原理解析
相机标定
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数的过程就称之为相机标定(或摄像机标定)。
无论是在图像测量或者机器视觉应用中,相机参数的标定都是非常关键的环节,其标定结果的精度及算法的稳定性直接影响相机工作产生结果的准确性。
算法流程
(1)打印一张棋盘方格图并贴在一个平面上
(2)从不同角度拍摄若干张模板图像
(3)检测出图像中的特征点
(4)由检测到的特征点计算出每幅图像中的平面投影矩阵H
(5)确定出摄像机的参数
计算单应性矩阵H
单应性:在计算机视觉中被定义为一个平面到另一个平面的投影映射。首先确定,图像平面与标定物棋盘格平面的单应性。
单应性:在计算机视觉中被定义为一个平面到另一个平面的投影映射。首先确定,图像平面与标定物棋盘格平面的单应性。
设三维世界坐标的点为
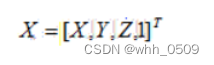
二维相机平面像素坐标为

所以标定用的棋盘格平面到图像平面的单应性关系为:
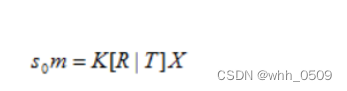
(其中,K为相机的内参矩阵,R为外部参数矩阵(旋转矩阵),T为平移向量。令
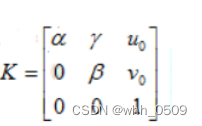
设棋盘格位于Z=0的平面,定义旋转矩阵R的第i列为 ri, 则有:
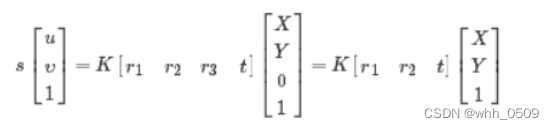
于是空间到图像的映射可改为:H=λK[r1 r2 t]
其中H 是描述Homographic矩阵,可通过最小二乘,从角点世界坐标到图像坐标的关系求解。
计算内参数矩阵
根据步骤1中的式子,令 H 为 H = [h1 h2 h3],则 [h1 h2 h3]=λK[r1 r2 t],再根据正交和归一化的约束可以得到等式:
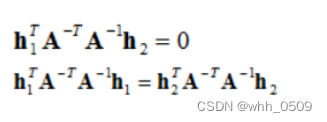
即每个单应性矩阵能提供两个方程,而内参数矩阵包含5个参数,要求解,至少需要3个单应性矩阵。为了得到三个不同的单应性矩阵,我们使用至少三幅棋盘格平面的图片进行标定。通过改变相机与标定板之间的相对位置来得到三个不同的图片。为了方便计算,我们定义:
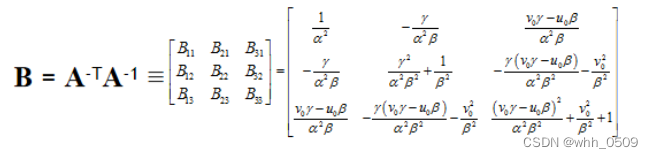
B 中的未知量可表示为6D 向量 b,在这里插入图片描述
设H中的第i列为 hi,在这里插入图片描述,根据b的定义,可以推导出公式在这里插入图片描述,在这里插入图片描述,
最后推导出:
在这里插入图片描述
通过上式,我们可知当观测平面 n ≥ 3 时,即至少3幅棋盘格图像,可以得到b的唯一解,求得相机内参数矩阵K。
计算外参数矩阵
外部参数可通过Homography求解,由 H = [h1 h2 h3] = λA[r1 r2 t],可推出:
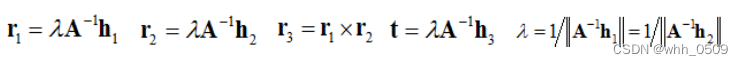
最大似然估计
上述的推导结果是基于理想情况下而言,但由于可能存在一些其他干扰,所以使用最大似然估计进行优化。假设拍摄了n张棋盘格图像,每张图像有m个角点。最终获得的最大似然估计公式为:
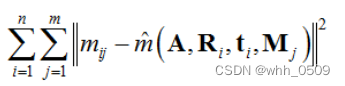
代码测试
import cv2
import numpy as np
import glob
# 找棋盘格角点
# 棋盘格模板规格(内角点个数,内角点是和其他格子连着的点,如10 X 7)
w = 10
h = 7
# 世界坐标系中的棋盘格点,例如(0,0,0), (1,0,0), (2,0,0) ....,(8,5,0),去掉Z坐标,记为二维矩阵
objp = np.zeros((w * h, 3), np.float32)
objp[:, :2] = np.mgrid[0:w, 0:h].T.reshape(-1, 2)
# 储存棋盘格角点的世界坐标和图像坐标对
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
# 标定所用图像(路径不能有中文)
images = glob.glob('D:\\python\\whh\\pycharmproject\\img_qipan\\*.jpg')
size = tuple()
for fname in images:
img = cv2.imread(fname)
# 修改图像尺寸,参数依次为:输出图像,尺寸,沿x轴,y轴的缩放系数,INTER_AREA在缩小图像时效果较好
# img = cv2.resize(img, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转灰度
size = gray.shape[::-1] # 矩阵转置
# 找到棋盘格角点
# 棋盘图像(8位灰度或彩色图像) 棋盘尺寸 存放角点的位置
ret, corners = cv2.findChessboardCorners(gray, (w, h), None)
# 角点精确检测
# criteria:角点精准化迭代过程的终止条件(阈值)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 执行亚像素级角点检测
corners2 = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
objpoints.append(objp)
imgpoints.append(corners2)
# 将角点在图像上显示
cv2.drawChessboardCorners(img, (w, h), corners2, ret)
cv2.imshow('findCorners', img)
cv2.waitKey(1000)
"""
标定、去畸变:
输入:世界坐标系里的位置 像素坐标 图像的像素尺寸大小 3*3矩阵,相机内参数矩阵 畸变矩阵
输出:标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
"""
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, size, None, None)
# mtx:内参数矩阵
# dist:畸变系数
# rvecs:旋转向量 (外参数)
# tvecs :平移向量 (外参数)
print("ret:", ret)
print("内参数矩阵:\n", mtx,'\n')
print("畸变系数:\n", dist,'\n')
print("旋转向量(外参数):\n", rvecs,'\n')
print("平移向量(外参数):\n", tvecs,'\n')
# 去畸变
img2 = cv2.imread('D:\\python\\RRJ\\pycharmproject\\img_qipan\\03.jpg')
h, w = img2.shape[:2]
# 我们还可以使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数,
# 通过设定自由自由比例因子alpha。当alpha设为0的时候,
# 将会返回一个剪裁过的将去畸变后不想要的像素去掉的内参数和畸变系数;
# 当alpha设为1的时候,将会返回一个包含额外黑色像素点的内参数和畸变系数,并返回一个ROI用于将其剪裁掉
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w, h), 0, (w, h)) # 自由比例参数
dst = cv2.undistort(img2, mtx, dist, None, newcameramtx)
# 根据前面ROI区域裁剪图片
x, y, w, h = roi
dst = dst[y:y + h, x:x + w]
cv2.imwrite('calibresult.jpg', dst)
# 反投影误差
# 通过反投影误差,我们可以来评估结果的好坏。越接近0,说明结果越理想。
total_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i], imgpoints2, cv2.NORM_L2) / len(imgpoints2)
total_error += error
print("total error: ", total_error / len(objpoints))
实验结果分析
1.数据集
使用手机相机一共拍摄16张棋盘格图片,图片统一尺寸为640 X 480,纸张大小为a4,棋盘格大小为11X8个格子,每个格子大小为20X20mm,使用数据集的时候没有取到边缘,所取内角点(内角点是和其他格子连着的点)维数为10X7。
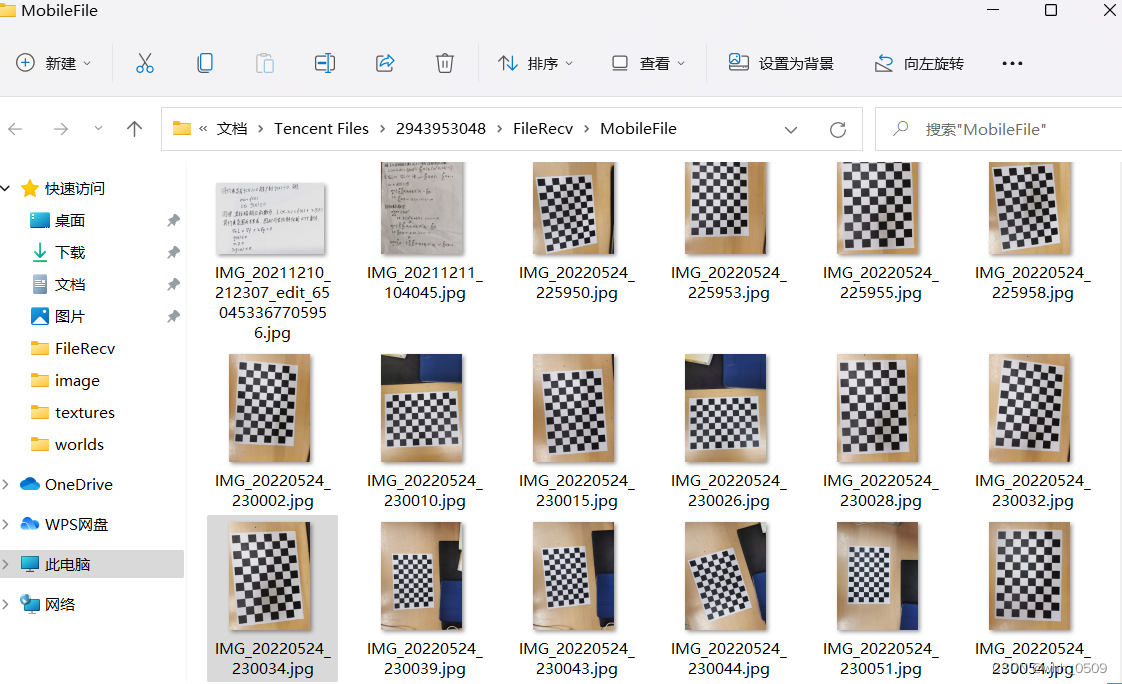
2.实验结果

内参矩阵:

畸变矫正系数:

