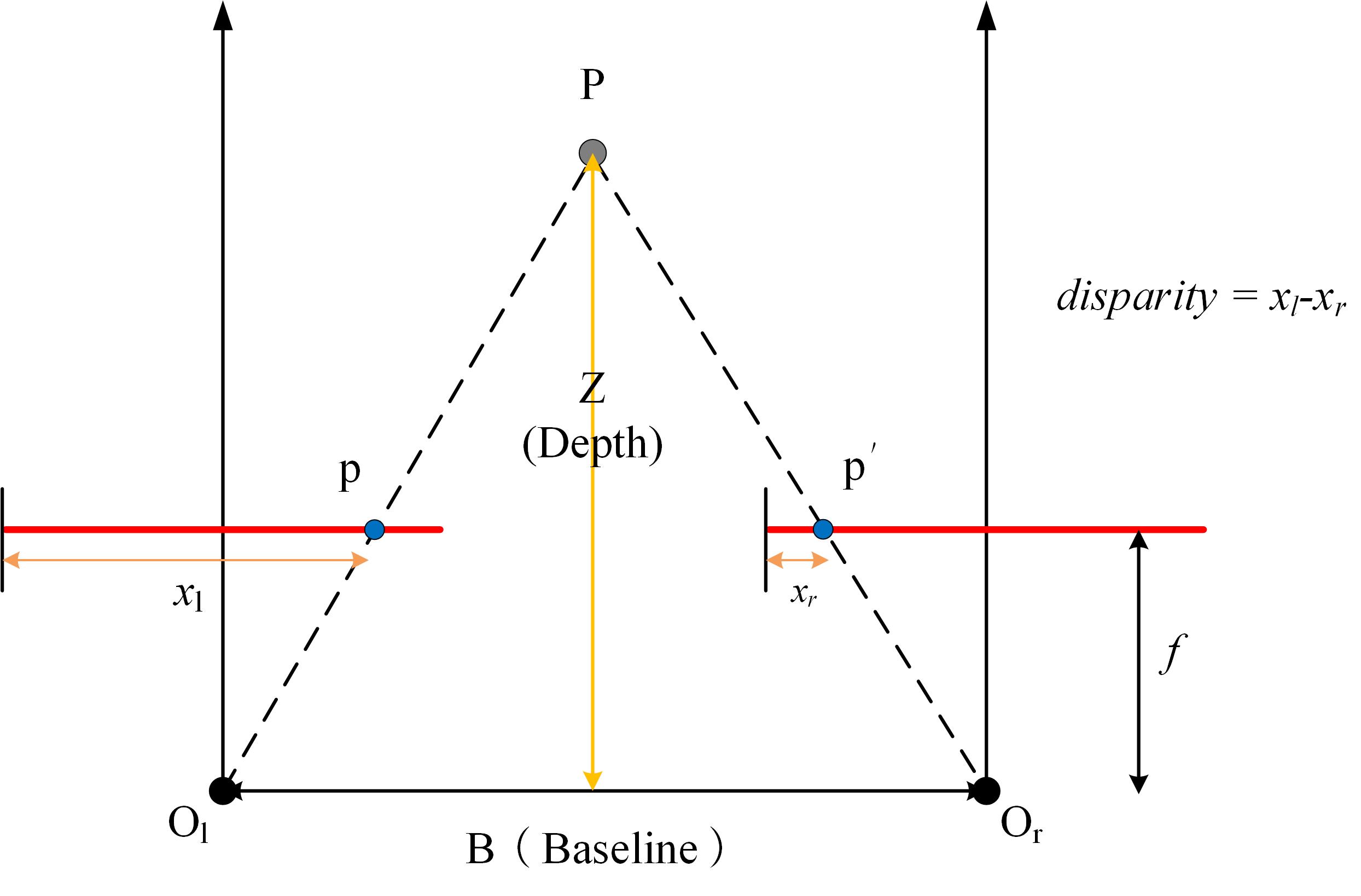
ЪгВю(disparity)
ЪгВю
d
d
d ЕШгкЭЌУћЕуЖддкзѓЪгЭМЕФСазјБъМѕШЅдкгвЪгЭМЩЯЕФСазјБъ,ЪЧЯёЫиЕЅЮЛ
d
=
x
l
?
x
r
d=x_l-x_r
d=xl??xr?СЂЬхЪгОѕРя,ЪгВюИХФюдкМЋЯпаЃе§КѓЕФЯёЖдРяЪЙгУЁЃ
ЩюЖШ(depth)
ЩюЖШDЕШгкЯёЫидкИУЪгЭМЯрЛњзјБъЯЕЯТ Z Z ZзјБъ,ЪЧПеМфЕЅЮЛЁЃЩюЖШВЂВЛЬидкаЃе§КѓЕФЭМЯёЖдРяЪЙгУ,ЖјЪЧШЮвтЭМЯёЖМПЩЛёШЁЩюЖШЭМЁЃ
ЪгВюЭМ(disparity map)
ЪгВюЭМжИДцДЂСЂЬхаЃе§КѓЕЅЪгЭМЫљгаЯёЫиЪгВюжЕЕФЖўЮЌЭМЯёЁЃ
- ЪгВюЭМЪЧвЛеХЖўЮЌЭМЯё,КЭдЭМЕШДѓаЁ
- ЪгВюЭМУПИіЮЛжУБЃДцЕФвдЯёЫиЮЊЕЅЮЛЕФИУЮЛжУЯёЫиЕФЪгВюжЕ
- вдзѓЪгЭМЪгВюЭМЮЊР§,дкЯёЫиЮЛжУpЕФЪгВюжЕЕШгкИУЯёЫидкгвЭМЩЯЕФЦЅХфЕуЕФСазјБъМѕШЅЦфдкзѓЭМЩЯЕФСазјБъ
ЩюЖШЭМ(depth map)
ЩюЖШЭМжИДцДЂЕЅЪгЭМЫљгаЯёЫиЕФЩюЖШжЕЕФЖўЮЌЭМЯё,ЪЧПеМфЕЅЮЛ,БШШчКСУзЁЃ
- ЩюЖШЭМЪЧвЛеХЖўЮЌЭМЯё,КЭдЭМЕШДѓаЁ,вВОЭКЭЪгВюЭМЕШДѓаЁ
- ЩюЖШЭМУПИіЮЛжУБЃДцЕФЪЧИУЮЛжУЯёЫиЕФЩюЖШжЕ
- ЩюЖШжЕОЭЪЧЯрЛњзјБъЯЕЯТЕФZзјБъжЕ
ЕудЦ(point cloud)
ЕудЦжИШ§ЮЌПеМфЕФШ§ЮЌЕуМЏКЯ,зјБъЪєад( X , Y , Z X,Y,Z X,Y,Z),ЗЈЯпЪєад( N x , N y , N z N_x,N_y,N_z Nx?,Ny?,Nz?)(ПЩбЁ),беЩЋЪєад( R , G , B R,G,B R,G,B)(ПЩбЁ)
ЦфДЮ,ЮЊЪВУДЛсгаЪгВюЭМКЭЩюЖШЭМФи?
ЮвУЧжЊЕР,СЂЬхЦЅХфвЛАуЪЧжИж№ЯёЫиЕФГэУмЦЅХф,етвтЮЖзХУПИіЯёЫиЖМЛсЕУЕНвЛИіЪгВюжЕ(АќРЈЮоаЇжЕ),ШчКЮДцДЂетаЉЪгВюжЕФи,ЯдШЛвдЖўЮЌЭМЕФЗНЪНДцДЂЪЧКмКЯЪЪЕФ,зюДѓЕФСНЕугХЪЦЪЧвЛЗНУцПЩвдЭЈЙ§ЯёЫизјБъПьЫйЕФдкЖўЮЌЭМжаевЕНЖдгІЮЛжУЕФЪгВюжЕ,ЖјЧвКЭЭМЯёвЛбљЪЧгаађЕФ,СкгђМьЫїЁЂЪгВюТЫВЈЕШНЋЛсБфЕУЗЧГЃЗНБу;СэвЛЗНУцЪЧПЩвджБЙлЕФЭЈЙ§ЙлВьЪгВюЭМКЭдЭМЕФЖдБШ,ЖдЪгВюЭМЕФжЪСПгаГѕВНЕФХаЖЈЁЃ
ЖјЩюЖШЭМЕФвтвхдђЪЧвдИќЩйЕФДцДЂПеМфЁЂгаађЕФБэДяЭМЯёЦЅХфЕФШ§ЮЌГЩЙћЁЃИќЩйЕФДцДЂПеМфЪЧвђЮЊжЛБЃДцСЫвЛИіЩюЖШжЕ,ЖјВЛЪЧШ§ЮЌЕудЦЕФШ§ИізјБъжЕ,ЖјЩюЖШжЕЪЧПЩвдНсКЯЯёЫизјБъМЦЫуШ§ЮЌЕузјБъжЕЕФЁЃгаађЪЧвђЮЊЩюЖШЭМКЭдЭМЯёЫиЪЧвЛвЛЖдгІЕФ,ЫљвддЭМЕФСкгђаХЯЂЭъШЋМЬГаЕНСЫЩюЖШЭМРяЁЃ
етОЭЪЧЪгВюЭМКЭЩюЖШЭМЕФвтвх,ЪгВюЭМЪЧСЂЬхЦЅХфЫуЗЈЕФВњГі,ЖјЩюЖШЭМдђЪЧСЂЬхЦЅХфЕНЕудЦЩњГЩЕФжаМфЧХСКЁЃ
ЪгВюЭМКЭЩюЖШЭМжаМф,газХвЛЖдвЛЕФзЊЛЛЙЋЪН:
D
=
B
f
d
+
(
x
0
r
?
x
0
l
)
D=\frac {Bf}{d+(x_{0r}-x_{0l})}
D=d+(x0r??x0l?)Bf?
Цфжа,
D
D
DЮЊЩюЖШ,
d
d
dЮЊЪгВю,
B
B
BЮЊЛљЯпГЄЖШ,
f
f
fЮЊНЙОр(ЯёЫиЕЅЮЛ),
x
0
l
x_{0l}
x0l?КЭ
x
0
r
x_{0r}
x0r?ЗжБ№ЮЊзѓгвЪгЭМжїЕуЕФСазјБъЁЃ,СэвЛИіНЯЮЊЪьжЊЕФЙЋЪНЪЧ
D
=
B
f
d
D=\frac {Bf}{d}
D=dBf?
етЪЧдкзѓгвЪгЭМжїЕуЕФСазјБъЯрЭЌЕФЬиЪтЧщПі,БШШчжїЕуЖМдкжааФЁЃ
ЩюЖШЭММЦЫуЯрЛњзјБъЯЕЯТЕФЕудЦ,вВгазХМђЕЅЕФЙЋЪН:
Z
=
D
X
=
D
(
x
?
x
0
l
)
f
Y
=
D
(
y
?
y
0
l
)
f
\begin{aligned} Z &= D\\ X &= \frac {D(x-x_{0l})}{f}\\ Y &= \frac {D(y-y_{0l})}{f} \end{aligned}
ZXY?=D=fD(x?x0l?)?=fD(y?y0l?)??
Цфжа,
x
,
y
x,y
x,yЮЊЯёЫиЕФСазјБъКЭаазјБъ,
x
0
l
x_{0l}
x0l?КЭ
y
0
l
y_{0l}
y0l?ЮЊжїЕуЕФЯёЫизјБъЁЃ
ГЃМћЮЪД№:
ЮЪ:ЮЊЪВУДЮвДг.pngИёЪНЕФЪгВюЭМРяЖСШЁЕНЕФЪгВюжЕКЭецЪЕжЕгаКмДѓВювь?
Д№: ЮвУЧвЊЯШИуЧхГў,ЪгВюЭМЪЧШчКЮДцДЂЕФЁЃЭЈГЃЖјбд,ЮвУЧЪЧАбЖўЮЌЪгВюЭМвдЭМЯёИёЪНДцДЂ,ГЃМћЕФИёЪНгаpngЁЂtifЁЂpfmЕШ,ЕЋетаЉЭМЯёИёЪНДцДЂЕФЪ§ОнРраЭЪЧгаЧјБ№ЕФ,ЦфжаpngжЛФмДцДЂећЪ§,ЖјtifКЭpfmдђПЩвдДцДЂаЁЪ§ЁЃЖјЯдШЛзМШЗЕФЪгВюжЕБиШЛЪЧИЁЕуаЭЕФаЁЪ§,ЫљвдДцДЂЮЊtifКЭpfmПЩвдджЕЮоЫ№ДцДЂ,ЖјДцДЂЮЊpngБиШЛЛсЫ№ЪЇОЋЖШ,ЫљвдгаЕФДњТыБШШчopencvЛсАбЕУЕНЕФИЁЕуаЭЪгВюжЕГЫвд16БЖШЁећ,ДцДЂЕНpngРя,етбљДцДЂЪгВюжЕЕФОЋЖШБфЮЊ1/16,ЖдгкетжжЧщПіЮвУЧдкЖСШЁpngКѓвЊЯШГ§вд16ВХЪЧецЪЕЪгВюжЕ,ЧвЪгВюЛсгаНзЬнЗжВуЯжЯѓЁЃ
ФЧгаЭЌбЇОЭЮЪ,МШШЛетбљЮЊЪВУДвЊДцДЂpngФи?ЪЧвђЮЊФПЧАжїСїЕФЭМЯёШэМў,ВЛжЇГжжБНгПДИЁЕуИёЪНЕФtifКЭpfm,ДцДЂЮЊpngПЩвдИќКУЕФЙлПДЪгВюЭМ,ЕБШЛвЊЪЧЪЕМЪЩњВњЪЙгУ,ЪЧБиШЛВЛНЈвщДцДЂЮЊpngЕФ,гУРДВщПДЪгВюНсЙћЪЧПЩвдЕФЁЃ
ЛЙгаШЫЛсжБНгАбЪгВюжЕРЩьЛђепбЙЫѕЕН0~255,ДцДЂЕНpngЛђbmpЕШДцДЂећЪ§ЕФИёЪНжа,етбљЕФЪгВюЭМжЛФмгУРДЙлПДЪгВюаЇЙћ,УЛгаЦфЫћзїгУ,БШШчЮвЕФДњТыРяЕФДцДЂЗНЪНЁЃ
ЮЪ:МЋЯпЯёЖдЯТЕФЩюЖШЭМКЭдЭМЕФЩюЖШЭМЪЧвЛбљЕФТ№?ШчКЮзЊЛЛ?
Д№: ВЛвЛбљ,вђЮЊЩюЖШЭМЪЧдкЪгЭМЫљдкЕФЯрЛњзјБъЯЕЯТЕФ,ЫљвдКЭЯрЛњзјБъЯЕЧПЙвЙГ,МЋЯоаЃе§КѓЕФзѓЪгЭМКЭдЪМЕФзѓЪгЭМЪЧВЛвЛбљЕФЯрЛњзјБъЯЕ,ЫљвдЫќУЧЕФЩюЖШЭМЪЧВЛвЛбљЕФЁЃ
- ЖдгкМЋЯпЯёЖдзѓЪгЭМФГЯёЫи p p p,ЭЈЙ§ЕЅгІБфЛЛ H H H зЊЛЛЕНдзѓЪгЭМЩЯ,ЕУЕНдЭМЩЯЕФЯёЫизјБъ q q qЁЃ
- НЋ p p pЕФЯрЛњзјБъЯЕзјБъЭЈЙ§вЛИіа§зЊ R R R БфЛЛЕНдзѓЪгЭМЕФЯрЛњзјБъЯЕзјБъ,ЕУЕН q q q ЕФЩюЖШЁЃ
- H H HКЭ R R RдкМЋЯпаЃе§ВНжшПЩвдЛёШЁ(МЋЯпаЃе§ЕФБиШЛВњГі)ЁЃ

