目录
1、如何对数据进行分类和预测?
- 人工智能就是利用数学统计方法,统计数据中的规律,然后利用这些统计规律进行自动化数据处理,使计算机表现出某种智能的特性,而各种数学统计方法,就是大数据算法。
KNN 分类算法
- KNN 算法,即 K 近邻(K Nearest Neighbour)算法,是一种基本的分类算法。其主要原理是:对于一个需要分类的数据,将其和一组已经分类标注好的样本集合进行比较,得到距离最近的 K 个样本,K 个样本最多归属的类别,就是这个需要分类数据的类别。
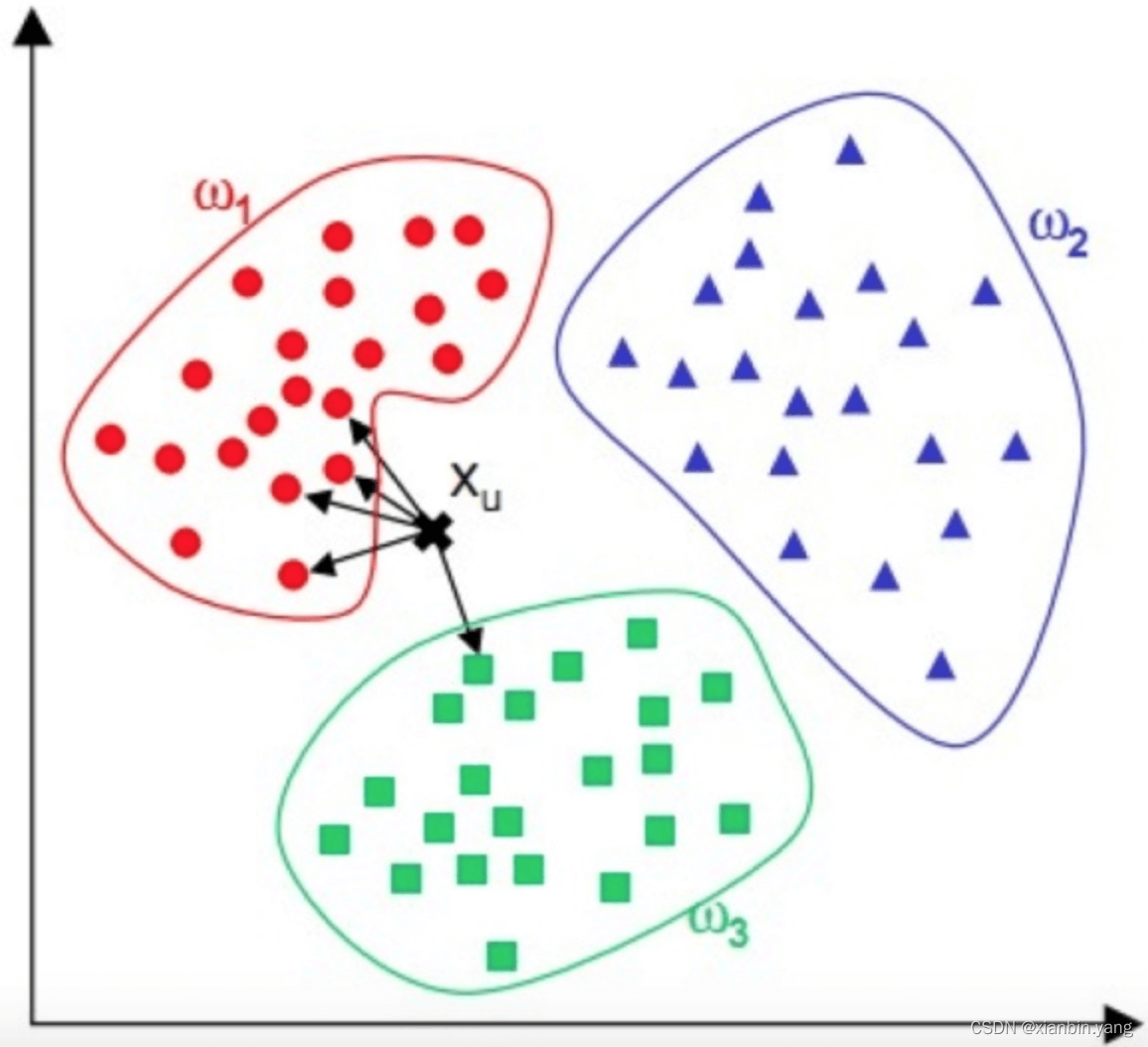
?
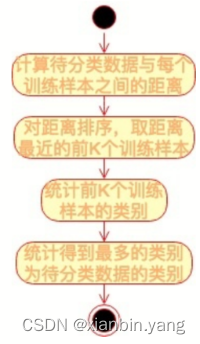
- KNN 的算法流程图?
- ? ?
?
- 新闻分类:可以提前对若干新闻进行人工标注,标好新闻类别,计算好特征向量。对于一篇未分类的新闻,计算其特征向量后,跟所有已标注新闻进行距离计算,然后进一步利用 KNN 算法进行自动分类。
数据的距离
- 提取数据的特征值,根据特征值组成一个 n 维实数向量空间(这个空间也被称作特征空间),然后计算向量之间的空间距离
- 空间之间的距离计算方法:欧氏距离、余弦距离
- 对于数据 xi 和 xj,若其特征空间为 n 维实数向量空间 Rn,即 xi=(xi1,xi2,…,xin),xj=(xj1,xj2,…,xjn),则其欧氏距离计算公式为
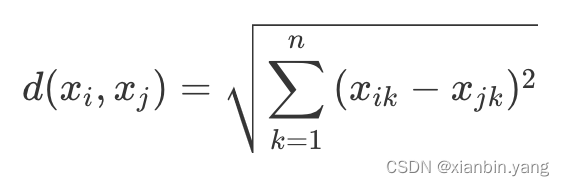
?

?
- 余弦相似度其实是计算向量的夹角,而欧氏距离公式是计算空间距离。余弦相似度更关注数据的相似性(适合文本数据)。余弦相似度的值越接近 1 表示其越相似,越接近 0 表示其差异越大。
- 比如两篇文章的特征值都是:“大数据”“机器学习”和“极客时间”,A 文章的特征向量为(3, 3, 3),即这三个词出现次数都是 3;B 文章的特征向量为(6, 6, 6),即这三个词出现次数都是 6。如果光看特征向量,这两个向量差别很大,如果用欧氏距离计算确实也很大,但是这两篇文章其实非常相似,只是篇幅不同而已,它们的余弦相似度(向量夹角)为 1,表示非常相似。
文本的特征值
- 文本数据的特征值就是提取文本关键词,TF-IDF 算法是比较常用且直观的一种文本关键词提取算法。这种算法是由 TF 和 IDF 两部分构成。
- TD-IDF:如果一个词在某一个文档中频繁出现,但在所有文档中却很少出现,那么这个词很可能就是这个文档的关键词
- TF 是词频(Term Frequency),表示某个单词在文档中出现的频率

?
- IDF 是逆文档频率(Inverse Document Frequency),表示这个单词在所有文档中的稀缺程度,越少文档出现这个词,IDF 值越高。

?
- TF 与 IDF 的乘积就是 TF-IDF
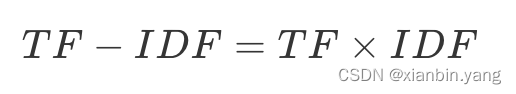
?
- 提取出关键词以后,就可以利用关键词的词频构造特征向量,比如上面例子关于原子能的文章,“核裂变”“放射性”“半衰期”这三个词是特征值,分别出现次数为 12、9、4。那么这篇文章的特征向量就是(12, 9, 4),再利用前面提到的空间距离计算公式计算与其他文档的距离,结合 KNN 算法就可以实现文档的自动分类。
贝叶斯分类
- 条件概率:是指事件A在另外一个事件B已经发生条件下的发生概率。条件概率 表示为:P(A|B),读作“A在B发生的条件下发生的概率”。条件概率可以用决策树进行计算。若只有两个事件A,B,那么:

?
- **贝叶斯公式:**用以描述在已知条件下某事件的发生概率
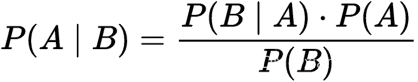
?
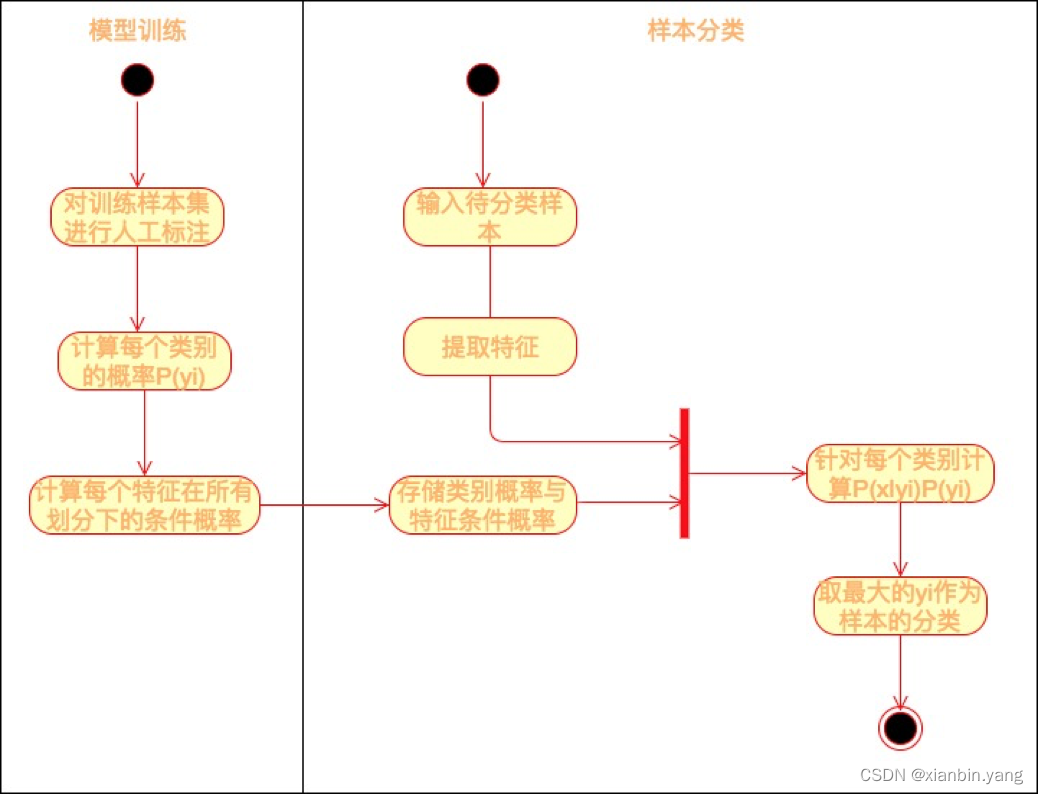
- 贝叶斯分类的算法流程图
?
2、如何发掘数据之间的关系?
搜索排序
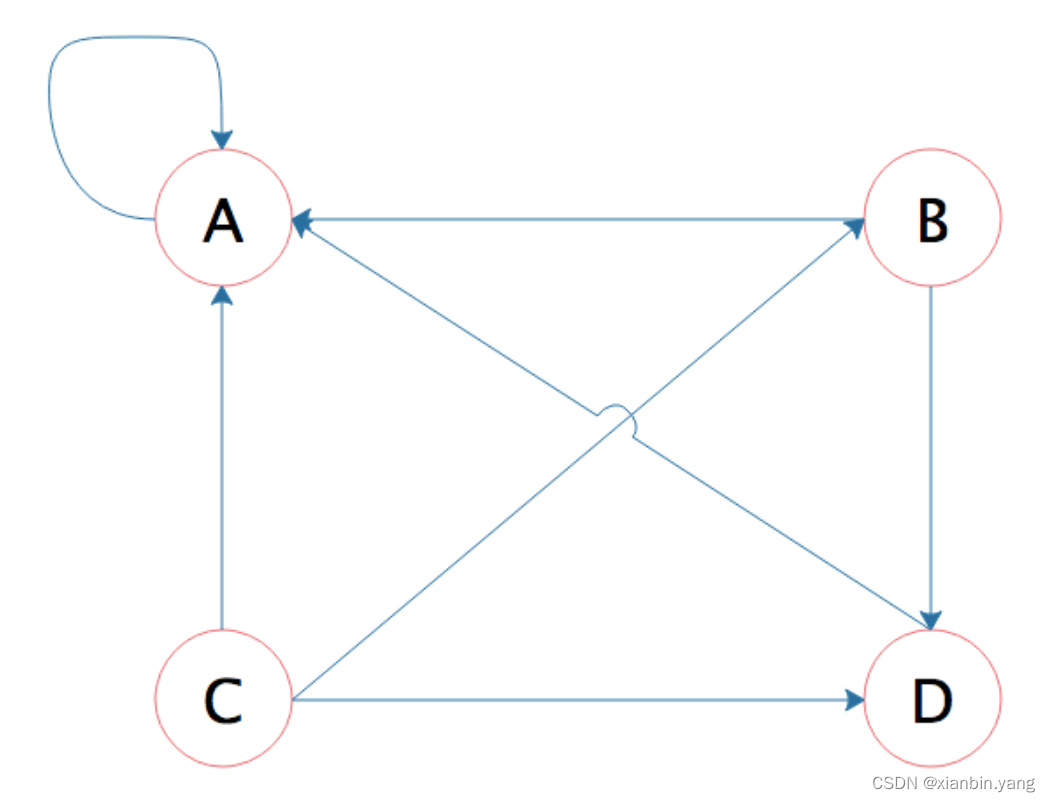
- PageRank:根据网页的链接关系给网页打分
- B 网页包含了 A、D 两个页面的超链接,相当于 B 网页给 A、D 每个页面投了一票,初始的时候,所有页面都是 1 分,那么经过这次投票后,B 给了 A 和 D 每个页面 1/2 分;这样经过一次计算后,每个页面的 PageRank 分值就会重新分配,重复同样的算法过程,经过几次计算后,根据每个页面 PageRank 分值进行排序,就得到一个页面重要程度的排名表。
- 浏览一个页面的时候,有一定概率不是点击超链接,而是在地址栏输入一个 URL 访问其他页面,(1?α) 就是跳转到其他任何页面的概率,通常取经验值 0.15(即 α 为 0.85)
?
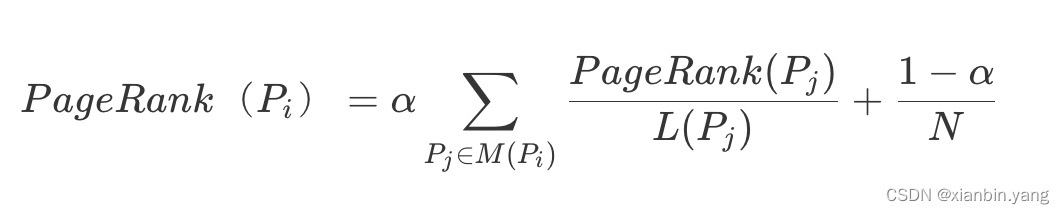
?
- 公式中,Pj∈M(Pi) 表示所有包含有 Pi 超链接的 Pj,L(Pj) 表示 Pj 页面包含的超链接数,N 表示所有的网页总和
关联分析
- 通过商品订单,可以发现频繁出现在同一个购物篮里商品间的关联关系,这种大数据关联分析也被称作是“购物篮分析”,频繁出现的商品组合也被称作是“频繁模式”。
- 支持度是指一组频繁模式的出现概率,比如(啤酒,尿不湿)是一组频繁模式,它的支持度是 4%,也就是说,在所有订单中,同时出现啤酒和尿不湿这两件商品的概率是 4%。
- 置信度用于衡量频繁模式内部的关联关系,如果出现尿不湿的订单全部都包含啤酒,那么就可以说购买尿不湿后购买啤酒的置信度是 100%;如果出现啤酒的订单中有 20% 包含尿不湿,那么就可以说购买啤酒后购买尿不湿的置信度是 20%。
- 大型超市的商品种类数量数以万计,所有商品的组合更是一个天文数字
- Apriori 算法:寻找到最小支持度的频繁模式;Apriori 算法极大地降低了需要计算的商品组合数目;这个算法的原理是,如果一个商品组合不满足最小支持度,那么所有包含这个商品组合的其他商品组合也不满足最小支持度。所以从最小商品组合,也就是一件商品开始计算最小支持度,逐渐迭代,进而筛选出所有满足最小支持度的频繁模式。
聚类
- 聚类就是对一批数据进行自动归类
- K-means 是一种在给定分组个数(K)后,能够对数据进行自动聚类(根据距离)的算法
- 1、设点:随机在图中取 K 个种子点,图中 K=2,即图中的实心小圆点;
- 2、分类:求图中所有点到这 K 个种子点的距离,假如一个点离种子点 X 最近,那么这个点属于 X 点群
- 3、重新设点:对已经分好组的两组数据,分别求其中心点。对于图中二维平面上的数据,求中心点最简单暴力的算法就是对当前同一个分组中所有点的 X 坐标和 Y 坐标分别求平均值(means),得到的就是中心点。
- 4、重复第 2 步和第 3 步,直到每个分组的中心点不再移动。这时候,距每个中心点最近的点数据聚类为同一组数据。
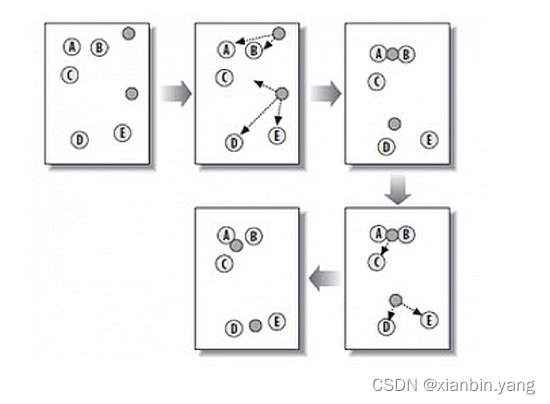
?
- 应用:具有相似购买习惯的用户群体被聚类为一组
3、如何预测用户的爱好?
- 基于人口统计的推荐:人口属性分类
- 基于商品属性的推荐:商品属性分类
- 基于用户的协同过滤推荐:相似的爱好
- 基于商品的协同过滤推荐:多个商品被同时喜欢的次数多
基于人口统计的推荐
- 根据用户的基本信息进行分类,然后将商品推荐给同类用户
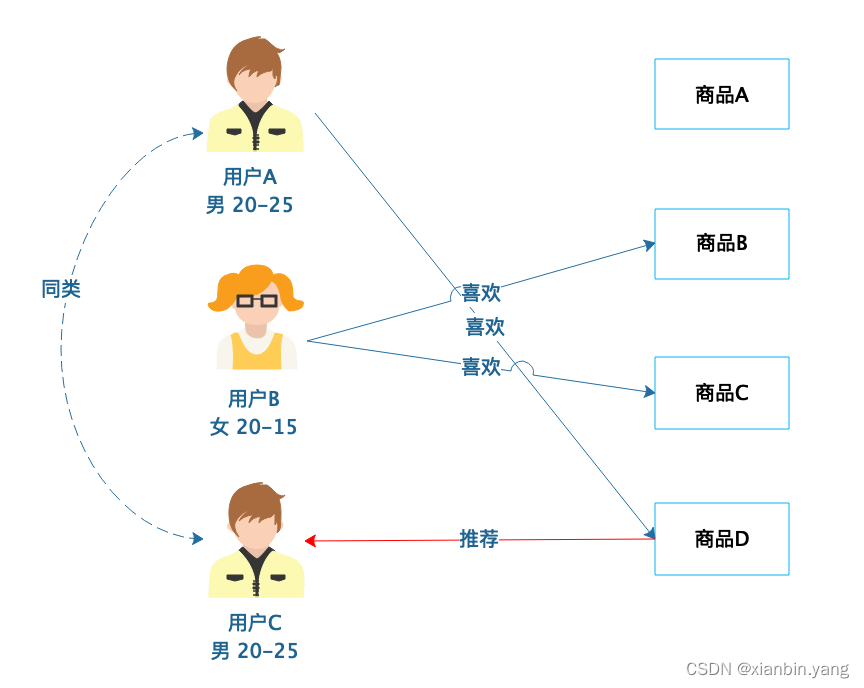
?
- 用户 A 和用户 C 有相近的人口统计信息,划分为同类,那么用户 A 喜欢(购买过)的商品 D 就可以推荐给用户 C。
- 基于人口统计的推荐比较简单,只要有用户的基本信息就可以进行分类,新注册的用户也可以分类到某一类别,那么立即就可以对他进行推荐,没有所谓的“冷启动”问题,也就是不会因为不知道用户的历史行为数据而不知道该如何向用户推荐。
- 在人口统计信息的基础上,根据用户浏览、购买信息和其他相关信息,进一步细化用户的分类信息,给用户贴上更多的标签,比如家庭成员、婚姻状况、居住地、学历、专业、工作等,即所谓的用户画像,根据用户画像进行更精细的推荐,并进一步把用户喜好当做标签完善用户画像,再利用更完善的用户画像进行推荐,如此不断迭代优化用户画像和推荐质量。
基于商品属性的推荐
- 将商品的属性进行分类,然后根据用户的历史行为进行推荐
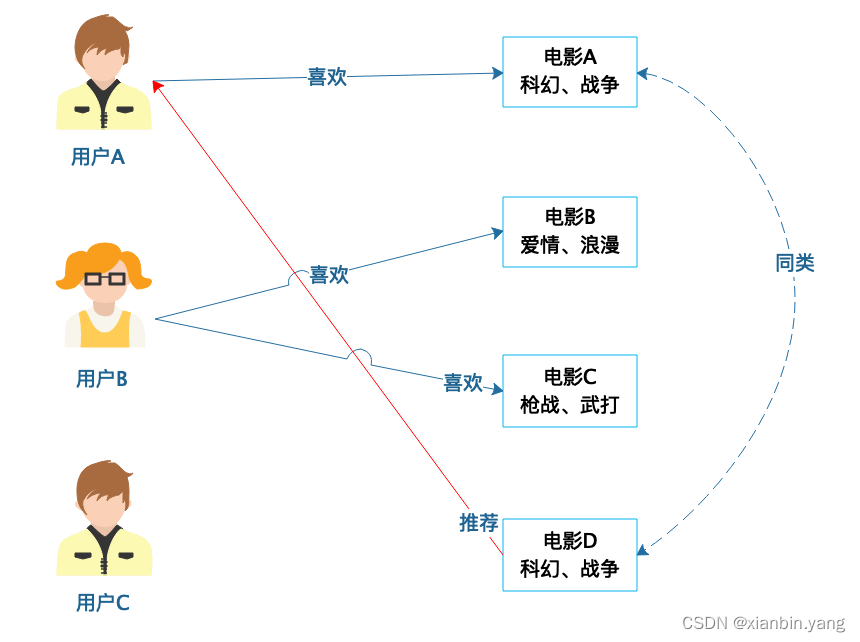
?
基于用户的协同过滤推荐
- 基于用户的协同过滤推荐是根据用户的喜好进行用户分类
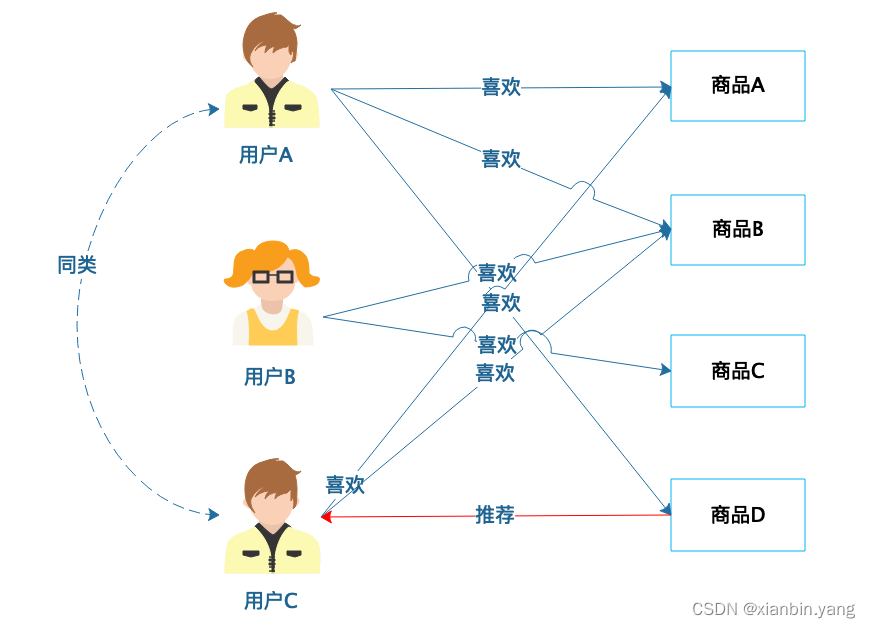
?
- 用户 A 喜欢商品 A、商品 B 和商品 D,用户 C 喜欢商品 A 和商品 B,那么用户 A 和用户 C 就有相似的喜好,可以归为一类,然后将用户 A 喜欢的商品 D 推荐给用户 C。
基于商品的协同过滤推荐
- 基于商品的协同过滤推荐是根据用户的喜好对商品进行分类,如果两个商品,喜欢它们的用户具有较高的重叠性,就认为它们的距离相近,划分为同类商品,然后进行推荐。
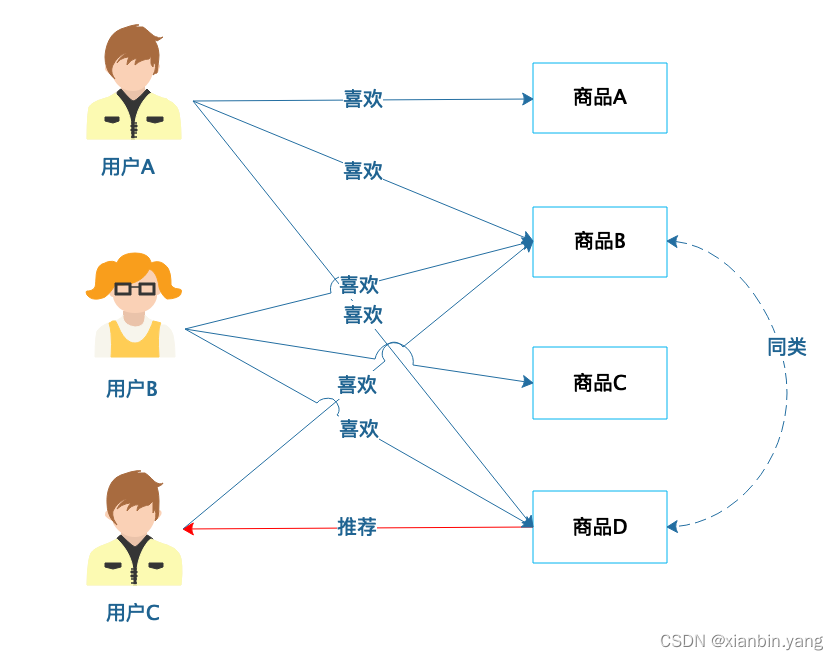
?
- 用户 A 喜欢商品 A、商品 B 和商品 D,用户 B 喜欢商品 B、商品 C 和商品 D,那么商品 B 和商品 D 的距离最近,划分为同类商品;而用户 C 喜欢商品 B,那么就可以为其推荐商品 D
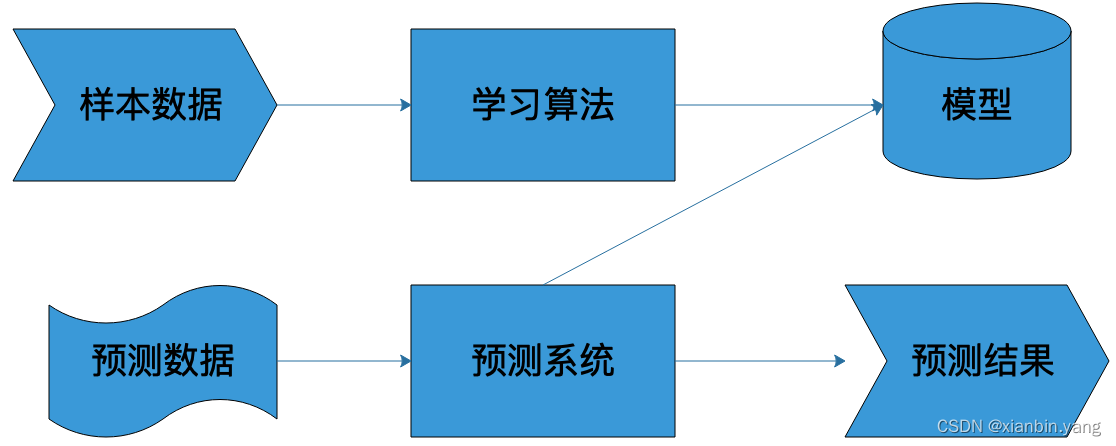
4、机器学习的数学原理是什么?
- 通过选择特定的算法对样本数据进行计算,获得一个计算模型,并利用这个模型,对以前未曾见过的数据进行预测
?
样本
- 样本就是通常我们常说的“训练数据”,包括输入和结果两部分

?
- 样本的数量和质量对机器学习的效果至关重要,如果样本量太少,或者样本分布不均衡,对训练出来的模型就有很大的影响。就像一个人一样,见得世面少、读书也少,就更容易产生偏见和刻板印象。
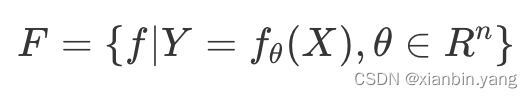
?
- 其中 θ 为 f 函数的参数取值空间,一个 n 维欧氏空间,被称作参数空间。
模型
- 模型就是映射样本输入与样本结果的函数,可能是一个条件概率分布,也可能是一个决策函数。一个具体的机器学习系统所有可能的函数构成了模型的假设空间

?
- 其中 X 是样本输入,Y 是样本输出,f 就是建立 X 和 Y 映射关系的函数。所有 f 的可能结果构成了模型的假设空间 F。
算法
- 算法就是要从模型的假设空间中寻找一个最优的函数,使得样本空间的输入 X 经过该函数的映射得到的 f(X),和真实的 Y 值之间的距离最小。这个最优的函数通常没办法直接计算得到,即没有解析解,需要用数值计算的方法不断迭代求解。
- 机器学习中用损失函数来评估模型是否最接近最优解。损失函数用来计算模型预测值与真实值的差距,常用的有 0-1 损失函数、平方损失函数、绝对损失函数、对数损失函数等。
- 平方损失函数
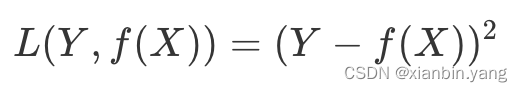
?
- 模型 f(X) 相对于真实值的平均损失为每个样本的损失函数的求和平均值。这个值被称作经验风险,如果样本量足够大,那么使经验风险最小的 f 函数就是模型的最优解,即求
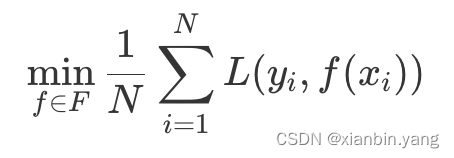
?
- 实际中使用的样本量总是有限的,可能会出现使样本经验风险最小的模型 f 函数并不能使实际预测值的损失函数最小,这种情况被称作过拟合,即一味追求经验风险最小,而使模型 f 函数变得过于复杂,偏离了最优解。这种情况下,需要引入结构风险以防止过拟合。结构风险表示为:
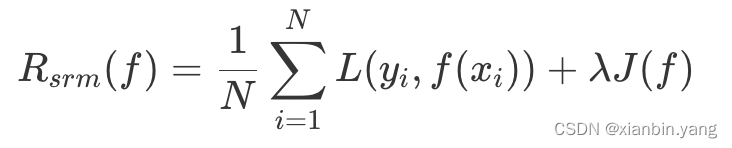
?
- 在经验风险的基础上加上 λJ(f),其中 J(f) 表示模型 f 的复杂度,模型越复杂,J(f) 越大。要使结构风险最小,就要使经验风险和模型复杂度同时小。求解模型最优解就变成求解结构风险最小值:

?
- 各种有样本的机器学习算法基本上都是在各种模型的假设空间上求解结构风险最小值的过程
- 机器学习要从假设空间寻找最优函数,而最优函数就是使样本数据的函数值和真实值距离最小的那个函数。给定函数模型,求最优函数就是求函数的参数值。给定不同参数,得到不同函数值和真实值的距离,这个距离就是损失,损失函数是关于模型参数的函数,距离越小,损失越小。最小损失值对应的函数参数就是最优函数。而我们知道,数学上求极小值就是求一阶导数,计算每个参数的一阶导数为零的偏微分方程组,就可以算出最优函数的参数值。这就是为什么机器学习要计算偏微分方程的原因。
5、从感知机到神经网络算法
- 神经网络由感知机组成
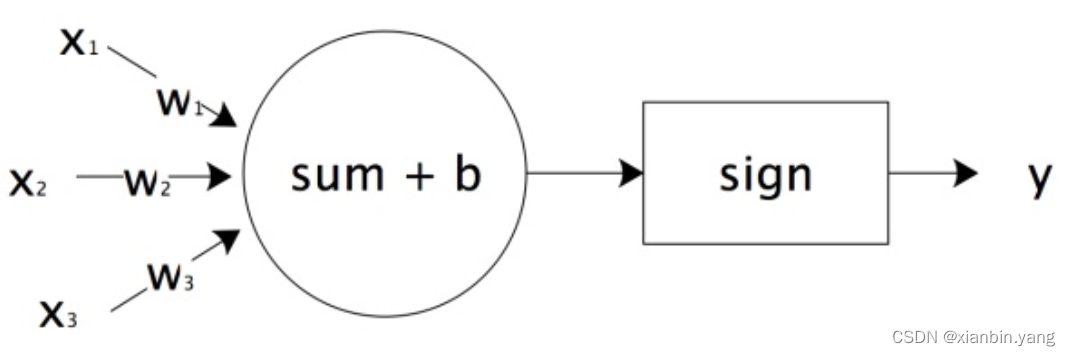
感知机
- 感知机是一种比较简单的二分类模型,将输入特征分类为 +1、-1 两类,就像下图所示的,一条直线将平面上的两类点分类。
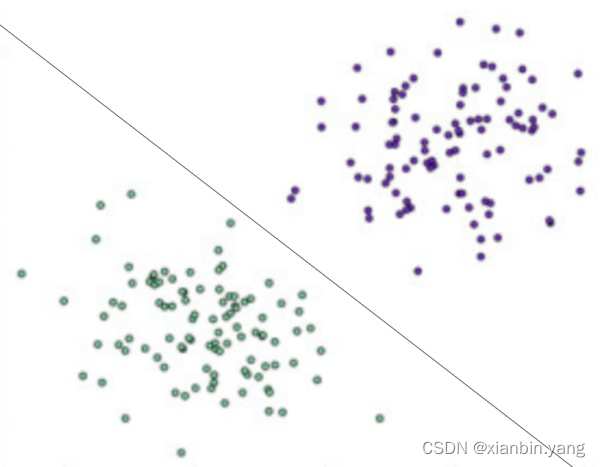
?
- 高维度上的分类模型也被称为超平面
- 感知机模型如下:
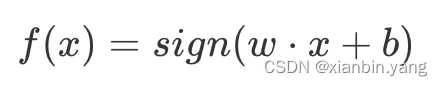
?
- w?x+b=0 为超平面的方程,当感知机输出为 +1 表示输入值在超平面的上方,当感知机输出为 -1 表示输入值在超平面的下方
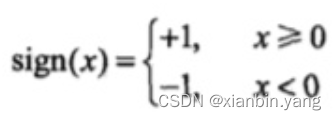
?
神经网络
- 神经元细胞的输出只有 0 或者 1 两种输出,人脑神经元可以通过感知机进行模拟,每个感知机相当于一个神经元,使用 sign 函数的感知机输出也是只有两个值,跟人脑神经元一样
- 感知机
?
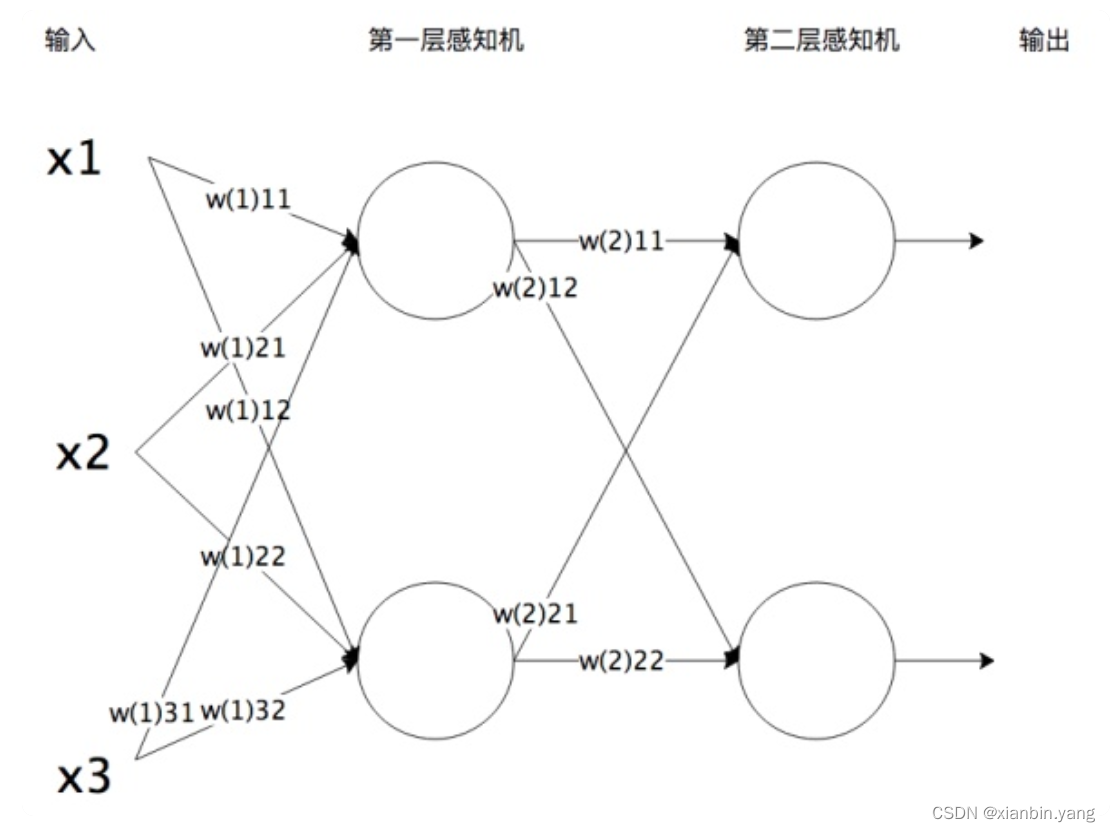
- 将感知机组成一层或者多层网络状结构,就构成了机器学习神经网络
?
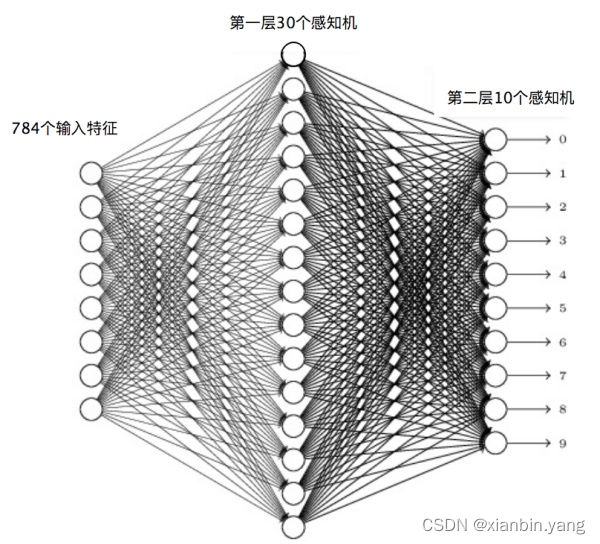
- 手写数字识别为例

?
- 这个手写数字样本中的每个数字都是一个 28×28 像素的图片,我们把每个像素当作一个特征值,这样每个数字就对应 784 个输入特征。因为输出需要判别 10 个数字,所以第二层(输出层)的感知机个数就是 10 个,每个感知机通过 0 或者 1 输出是否为对应的数字。
?
- 训练神经网络的时候采用一种反向传播的算法,针对每个样本,从最后一层,也就是输出层开始,利用样本结果使用梯度下降算法计算每个感知机的参数。然后以这些参数计算出来的结果作为倒数第二层的输出计算该层的参数。然后逐层倒推,反向传播,计算完所有感知机的参数。
- 两层神经网络,用sigmoid 函数
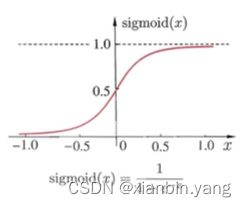
?
- 对于两层以上的多层神经网络,ReLU 函数的效果更好一些

?
?

