城市复杂环境的视觉定位与建图
出处:2022-05-19鹏城实验室线上分享
报告人:上交邹丹平教授 Google scholar
整理人:高斯球
其他资料:2018年邹丹平老师在北京大学题目为“基于环境结构性特征的视觉SLAM方法”的分享
报告内容

内容概要
该部分主要是邹老师团队围绕城市环境中的视觉定位与地图构建方法做的一系列工作:
- StructSLAM,2015
- StructVIO,2019
- TextSLAM,2020
- StructDepth,2021
上面是利用结构化信息,包含纯视觉的方法、视觉惯性里程计的方法;邹老师的团队最近在探索如何将场景中的语义结合到SLAM中,代表作是上面TextSLAM;以及如何将城市里的结构化信息整合到建图中,代表作是上面的StructDepth;这次分享的内容主要就是围绕着四篇工作。
视觉SLAM基础
视觉SLAM的定义:Simultaneous Localization And Mapping(同步定位与地图构建);描述**我在哪?(定位)和周围环境是怎样的?(地图构建)**两个问题。

在2010年到2020年视觉SLAM有非常多的方法,其中最具代表性的当然是ORBSLAM系列;除此之外还有直接法和半直接法,这些方法有自己的特征所在;视觉SLAM方法落地最关键的还是取决于视觉惯性两种传感器的融合,使用视觉SLAM在鲁棒性和精度都取得了非常大的突破,实现了可靠的视觉SLAM。
从方法论的角度上来说,视觉SLAM在2010前框架都比较成熟,比如以Mono-SLAM/MSCKF为代表的滤波的框架,以PTAM为代表的关键帧的框架;所以从理论方法甚至框架的角度上来说,视觉SLAM都比较成熟,剩下的挑战是针对具体实际的应用场景高度定制的视觉SLAM,使得视觉SLAM在该场景下能达到稳定、精准的运行效果。

考虑应用场景应该同时考虑环境和载体两部分,载体可以有可穿戴XR、无人车、无人机,每个载体都有不同的特点。
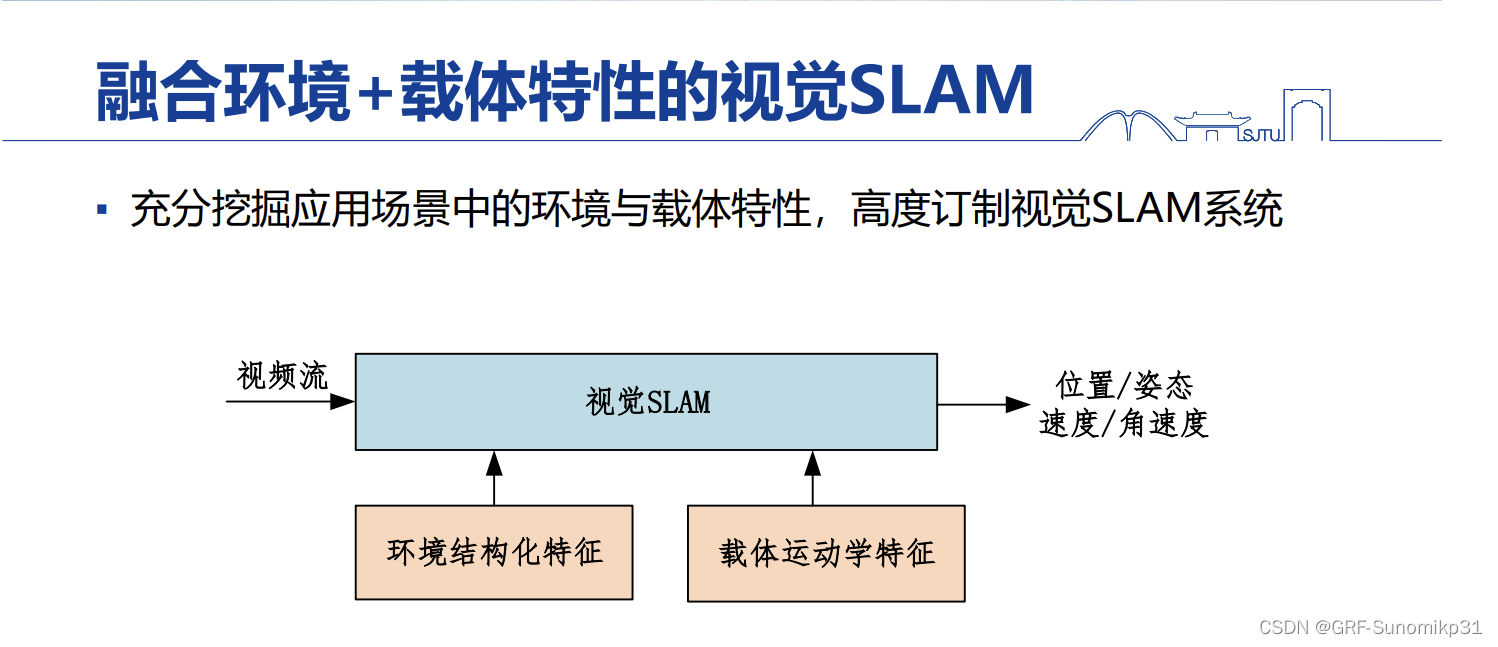
邹老师今天的介绍主要是分享如何挖掘应用场景下的环境特性,让视觉SLAM工作的更好。
StructSLAM
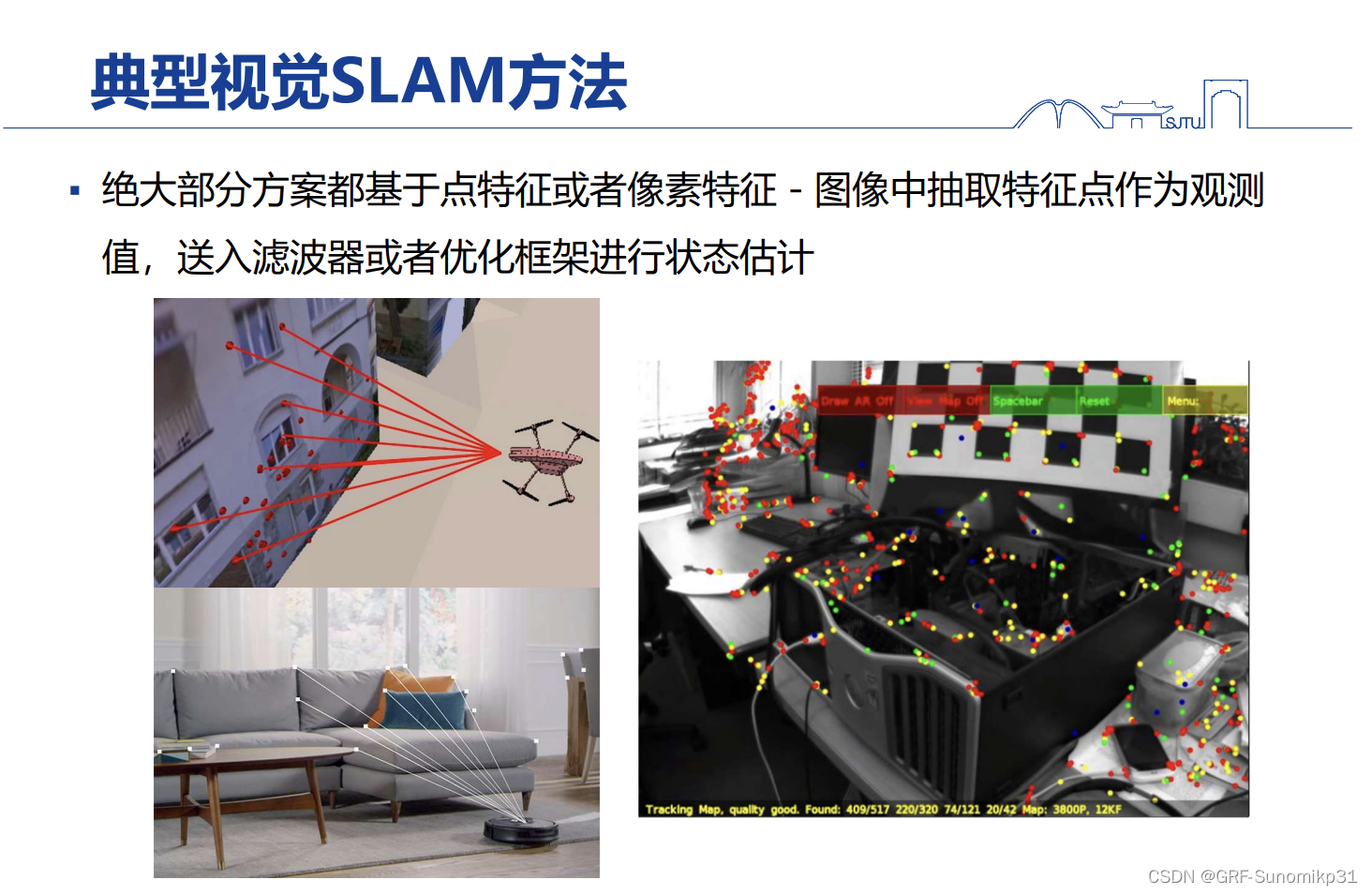
上述图片以间接法为例,直接法也是类似的,其在像素级别进行操作,最后也会放到滤波器或者优化框架中。从图里可以看到场景中的点是非常稀疏的,这些点是没有能够充分地将场景中的几何结构特性利用好;

在日常生活当中尤其是城市生活当中,自然场景和城市场景是非常不一样的,纯自然场景是非常杂乱的(图像的纹理),没有特别强的规整性,如果是城市场景中可以看到人造痕迹很强,就是表现很强的几何规整性。
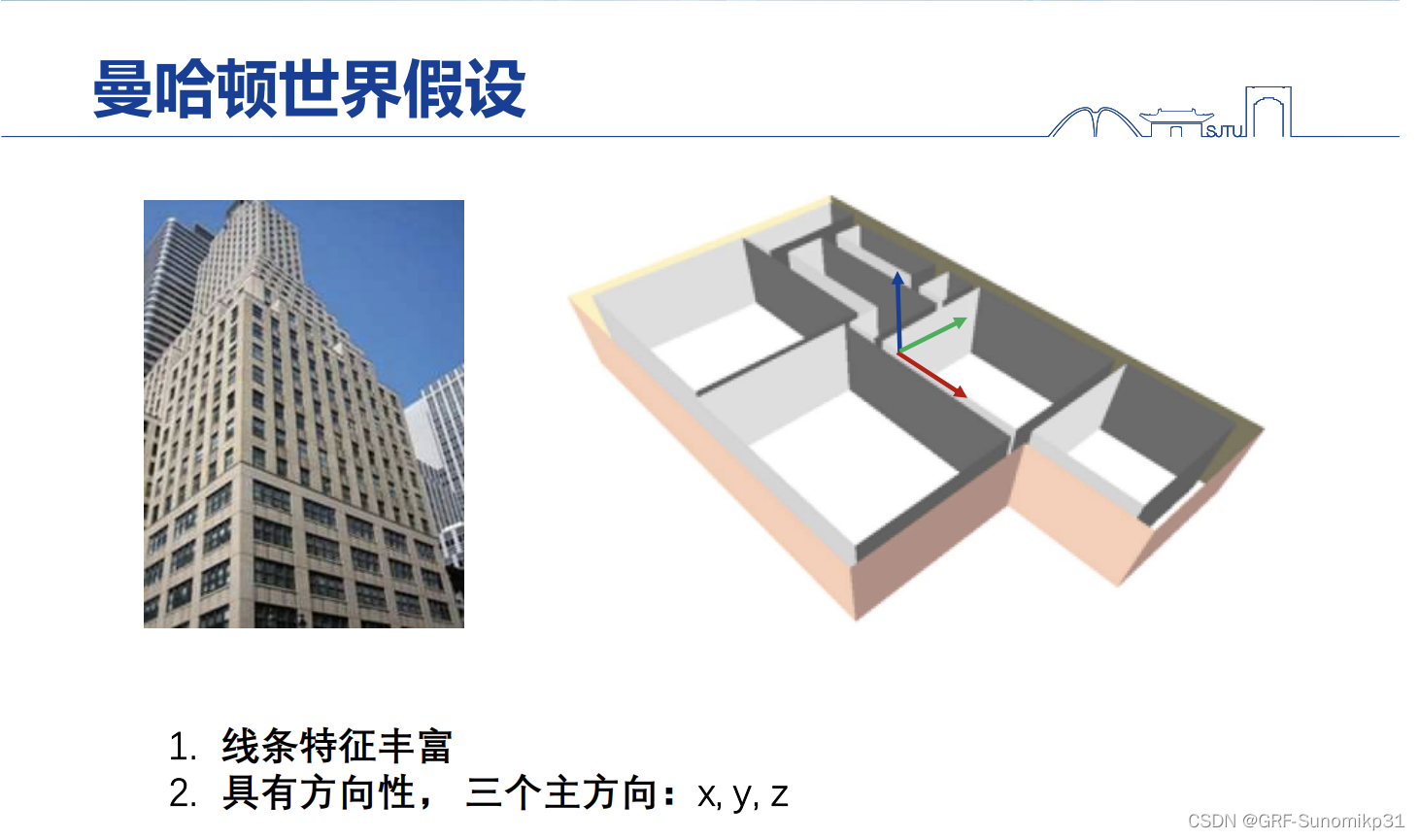
上述特性很早就有人注意到,叫做曼哈顿世界假设,也有一些早期的SFM工作用了这个特性,比如试图用一幅图像将场景的三维结构恢复出来,在早期没有深度神经网络的情况下,研究者都是充分挖掘这种假设去做三维的恢复,特别是单幅图的三位恢复。

这样特性能够用于提升视觉SLAM的性能,包括视觉SLAM的精度和鲁棒性;邹老师的团队在2015年做了第一个尝试,将线条尤其是结构化的线条(线条+方向,线条的方向要和曼哈顿世界的三个主方向一致)当作一个新的特征进行地图构建和定位;因为该场景下很多墙上是没有纹理的,所以这时只有特征点是不稳定的;在这个系统里面因为有线条的方向性约束,精度和稳定都很非常高;

后面是该工作的一些细节;首先是结构线条的定义:线条+方向,线条的方向要和曼哈顿世界的三个主方向一致;这里structslam对结构化线条的描述是这样的,先找到曼哈顿三个方向,在定义一个参数平面,结构线条都能投影到参数平面上成为一个点。参数平面的三个方向和曼哈顿三个方向重合。
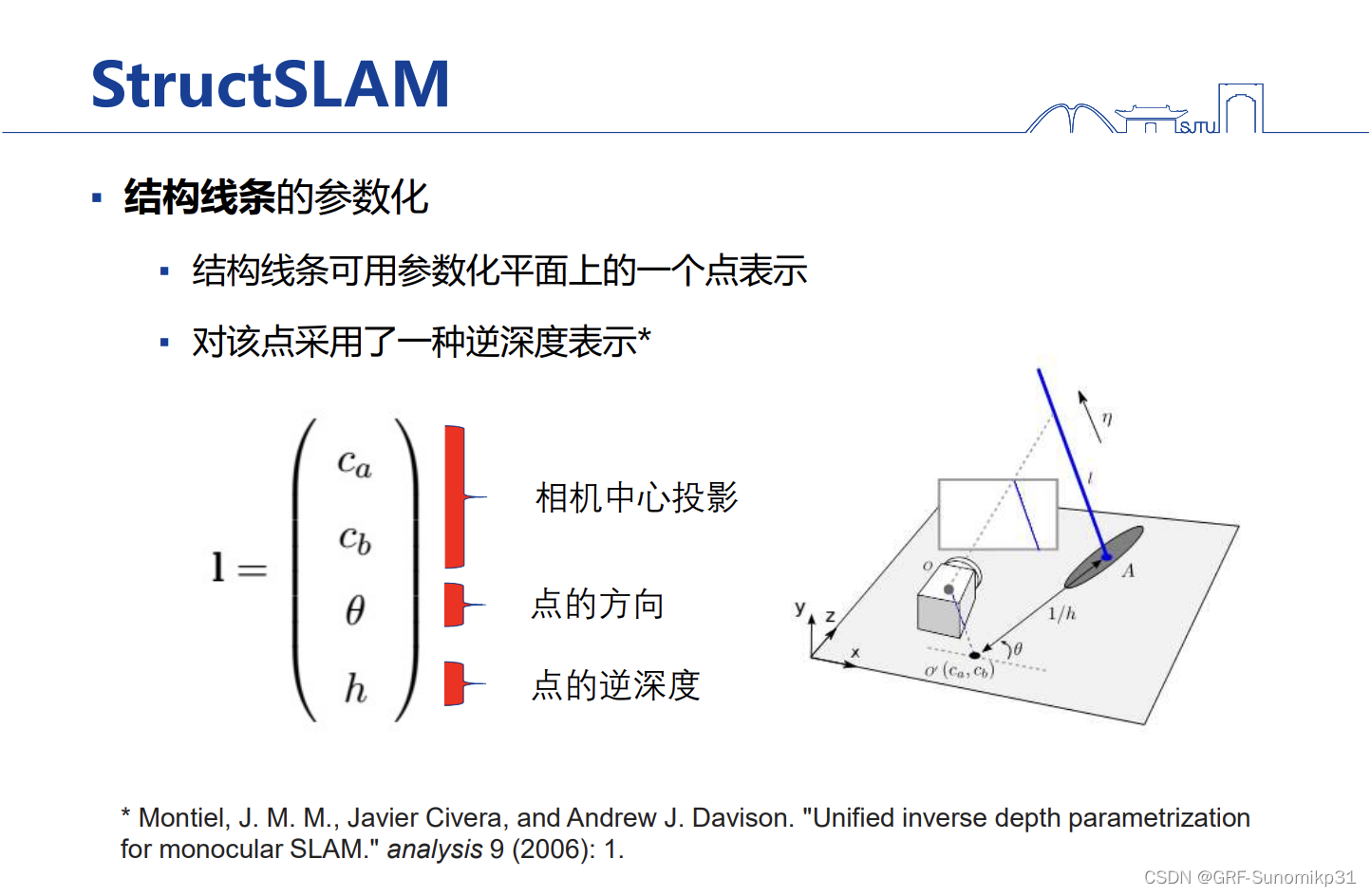
早期的视觉SLAM基于最经典的滤波框架(MonoSLAM),实现起来非常简单,只需要在MonoSLAM框架下加一个参数方程,定义一个结构你线条表示的状态量;这里没有直接用点的二维坐标表示线段,而是采用了逆深度表示,因为早期有个研究如果用笛卡尔坐标直接表示,那么在滤波器初始阶段,初始化的坐标是非常不准的。所以滤波器误差会很大,可以用逆深度做参数化解决这一问题。
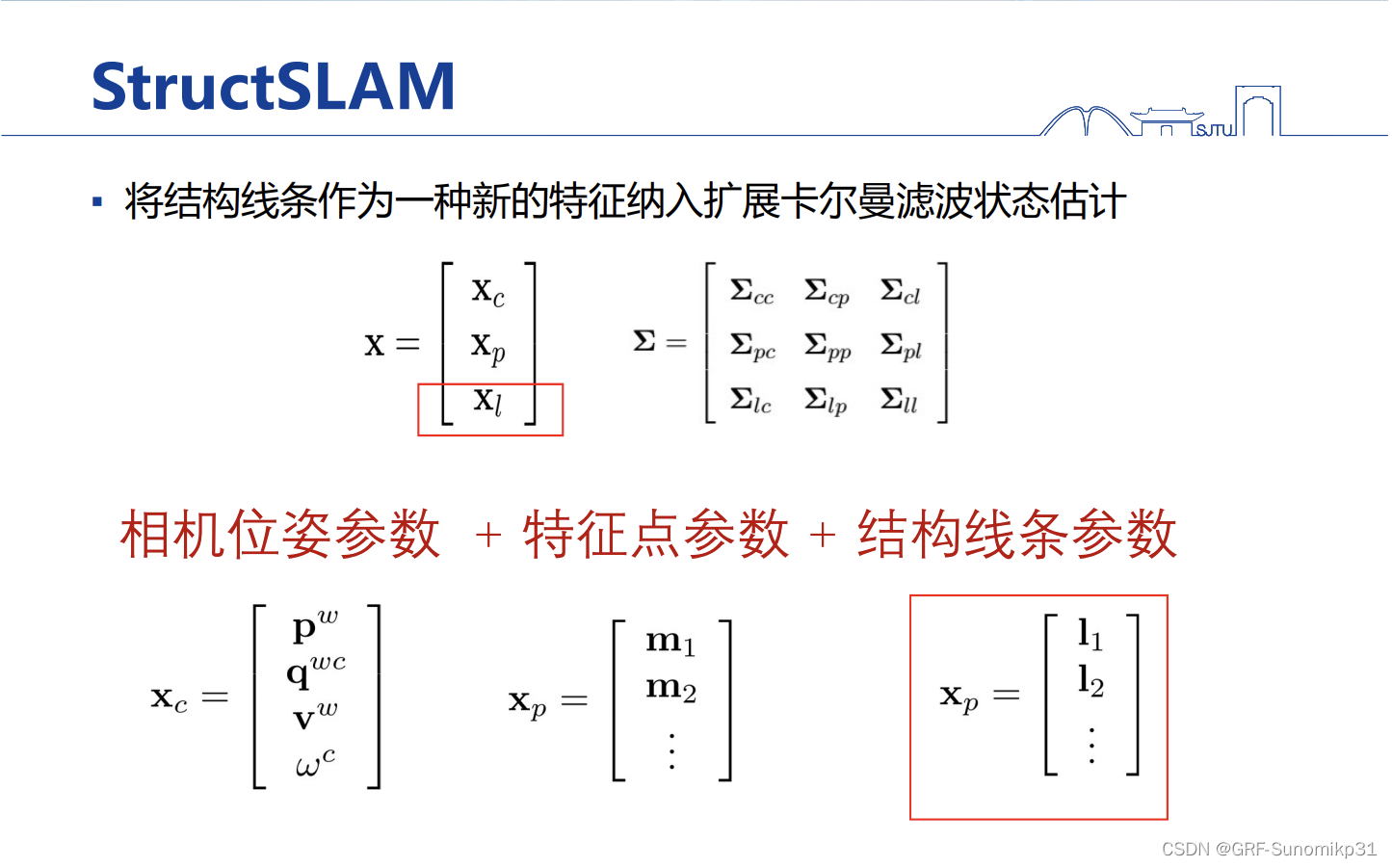
加入到整体状态定义中。右边是卡尔曼滤波的协方差矩阵。
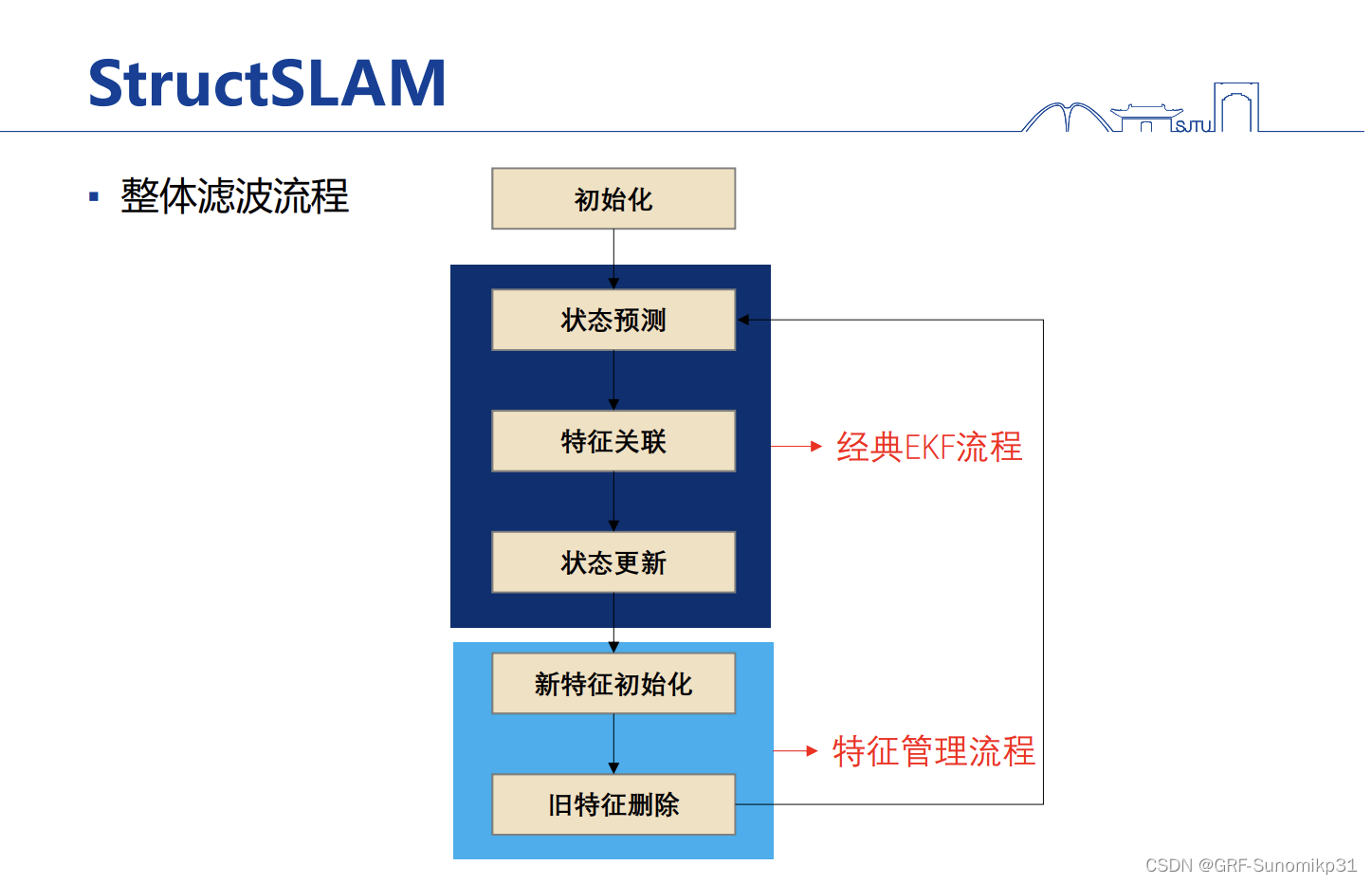
最终整个流程的pipeline是标准的基于卡尔曼滤波的视觉SLAM流程,核心包括状态预测、特征关联和状态更新。
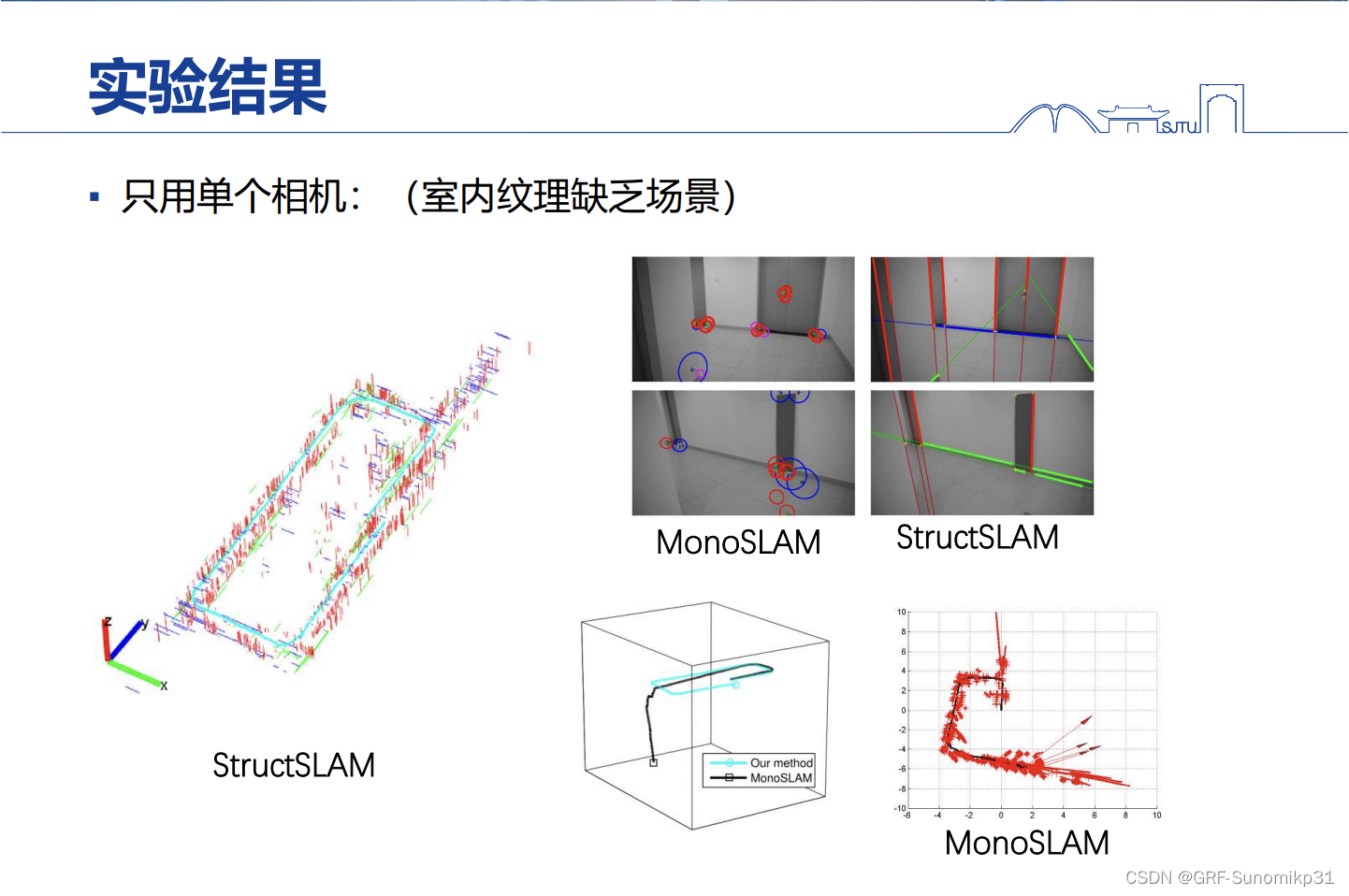
当纹理比较差的时候,结构线条帮助是非常大的。
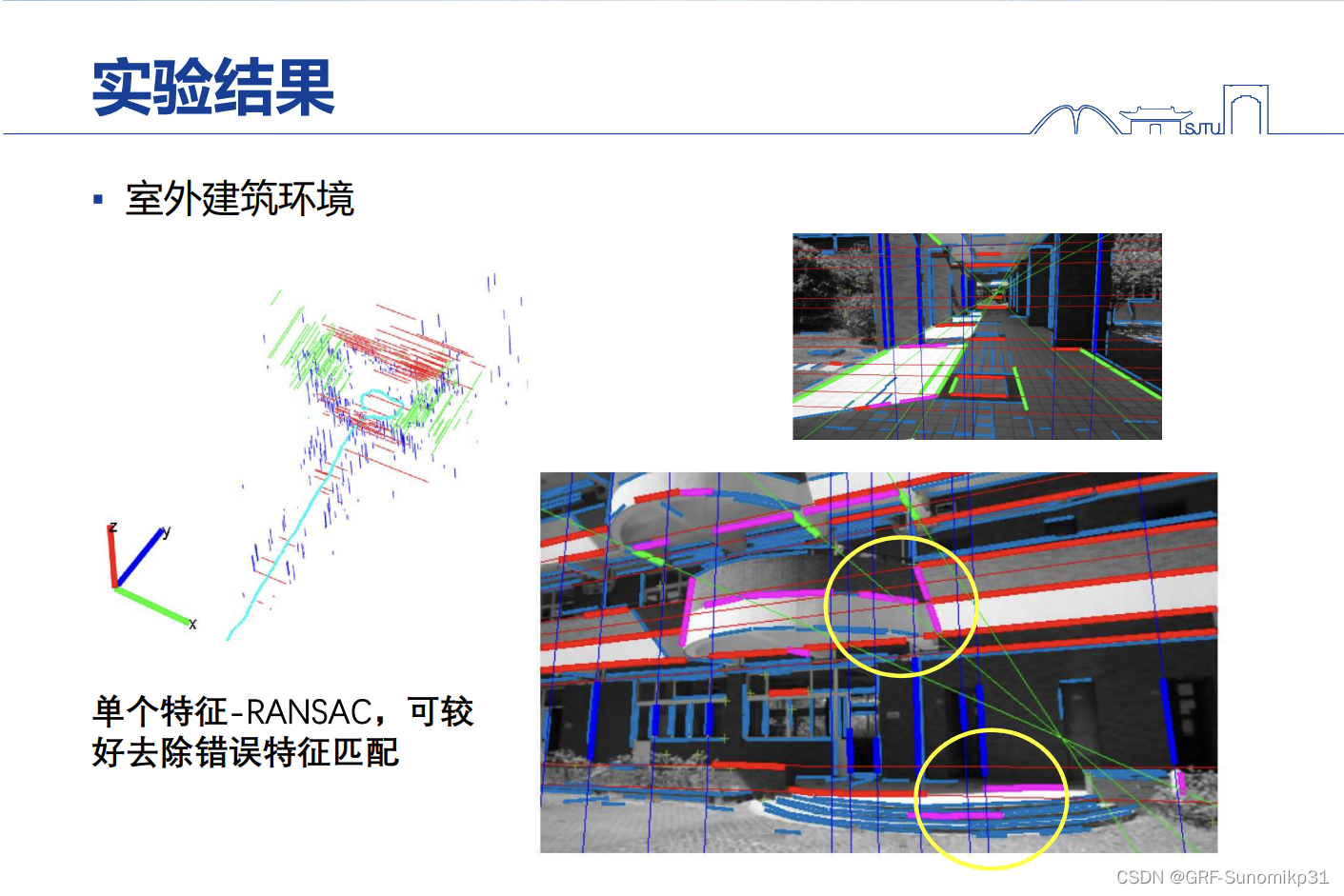
当环境是比较杂乱的时候,那些杂乱的线条会不会对算法有影响呢?答案是会的,那些杂乱的线条对视觉SLAM影响是比较大的,这里提出一种单特征RANSAC进行解决。具体流程如下:因为前面是有卡尔曼滤波进行预测,现在就是拿一个特征(点和线都行)作为观测量去更新整个状态,然后用整个状态再去和整个观测看是否符合一致,去判断这个特征是否需要被踢出(这里是否比较消耗时间?能否实时?)。
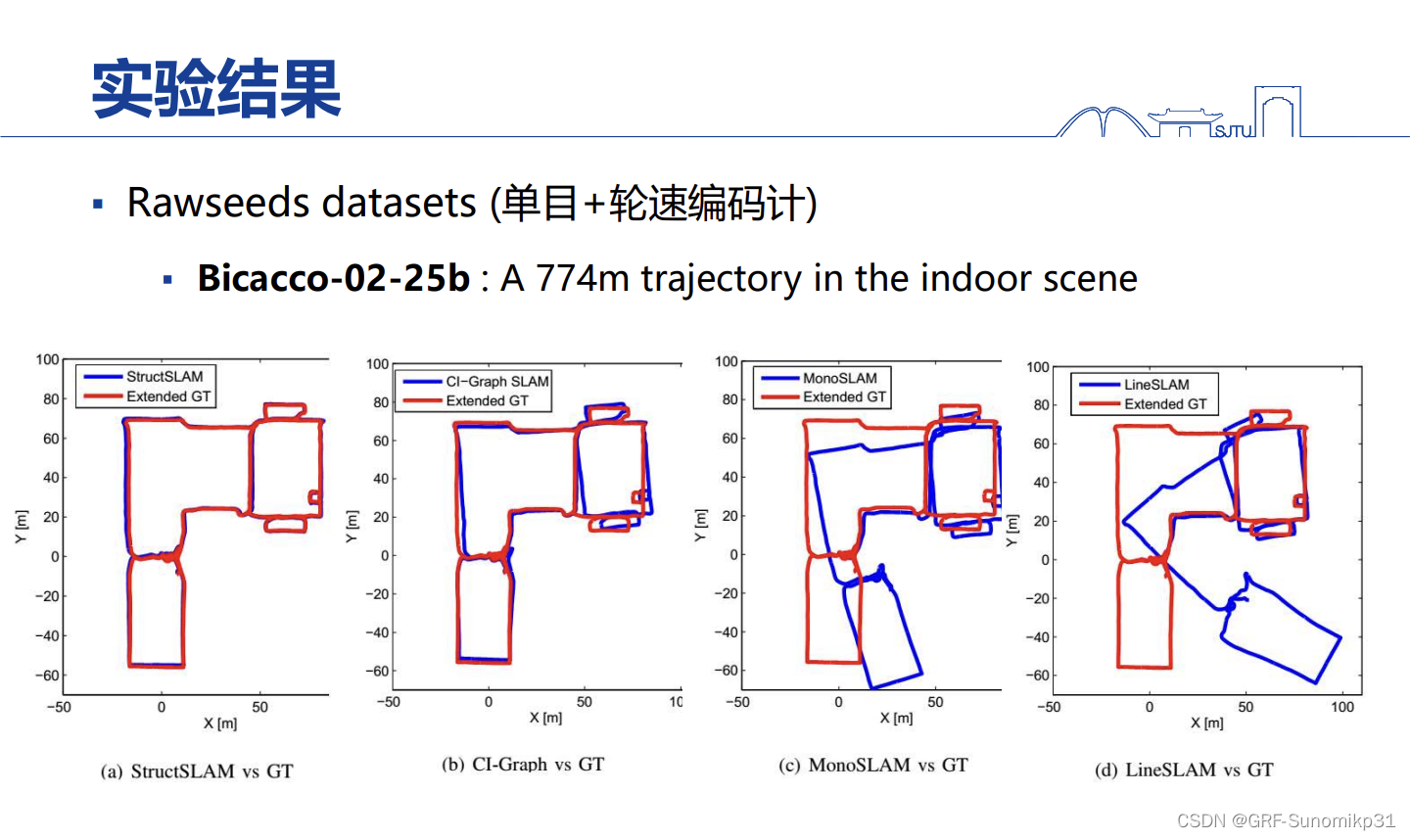
这里是一些对比,这里是Rawseeds数据集,这个数据集是一个很早的室内机器人数据集,这个数据集场景是非常大的,整个场景有700+m;这里加了个轮速计,因为该数据集场景有纯黑的部分,对于纯视觉SLAM的方法是跑不过去的,加轮速计对于SLAM是非常简单的,就是这预测的阶段用轮速计做下一帧阶段的预测。PTAM是小场景的跑不了这个数据集。最右边是直接用线条特征而不用结构化线条特征,可以看到还不如只用点的。
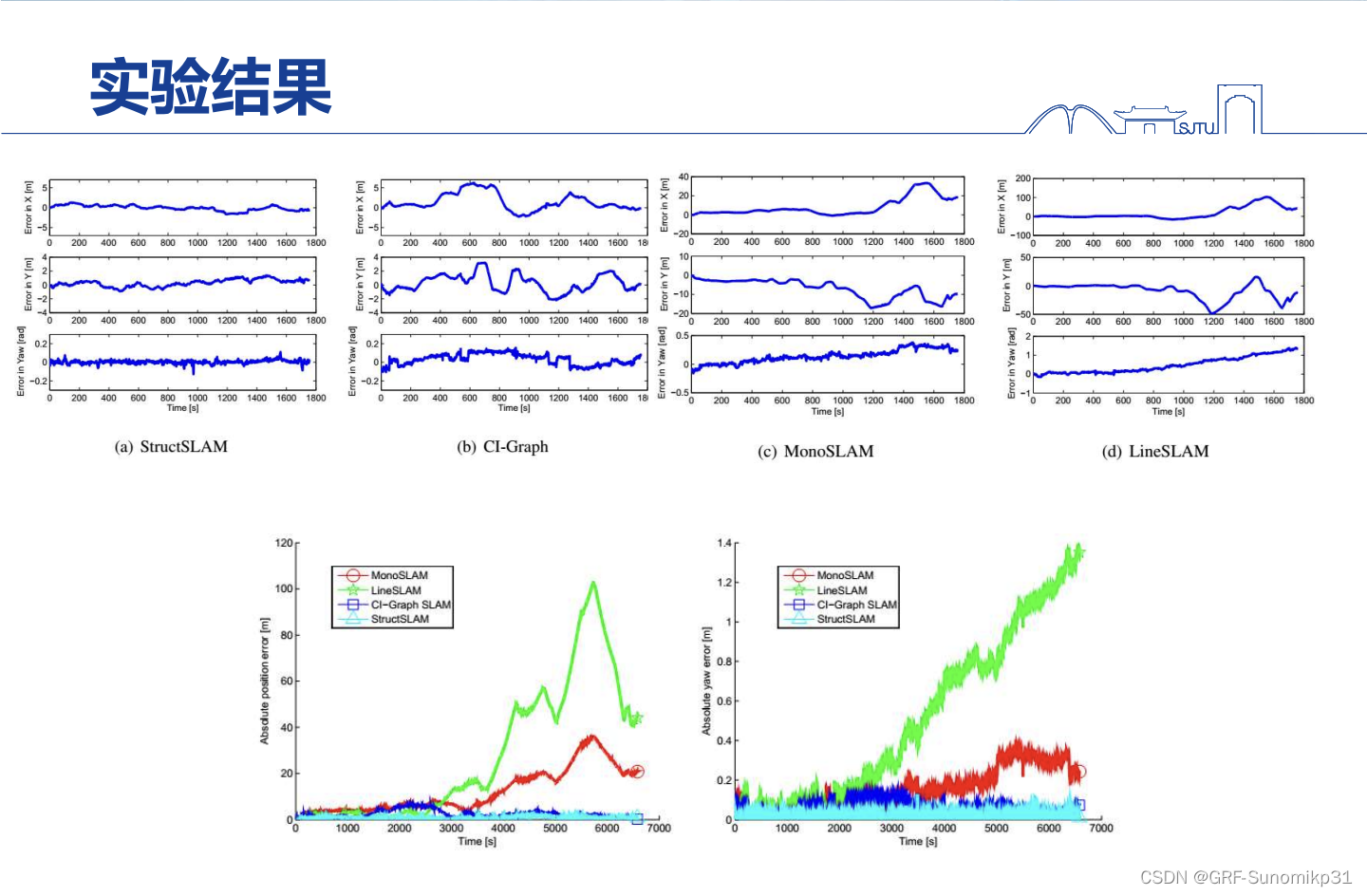
量化比较,可以看到加了结构化特征约束之后,误差基本上不会增长。
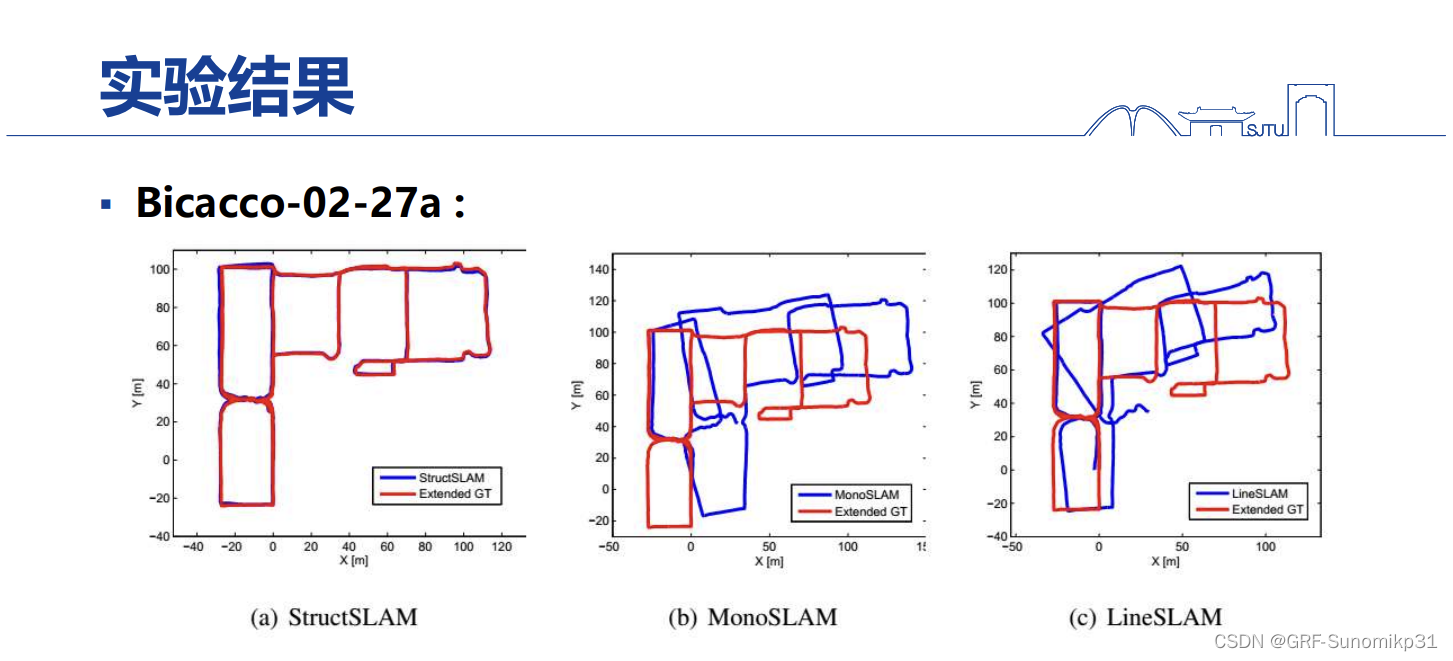
这是1000m场景下的效果。
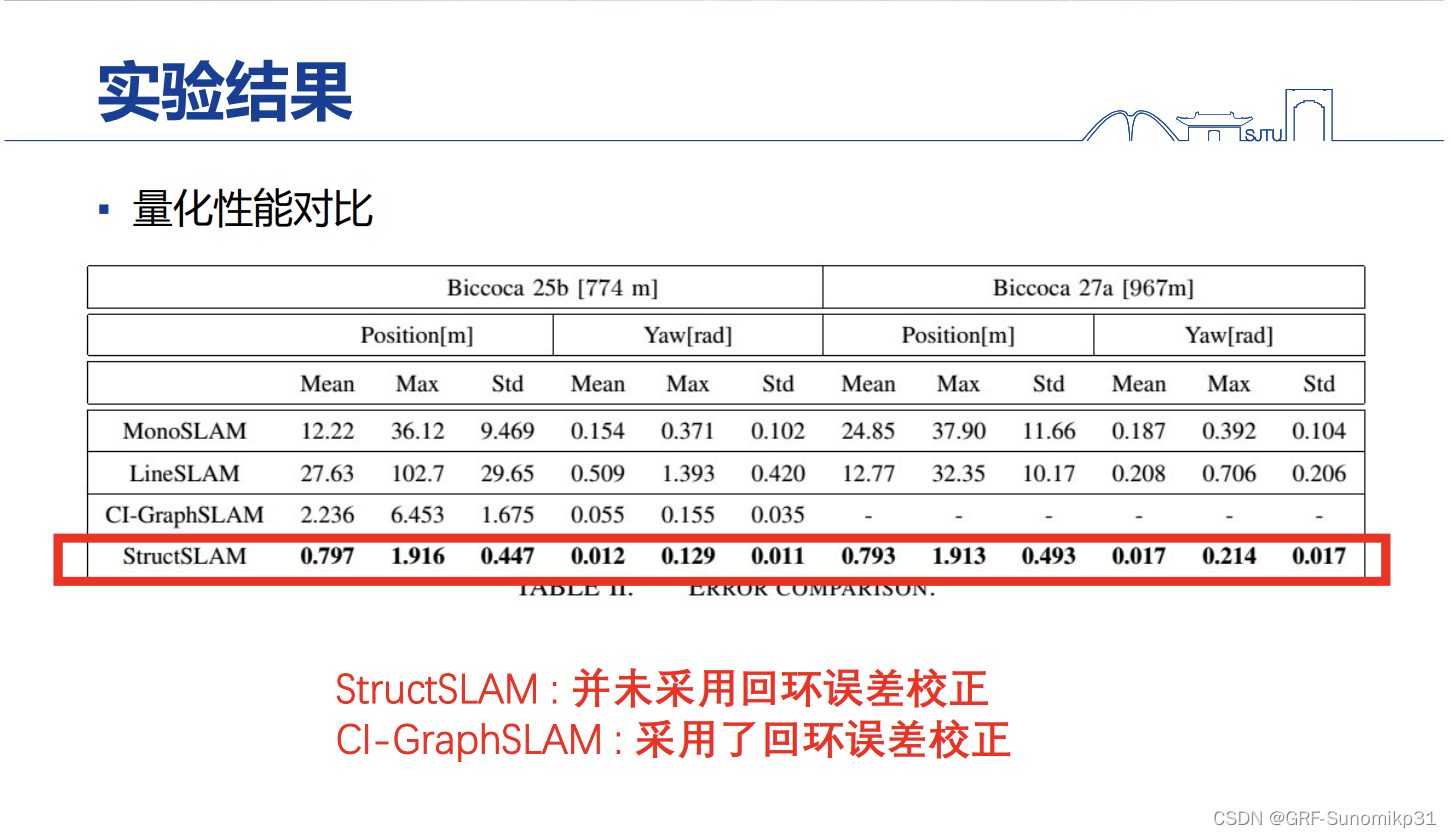
这里是量化数据对比,structslam是纯滤波器的方案,没有回环。
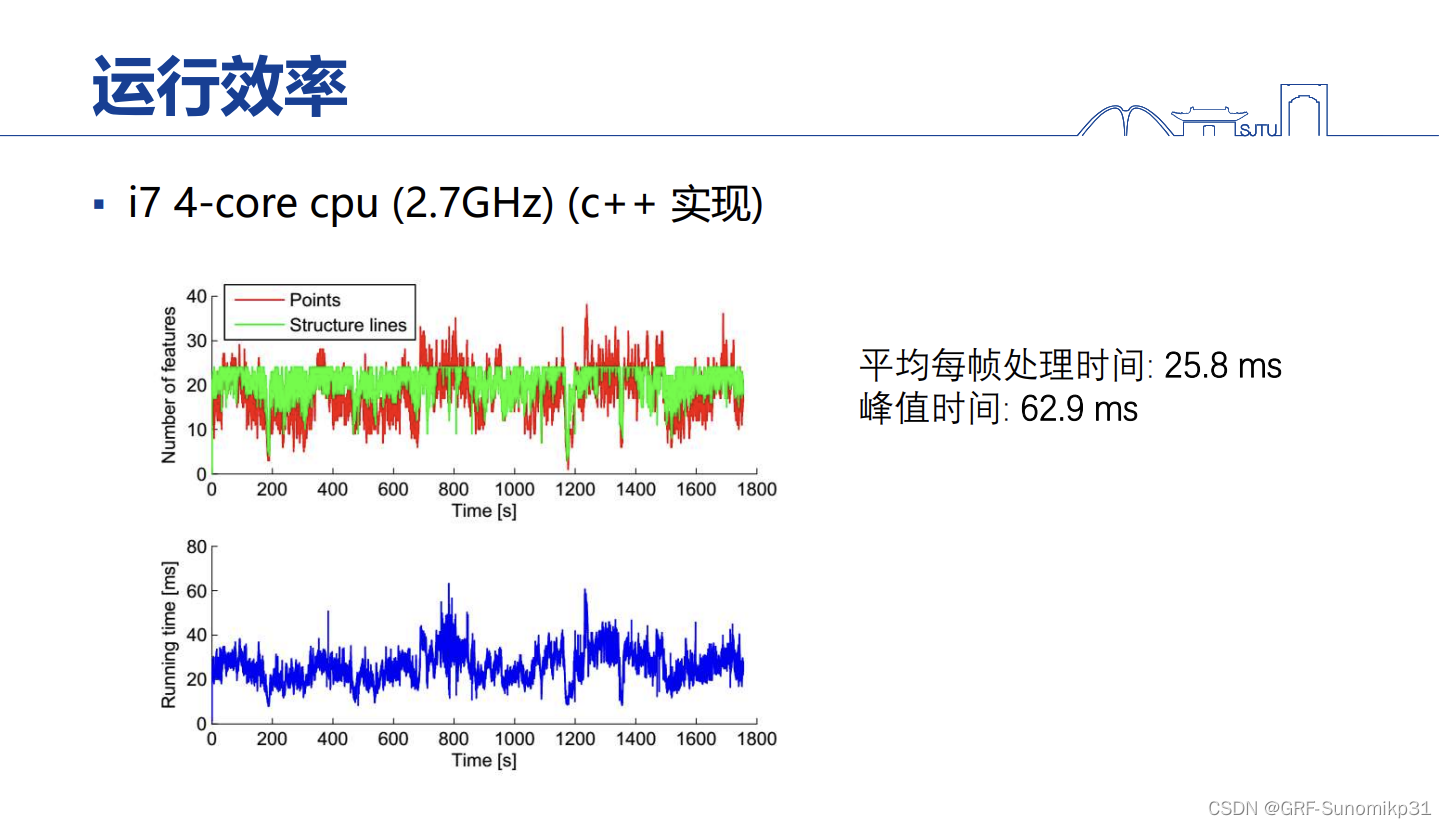
滤波的方案效率还是比较高的。
StructVIO

刚才的StructSLAM主要是基于曼哈顿世界假设,其实在现实世界有各种各样的建筑,包括斜的不规则的建筑,这种环境下如果直接用曼哈顿世界的话肯定会产生一些问题的,如何解决这些问题?
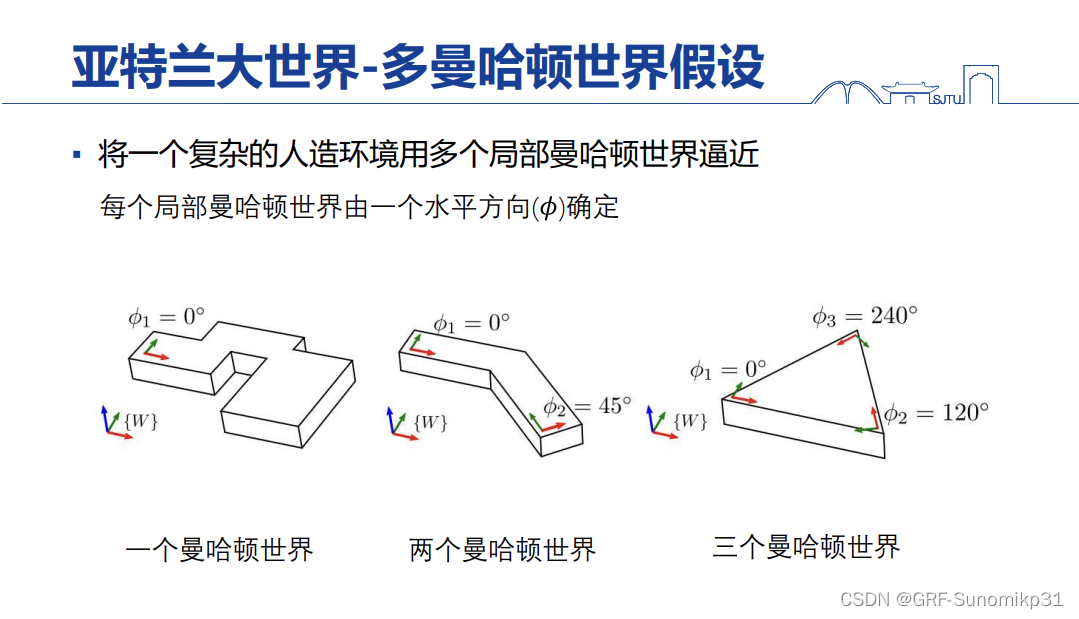
一个思路是:把这个模型进行扩展,其实这个扩展模型别人也用过叫做亚特兰大世界,这个假设是说局部可以是曼哈顿世界,整个可以是不规则的;另一方面就是说对这一个概念进行扩展,最右边所示,即使不满足曼哈顿世界,可以看作是三个曼哈顿世界的叠加,但是每一个曼哈顿世界可能只有一个轴是有效的。用这些方法也可以设计一个比较好的视觉SLAM系统。

这里介绍在19年邹老师团队做的StructVIO,核心思路也是用场景的结构化特性,这里用到多个曼哈顿世界叠加的模型也就是亚特兰大模型;这里对滤波器进行了修改,使用了多状态滤波的方法,多状态滤波在视觉和惯性融合方面有其优势,后面会提到;另外还比较早的公布了一个室内外视觉惯性的数据集,后面有一个叫做TUM-VI的数据集,其实邹老师这个数据集是比它更早公布的,当时市面上出了Euroc基本上没有其他数据集,而且设计思路是比较好的,就是一头一尾采集groundtruth,TUM-VI也是采用了这个方案。

技术细节的如上;这里面有一些trick还是比较重要的,是当时做实验做到的。
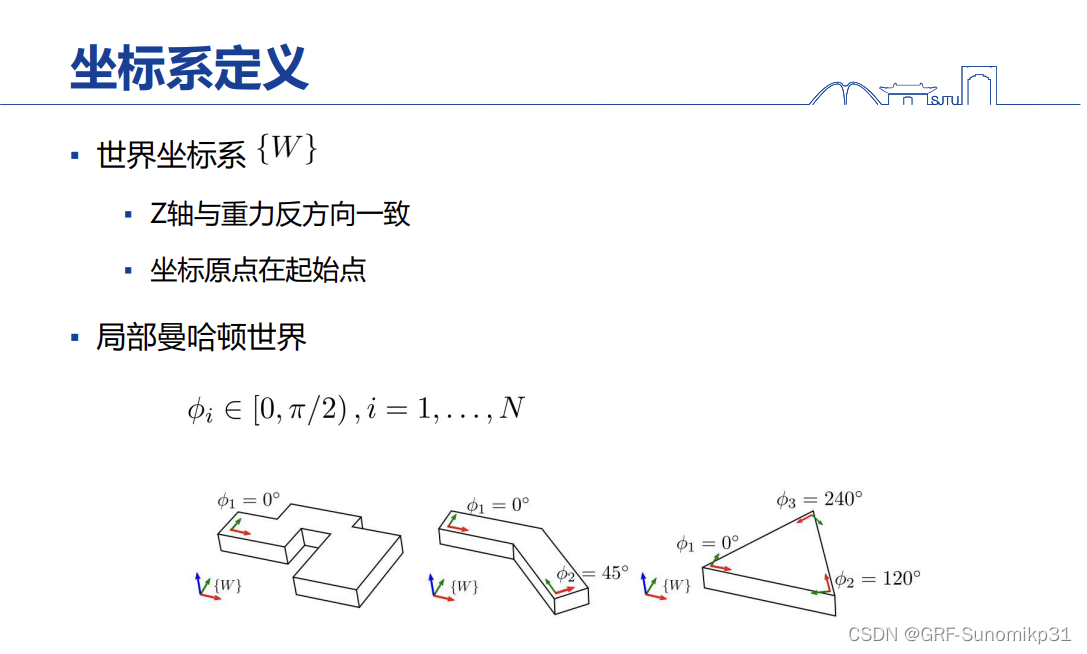
坐标系定义和structslam定义是一样的,不同点在于每个结构化线条是在local的曼哈顿世界进行表征的;每个曼哈顿世界使用一个水平朝向去表示。比如这里最左边的曼哈顿世界只有一个参数φ=0。曼哈顿世界的φ也是作为状态里面的一个变量一起去更新估算的。
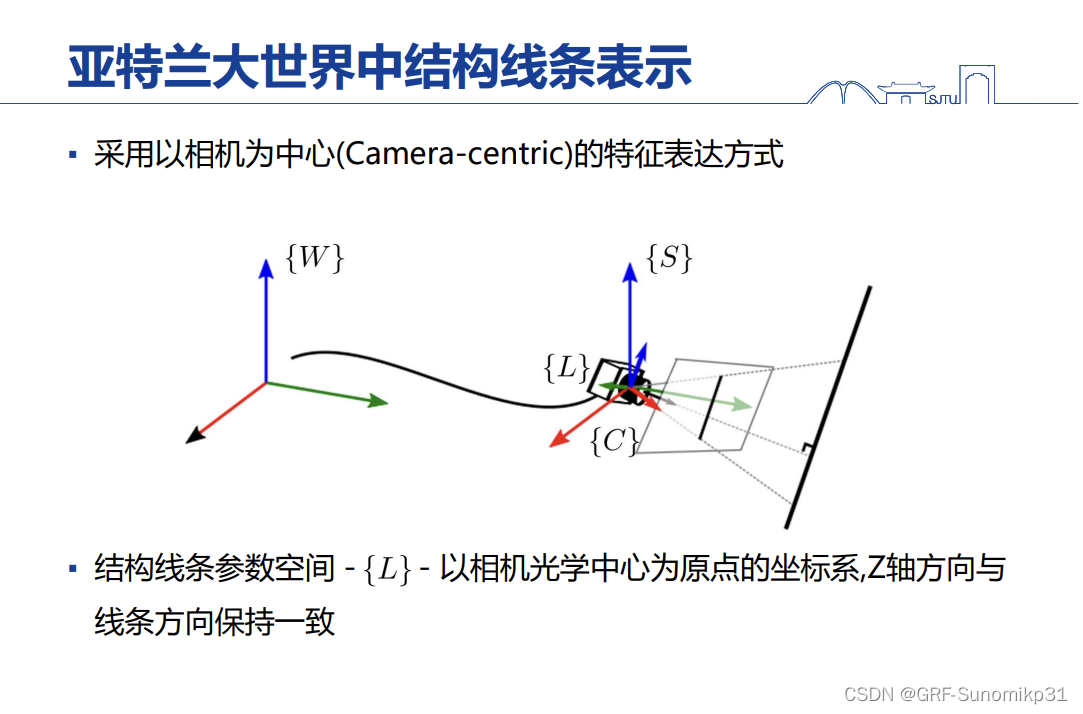
这里是结构化线条的表示,和structslam大同小异,无非这里是嵌入到局部坐标系中;在起始帧做参数化。
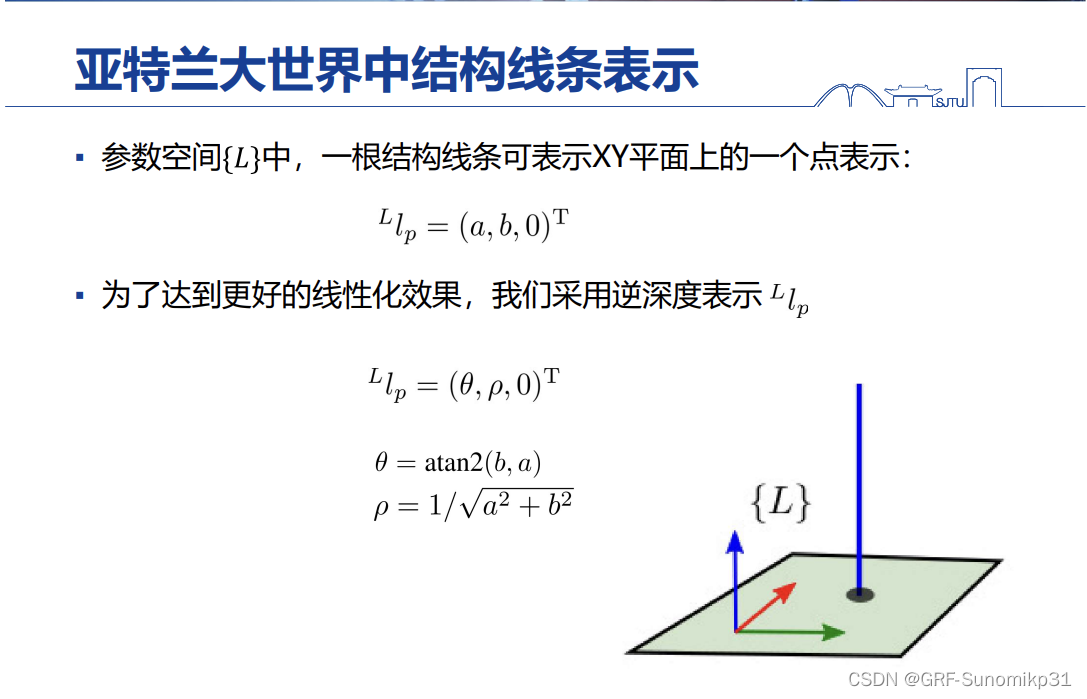
这里参数化的方式和structslam是一样的。
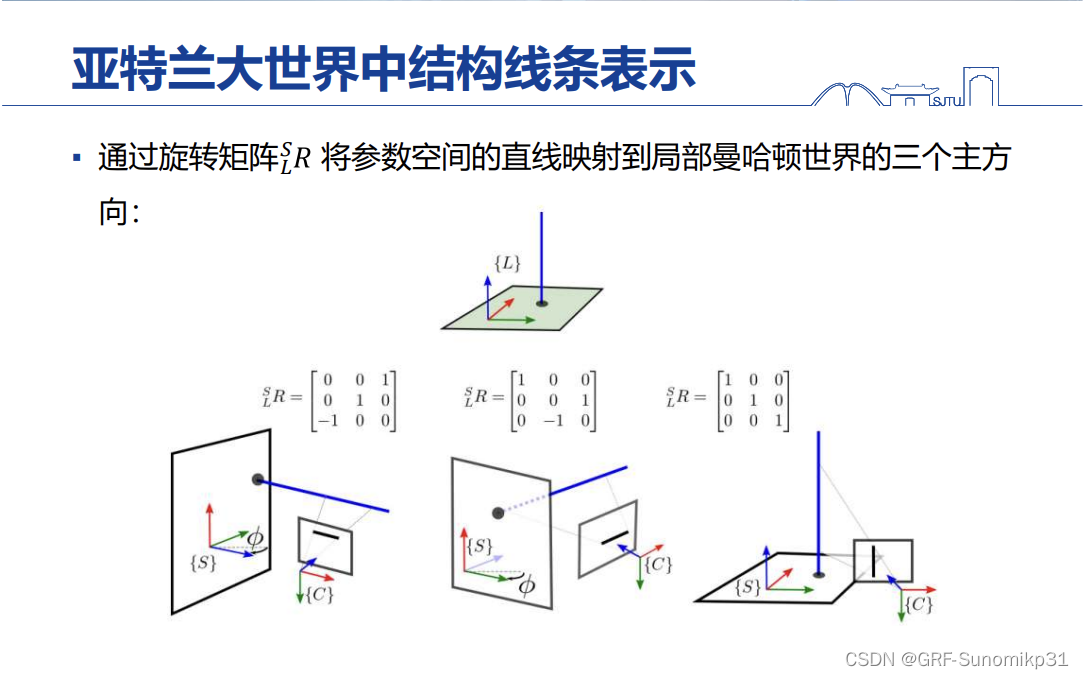
这里通过三种旋转,将参数空间的直线变成三个方向的直线,这三种旋转是固定的。

最后通过水平的旋转变换到各个局部的曼哈顿世界中。
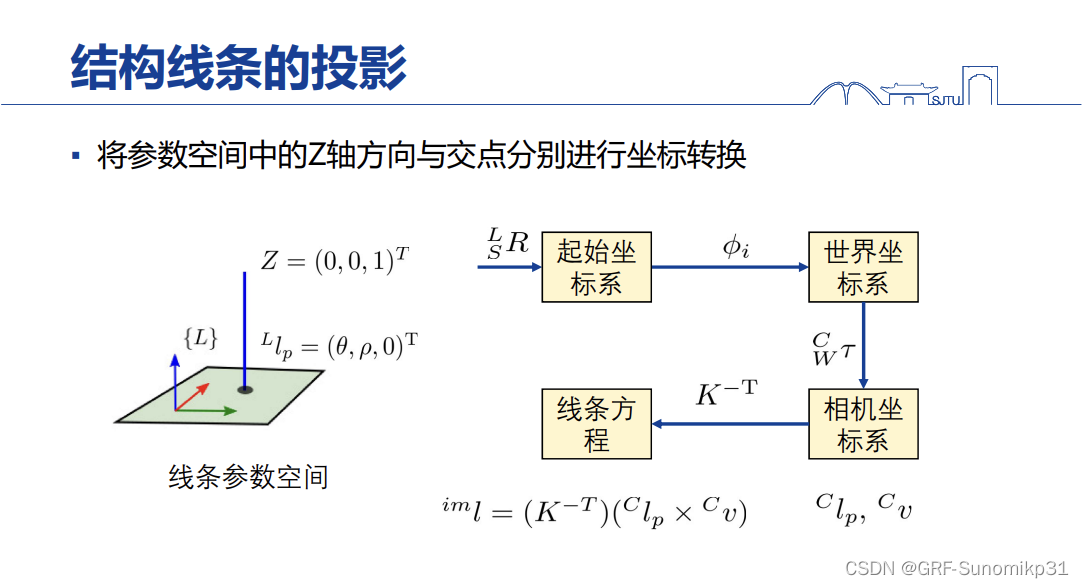
整个流程如上。

后面其实是说怎么设计滤波器的问题,
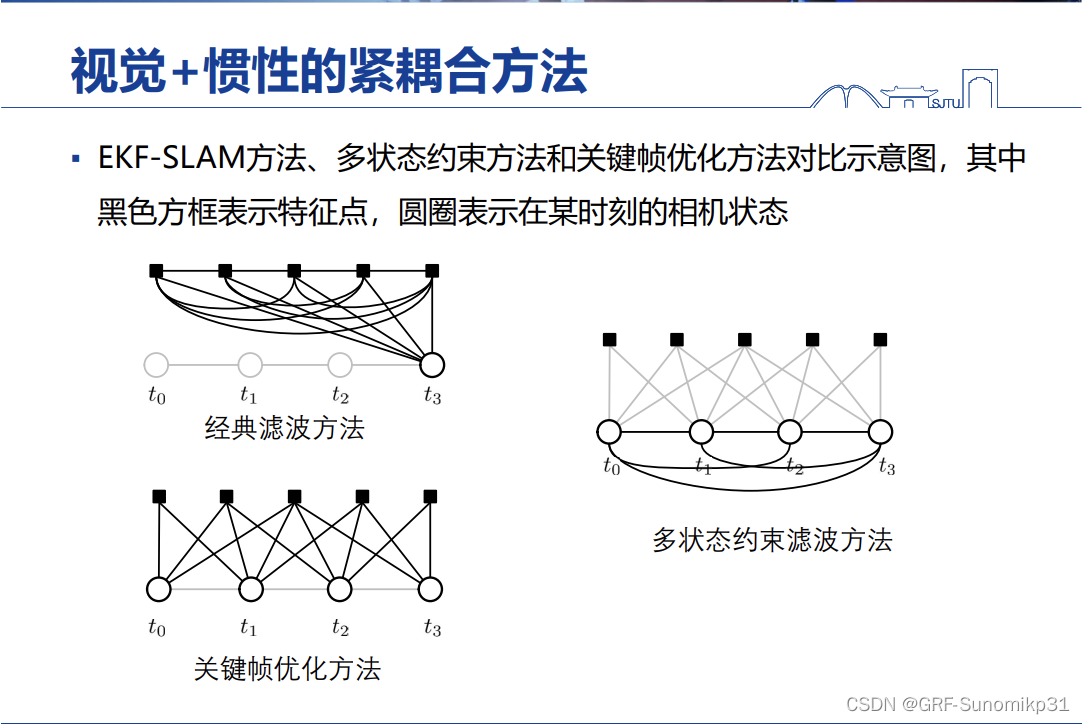
structslam用的是经典的滤波方法,圆圈表示状态,黑点表示特征的状态,在经典的滤波框架中状态量包括当前的相机的状态以及所有特征的状态;这会造成滤波中协方差矩阵的维度和状态的维度一致,但是做卡尔曼滤波的时候需要对协方差矩阵求逆,当协方差矩阵很大的时候求逆会非常慢,这经典的 滤波方法中协方差矩阵都不能太大,一般取得都比较少。关键帧优化的方法都很熟悉了。多状态约束滤波方法状态中只有关键帧的参数,并没有将特征的参数放到状态里估计,好处在于只有关键帧的状态,维度会非常小。

三个框架的区别。从鲁棒性的角度多状态约束滤波方法是有优势的。

这里是一些细节了,怎么去实现一个多状态约束紧耦合滤波方法;这里是structVIO采用的状态设计。这里维度是4+3+3+6=16维,旋转用四元数4维表示。

多状态约束滤波方法可以实现解耦的效果,这里有个问题是观测方程依赖特征的参数的,这里需要对观测方程进行出了,使得这个观测方程不需要特征的参数,只需要历史帧的参数。

一阶泰勒展开,不仅考虑当前帧还要考虑历史帧。

这里用了MSCKF的原理方法。
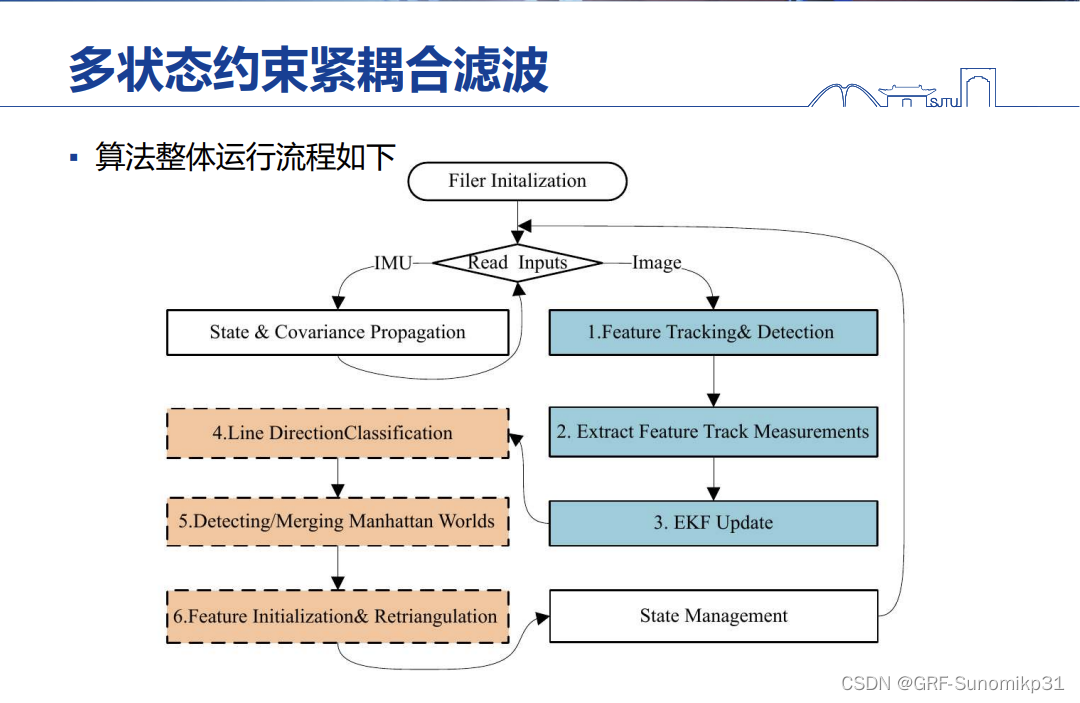
这里算法流程和structSLAM差不多。

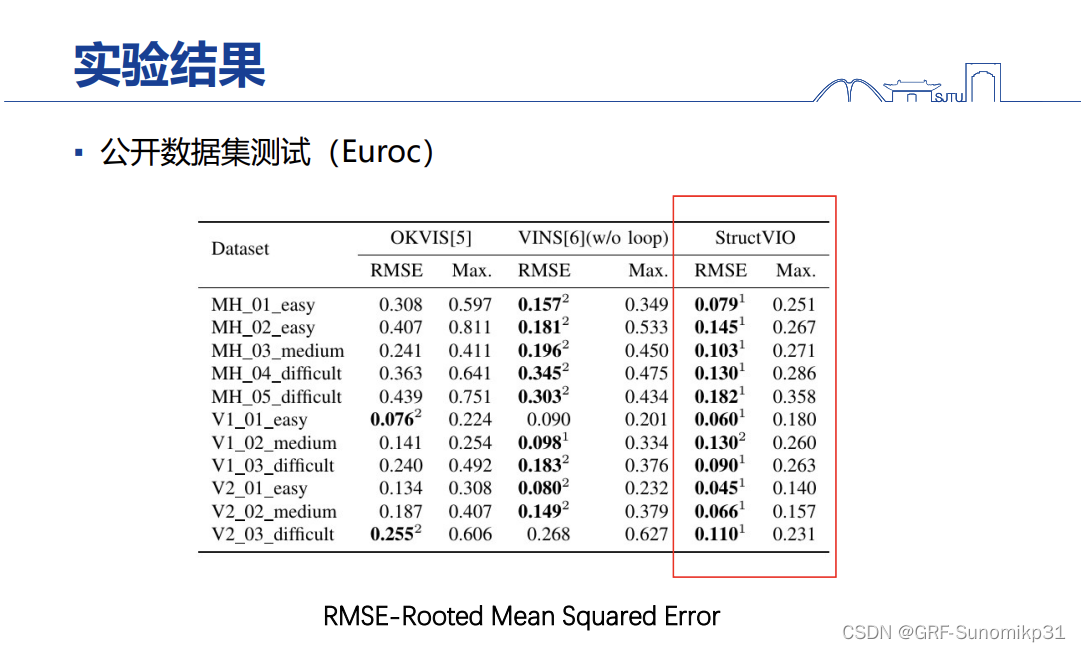
展示Euroc数据集效果。
这是一个比较。
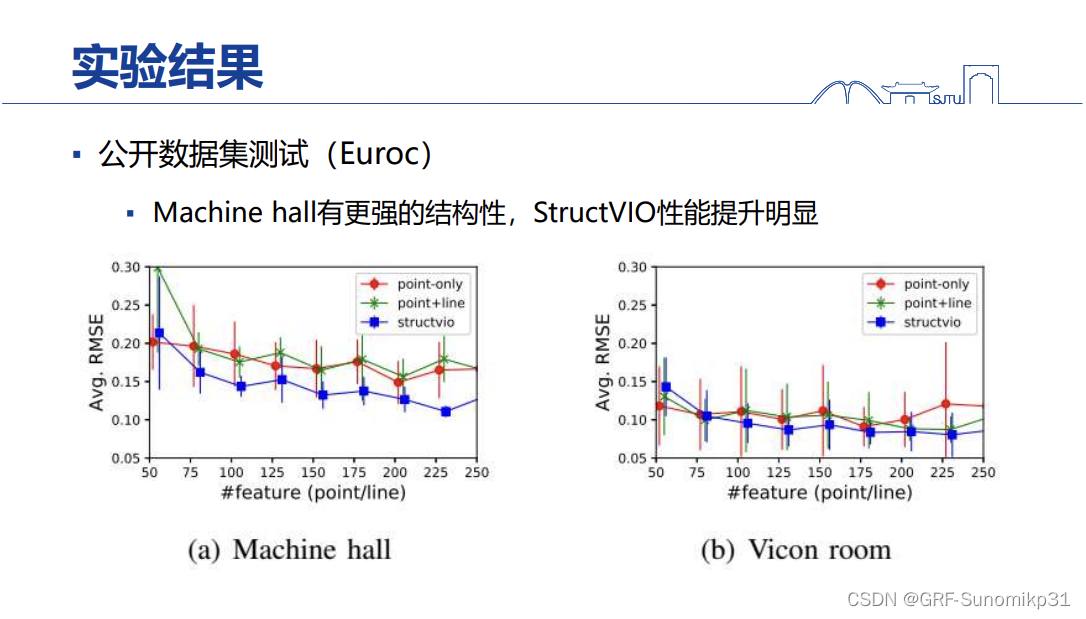
如果环境本身有较强的环境性,那么提升是非常明显的。上面展示了用点和线(非结构线)的方法,和纯用点其实差不多的。
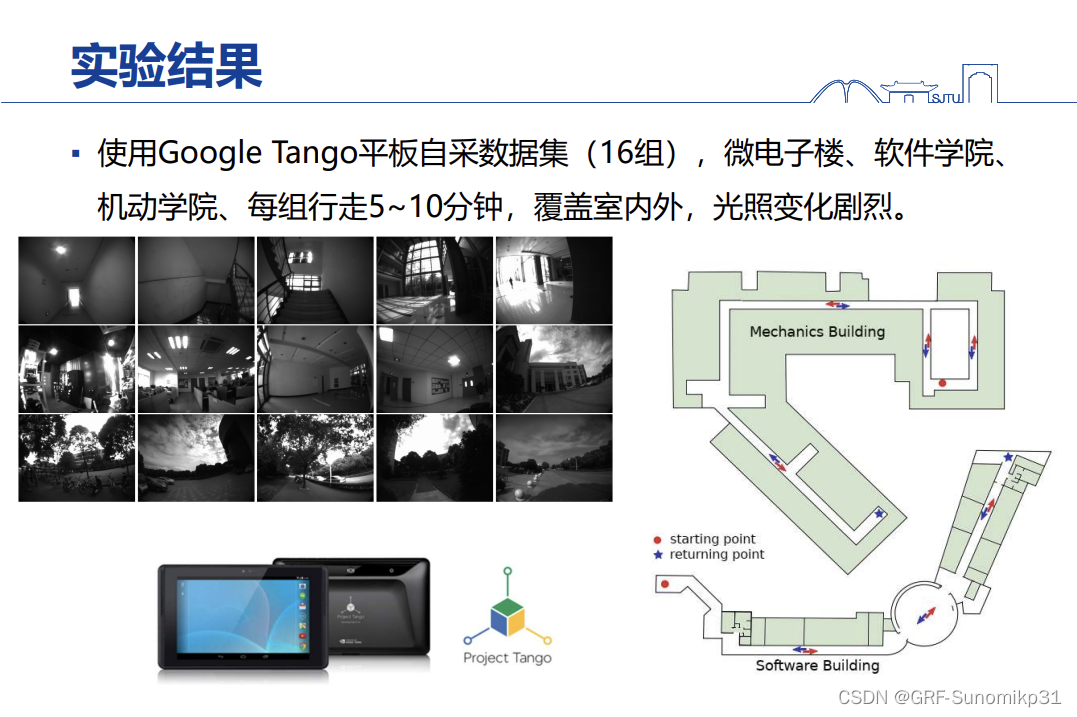
采了一些数据评估了一些比较大的场景。这里比较好的地方是有个鱼眼,而且IMU同步比较好。
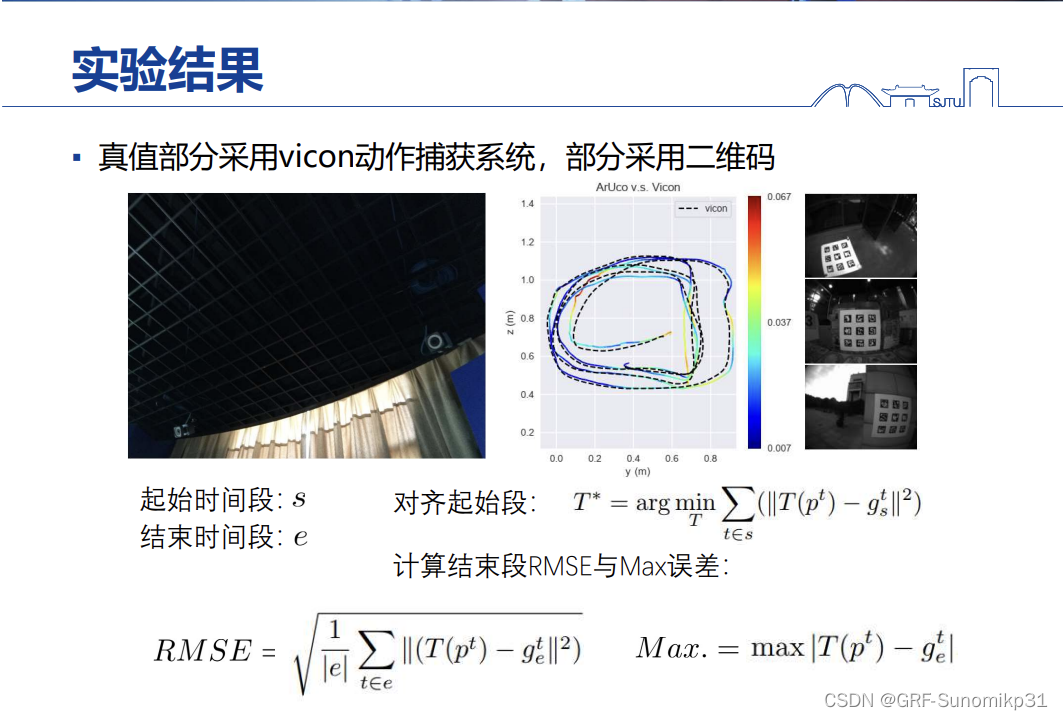
真值的获取方法,一般有动捕会一头一尾采集真值;其他的地方没有动捕的地方,用二维码获取。
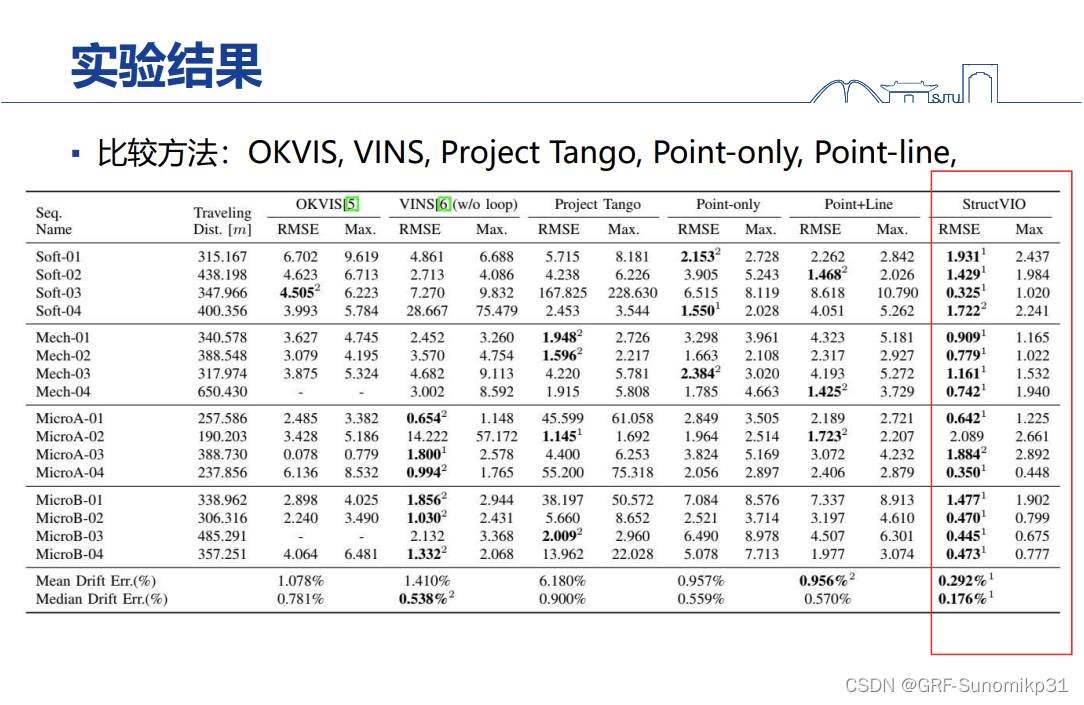
测试结果,tango是ARcore的前身,其是 用了MSCKF的路线。倒数第二列是用点和线(非结构化线条),线的加入基本上没有什么提升,加上去起不了什么作用。
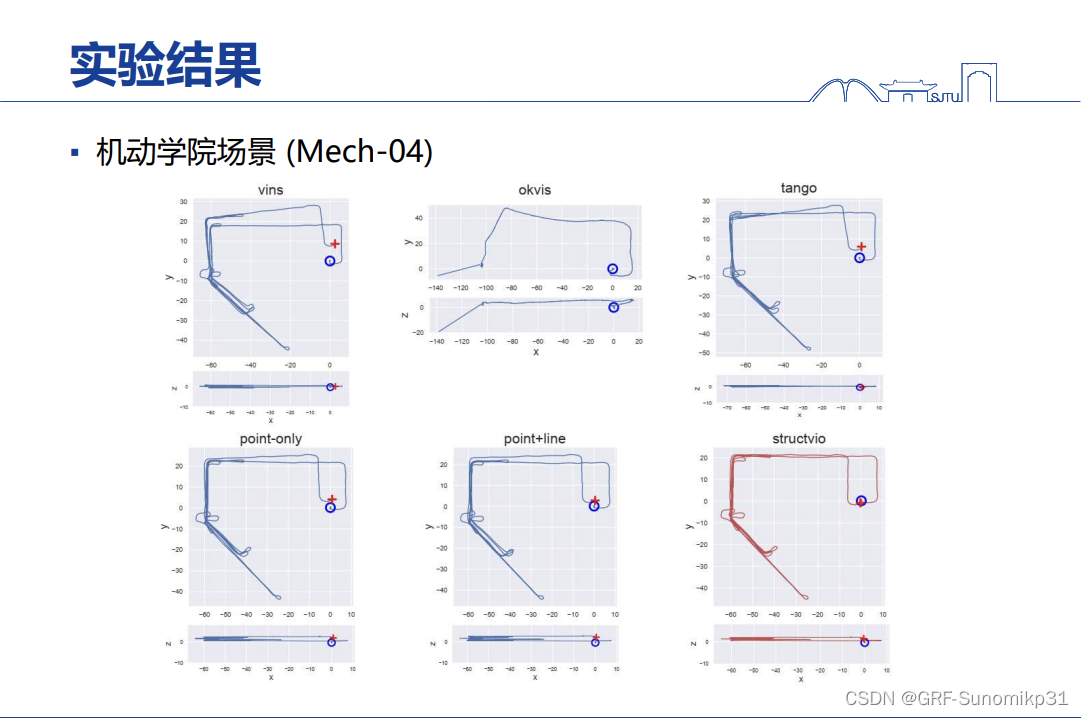
具体的一些结果。
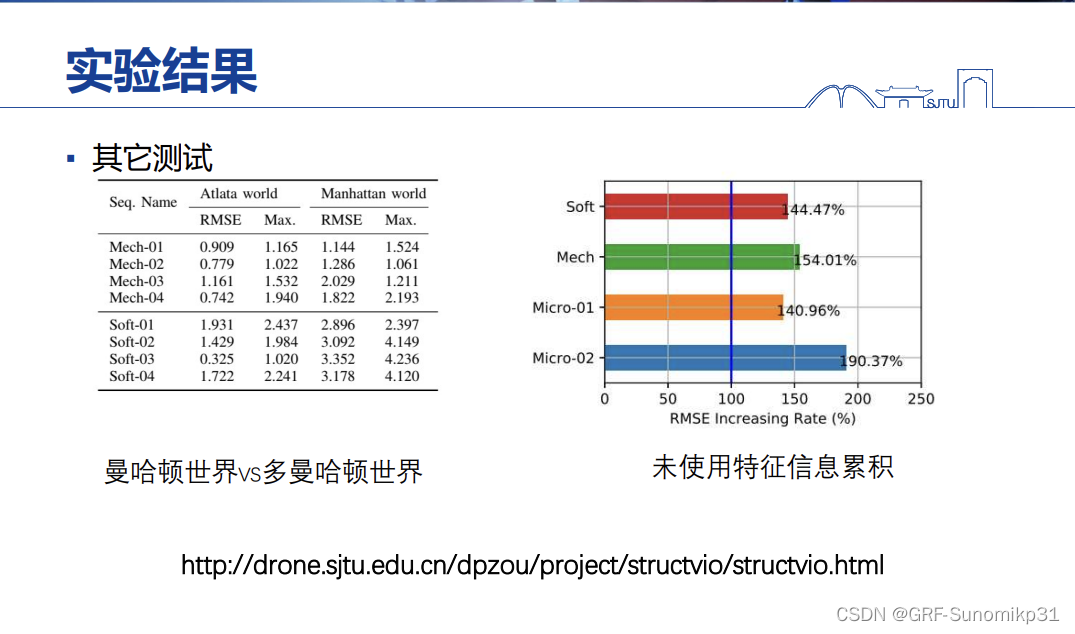
这是一些trick,左边是单个曼哈顿世界和多个曼哈顿世界的比较,多个曼哈顿世界的方法可以动态的检测新的曼哈顿世界,是非常有效的。
TextSLAM
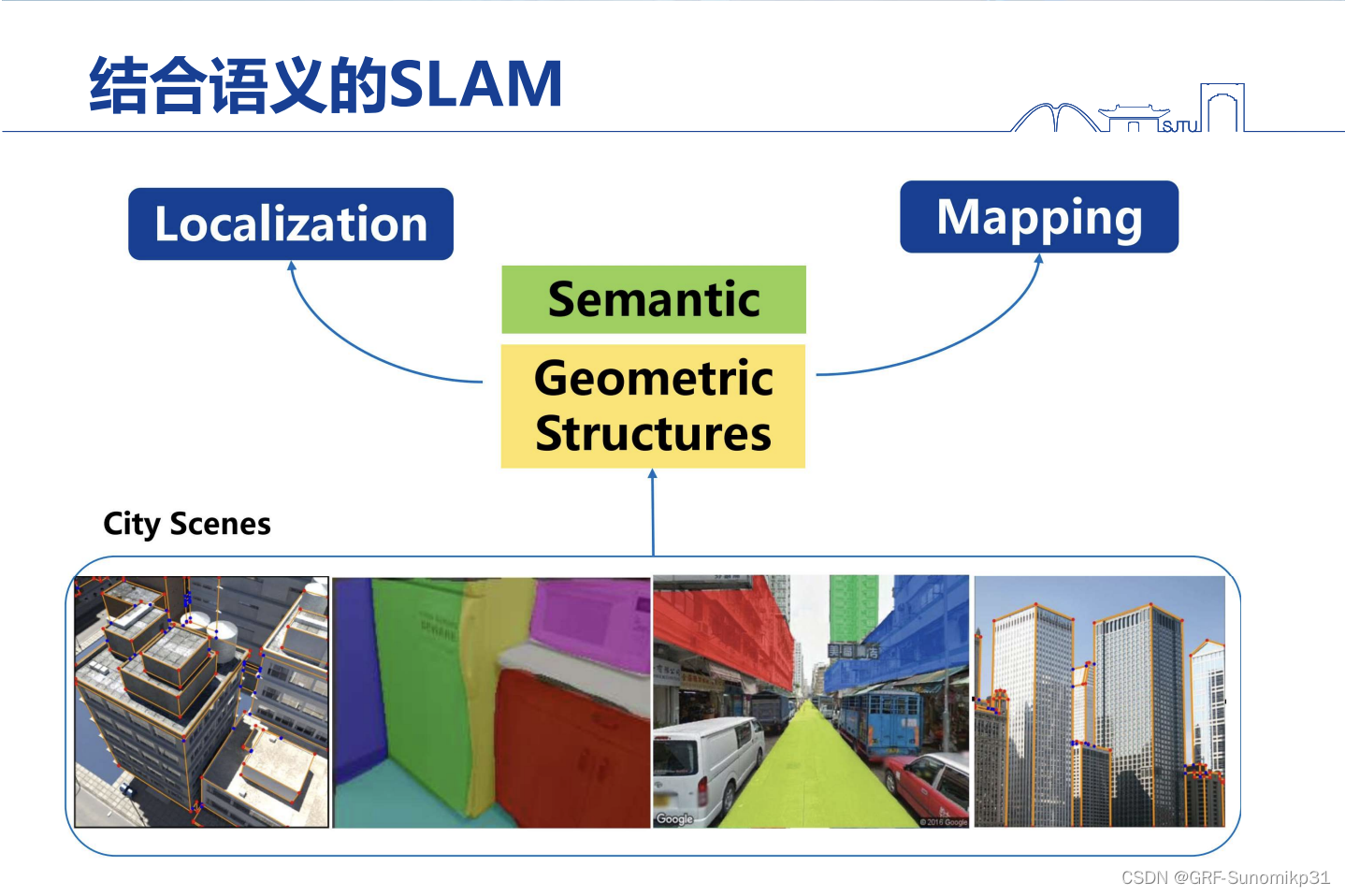
这部分主要是考虑怎样结合语义做SLAM,因为机器人在场景中如果能更好的理解场景,肯定会对后面的人机交互提供很好的帮助;前面是充分利用了结构信息,那如何利用语义信息呢?
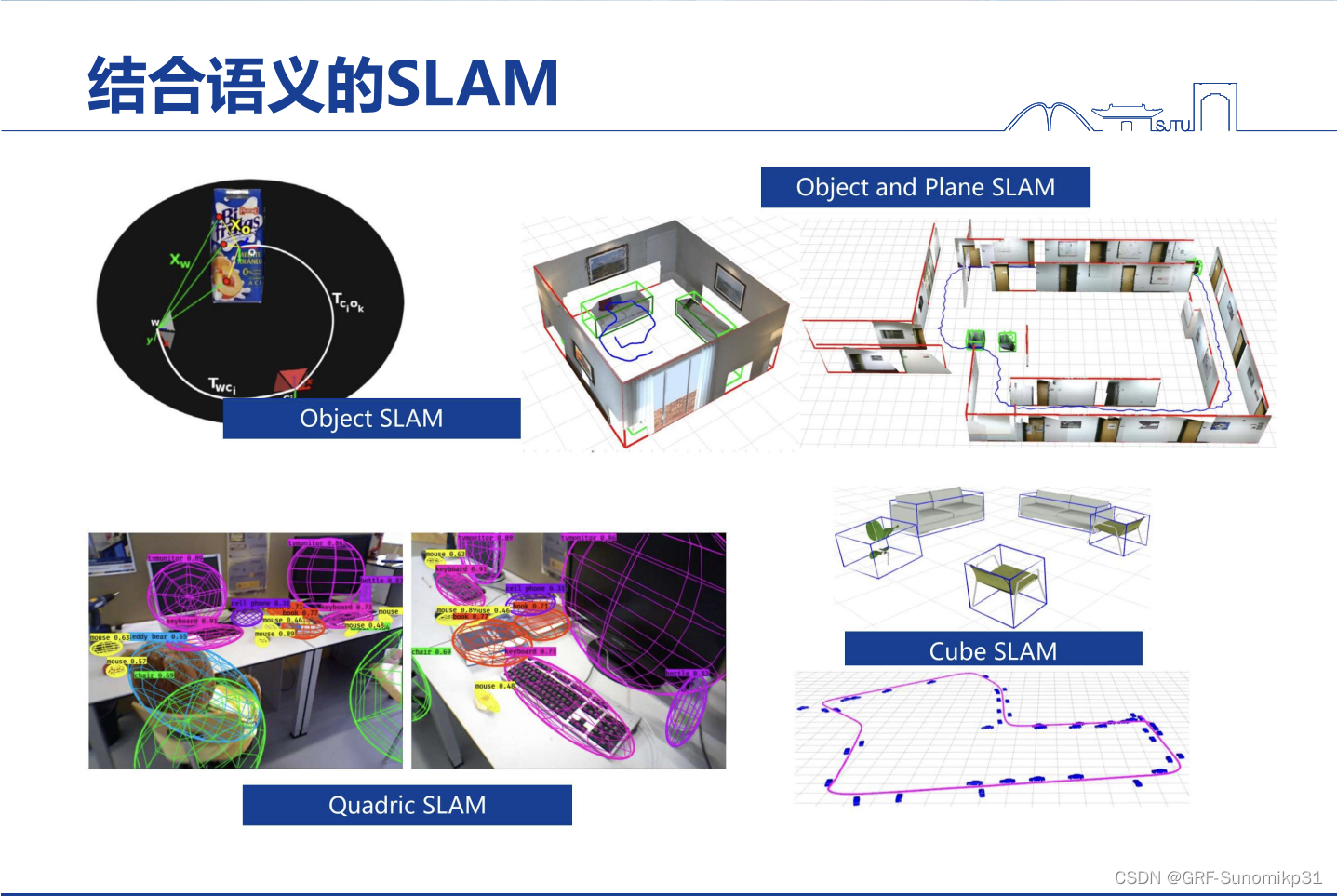
结合语义信息由很多做法,大部分方法集中于两大块,一是将场景中的背景分割出来,包括墙、人、天花板等等,每一个部分称为一个语义,然后构建一个有标签的地图;还一种是将场景中的物体做一个标注,生成一个带有语义的object的地图;两者都有其道理,邹老师觉得可能更加重要的是怎样把日常生活中的文本标识用上,因为这些是真正的语义。

因为文本就是给人看的,人就是通过这些文本的标识判断、理解场景;类比人进入陌生的场景都是通过文本信息来进行导航的。
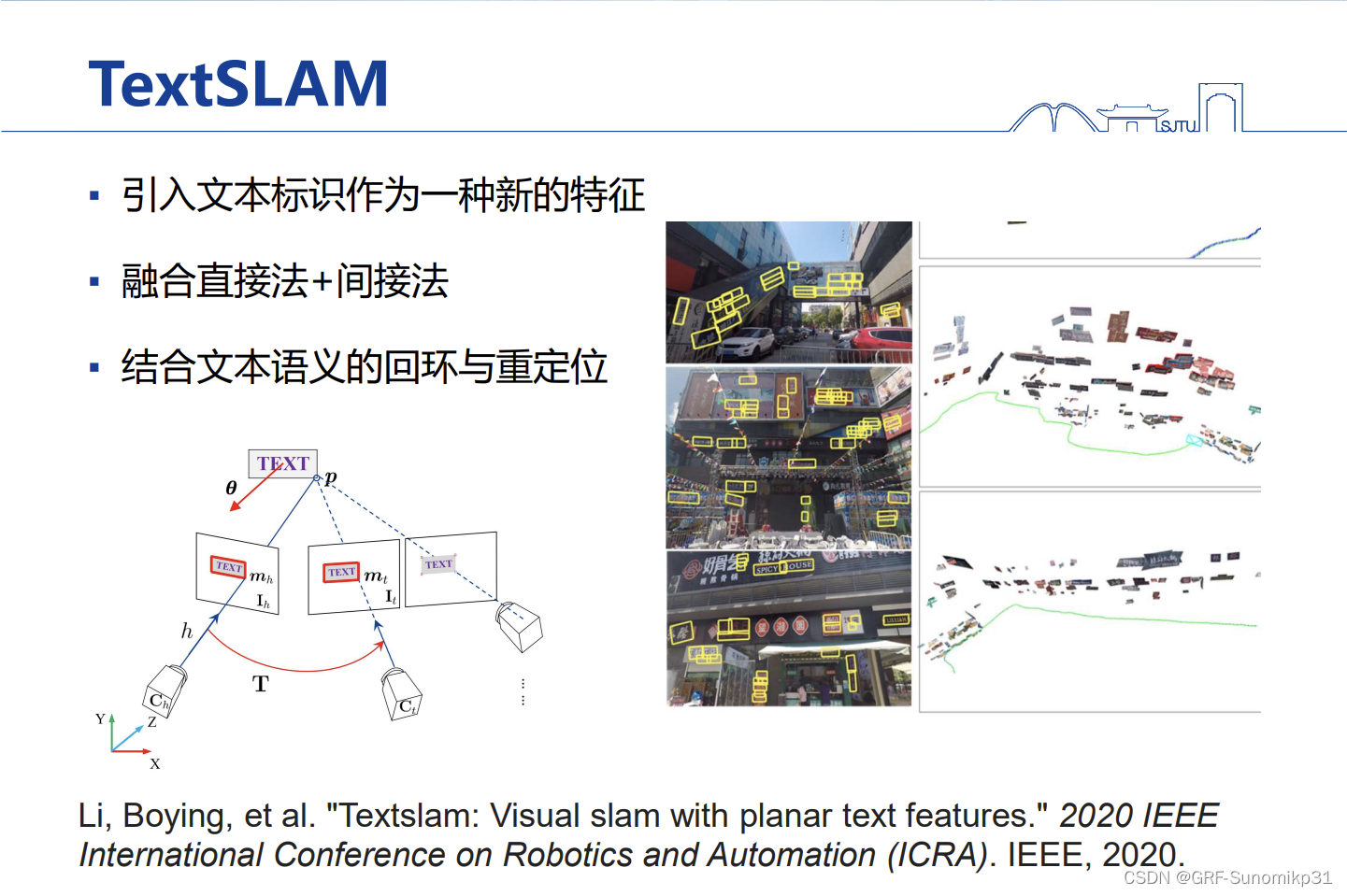
所以说本文信息是非常重要的,如何利用这些文本,邹老师团队尝试并使用提出了TextSLAM这项工作;再视觉领域,文本检测以前是非常难的问题,但是现在有神经网络的加持,所以文本识别变得非常容易,现在文本检测每年都有新的模型,而且越来越好;
在这个趋势下,想将这些文本检测的神经网络结合起来,做一个基于文本标识的SLAM系统;文本是一个天生就比较好的视觉SLAM特征,原因有以下几点,首先文本的纹理非常丰富,其次是文本是富含语义的,第三点是文本标识一般是在局部的平面上,平面特征有助于提供鲁棒性(精度可能会提高,但是更重要的还是鲁棒性);所以说如果能把文本识别出来,语义信息是非常重要的,这些语义是和光照无关的;
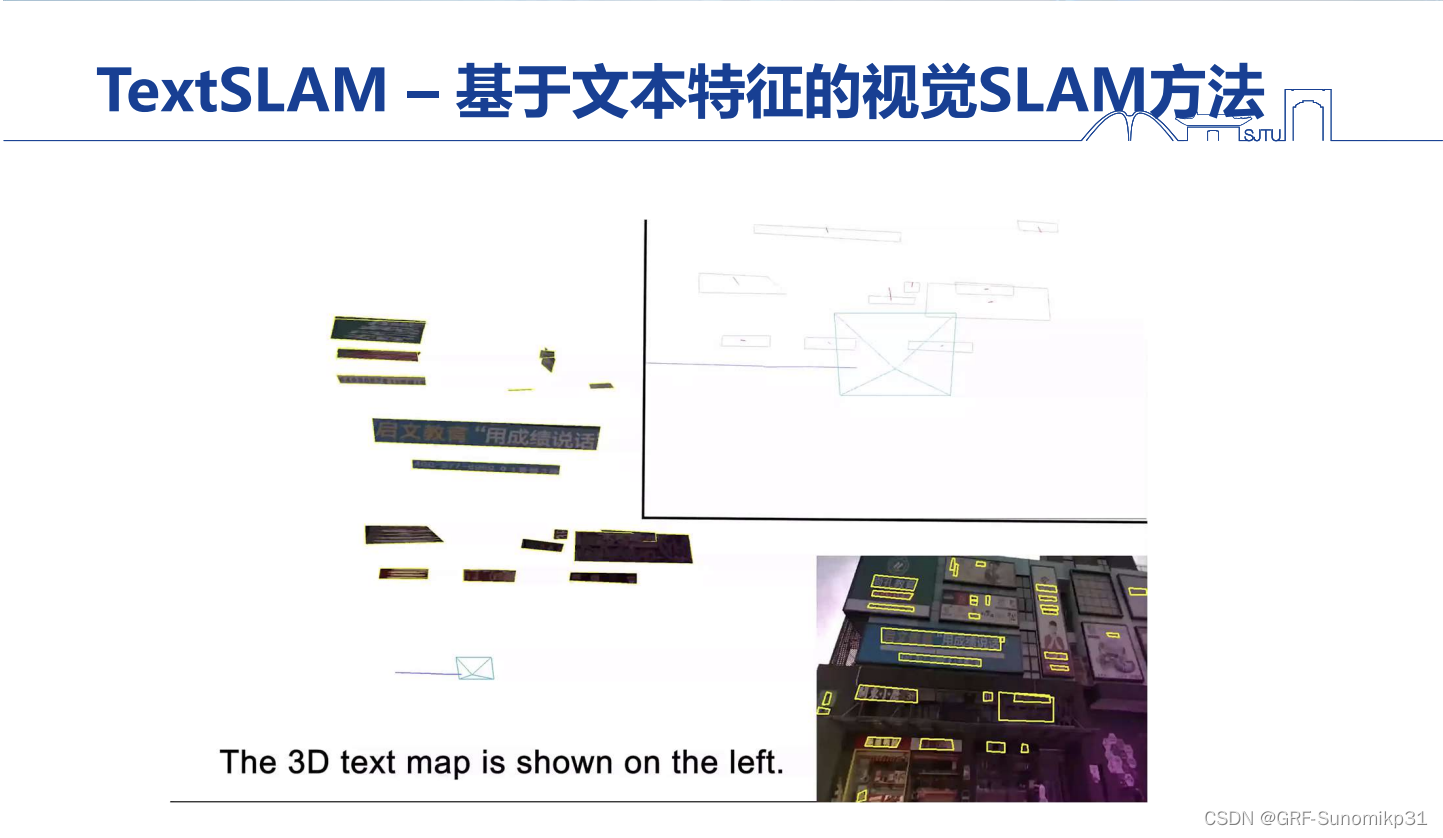
这里展示的TextSLAM的一个视频效果,通过文本检测的方法,将一个商场环境,将其中的文本,包括招牌、广告牌等检测出来,并将其集成到视觉SLAM中,构建一个文本的三维地图;首先文本信息有助于提高SLAM的稳定性和精度,其次文本三维地图有语义信息,可以更好的做回环,一般的回环要求位置不能差太远,因为特征描述子对视角敏感(视觉切换大描述子不同),但是文本不会出现这个问题,即使视野变化非常大;

第三是上面提到的,文本信息是局部平面的特征,所以其处理模糊比较更加匹配;
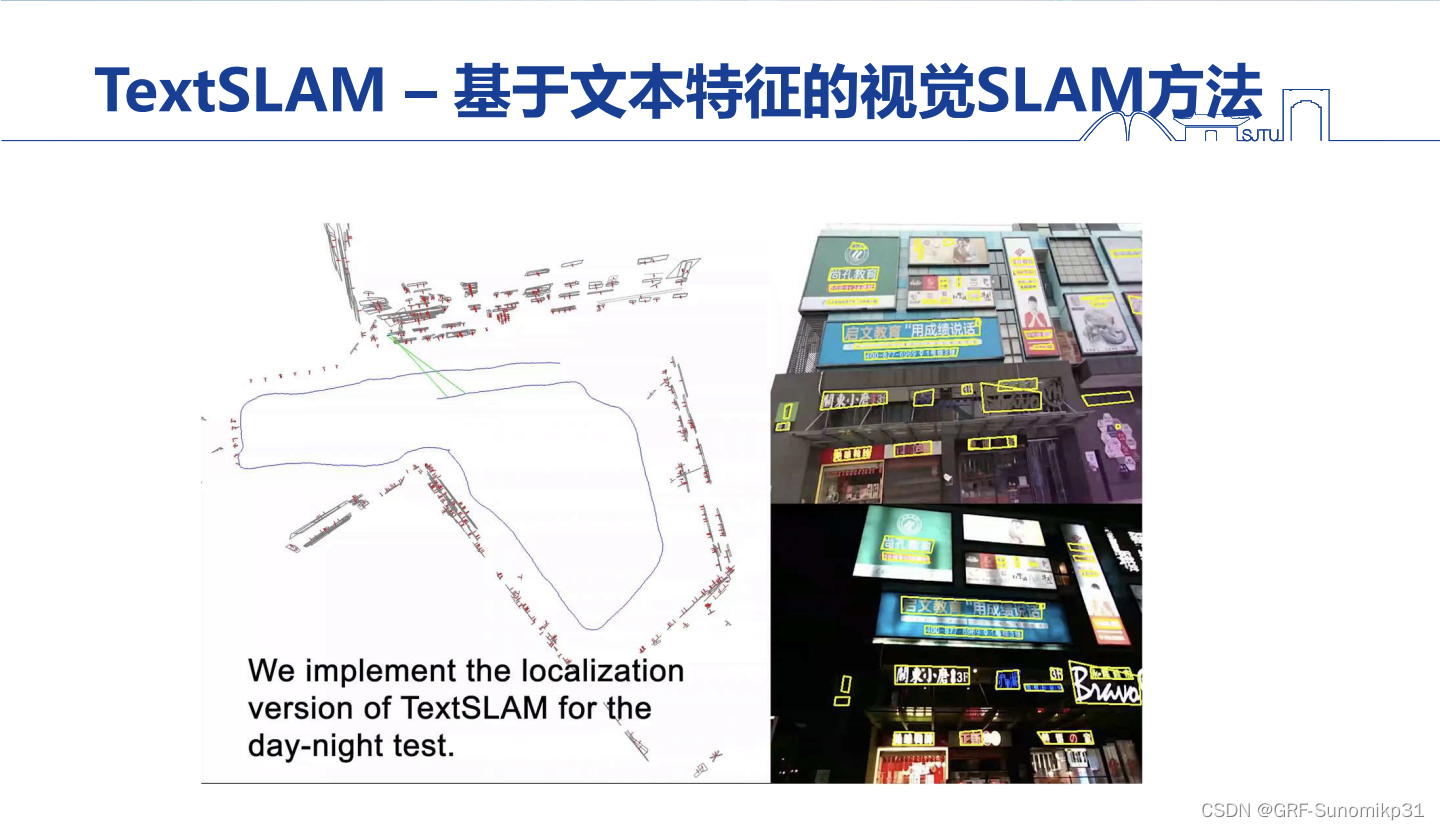
另外,如果将文本地图预存下来,那么当做定位的时候(重定位),这个地图可以在白天和晚上重复使用。
StructDepth

邹老师团队在mapping部分也想着做一些工作,因为视觉SLAM构建稠密的地图是非常困难的,特别是在室内环境,室内环境面临的主要问题是墙上的特征不够丰富,这样会导致后面做像素级的特征匹配会非常困难;最近兴起的有自监督单目深度估计的这个技术,这里也是前几年出现一个突破性的技术;单幅图像估计深度在早期的计算机视觉领域是一件非常困难的事情,相当于将三维投影到二维信息缺失的非常多,这时想要做从二维图像恢复三维这个逆问题会对应无穷多个解可以解释这个图像;
自监督单目深度估计的原理如下:使用图像本身,用神经网络用这幅图推算出一个几何模型,通过这个几何模型将这个视角的图像变化到另一个视角,另一个视角刚好也拍了一张图像,自监督是说将拍出的照片和预测的照片进行比较,其中的差异可以用来训练网络模型;训练信号是比较两幅图像,那么在室内遇到的问题是当纹理不够丰富的情况下,监督信息比较弱。这时候怎么办呢?这里也是充分利用结构化信息;

这是比较有代表性的MonoDepth2,只要一副图像通过神经网络就能输出深度;如果是两幅图像叠加在一起输入到pose network中,这个网络就能输出两幅图像的相对位姿;这里用到的图像是室外场景的图像,室外图像纹理比较丰富,可以看到上面的效果还是比较不错的。

如果将MonoDepth2直接用于室内可以看到质量不是很好的。分析一下还是因为监督信号比较弱,因为缺乏纹理。
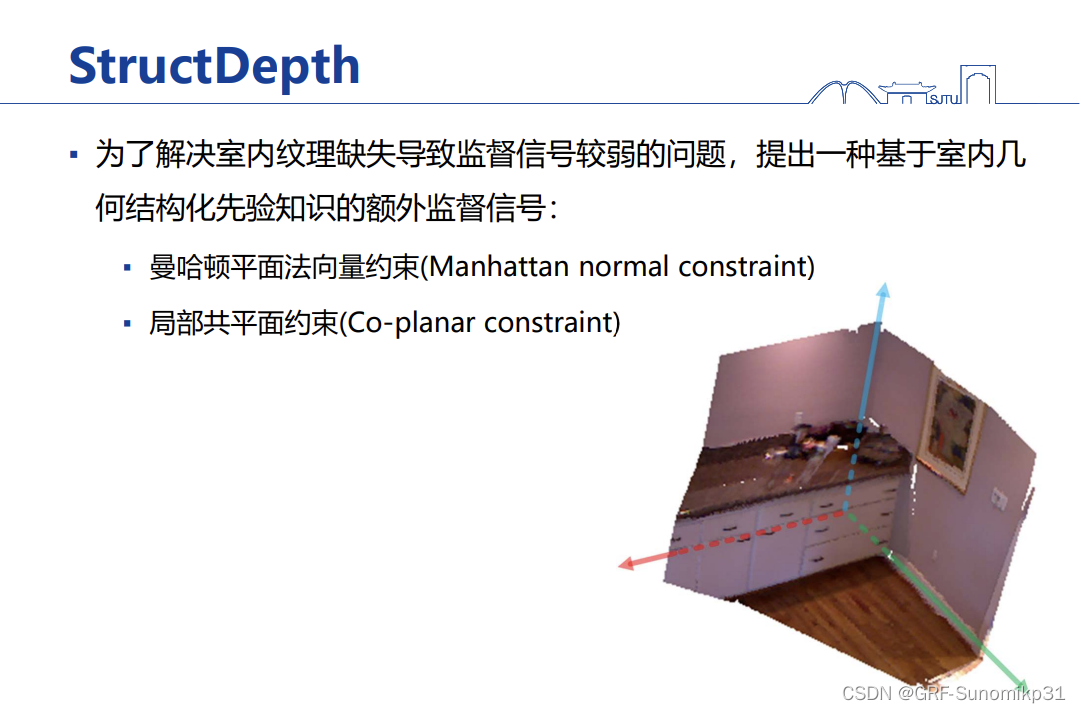
为了解决因室内缺乏纹理导致监督信息比较弱的问题,邹老师团队提出充分利用结构化特性来作为额外的监督信号,一个是曼哈顿法向量平面的约束,另一个如果是在平面的话将平面的约束加入到这个自监督网络模型中。
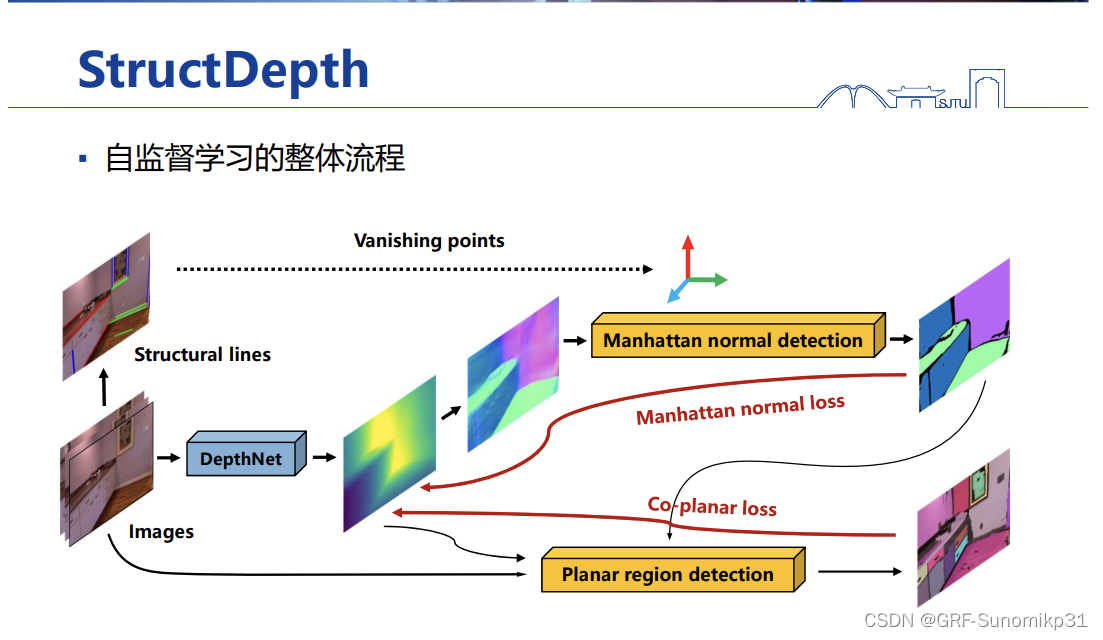
具体做法如上图所示,自监督只能用图像本身的信息。这里先是用传统的方法对图像抽取VP,同时找出这些VP对应的线段;另一边将图像输入到网络模型中,这个网络模型输出深度,这个深度可以去计算出法向量,然后用这些法向量和VP进行比较匹配,曼哈顿平面拉平,转化为一个曼哈顿的loss;第二路会比较复杂,它会检测场景中有没有动态平面。
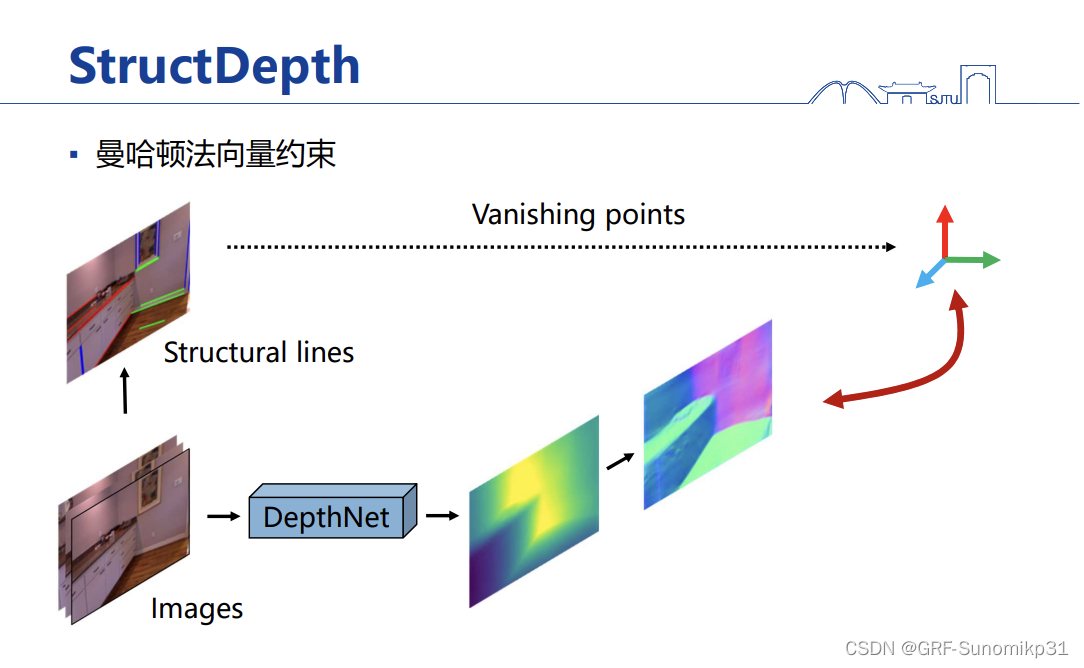
这里是上面说到的法向量的约束,VP转为三个方向去约束normal;
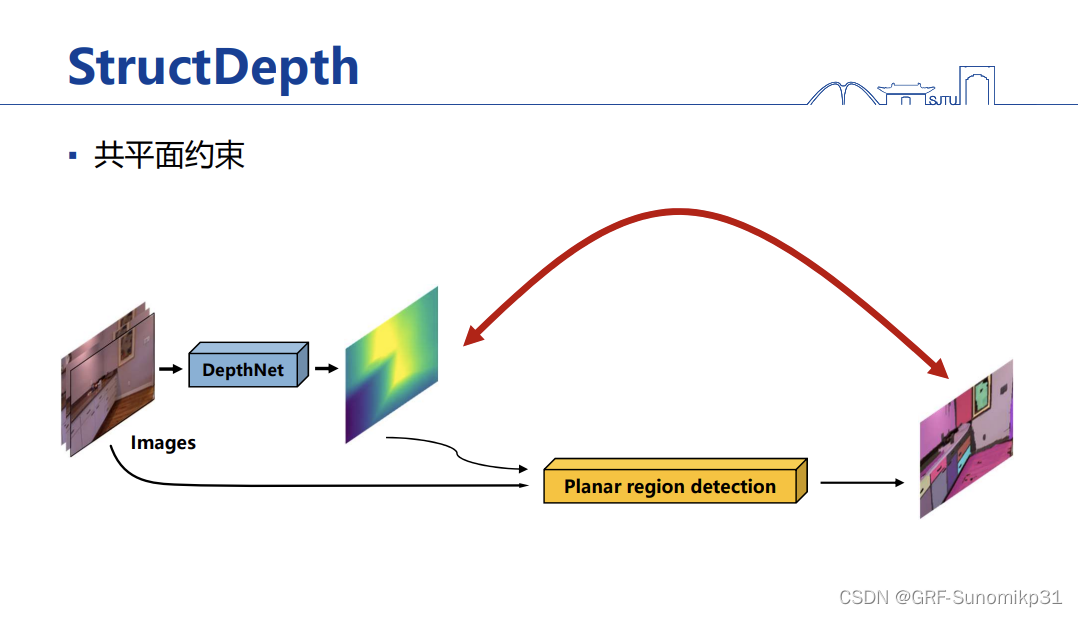
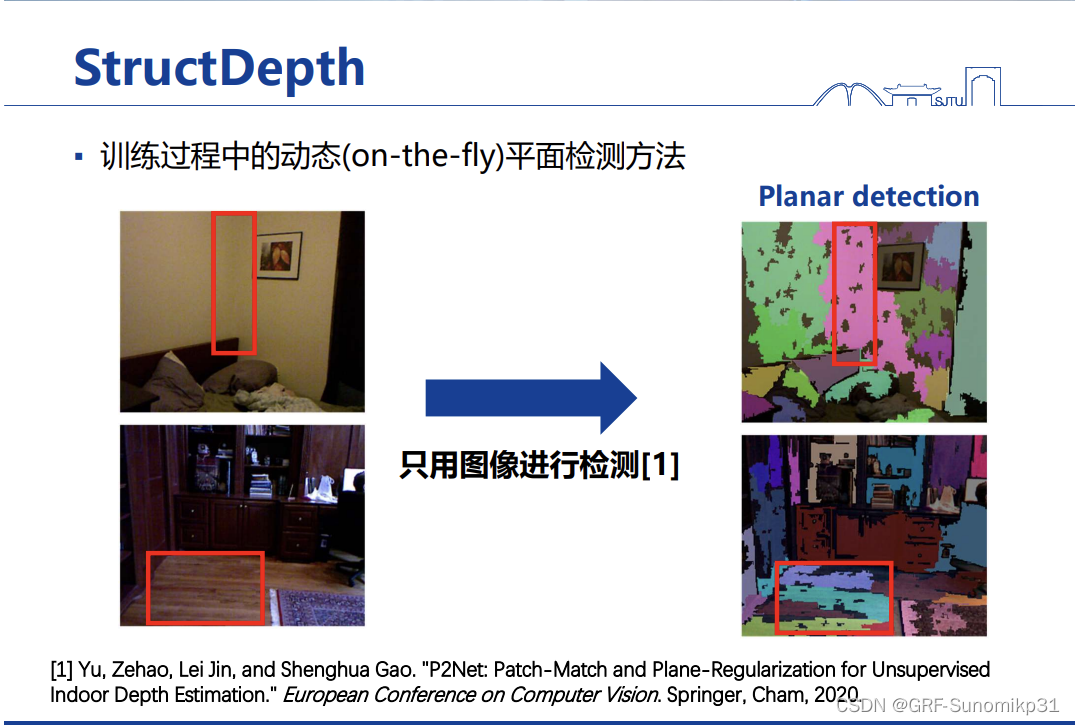
该部分的关键是如何检测平面,这里提出一种动态平面检测方法on-the-fly(很好的训练思想),说的是这个平面会随着训练过程中输出的depth来不断调整检测,使得平面检测越来越好;这里是参考前一篇工作P2Net这个方法,但是它的问题在于只用颜色检测平面会很有问题;
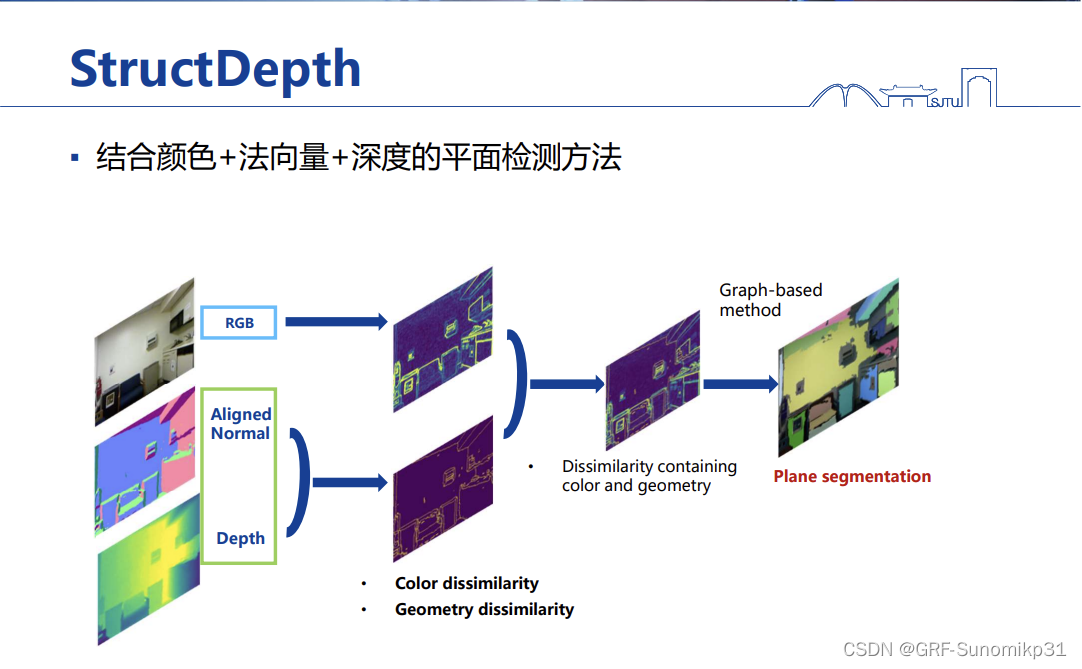
这里提出用网络输出的depth和网络输出的normal作为一个额外的信息叠加到原始的图像上进行图聚类,然后将平面求解出来。
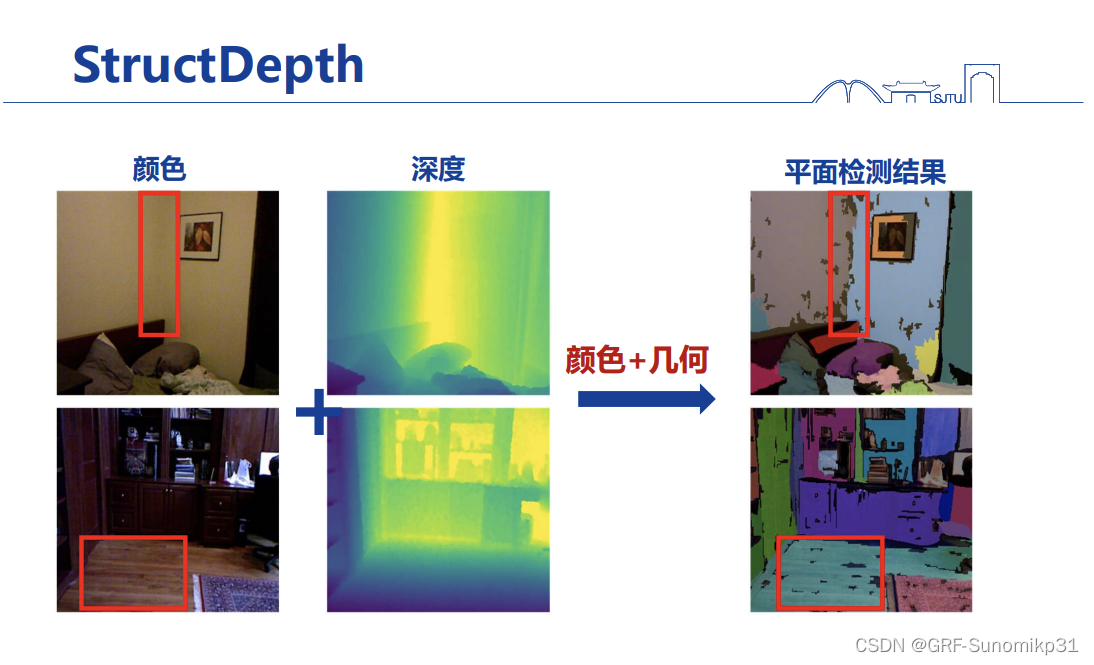
这种动态平面检测的方法会比纯用图像的会好很多。
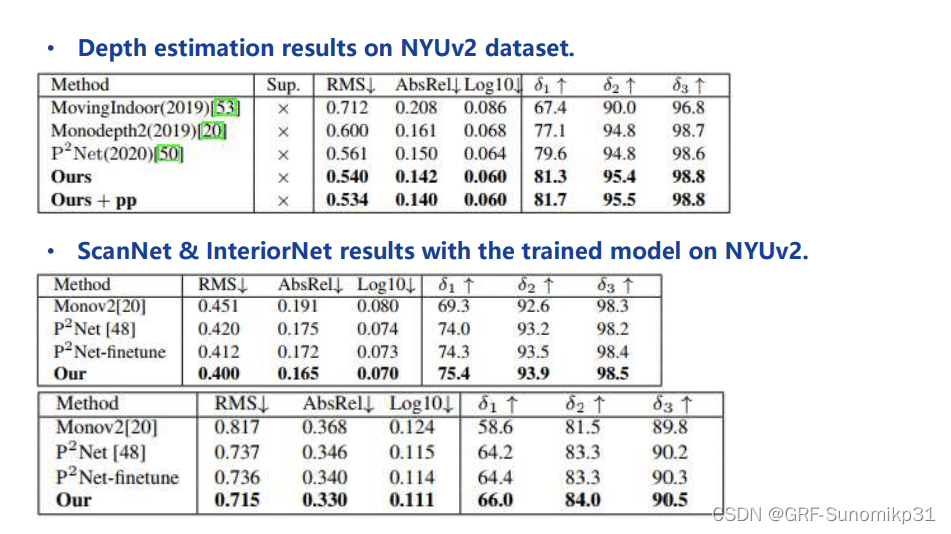
这里是一些指标,跟monodepth2比提升非常多。
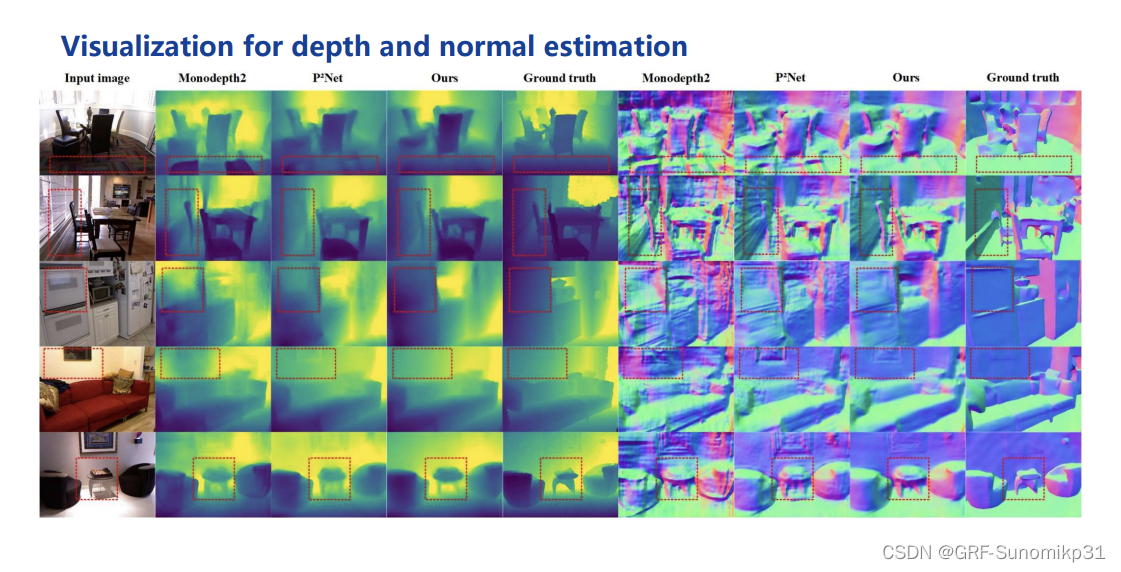
这是可视化的结果,从相关区域可以看到该方法的精度。

这是点云的可视化效果,加上了曼哈顿会比较垂直。
总结

针对实际应用的场景怎么去挖掘结构化信息是一个可以做的方向。
未来在语义这块还值得探索,究竟怎样的语义结合起来才更好更合适,包括算法的提升和后面人机交互实际使用的需求比较合适,邹老师团队探究一种文本的方式,那还有什么其他的方式有利于后面具体的应用?
另一个方面是自监督学习以及包括最近的NeRF也是可以和视觉SLAM结合起来,解决以前视觉SLAM很难解决的问题,比如和前端缺纹理、光照的问题,以及建图这种短板的结合。
提问环节
提问环节主要包括端到端深度学习、TextSLAM、曼哈顿世界约束、单目深度估计、
1、基于模型的SLAM(滤波/优化)和基于深度学习端到端的SLAM有什么结合或者优劣?
邹老师:纯端到端的SLAM,要么像特斯拉一样可以拥有海量的数据,但是大部分研究者或者公司团队是拿不到这些数据的,所以不能直接完全依赖端到端,端到端的问题还是在于泛化性的问题(数据少的情况下会产生过拟合);所以现在比较折中一些的方案是有些部分是端到端的,另外的部分还是传统的;目前可能做的最好的是DROID-SLAM;
Q:DROID-SLAM你能点评一下吗?好像很多人都说很好。
邹老师:传统SLAM有两个短板,一是当纹理光照比较差的时候视觉前端匹配特征效果较差,二是建图比较稀疏;DROID-SLAM是将传统SLAM的整个前端替换掉,其核心是光流,就是说其对整幅图作光流,同时对这个光流做一些约束,让它满足MVS的约束;最后光流作为BA的变量输入一起优化,一起优化的变量是每个关键帧的depth,所以DROID-SLAM算是一个end-to-end的光流模型+传统BA,所以它结合的是非常好的;因为BA在数学上已经解释的很好了。从视频效果上来看,DROID-SLAM的点云比激光雷达的点云还稠密,而且看起来精度还更高,有点要替换激光雷达的效果了。
2、TextSLAM的开源问题
邹老师:TextSLAM准备要开源,因为代码是一个学生写的,之前投了ICRA,现在也在投期刊,如果期刊没问题,后面代码会放出来。
Q:文本形式的进展和目前存在的问题?
邹老师:可能存在的问题有几点,一是当文本不够的情况下就会退化成一个点;二是文本检测存在问题,需要大量的标准,国内汉字环境没有比较丰富的训练数据集能够识别比较丰富的文本标识;TextSLAM的数据集是学生自己做的。
Q:TextSLAM使用特征的问题
邹老师:上面介绍的包括SLAM、VIO都是在点的基础上的加上其他的特征,点不用肯定不行的,因为点是无处不在的,因为文本和线条不是都有的,很多是一个互补的关系。
3、局部曼哈顿世界三个轴的数据关联是怎样进行的?
邹老师:数据关联是靠线条的分类进行的,具体是在上面pipline的第五步;第五步的内容是这样的,将主方向投影到图像上变成一个灭点VP,这些灭点和线段进行连线,再看这些线段和所连直线的吻合度,如果是吻合的话,那么这个线段是属于这个灭点的,那么这样这个灭点就和结构线条关联起来,就可以通过观测方程对滤波器进行更新,就能更新曼哈顿世界的φ参数,同时更新结构线条的参数。
4、单目深度估计是否到了能用的阶段?
邹老师:我觉得单目深度估计现在离能用还有点差别,但是具体看怎么用,比如无人机避障是没问题的,但是这个模型需要自己重新训练,在别人训练好的再到自己场景下采集数据再训练一下;但是如果要构建一个很好的三维地图,单目深度估计是没办法做的或者替换RGBD/双目。
5、后端优化研究点
邹老师:后端优化研究起来比较难,因为后端优化要么是BA,要么是factor-graph因子图,这两块都是传统领域的东西,我们实验室最近也有一份工作,是关于全局BA在效率上的提升;但是我认为这个点很难有很大的突破,整个BA基本上就这样了,可能神经网络解BA比较快?我觉得可能性很小。
Q:继续问了神经网络做BA的问题
邹老师:觉得不是很有必要,有种牛刀杀鸡的感觉。BA-net后端是一个传统BA,是将传统的BA作为一个layer嵌入到整个pipeline中。
6、NeRF和SLAM的关系是不是虚作?
邹老师:我觉都肯定不是,戴森已经做出了一个imap和ilabel,确实是非常管用的,是一个很好的点;但是目前的问题是NeRF的优化比较费时,还有就是精度还是比不上ORB-SLAM,尤其时定位上还是比不上传统方法;但是这个方向我还是比较看好的,尤其是用NeRF做三维重构,比如google的那个视频,他们用NeRF生成了一个室内外的三维地图,效果非常好。NeRF的pose一般是由传统方法计算的,但是也有像imap的pose是用随机梯度优化的;NeRF的方向值得探索,但是其优势在于地图,而不是定位。
6、面向物体的SLAM只是用object不使用特征点怎么样?
邹老师:object slam也有人研究过,比如SLAM++;但是我觉得物体的SLAM是和场景的有关,我能想的场景是机械臂抓取,这时需要自己的pose和物体的pose,这时用object slam可以比较好的解决这个问题;但是在普通场景下,object的CAD不知道或者知道了精度不够高,这时可能会用圆球或者立方体表示,但是这样表示会降低SLAM精度,尤其是pose估计,可想而知,特征点是比整个物体是精准的。所以object slam是要看场景的,在机械臂抓取所有的CAD模型是已知的,所以这时比较精准,但是一般场景下是拖后腿的。

