Ŀ¼
һ�� ���������
1������
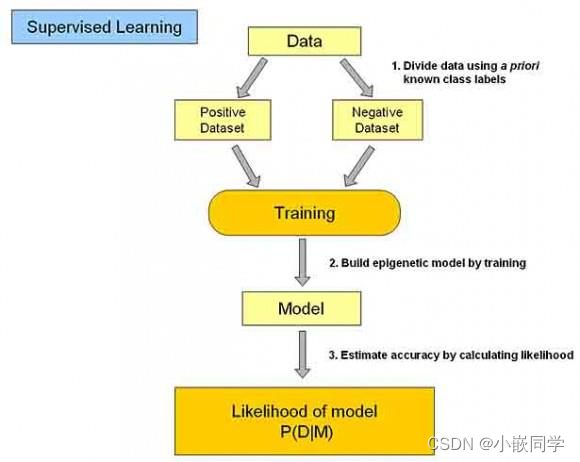
??������ʵ�����ض����������ھ�ģʽ,�����жϵĹ��̡�
??����ѧϰ��Ҫ����:
??(1)ѵ�����ݼ�����һ�����Ǻ�,�ж������������ݼ�(���������,�������ʼ�),���Ǹ������ݼ�(����������,�����ʼ�);
??(2)Ȼ����Ҫ�����ݼ�����ѧϰѵ��,������һ��ѵ����ģ��;
??(3)ͨ����ģ�Ͷ�Ԥ�����ݼ���Ԥ��,���������������ܡ�
2������
??�ӹ�����˵,������������ݼ�����ijЩ�������Ƶ����ݳ�Ա����һ��
??һ���������һЩ����ʵ���ļ���,���д�����ͬ�����е�����Ԫ�ر˴�����,���Ǵ��ڲ�ͬ�����е�Ԫ�ر˴˲�ͬ��
??�����ھ�������Щ��ʾ�������ķ���������Ϣ��û�е�, ����Щ������û�б�ǩ��,��������ͨ������Ϊ�ලѧϰ(Unsupervised Learning),����ʹ�õ����ݴ�������б�ǩ��,��Ϊ�мලѧϰ��
??�����Ŀ��Ҳ�ǰ����ݷ���,���������Dz�֪�����ȥ�ֵ�,��ȫ���㷨�Լ����жϸ�������֮���������,���Ƶľͷ���һ��
??�ھ���Ľ��۳���֮ǰ,��ȫ��֪��ÿһ����ʲô�ص�,һ��Ҫ���ݾ���Ľ��ͨ���˵ľ���������,�����۳ɵ���һ������ʲô�ص㡣
??��֮,������Ҫ��"�������",ͨ������������Ԫ�ؾۼ���һ��,��û�б�ǩ;������ͨ����ǩ��ѵ���õ�һ��ģ��,�������ݼ�����Ԥ��Ĺ���,�����ݴ��ڱ�ǩ��
���������������
- ��������:���ϵ����: 0.1,0.5,0.9
- ��������:�Ա�:��,Ů
����ij����㷨
�����㷨��Ϊ������:
- ԭ�;���:
? K��ֵ�����㷨 - ��ξ���
- �ܶȾ���
����K-Means����
1�����塢�ŵ�
??K-Means��������õľ����㷨,�����Դ���źŴ���,��Ŀ���ǽ����ݵ㻮��ΪK����ء�
??���㷨������ŵ��Ǽ���������,�����ٶȽϿ�,ȱ����Ҫ�ھ���ǰָ���ۼ����������
??k-means�㷨��һ��ԭ�;����㷨��
2��k-means�����㷨�ķ�������:
��һ��,ȷ��Kֵ,�������ݼ��ۼ���K����ػ�С�顣
�ڶ���,�����ݼ������ѡ��K�����ݵ���Ϊ����(Centroid)���������ġ�
������,�ֱ����ÿ���㵽ÿ������֮��ľ���,����ÿ���㻮�ֵ���������ĵ�С�顣
���IJ�,��ÿ�����Ķ��ۼ���һЩ���,���¶����㷨ѡ���µ����ġ�(����ÿ����,��
�����ֵ,���õ��µ�k�����ĵ�)
���岽,����ִ�е����������IJ�,ֱ��������ֹ��������Ϊֹ(���������ٱ仯)
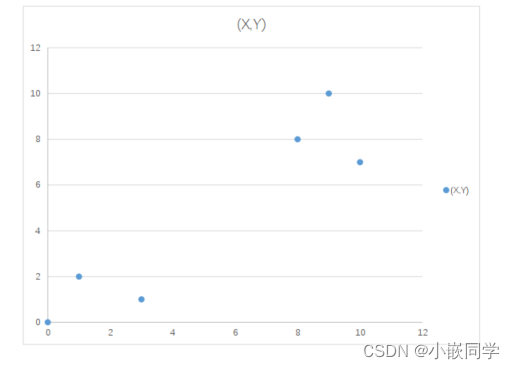
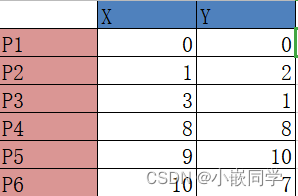
��һ��,ȷ��Kֵ,�������ݼ��ۼ���K����ػ�С�顣
----��������ѡK=2
�ڶ���,�����ݼ������ѡ��K�����ݵ���Ϊ����(Centroid)����
�����ġ�
----��������ѡ��P1��P2��Ϊ��ʼ������
������,�ֱ����ÿ���㵽ÿ������֮��ľ���,����ÿ���㻮��
����������ĵ�С�顣
----����P3��P1�ľ���:��10 = 3.16;
----����P3��P2�ľ���:��((3-1)^2+(1-2)^2 = ��5 = 2.24;
----����P3��P2����,P3�ͼ���P2�Ĵء�ͬ��,P4��P5��P6;
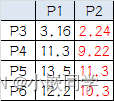
P3��P6����P2����,���Ե�һ�η���Ľ����:
? ��A:P1
? ��B:P2��P3��P4��P5��P6
���IJ�,��ÿ�����Ķ��ۼ���һЩ���,���¶����㷨ѡ���µ����ġ�
(����ÿ����,�������ֵ,���õ��µ�k�����ĵ�)
----��Aûɶ��ѡ��,����P1�Լ�
----��B�������,��Ҫѡ�����ġ� ����Ҫע��ѡ��ķ�����
ÿ����X�����ƽ��ֵ��Y�����ƽ��ֵ��ɵ��µĵ�,Ϊ
������,Ҳ����˵��������ǡ�����ġ���
----���, B��ѡ�������ĵ�����Ϊ: P��((1+3+8+9+10) /5,
(2+1+8+10+7) /5) =(6.2, 5.6)��
----�ۺ�����,������ΪP1(0, 0), P��(6.2, 5.6) ��
----��P2-P6���³�Ϊ��ɢ�㡣
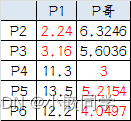
�ٴμ���㵽���ĵľ���:
��ʱ���Կ���P2�� P3��P1����, P4�� P5�� P6��P���
����
�ڶ��η���Ľ����:
? ��A: P1�� P2�� P3
? ��B: P4�� P5�� P6(����������ʱ����ʧ)
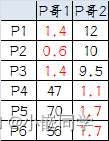
������һ�εķ���ѡ�������µ���������:
---P��1(1.33, 1), P��2(9, 8.33)��
�����μ���㵽���ĵľ���:
--- ��ʱ���Կ���P1�� P2�� P3��P��1����, P4��
P5�� P6��P��2������
--- ���Ե����η���Ľ����:
? ��A: P1�� P2�� P3
? ��B: P4�� P5�� P6
���Ƿ���,��η���Ľ�����ϴ�û���κα仯��,˵
���Ѿ�����,���������
??��ͼ������,ͨ��K-Means�����㷨����ʵ��ͼ��ָͼ����ࡢͼ��ʶ��Ȳ�����
??����ͨ��K-Means���Խ���Щ���ص�����K����,Ȼ��ʹ��ÿ�����ڵ����ĵ����滻�������е����ص�,��������ʵ���ڲ��ı�ֱ��ʵ����������ѹ��ͼ����ɫ,ʵ��ͼ����ɫ�㼶�ָ���
3��K-Means��ȱ��
�ŵ�:
?1.�ǽ�����������һ�־����㷨,������
?2.�Դ��������ݼ�,���㷨���ָ�Ч��
?3.����������ܼ���,����Ч���Ϻ�
ȱ��:
?1.�������ȸ���k(Ҫ���ɵĴص���Ŀ)��
?2.��������������������
4������ʵ��
# coding=utf-8
from sklearn.cluster import KMeans
"""
��һ����:���ݼ�
X��ʾ��ά��������,�����˶�Ա��������
�ܹ�20��,ÿ����������
��һ�б�ʾ��Աÿ����������:assists_per_minute
�ڶ��б�ʾ��Աÿ���ӵ÷���:points_per_minute
"""
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1306, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.1121, 0.5735],
[0.1007, 0.6318],
[0.2567, 0.4326],
[0.1956, 0.4280]
]
#������ݼ�
print (X)
"""
�ڶ�����:KMeans����
clf = KMeans(n_clusters=3) ��ʾ�����Ϊ3,�۳�3������,clf����ֵΪKMeans
y_pred = clf.fit_predict(X) �������ݼ�X,���ҽ�����Ľ����ֵ��y_pred
"""
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
#�������Kmeans����,�����ܶ�ʡ�Բ���
print(clf)
#�������Ԥ����
print("y_pred = ",y_pred)
"""
��������:���ӻ���ͼ
"""
import numpy as np
import matplotlib.pyplot as plt
#��ȡ���ݼ��ĵ�һ�к͵ڶ������� ʹ��forѭ����ȡ n[0]��ʾX��һ��
x = [n[0] for n in X]
print (x)
y = [n[1] for n in X]
print (y)
'''
����ɢ��ͼ
����:x����; y����; c=y_pred����Ԥ����; marker����:o��ʾԲ��,*��ʾ����,x��ʾ��;
'''
plt.scatter(x, y, c=y_pred, marker='x')
#���Ʊ���
plt.title("Kmeans-Basketball Data")
#����x���y������
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
#�������Ͻ�ͼ��
plt.legend(["A","B","C"])
#��ʾͼ��
plt.show()
# coding: utf-8
'''
��OpenCV��,Kmeans()����ԭ��������ʾ:
retval, bestLabels, centers = kmeans(data, K, bestLabels, criteria, attempts, flags[, centers])
data��ʾ��������,�����np.flloat32���͵�Nά�㼯
K��ʾ���������
bestLabels��ʾ�������������,���ڴ洢ÿ�������ľ����ǩ����
criteria��ʾ����ֹͣ��ģʽѡ��,����һ����������Ԫ�ص�Ԫ����������ʽΪ(type, max_iter, epsilon)
����,type������ģʽ:
���Ccv2.TERM_CRITERIA_EPS :��ȷ��(���)����epsilonֹͣ��
��-cv2.TERM_CRITERIA_MAX_ITER:������������max_iterֹͣ��
��-cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER,���ߺ���,����һ�����������
attempts��ʾ�ظ�����kmeans�㷨�Ĵ���,�㷨���ز�������ѽ���ı�ǩ
flags��ʾ��ʼ���ĵ�ѡ��,���ַ�����cv2.KMEANS_PP_CENTERS ;��cv2.KMEANS_RANDOM_CENTERS
centers��ʾ��Ⱥ���ĵ��������,ÿ����Ⱥ����Ϊһ������
'''
import cv2
import numpy as np
import matplotlib.pyplot as plt
#��ȡԭʼͼ��Ҷ���ɫ
img = cv2.imread('lenna.png', 0)
print (img.shape)
#��ȡͼ��߶ȡ�����
rows, cols = img.shape[:]
#ͼ���ά����ת��Ϊһά
data = img.reshape((rows * cols, 1))
data = np.float32(data)
#ֹͣ���� (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#���ñ�ǩ
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means���� �ۼ���4��
compactness, labels, centers = cv2.kmeans(data, 4, None, criteria, 10, flags)
#��������ͼ��
dst = labels.reshape((img.shape[0], img.shape[1]))
#����������ʾ���ı�ǩ
plt.rcParams['font.sans-serif']=['SimHei']
#��ʾͼ��
titles = [u'ԭʼͼ��', u'����ͼ��']
images = [img, dst]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

# coding: utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#��ȡԭʼͼ��
img = cv2.imread('lenna.png')
print (img.shape)
#ͼ���ά����ת��Ϊһά
data = img.reshape((-1,3))
data = np.float32(data)
#ֹͣ���� (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#���ñ�ǩ
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means���� �ۼ���2��
compactness, labels2, centers2 = cv2.kmeans(data, 2, None, criteria, 10, flags)
#K-Means���� �ۼ���4��
compactness, labels4, centers4 = cv2.kmeans(data, 4, None, criteria, 10, flags)
#K-Means���� �ۼ���8��
compactness, labels8, centers8 = cv2.kmeans(data, 8, None, criteria, 10, flags)
#K-Means���� �ۼ���16��
compactness, labels16, centers16 = cv2.kmeans(data, 16, None, criteria, 10, flags)
#K-Means���� �ۼ���64��
compactness, labels64, centers64 = cv2.kmeans(data, 64, None, criteria, 10, flags)
#ͼ��ת����uint8��ά����
centers2 = np.uint8(centers2)
res = centers2[labels2.flatten()]
dst2 = res.reshape((img.shape))
centers4 = np.uint8(centers4)
res = centers4[labels4.flatten()]
dst4 = res.reshape((img.shape))
centers8 = np.uint8(centers8)
res = centers8[labels8.flatten()]
dst8 = res.reshape((img.shape))
centers16 = np.uint8(centers16)
res = centers16[labels16.flatten()]
dst16 = res.reshape((img.shape))
centers64 = np.uint8(centers64)
res = centers64[labels64.flatten()]
dst64 = res.reshape((img.shape))
#ͼ��ת��ΪRGB��ʾ
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dst2 = cv2.cvtColor(dst2, cv2.COLOR_BGR2RGB)
dst4 = cv2.cvtColor(dst4, cv2.COLOR_BGR2RGB)
dst8 = cv2.cvtColor(dst8, cv2.COLOR_BGR2RGB)
dst16 = cv2.cvtColor(dst16, cv2.COLOR_BGR2RGB)
dst64 = cv2.cvtColor(dst64, cv2.COLOR_BGR2RGB)
#����������ʾ���ı�ǩ
plt.rcParams['font.sans-serif']=['SimHei']
#��ʾͼ��
titles = [u'ԭʼͼ��', u'����ͼ�� K=2', u'����ͼ�� K=4',
u'����ͼ�� K=8', u'����ͼ�� K=16', u'����ͼ�� K=64']
images = [img, dst2, dst4, dst8, dst16, dst64]
for i in range(6):
plt.subplot(2,3,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

���� ����
1������
??��ξ�����һ�ֺ�ֱ�۵��㷨������˼�����Ҫһ��һ��ؽ��о��ࡣ
??��η�(Hierarchical methods) �ȼ�������֮��ľ��롣ÿ�ν���������ĵ�ϲ���ͬһ���ࡣȻ��,�ټ���������֮��ľ���,�������������ϲ�Ϊһ�����ࡣ��ͣ�ĺϲ�,ֱ���ϳ���һ���ࡣ����������ľ���ļ��㷽����:��̾��뷨,����뷨,�м���뷨,��ƽ�����ȡ�������̾��뷨,��������ľ��붨��Ϊ������֮����������̾��롣
??��ξ����㷨���ݲ�ηֽ��˳���Ϊ:���µ����Ϻ���������,�����۵IJ�ξ����㷨�ͷ��ѵIJ�ξ����㷨(agglomerative��divisive) ,Ҳ��������Ϊ���¶��Ϸ�(bottom-up)�����϶��·�(topdown)��
2�����۲�ξ��������
??�����Ͳ�ξ���IJ������Ƚ�ÿ��������Ϊһ����,Ȼ��ϲ���Щԭ�Ӵ�ΪԽ��Խ��Ĵ�,ֱ�����ж�����һ������,����ij���ս����������������������ξ������������Ͳ�ξ���,����ֻ���ڴؼ����ƶȵĶ�����������ͬ�� �������������С���������۲�ξ����㷨����:
(1) ��ÿ��������һ��,��������֮�����С����;
(2) ��������С��������ϲ���һ������;
(3) ���¼���������������֮��ľ���;
(4) �ظ�(2)�� (3),ֱ�����������ϲ���һ�ࡣ
�ص�:
? ���۵IJ�ξ��ಢû������K��ֵ��ȫ��Ŀ�꺯��,û�оֲ���С������Ǻ���ѡ���ʼ������⡣
? �ϲ��IJ������������յ�,һ���ϲ�������֮��Ͳ��᳷����
? ��Ȼ�����洢�Ĵ����ǰ���ġ�
3����ξ������ȱ��
�ŵ�:
1,�����������ƶ�������,������;
2,����ҪԤ���ƶ�������;
3,���Է�����IJ�ι�ϵ;
4,���Ծ����������״
ȱ��:
1,���㸴�Ӷ�̫��;
2,����ֵҲ�ܲ����ܴ�Ӱ��;
3,�㷨�ܿ��ܾ������״
4��ʾ��
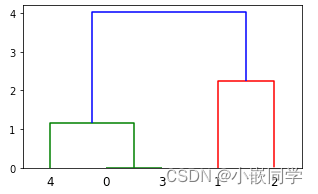
??����ͼ��ʾ����5����,�������ϵ��������ִ�����Ų�������ֵ����ͼ�����5������в�ξ���Ĺ��̡�

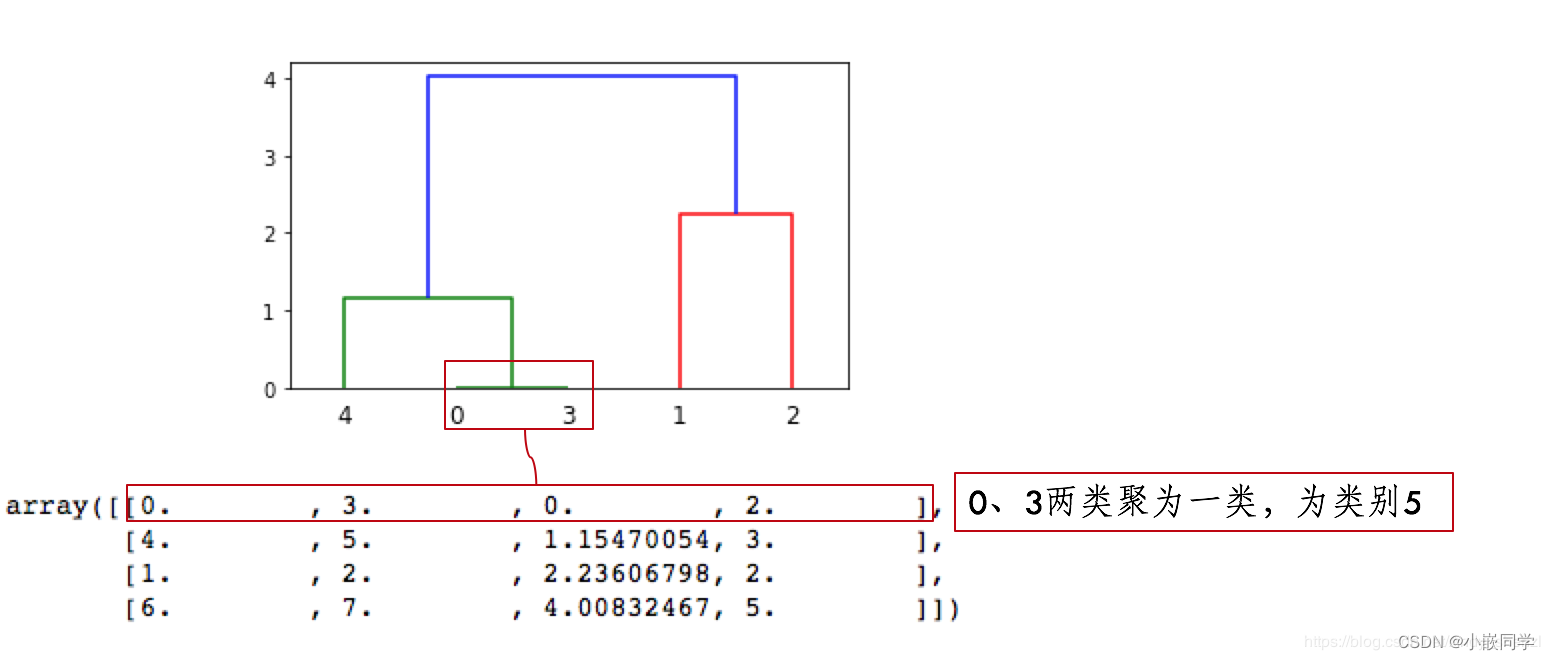
??Z�ĵ�һ��: [0, 3]��˼�����0�����3�������,���Ⱦ۳�һ��,���Զ��������Ϊ5(=len(X)-1+1),����������0����0��3������ľ���,��Ϊ�������ص���,ͬһ������,�ʶ�����Ϊ0,������Ϊ������Ԫ����,������0��3,����2��
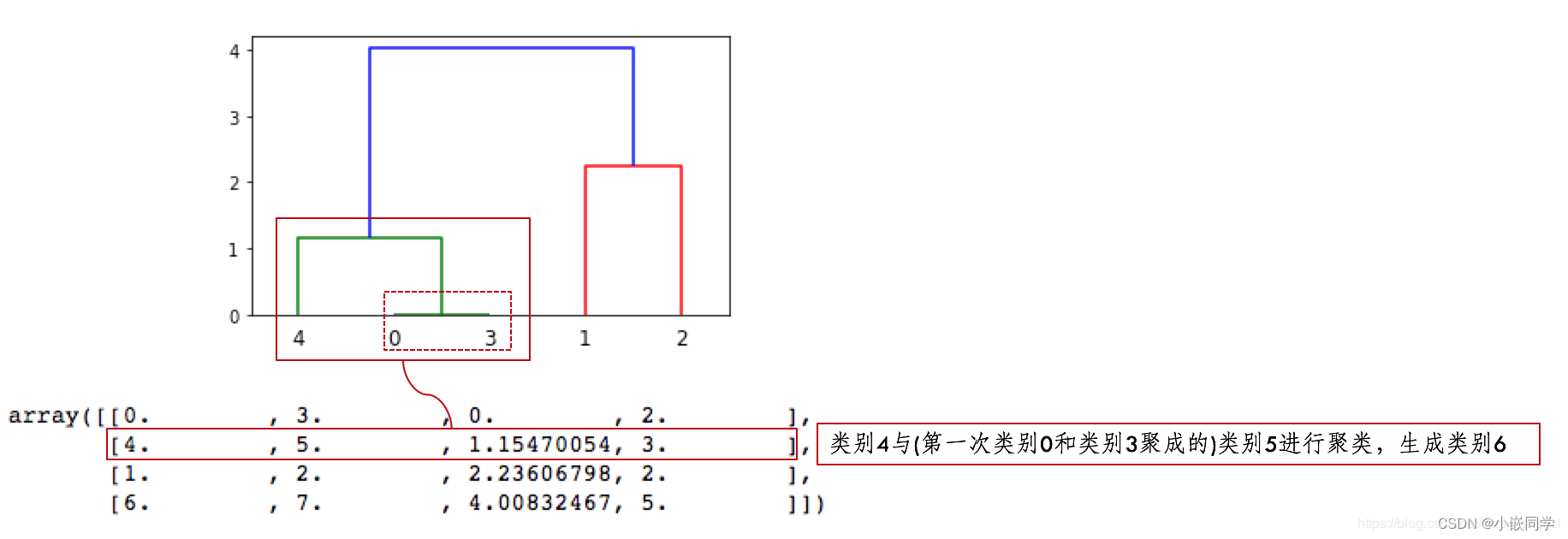
??Z�ĵڶ���: [4, 5]��˼�����4���������������5����Ϊ�ڶ���, 4�� 5�۳�һ��,���Ϊ6(=len(X)-1+2)
�����С��������Դ�����,
�����5����������,�������4����6,��3������;
���7�����1�� 2�����γ�,����������;
���6�� 7�۳�һ���,���8��5������,����Xȫ�������������,������ɡ�
Z���������������ĸ���,��������һ���е��������ﵽ��������ʱ,���������ˡ�
5����״ͼ�����ж�
??�������ʱ,�ʹ�������������������ʱ�����и�,��ô����Ӧ���������������ӵ�Ϊһ��
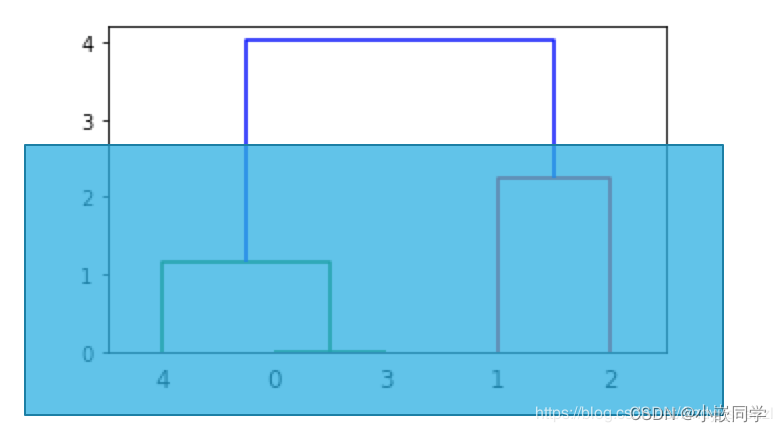
??�������ʱ,�ʹ�������������������ʱ�����и�,��ô����Ӧ���������������ӵ�Ϊһ��
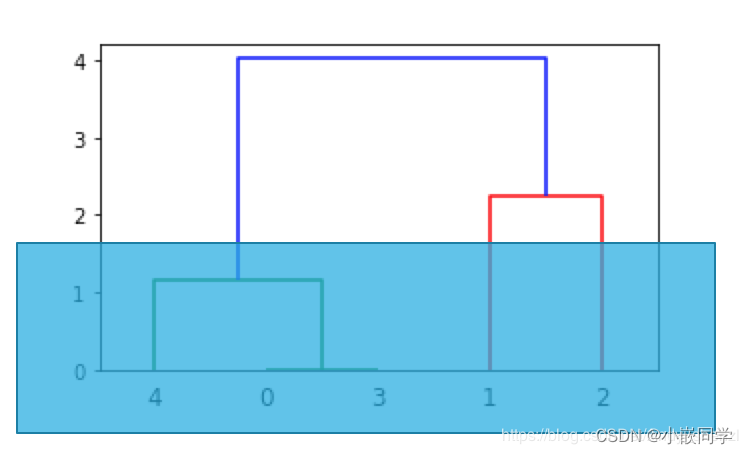
??ÿһ�־�����������ض������ݽṹ,���ڷ��Ӹ�˹�ֲ���������K-Means�����о���Ч����ȽϺá����������֮����ڲ�ṹ������,�ò�ξ����ȽϺá�
6��ʾ������
###cluster.py
#������Ӧ�İ�
from scipy.cluster.hierarchy import dendrogram, linkage,fcluster
from matplotlib import pyplot as plt
'''
linkage(y, method=��single��, metric=��euclidean��) ������3������:
1. y�Ǿ������,������1άѹ������(��������),Ҳ������2ά�۲�����(�������)��
��y��1άѹ������,��y������n����ʼ�۲�ֵ�����,n����������гɶԵĹ۲�ֵ��
2. method��ָ����������ķ�����
'''
'''
fcluster(Z, t, criterion=��inconsistent��, depth=2, R=None, monocrit=None)
1.��һ������Z��linkage�õ��ľ���,��¼�˲�ξ���IJ����Ϣ;
2.t��һ���������ֵ-��The threshold to apply when forming flat clusters����
'''
X = [[1,2],[3,2],[4,4],[1,2],[1,3]]
Z = linkage(X, 'ward')
f = fcluster(Z,4,'distance')
fig = plt.figure(figsize=(5, 3))
dn = dendrogram(Z)
print(Z)
plt.show()
�ġ��ܶȾ���
1���㷨
��Ҫ��������:�� (eps) ���γɸ��ܶ���������Ҫ�����ٵ��� (minPts)
? ����һ������δ�����ʵĵ㿪ʼ,Ȼ��̽�������� ��-����,��� ��-���������㹻�ĵ�(�������Ҫȷ����ָ�����������Dz�����),����һ���µľ���,��������㱻��ǩΪ������
? ע��,���������֮����ܱ�������������� ��-������,���� ��-����������㹻�ĵ�,��ʱ�����ᱻ����þ����С�
? ��ij������ܼȳ�����ij����������ֳ�������һ���������,�����õ㵽����Ŀ���ľ���ȷ�����ʺ��Ǹ���
2����ȱ��
�ŵ�:
- ������������;
- �ܷ���������״�ľ��ࡣ
ȱ��:
- ���Ǿ���Ľ��������кܴ�Ĺ�ϵ;
- �ù̶�����ʶ�����,���������ϡ��̶Ȳ�ͬʱ,��ͬ���ж������ܻ��ƻ��������Ȼ�ṹ,����ϡ�ľ���ᱻ����Ϊ�������ܶȽϴ�����ýϽ�����ᱻ�ϲ���һ�����ࡣ
3��ʾ������
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.cluster import DBSCAN
iris = datasets.load_iris()
X = iris.data[:, :4] # #��ʾ����ֻȡ�����ռ��е�4��ά��
print(X.shape)
# �������ݷֲ�ͼ
'''
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
'''
dbscan = DBSCAN(eps=0.4, min_samples=9)
dbscan.fit(X)
label_pred = dbscan.labels_
# ���ƽ��
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
�塢��չ�C����
1���㷨����
1.�������ݹ���һ�� ͼ�ṹ(Graph) ,Graph ��ÿһ���ڵ��Ӧһ�����ݵ�,����
�Ƶĵ���������,���ұߵ�Ȩ�����ڱ�ʾ����֮������ƶȡ������ Graph ���ڽӾ�
�����ʽ��ʾ����,��Ϊ W ��
2. �� W ��ÿһ��Ԫ�ؼ������õ� N ����,�����Ƿ��ڶԽ�����(�����ط�������),
���һ�� N * N�ľ���,��Ϊ D ������ L = D-W ��
3.��� L ��ǰ k ������ֵ,�Լ���Ӧ������������
4.���� k ������(��)����������һ�����һ�� N * k �ľ���,������ÿһ�п��� k
ά�ռ��е�һ������,��ʹ�� K-means �㷨���о��ࡣ����Ľ����ÿһ����������
�����ԭ�� Graph �еĽڵ��༴�����N �����ݵ�ֱ����������
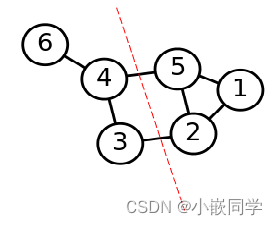
�ڽӾ���:
���ṹ��Ϊ������:V��E����,����,V�Ƕ���,E�DZߡ����,��һ��һά������ͼ��
���ж�������;��һ����ά�����Ŷ�����ϵ(��)������,�����ά�����Ϊ�ڽ�
�����ڽӾ����ַ�Ϊ����ͼ�ڽӾ��������ͼ�ڽӾ���
�����������,��Ҫ������:
- ��ͼ,�����������ݹ����һ����ͼ��
- ��ͼ,������һ����������İ���һ�����б���,�зֳɲ�ͬ��ͼ,����ͬ����ͼ,�����Ƕ�Ӧ�ľ�������
ע:�����²ο��˰ٶȰٿơ����˼������͡��˶�ѧԺ�μ����ϡ�������Ӿ���ģʽʶ���鼮���ۺ���������,������Ȩ,��ϵɾ��!ˮƽ����,��ӭ��λָ������!

