加载手写数字的数据
组成训练集和测试集,这里已经下载好了,所以download为False
import torchvision
# 是否支持gpu运算
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# print(device)
# print(torch.cuda.is_available())
# 加载训练集的数据 使用torchvision自带的MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data1',
train=True,
transform=torchvision.transforms.ToTensor(),
download=False
)
# 加载测试集的数据 创建测试集
test_dataset = torchvision.datasets.MNIST(root='./data1',
train=False,
transform=torchvision.transforms.ToTensor(),
download=False
)
数据加载器(分批加载)
# 加载数据的批次 一批有多少条数据
batch_size = 100
# 创建数据加载器shuffle为True 加载时打乱
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True
)
# 数据加载器生成的对象转为迭代器
examples = iter(test_loader)
# 使用next方法获取到一批次的数据
example_data, example_targets = examples.next()
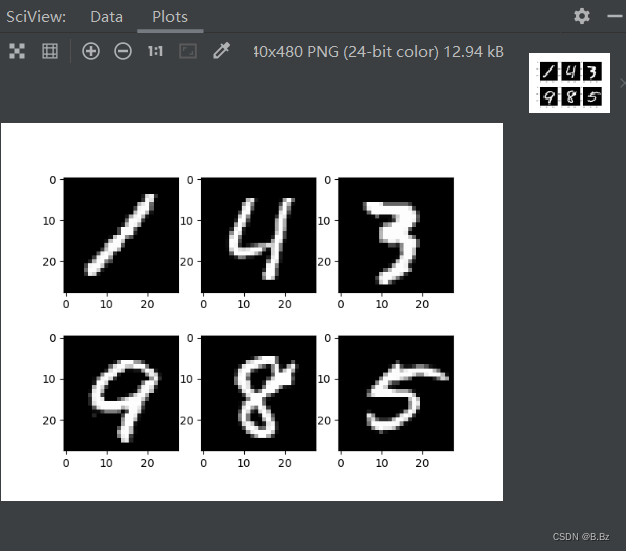
# 遍历获取到6条数据 展示观察一下
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(example_data[i][0], cmap='gray')
# 查看图片的大小 方便建立模型时输入的大小
print(example_data[i][0].shape)
plt.show()
建立模型
- 建立模型之前定义输入大小和分类类别输出大小
通过上边查看图片的大小为28*28*1,所以输入大小为784
数字识别只有0~9所以为10个类别的多分类问题
input_size = 784
num_classes = 10
- 创建模型类
class NeuralNet(torch.nn.Module):
def __init__(self, n_input_size, hidden_size, n_num_classes):
"""
神经网络类初始化
:param n_input_size: 输入
:param hidden_size: 隐藏层
:param n_num_classes: 输出
"""
# 调用父类__init__方法
super(NeuralNet, self).__init__()
self.input_size = input_size
# 第一层线性模型 传入输入层和隐藏层
self.l1 = torch.nn.Linear(n_input_size, hidden_size)
# relu激活函数层
self.relu = torch.nn.ReLU()
# 第二层线性模型 传入隐藏层和输出层
self.l2 = torch.nn.Linear(hidden_size, n_num_classes)
def forward(self, x):
"""
重写正向传播函数 获取到预测值
:param x: 数据
:return: 预测值
"""
# 线性模型
out = self.l1(x)
# 激活函数
out = self.relu(out)
# 线性模型2
out = self.l2(out)
# 返回预测值
return out
# 获取到gpu设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建模型并把模型放到当前支持的gpu设备中
model = NeuralNet(input_size, 500, num_classes).to(device)
print(model)
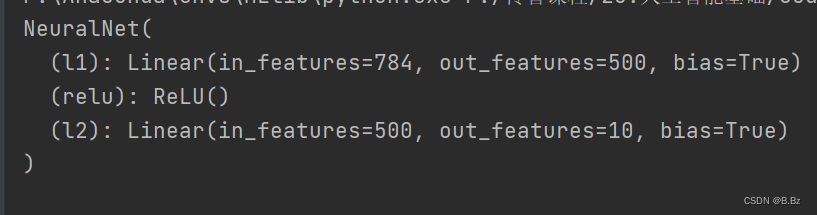
- 可以看出模型一共三层
- 输入层(节点数量和图小大小相同)
- 隐藏层(节点数为500)
- 输出层(输出节点数量为10
0~9)
定义损失函数和优化器
-
因为是多分类问题,所以使用交叉熵函数的多分类损失函数 -
因为传统的梯度下降存在一定缺陷,比如学习速率一直不变,所以使用PyTorch中梯度下降的优化算法Adam算法
# 定义学习率
learning_rate = 0.01
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 定义优化器 参数1为模型的参数 lr为学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
模型训练
训练步骤:
-
通过模型类正向传播获取到预测结果
-
通过损失函数传入预测结果和真实值计算损失
-
通过反向传播获取梯度
-
通过梯度下降更新模型参数的权重
-
梯度清空,防止下次梯度累加
-
循环,降低损失为我们想要的结果(提高模型精度)
# 定义训练的次数
num_epochs = 10
# 训练集数据的总长度
total_steps = len(train_loader)
# 遍历训练次数
for epoch in range(num_epochs):
# 每次从数据加载器中取出一批数据 每批次100条
for i, (images, labels) in enumerate(train_loader):
# 把图片降维到一维数组 加载到gpu
images = images.reshape(-1, 28 * 28).to(device)
# 真实值加载到gpu
labels = labels.to(device)
# 正向传播 获取到预测值
outputs = model(images)
# 通过损失函数获取到损失值
loss_val = criterion(outputs, labels)
# 清空梯度
optimizer.zero_grad()
# 进行反向传播
loss_val.backward()
# 梯度下降更新参数
optimizer.step()
# 打印每次训练的损失值
if i % 100 == 0:
print(f'Loss:{loss_val.item():.4f}')
print('训练完成')
# 训练完之后保存模型
torch.save(model.state_dict(), './last.pt')
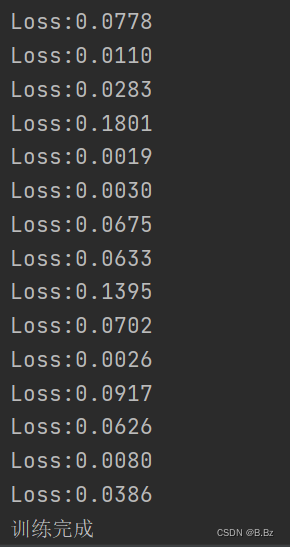
- 损失值很明显的在收敛
- 生成了pt模型文件
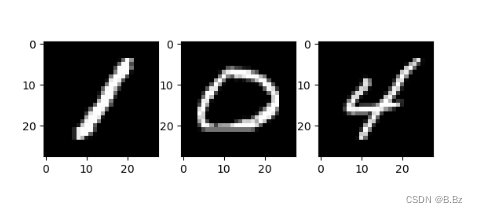
测试集抽取数据,查看预测结果
# 把测试集的数据加载器转为生成器
examples = iter(test_loader)
# next()方法获取一批数据
example_data, example_targets = examples.next()
# 拿出前三条
for i in range(3):
# 画图展示
plt.subplot(1, 3, i + 1)
plt.imshow(example_data[i][0], cmap='gray')
plt.show()
images = example_data
# 图片将为加载到GPU
images = images.reshape(-1, 28 * 28).to(device)
# 正向传播获取预测结果
outputs = model(images)
# 打印结果 detach()方法结果不会计算梯度更新 转为numpy
print(f'真实结果:{example_targets[0:3].detach().numpy()}')
# 预测完的结果为10个数字的概率 使用argmax()根据行归一化并求自变量的概率最大值
print(f'预测结果:{np.argmax(outputs[0:3].cpu().detach().numpy(), axis=1)}')

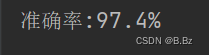
计算模型精度
# 用测试集的数据,校验模型的准确率
with torch.no_grad():
n_correct = 0
n_samples = 0
# 取出测试集数据
for images, labels in test_loader:
# 和训练代码一致
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
outputs = model(images)
# 返1 最大值 返2 索引 0每列最大值 1每行最大值
_, predicted = torch.max(outputs.data, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
# 计算模型精度
acc = 100.0 * n_correct / n_samples
print(f"准确率:{acc}%")
自己手写数字进行预测
import cv2
import numpy as np
import torch
from 手写数字神经网络结构 import NeuralNet
# 获取到gpu设备
device = torch.device('cuda')
# 加载保存好的模型
input_size = 784
num_classes = 10
model = NeuralNet(input_size, 500, num_classes)
# 因为保存模型时在GPU所以要指定map_location='cuda:0'
model.load_state_dict(torch.load('./last.pt', map_location='cuda:0'))
# 加载到gpu上
model.to(device)
# 局域内不计算梯度
with torch.no_grad():
# cv2读取图片 灰度方式
images = cv2.imread('./number_four.png', cv2.IMREAD_GRAYSCALE)
# 使用大津算法进行二值化处理 并反转
ret, thresh_img = cv2.threshold(images, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
# 展示处理过后的图片
cv2.imshow('png1', thresh_img)
cv2.waitKey()
# 图片降维 把拍的图片降维到和训练时的图片大小一样
my_image = cv2.resize(thresh_img, (28, 28))
# 转为numpy
my_image = np.array(my_image, np.float32)
# 转为torch的张量
my_image = torch.from_numpy(my_image)
# 降维
my_image = my_image.reshape(-1, 28 * 28).to(device)
# 正向传播获取预测值
outputs = model(my_image)
# 取出预测结果
pred = np.argmax(outputs.cpu().detach().numpy(), axis=1)
print(f'预测结果为:{pred[0]}')