�㷨����
�������Ǵ�Random sample consensus - Wikipedia���ҵ�RANSACԭ���Ľ��ܡ�
RANSAC�㷨�������������������һ���㷨(Random Sample Consenus),��˵,ͨ��RANSAC�㷨,���ǽ����ݷ�Ϊinliers��outliers,inliers�Ƕ���ģ�������Ч�ĵ�,Ҳ��֮Ϊ�ڵ�;outliers�Ƕ���ģ�������Ч�ĵ�,Ҳ���Ǵ�������ݵ�,��֮Ϊ�������������ʹ�ù۲��������ģ�͵Ĺ�����,���Ĵ��ڶ���ʹ���������ģ�����к���,��ô���Ǹ��������Щ�����?RANSAC�㷨�����ܹ�������һ�������Ե��㷨��
����
��ͼ��ʾ����RANSAC�㷨������:�����,ʹģ���Ƹ���ȷ,�ο�Robust line model estimation using RANSAC �� skimage v0.19.2 docs (scikit-image.org)
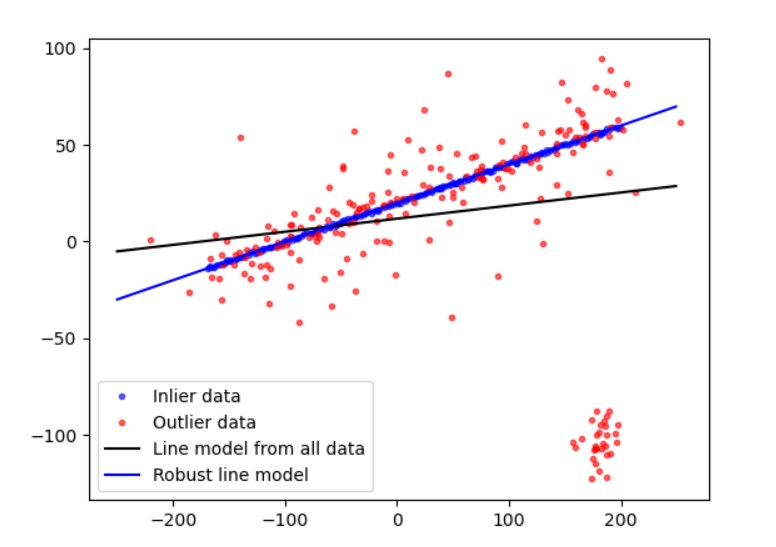
�㷨�Ļ���˼�������
�㷨��ʵ������:
- ѡ�������ģ�͵���С��������(���ڶ�ά����άֱ�������˵,ȷ��һ��ֱ��������Ҫ2����;������άƽ�������˵,ȷ��һ����άƽ��������Ҫ3����)
- ʹ�������С����������,�����ϵ�ģ�͡�(Ҳ����ֱ�߷��̻���ƽ�淽��)
- �����е�ģ�ʹ��������ϵ�ģ��,������ڵ� ��������(���ݵ����ϵ�ģ�͵������һ����ֵ��Χ�ڵ����ݵ������)
- �Ƚϵ�ǰģ�ͺ�֮ǰ�����ĵõ�����õ�ģ�͵��ڵ�����(�ڵ�����Խ��,ģ��Խ��),��¼�����ڵ�����ģ�Ͳ������ڵ�������
- �ظ�1-4��,ֱ���ﵽ������ֹ����(����ﵽ�����������ڵ������ﵽ������ֹ����)
�����������Ƶ�
�����ڵ�����������ռ�ı���Ϊ
t
t
t
t
=
n
i
n
l
i
e
r
s
n
i
n
l
i
e
r
s
+
n
o
u
t
l
i
e
r
s
t=\frac{n_{inliers}}{n_{inliers}+n_{outliers}}
t=ninliers?+noutliers?ninliers??
�������ÿ�ε�������Ҫ
N
N
N����,��ôÿ�ε���������һ�����ĸ�����:
P
1
=
1
?
t
N
P_{1}=1-t^N
P1?=1?tN
�����������
k
k
k��,���е�
k
k
k�ε�����������һ�����ĸ���Ϊ
P
1
k
P_{1}^{k}
P1k?,��ô��
k
k
k�ε���,�ܹ���������ȷ��
N
N
N���ڵ�ȥ����ģ�͵ĸ��ʾ����������ʵIJ�����
P
=
1
?
P
1
k
=
1
?
(
1
?
t
N
)
k
P=1-P_{1}^{k}=1-(1-t^{N})^{k}
P=1?P1k?=1?(1?tN)k
ͨ����ʽ,���ǿ������
k
=
l
o
g
(
1
?
P
)
l
o
g
(
1
?
t
N
)
k=\frac{log(1-P)}{log(1-t^{N})}
k=log(1?tN)log(1?P)?
ע��:�ڵ�ĸ���
t
t
t��һ������ֵ,�������һ��ʼ��֪���������ֵ
t
t
t,���Բ�������Ӧ�����ķ���,�õ�ǰ���ڵ�ı�ֵ������
t
t
t����������Ĵ�����Ȼ��ͨ�����ϵ���,�ڵ�ı�ֵҲ������,�����µĸ�����ڵ��ֵȥ����
t
t
t��ֵ;����
P
P
P��˵,һ���ȡһ����ֵ0.99,��ʽ(4)���Կ���,��
P
P
P����ʱ,
t
t
tԽ��,
k
k
kԽС,
t
t
tԽС,
k
k
kԽ��
�㷨��ʵ��
Given:
data �C A set of observations.
model �C A model to explain observed data points.
n �C Minimum number of data points required to estimate model parameters.
k �C Maximum number of iterations allowed in the algorithm.
t �C Threshold value to determine data points that are fit well by model.
d �C Number of close data points required to assert that a model fits well to data.
Return:
bestFit �C model parameters which best fit the data (or null if no good model is found)
iterations = 0
bestFit = null
bestErr = something really large
while iterations < k do
maybeInliers := n randomly selected values from data
maybeModel := model parameters fitted to maybeInliers
alsoInliers := empty set
for every point in data not in maybeInliers do
if point fits maybeModel with an error smaller than t
add point to alsoInliers
end if
end for
if the number of elements in alsoInliers is > d then
// This implies that we may have found a good model
// now test how good it is.
betterModel := model parameters fitted to all points in maybeInliers and alsoInliers
thisErr := a measure of how well betterModel fits these points
if thisErr < bestErr then
bestFit := betterModel
bestErr := thisErr
end if
end if
increment iterations
end while
return bestFit
python����ʵ��
���´���ο�scikit-image/fit.py at v0.19.2 �� scikit-image/scikit-image (github.com),Ҳ����skimage��Դ�롣
def _dynamic_max_trials(n_inliers, n_samples, min_samples, probability):
if n_inliers == 0:
return np.inf
if probability == 1:
return np.inf
if n_inliers == n_samples:
return 1
nom = math.log(1 - probability)
denom = math.log(1 - (n_inliers / n_samples) ** min_samples)
return int(np.ceil(nom / denom))
def ransac(data, model_class, min_samples, residual_threshold,
is_data_valid=None, is_model_valid=None,
max_trials=100, stop_sample_num=np.inf, stop_residuals_sum=0,
stop_probability=1, random_state=None, initial_inliers=None):
best_inlier_num = 0
best_inlier_residuals_sum = np.inf
best_inliers = []
validate_model = is_model_valid is not None
validate_data = is_data_valid is not None
random_state = np.random.default_rng(random_state)
# in case data is not pair of input and output, male it like it
if not isinstance(data, (tuple, list)):
data = (data, )
num_samples = len(data[0])
if not (0 < min_samples < num_samples):
raise ValueError(f"`min_samples` must be in range (0, {num_samples})")
if residual_threshold < 0:
raise ValueError("`residual_threshold` must be greater than zero")
if max_trials < 0:
raise ValueError("`max_trials` must be greater than zero")
if not (0 <= stop_probability <= 1):
raise ValueError("`stop_probability` must be in range [0, 1]")
if initial_inliers is not None and len(initial_inliers) != num_samples:
raise ValueError(
f"RANSAC received a vector of initial inliers (length "
f"{len(initial_inliers)}) that didn't match the number of "
f"samples ({num_samples}). The vector of initial inliers should "
f"have the same length as the number of samples and contain only "
f"True (this sample is an initial inlier) and False (this one "
f"isn't) values.")
# for the first run use initial guess of inliers
spl_idxs = (initial_inliers if initial_inliers is not None
else random_state.choice(num_samples, min_samples,
replace=False))
# estimate model for current random sample set
model = model_class()
for num_trials in range(max_trials):
# do sample selection according data pairs
samples = [d[spl_idxs] for d in data]
# for next iteration choose random sample set and be sure that
# no samples repeat
spl_idxs = random_state.choice(num_samples, min_samples, replace=False)
# optional check if random sample set is valid
if validate_data and not is_data_valid(*samples):
continue
success = model.estimate(*samples)
# backwards compatibility
if success is not None and not success:
continue
# optional check if estimated model is valid
if validate_model and not is_model_valid(model, *samples):
continue
residuals = np.abs(model.residuals(*data))
# consensus set / inliers
inliers = residuals < residual_threshold
residuals_sum = residuals.dot(residuals)
# choose as new best model if number of inliers is maximal
inliers_count = np.count_nonzero(inliers)
if (
# more inliers
inliers_count > best_inlier_num
# same number of inliers but less "error" in terms of residuals
or (inliers_count == best_inlier_num
and residuals_sum < best_inlier_residuals_sum)):
best_inlier_num = inliers_count
best_inlier_residuals_sum = residuals_sum
best_inliers = inliers
dynamic_max_trials = _dynamic_max_trials(best_inlier_num,
num_samples,
min_samples,
stop_probability)
if (best_inlier_num >= stop_sample_num
or best_inlier_residuals_sum <= stop_residuals_sum
or num_trials >= dynamic_max_trials):
break
# estimate final model using all inliers
if any(best_inliers):
# select inliers for each data array
data_inliers = [d[best_inliers] for d in data]
model.estimate(*data_inliers)
if validate_model and not is_model_valid(model, *data_inliers):
warn("Estimated model is not valid. Try increasing max_trials.")
else:
model = None
best_inliers = None
warn("No inliers found. Model not fitted")
return model, best_inliers
��һƪ���ǽ��ص㽲��ʹ��RANSAC���ֱ�ߵ�����,���Ʋ�RANSAC�㷨��ԭ��(��)
References
Random sample consensus - Wikipedia
RANSAC�㷨���(��Python���ֱ��ģ�ʹ���) - ֪�� (zhihu.com)
Robust line model estimation using RANSAC �� skimage v0.19.2 docs (scikit-image.org)
scikit-image/fit.py at v0.19.2 �� scikit-image/scikit-image (github.com)

