���Ż������������ı�����Խ��Խ��,�ı���Ϣ����������������,�Ը����ı�����һ������ά�������Ե÷dz���Ҫ,���ı�ժҪ��������һ����Ҫ���ֶΡ�
�������Ƚ����˾�����ı�ժҪ����,�������˶Ի�ժҪ��ģ��,����������������ʵ�Ի�ժҪ���������ٵ���ս��ͬʱ����ʵ�ʵij���,����������Ķ�����ľ���ලSpan-Level�Ի�ժҪ����(�ѷ�����SIGIR 2021),�÷�����ǿ��������ROUGE-Lָ���BLEUָ����������3%���ҡ�
1. �Ի�ժҪ��������
�ı�ժҪ[65-74]ּ�ڽ��ı����ı�����ת��Ϊ�����ؼ���Ϣ�ļ��ժҪ,�ǻ����ı���Ϣ���ص�һ����Ҫ�ֶΡ��ı�ժҪ������������,�ɷ�Ϊ���ĵ�ժҪ�Ͷ��ĵ�ժҪ�����ĵ�ժҪ�Ӹ�����һ���ĵ�������ժҪ,���ĵ�ժҪ�Ӹ�����һ��������ص��ĵ�������ժҪ������������Ϳɷ�Ϊ��ȡʽժҪ������ʽժҪ����ȡʽժҪ��Դ�ĵ��г�ȡ�ؼ���ؼ������ժҪ,ժҪ��Ϣȫ����Դ��ԭ�ġ�����ʽժҪ����ԭ��,���������µĴ�����������ժҪ������,�������ල����,�ı�ժҪ���Է�Ϊ�мලժҪ���ලժҪ������������������,�ı�ժҪ�ֿ��Է�Ϊ����ժҪ��ר��ժҪ������ժҪ���Ի�ժҪ�ȵȡ�
�Զ��ı�ժҪ���Կ�����һ����Ϣѹ���Ĺ���,���ǽ������һƪ���ƪ�ĵ��Զ�ѹ��Ϊһƪ��̵�ժҪ,�ù��̲��ɱ���ش�����Ϣ��ʧ,��Ҫ���������ܶ����Ҫ��Ϣ���Զ���ժϵͳͨ���漰�������ĵ������⡢Ҫ���ɸѡ�Լ���ժ�ϳ���������Ҫ���衣����,�ĵ������dz����,������Զ���ժϵͳֻ��Ҫ���бȽ�dz����ĵ�����,������仮�֡������з֡��ʷ�������,Ҳ����ժϵͳ��Ҫ�����䷨�����������ɫ��ע��ָ������,���������������ȼ�����
�Ի�ժҪ���ı�ժҪ��һ������,�����������ǶԻ������ݡ��Ի����������Ų�ͬ����ʽ,����:���顢���ġ��ʼ������ۡ��ͷ��ȵȡ���ͬ��ʽ�ĶԻ�ժҪ���Լ����ض��������Ų�ͬ��Ӧ�ó���,�������ǵĺ�����ժҪ����ĺ�����һ�µ�,����Ϊ�˲��Ի��еĹؼ���Ϣ,������������Ի��ĺ������ݡ����ı�ժҪ��ͬ����,�Ի�ժҪ�Ĺؼ���Ϣ����ɢ���ڲ�֮ͬ��,�Ի��е�˵���ߡ����ⲻͣ��ת��������,��ǰҲȱ�ٶԻ�ժҪ�����ݼ�,��Щ�������˶Ի�ժҪ���Ѷ�[64]��
����ʵ�ʵij���,����������Ķ�����ľ���ලSpan-Level�Ի�ժҪ������Distant Supervision based Machine Reading Comprehension for Extractive Summarization in Customer Service��(�ѷ�����SIGIR 2021),�÷�����ǿ��������ROUGE-Lָ���BLEUָ����������3%���ҡ�
2. �ı�ժҪ��Ի�ժҪ����ģ�ͽ���
�ı�ժҪ�����ɷ�ʽ�Ͽɷ�Ϊ��ȡʽժҪ������ʽժҪ����ģʽ����ȡʽժҪͨ��ʹ���㷨��Դ�ĵ�����ȡ�ֳɵĹؼ��ʡ�������ΪժҪ�䡣��ͨ˳����,һ����������ʽժҪ������,��ȡʽժҪ����������������Ϣ,������ժҪ�������ص㡣����ʽժҪ���ǻ���NLG(Natural Language Generation)����,����Դ�ĵ�����,���㷨ģ��������Ȼ��������,����ֱ����ȡԭ�ĵľ��ӡ�
Ŀǰ,����ʽժҪ�ܶ�����ǻ������ѧϰ�е�Seq2Seqģ��[44]���������BERT[34]Ϊ�����Ĵ���Ԥѵ��ģ�ͳ�����,Ҳ�кܶ���������������Ԥѵ��ģ������NLG��������ֱ������������ģʽ�µľ���ģ�͡�
2.1 ��ȡʽժҪģ��
��ȡʽժҪ��ԭ����ѡȡ�ؼ��ʡ��ؼ������ժҪ�����ַ�����Ȼ������䷨�ϴ����ʵ�,��֤��һ����Ч������ͳ�ij�ȡʽժҪ����ʹ��ͼ����������ȷ�ʽ����ලժҪ��Ŀǰ���еĻ���������ij�ȡʽժҪ,���������⽨ģΪ���б�ע�;����������������������Ƚ��ܴ�ͳ�ij�ȡʽժҪ����,���ż�������������ij�ȡʽժҪ������
��ͳ��ȡʽժҪ����
Lead-3
һ����˵,�ĵ��������ڱ�����ĵ���ʼ�ͱ�������,�����ķ������dz�ȡ�ĵ��е�ǰ������ΪժҪ�����õķ���ΪLead-3[63],����ȡ�ĵ���ǰ������Ϊ�ĵ���ժҪ��Lead-3������Ȼ��ֱ��,��ȴ�Ƿdz���Ч�ķ�����
TextRank
TextRank[58] �㷨����PageRank,��������Ϊ�ڵ�,ʹ�þ��Ӽ����ƶ�,����������Ȩ�ߡ�ʹ�ñ��ϵ�Ȩֵ�������½ڵ�ֵ,���ѡȡN���÷���ߵĽڵ�,��ΪժҪ��
����
���ھ���ķ���,���ĵ��еľ�����Ϊһ����,���վ���ķ�ʽ���ժҪ������Padmakumar��Saran [11]���ĵ��еľ���ʹ��Skip Thought Vectors��Paragram Embeddings���ַ�ʽ���б���,�õ����Ӽ����������ʾ��Ȼ����ʹ��K��ֵ����[59]��Mean-Shift����[60]���о��Ӿ���,�õ�N���������ÿ�������,ѡ�������������ľ���,�õ�N������,��Ϊ���յ�ժҪ��
����������ij�ȡʽժҪ����
���������������֮��,����������ij�ȡʽժҪ�����ȴ�ͳ�ij�ȡʽժҪ�����������Ը��ߡ�����������ij�ȡʽժҪ������Ҫ��Ϊ���б�ע��ʽ�;�������ʽ,���������ھ�������ʽʹ�þ���������Ϊ��ַ�ʽ,���Ǿ���֮������ϵ��
���б�ע��ʽ
���ַ������Խ�ģΪ���б�ע������д���,������뷨��:Ϊԭ���е�ÿһ�����Ӵ�һ���������ǩ(0��1),0�����þ䲻����ժҪ,1�����þ�����ժҪ������ժҪ�����б�ǩΪ1�ľ��ӹ��ɡ�
���ַ����Ĺؼ����ڻ�þ��ӵı�ʾ,�������ӱ���Ϊһ������,���ݸ��������ж���������,����SummaRuNNerģ��[48],ʹ��˫��GRU�ֱ�ģ���V��;��Ӽ���ı�ʾ(ģ������ͼ1��ʾ)����ɫ����Ϊ���V���ʾ,��ɫ����Ϊ���Ӽ����ʾ,����ÿһ�����ӱ�ʾ,��һ��0��1��ǩ���,ָʾ���Ƿ���ժҪ��
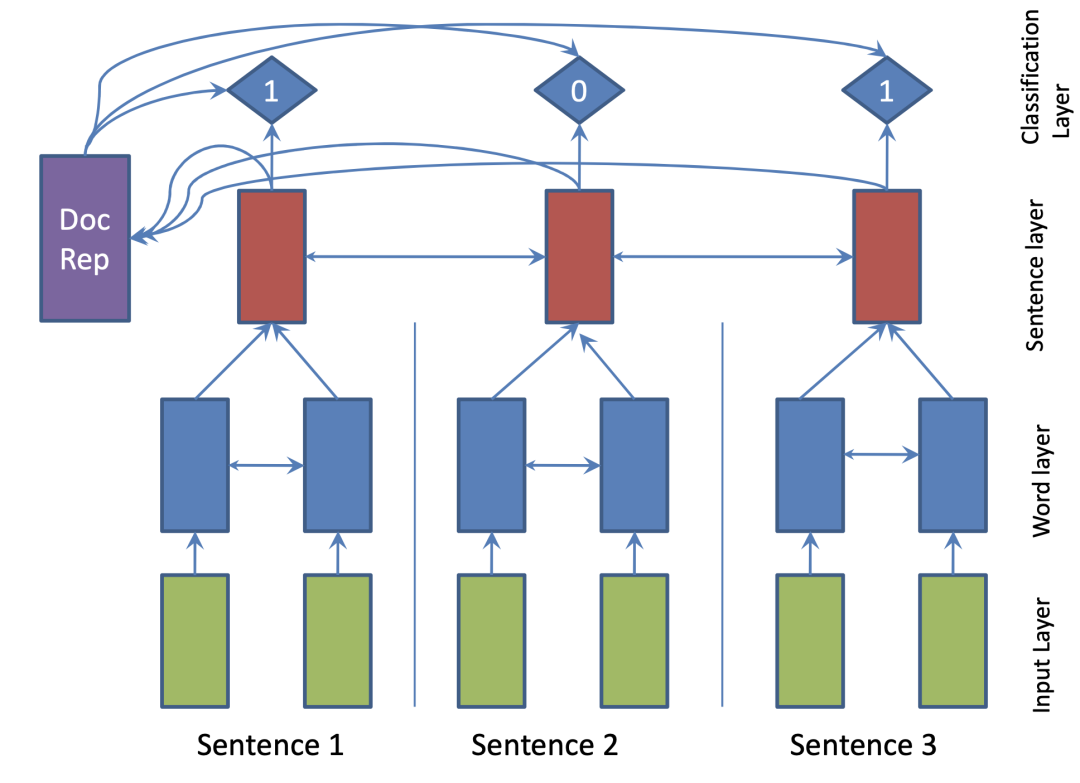
��ģ�͵�ѵ����Ҫ�ල����,�������ݼ�����û�ж�Ӧ�ľ��Ӽ���ı�ǩ,����ͨ������ʽ������л�ȡ�����巽��Ϊ:����ѡȡԭ�������ժҪ����ROUGE�÷���ߵ�һ�仰�����ѡ����,���ż�����ԭ���н���ѡ��,��֤ѡ����ժҪ����ROUGE�÷�����,ֱ����������������õ��ĺ�ѡժҪ���϶�Ӧ�ľ�����Ϊ1��ǩ,����Ϊ0��ǩ��
��������ʽ
��ȡʽժҪ�����Խ�ģΪ������������,�����б�ע����IJ�ͬ������,���б�ע����ÿһ�����ӱ�ʾ��һ��0��1��ǩ,���������������������ÿ������������Ƿ���ժҪ��ĸ���,�������ݸ���,ѡȡTop K��������Ϊ����ժҪ����Ȼ����ģ��ʽ(����ѡȡժҪ��ʽ)��ͬ,��������Ĺ�ע�㶼�Ƕ��ھ��ӱ�ʾ�Ľ�ģ��
���б�ע��ʽ��ģ���ڵõ����ӵı�ʾ�Ժ���ھ��ӽ��д��,�������˴����ѡ���Ƿ����,�ȴ��,����ݵ÷ֽ���ѡ��,û�����õ�����֮��Ĺ�ϵ��NeuSUM[49]�����һ���µĴ�ַ�ʽ,ʹ�þ���������Ϊ��ַ�ʽ,���ǵ��˾���֮������ϵ����ģ��NeuSUM����ͼ2��ʾ:
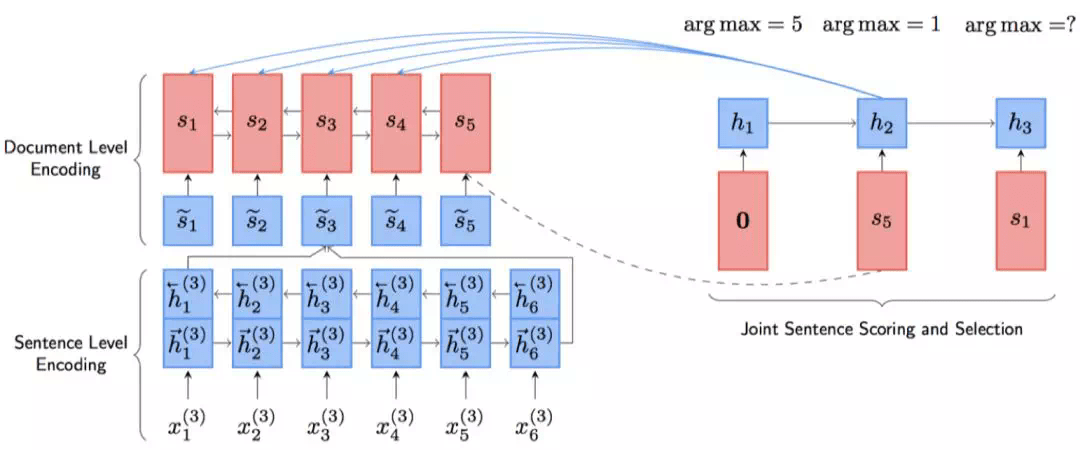
���ӱ��벿����֮ǰ������ͬ����ֺͳ�ȡ����ʹ�õ���GRU��˫��MLP��ɡ�����GRU���ڼ�¼��ȥ��ȡ���ӵ����,˫��MLP���ڴ��,���¹�ʽ��ʾ:
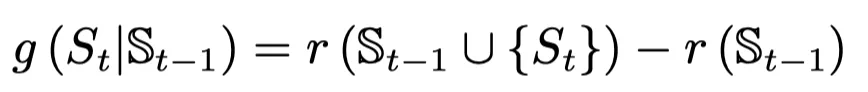
2.2 ����ʽժҪģ��
��ȡʽժҪ������䷨����һ���ı�֤,����Ҳ������һ��������,����:����ѡ����������Բ����Բ�����⡣����ʽժҪ����ժҪ�а����µĴ�������,����Խϸߡ����Ž�����������ģ�͵ķ�չ,���е�����(Seq2Seq)ģ�ͱ��㷺����������ʽժҪ����,��ȡ��һ���ijɹ��������������ʽժҪģ���о����Pointer-Generator[50]ģ�ͺͻ���Ҫ�������ʽժҪģ��Leader+Writer[4]��
Pointer-Generatorģ��
��ʹ��Seq2Seq���������ʽժҪ������������:��δ��¼������(OOV);���ظ��������⡣Pointer-Generator[50]�ڻ���ע�������Ƶ�Seq2Seq������������Copy��Coverage����,��Ч�ػ������������⡣��ģ�ͽṹ����ͼ3��ʾ:
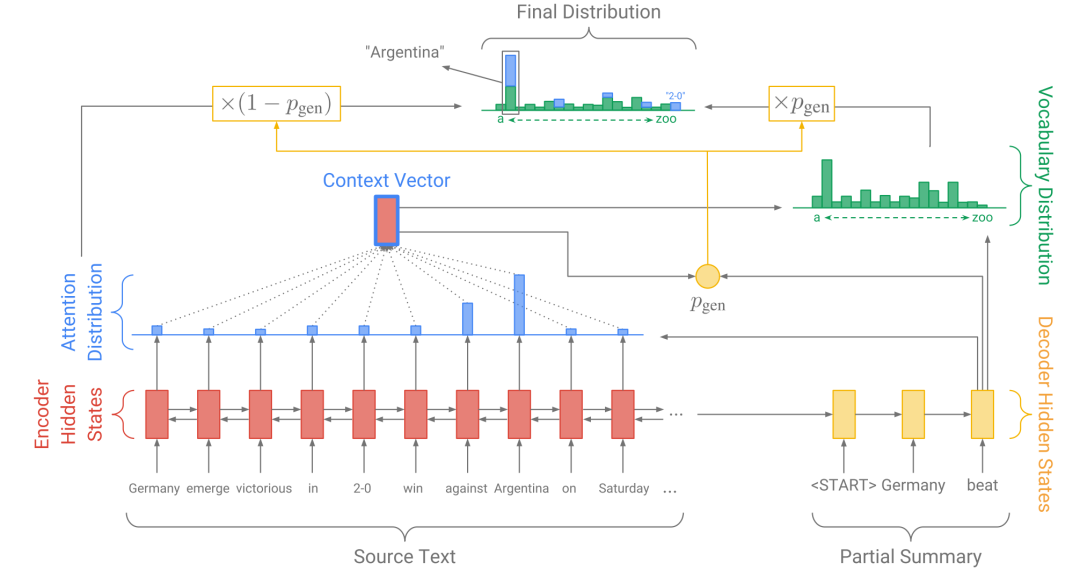
��ģ�ͻ���ע�������Ƶ�Seq2Seqģ��,ʹ��ÿһ�����������״̬�������������״̬����Ȩ��,���յõ�Context����,����Context�����ͽ���������״̬����������ʡ�
��������
-
Copy����:�ڽ����ÿһ�����㿽�������ɵĸ���,��Ϊ�ʱ��ǹ̶���,�û��ƿ���ѡ���ԭ���п������ﵽժҪ��,��Ч�ػ�����δ��¼��(OOV)�����⡣
-
Coverage����:�ڽ����ÿһ������֮ǰ����ע����Ȩ��,���Coverage��ʧ, ������������Ѿ���ø�Ȩ�صIJ��֡��û��ƿ�����Ч���������ظ������⡣
Leader-Writerģ��
Leader-Writerģ����Ҫͨ���ھ�Ի��д��ڵ�Ҫ�� (���米�������۵�) ������ժҪ�������ܽ�������ʽժҪ�ִ�ļ�������:������,�����ڿͷ��Ի���,����Ӧ���ڽ���֮ǰ;��������,���Ի��д��ڵĸ���Ҫ�㶼Ӧ����ժҪ�д���;�۹ؼ���Ϣ��ȷ,���硰�û�ͬ�⡱�͡��û���ͬ�⡱��Ȼֻ��һ��֮��,��������ȫ�෴;��ժҪ�������⡣Ϊ�˽����Щ����,������������½������:
-
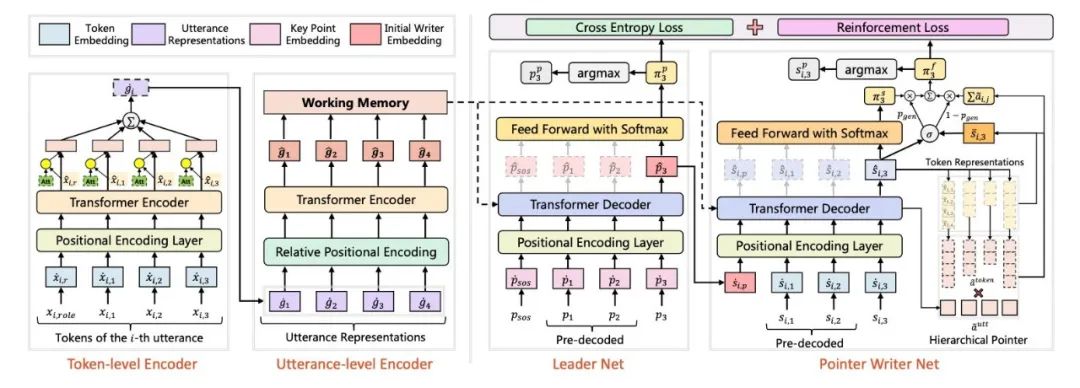
����Ҫ������Ԥ�⸨������,�����öԻ���Ҫ��������Ϣ����ģ�����ɾ������ԡ������ԡ��ؼ���Ϣ��ȷ��ժҪ������ͼ4��ʾ,Leader-Writerģ����һ����ε�Transformer ����������ÿ������,��Leader��������ÿ�������Ҫ����з���,��ʹ��Writer����������ժҪ���ɡ�Leader����������������ΪWriter��������ʼ״̬������,�����ò�ͬ�Ի�Ƭ�ε�Ҫ����Ϣ��
-
����Pointer-Generatorģ��,�����ɸ�������Ϣ���ḻ��ժҪ��
2.3 �Ի�ժҪģ��
�Ի����йؼ���Ϣɢ�䡢����Ϣ�ܶȡ���������ת����˵���߽�ɫ����ת�����ص�,��˿���ֱ�ӽ��ı�ժҪӦ���ڶԻ�ժҪ,һЩ�о�����Ҳ�����ڽ����Щ���⡣�������2���д����ԵĶԻ�ժҪģ��:SPNet[53]��TDS-SATM[54]��
Scaffold Pointer Network (SPNet)
��ԶԻ�ժҪ���ٵ�3������:��˵�����ڶ�;��������ȷ�ܽ�ؼ�ʵ����Ϣ;�۶Ի������ڶࡢ�������Դ�Ϊ��,���������3���������:
-
ʹ��Ponter-generator��������ʽ��ժҪ��ȡ,ͬʱ���벻ͬ���������벻ͬ��˵���߽�ɫ��
-
��Ե�����ʱ���ʵ����Ϣ,�ڱ�������������ͳһ�ķ��Ŵ���,��ʱ�䶼��[time]���档
-
����Ի��������ĸ�����ʧ,�����˶���������Ľ�������ʧ��Ϊ������ʧ��
TDS-SATM
�Ի�����Ҫ��Ϣ����ɢ���ڲ�ͬ���ӵ���,������������Dz���Ҫ�ij�������,����������ת�����Ҳ���������ڶԻ��С�Ϊ�˽����������,������������������������:
-
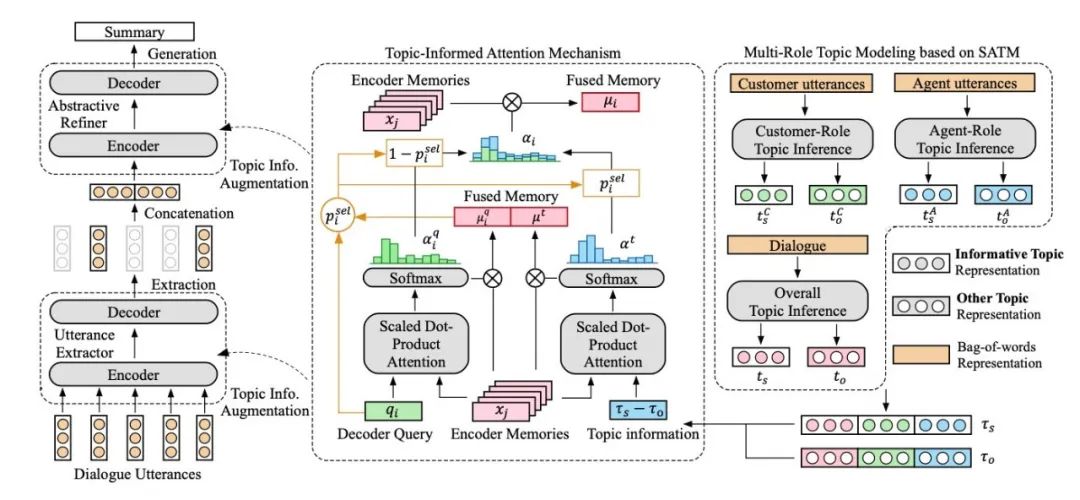
��������ģ�͵Ļ���������������Ը�֪������ģ�� (SATM),ͨ���Ի��ƶϳ�����ֲ������߰������Ϊ����Ϣ��������������⡣��SATM�����ɹ�����,���߰����ժҪ���Ӧ��ÿ������Լ��Ϊ������Ϣ������������,����SATM���������������صĴʡ�
-
Ϊ�˲����ɫ��Ϣ���ӶԻ�����ȡ��������,����ʹ��SATM�ֱ�Կͻ�����,�ͷ����������Ի�ִ�ж��ɫ���⽨ģ������ʹ�����ε�ժҪ������,�������ӳ�ȡ�ʹӳ�ȡ�ľ���������ժҪ����SATM�õ���������Ϣ����ժҪ��������,��ͨ���Ի��е���Ҫ��Ϣ����ժҪ��
ģ�͵�����ܹ�ͼ����ͼ5��ʾ:
3. �����Ķ������Span-level��ȡʽժҪ����DSMRC-S
3.1 ��������
δ����֤���õ��û�����,�����д������˹��ͷ��������û���������,�ͷ�ͬѧ�ӵ��绰�����ֶ���¼�绰������,��ʱ������һ����Ч�ĶԻ�ժҪģ�Ϳ��Դ�����ӿͷ�ͬѧ�Ĺ���Ч��,�����˹��ͷ�����ÿͨ�����ƽ������ʱ�䡣
�����������䷽����CNN/Daily Mail��LCSTS�����ݼ���ȡ���˲�����Ч��,����ʵ�ʵij�������Ȼ�������ܶ���ս������,����ʽժҪ��Ȼȱ���ȶ���(�ظ����߲�����ֵĴ�)������,����ȡʽժҪ���û����ȷ�ı�ע��Ϣȥѵ��ģ��,һ��ͨ����ROUGE-Lָ��ߵľ��ӱ�Ϊ�������ķ�ʽ�Զ���ע���Ӳ�εı�ǩ,������ֻ��ȡ���Ӳ�εĴ����ȷ�ʽҲ���״�������������,���жԻ�ժҪ������ɿ�,���Եõ��ض�����ϢҪ�ء�
Ϊ������ʵ�ʵij���,���ǽ��ܻ����Ķ������Span-Level��ȡʽ�Ի�ժҪ����,�÷������������˹��ͷ���¼��ժҪ,����Ҫ�����ע,Ҳȡ���˲����Ľ����������صijɹ�����Ҳ��SIGIR 2021���ʻ�����,���Ľ���ϸ���ܸ÷�����
3.2 ��������
Ϊ�˽�����жԻ�ժҪ���Եõ�ָ����ϢҪ���Լ�ȱ�ٱ�ע���ݵ�����,���������һ�������ġ�����Զ�̼ල���Ķ�����ij�ȡʽժҪģ��(Distant Supervision based Machine Reading Comprehension Model for Extractive Summarization),���ΪDSMRC-S,����ṹ����ͼ6��ʾ:
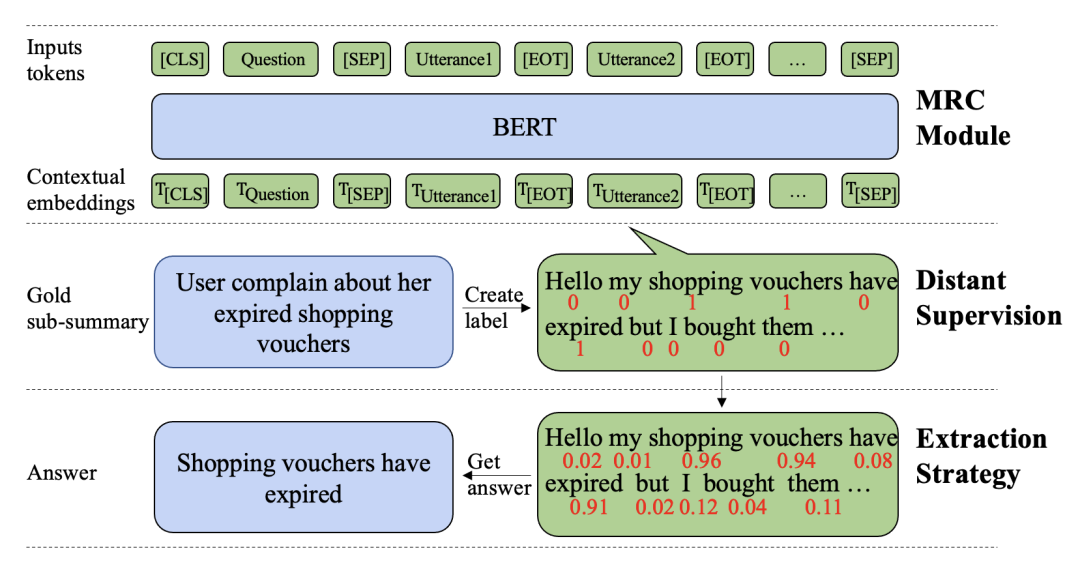
DSMRC-S��һ������BERT��MRC(Machine Reading Comprehension)ģ�顢Զ�̼ලģ���һ�������ܶȵ���ȡ������ɡ���Ԥ������,�Ի��е�Token�ᱻ�Զ���ע,ģ�ͻᱻѵ��ȥԤ��Ի���ÿ��Token�����ڴ��еĸ��ʡ�Ȼ��,������һ��Ԥ��ĸ���,һ�������ܶȵ���ȡ���Իᱻ������ȡ����ʵ�Span��Ϊ�𰸡�
���ǵķ���������Ҫ�ֳ�������:�ٽ��Ի�ժҪ����ת�����Ķ�����;����������ע���Ķ����ⷽ����
�Ի�ժҪת�����Ķ���������
�ͷ��ӵ�һ���绰����Ҫдһ��ժҪ,ժҪ������ͨ�������һЩ�̶��Ĺؼ�Ҫ��,���硰�û����米���������û���������������������ȡ������������ص�,���ǽ��Զ�ժҪ����ת�����Ķ���������,ժҪ�е�ÿһ���ؼ�Ҫ�ض�Ӧ�Ķ����������е�һ�����⡣
����ת���ĺô�����:
-
���Ը���Ч������Ԥѵ������ģ��ǿ�����������������
-
���Seq2Seq�������ݲ��ɿ�,�Ķ�����ķ�ʽ����ͨ���ʾ���и������������,ʹ�ô���ΪժҪ���۽�,���Եõ���ע����ϢҪ�ء�
��������ע���Ķ����ⷽ��
�Ķ�����������Ҫͨ����Ҫ�����ı�ע���ݡ����˵���,�˹��ͷ���¼�˴����Ĺؼ���Ϣ(���硰�û����米���������û����������������������),��Щ��¼������Ϊ�Ķ������ʾ��Ӧ�Ĵ𰸡�Ȼ���˹��ͷ��ļ�¼���ǶԻ���ԭʼ�ı�Ƭ��,����ֱ�����ڳ�ȡʽ�Ķ�����,Ϊ�˽���������,�������������������(�����������ע���Ķ����ⷽ��):
��һ��:Ԥ��Ի���ÿһ��Token�����ڴ𰸵ĸ���
����ͼ6��ʾ,��������ͨ���ж϶Ի��е�Token�Ƿ�����ڴ�(�ͷ���¼�Ĺؼ���Ϣ)��,���Զ���ÿ��Tokenһ����ǩ(�������Ϊ1,���������Ϊ0)��Ȼ��,���Ի�������(Ԥ���õ�,ÿ�������Ӧһ���ؼ�Ҫ��)һ�����뵽BERT��,ʹ��BERT���һ���ÿ��Token���з���,�����һ���Զ���ע�ı�ǩ,������ʧ���¹�ʽ:
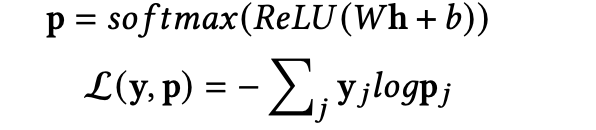
����hΪBERT���һ���Token����,W��b�ǿ�ѵ����Ȩ�ؾ���
�ڶ���:������һ�εĸ�����ѡ�ܶ���ߵ�Span��Ϊ��
����������ܶȵļ��㷽ʽ,����һ����Span,���ܶȼ�������ʽ:
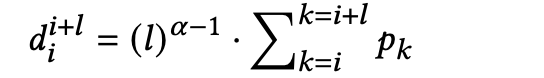
ΪSpan�ij���,���ڵ�һ�εĸ��ʡ�
DSMRC-S��,��������е�Span(�������Խ���˵����),�ܶ���ߵ�Span�ᱻ��ѡΪ������Ĵ�,�������Ǵ���������SpanƬ�ζ����Ը��ǡ�
3.3 ʵ��
�ڱ�����,��������DSMRC-S��ģ������,������ϸ����ʵ�����ú�ʵ������
���ݼ�
���������ų��������н�������,�����ݼ�����40��ζԻ�,ÿ���Ի������ĸ���ϯ��д�Ĺؼ�Ҫ��(�����û�����������ϯ���������)��
ʵ��ϸ��
����ʹ��BERT�Ļ����汾,ʹ�ò���Ϊ��ADAM�Ż��������Ż���������֤����ROUGE-L����ѡ����õ�ģ��,BatchΪ32,����ʵ������Ϊ0.4��
����ָ��
����ʹ�û���������ı�ժҪ�г��õ�BLEU��ROUGE-L (F1) ָ���������������Ͳο��ı�(�ͷ���дժҪ)�Ľӽ��̶�,���Ƿֱ���ھ�ȷ�ʺ�F1��������ģ������ı���ο��ı���n-grams�ϵ��ص������ͬʱ,Distinctָ��Ҳ��ʹ��ȥ�������ժҪ�IJ����ԡ�
�ȽϷ���
-
S2S+Att:һ������RNN+Attention[45]���Ƶ�Sequence-to-Sequence[44]ģ�͡�
-
S2S+Att+Pointer:������Pointer����[50],��ģ���Լ������Ǵ�����һ��Token���ǴӶԻ��и���һ��Token��
-
S2S+Att+Pointer(w):(w)ָ���ǽ�����ժҪ��Ϊһ���������Ԥ��,������Ԥ�����ؼ�Ҫ��,��������ϡ�
-
Trans+Att+Pointer:��RNN�滻ΪTransformer[46]��
-
Trans+Att+Pointer(w):��RNN�滻ΪTransformer,(w)ָ���ǽ�����ժҪ��Ϊһ���������Ԥ��,������Ԥ�����ؼ�Ҫ��,��������ϡ�
-
Leader+Writer:һ����λ���Transformer�ṹ[4],Leaderģ����Ԥ��ؼ�Ҫ������,Writerģ����ݹؼ�Ҫ�������������յ�ժҪ��
-
TDS+SATM:����Transformer�ṹ���о��Ӽ����ժҪ��ȡ���ַ������ժҪ���ɵ����η���[54],��ʹ��������ģ�ͽ���������ǿ��
-
DSMRC-S:��������Ļ����Ķ������Span-level��ȡʽժҪ������
ʵ����
��ʵ��
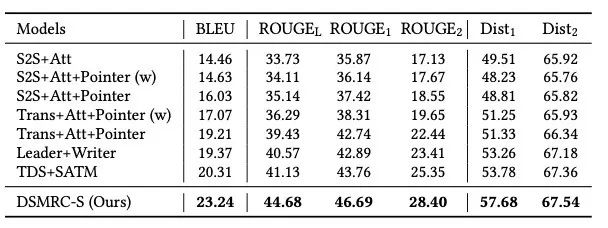
DSMRC-S������Baseline�������������1��ʾ�����ǿ��Եõ����½���:
-
���ǵ�ģ�ͻ������õ�����,����õ�Baseline������BLEU�Ϻ�ROUGE-L�϶�������Լ3%��
-
������ÿ���ؼ�Ҫ�ؽ���Ԥ��ķ�ʽ,���������ժҪ����Ԥ��,Ч�����Ը��á�����,Trans+Att+Pointer��Trans+Att+Pointer(w)Ҫ��ROUGE-L�ϸ�3.62%������ζ���ڿͷ�����,��ժҪ���в��Ԥ�����б�Ҫ�ġ�
-
��ժҪ�IJ���������,���ǵ�ģ��Ҳ�������õ�����,����õ�Baseline������Distinct1ָ����������3.9%��
��ͬ�ؼ�Ҫ���ϵ�����
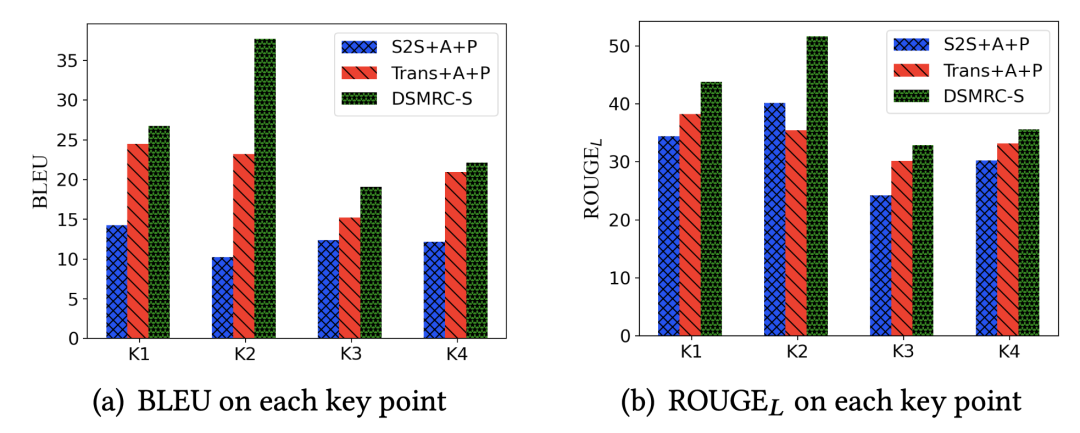
����ͼ��ʾ,����չʾ��ģ����Ԥ�ⲻͬ�Ĺؼ�Ҫ���ϵ����ܡ����ǵķ���DSMRC-S��ÿ���ؼ�Ҫ�ص�Ԥ���϶�����������Baseline����,��˵�����ǵķ��������ڳ�ȡ��ͬ�ؼ�Ҫ�ص����ݡ������,�ڵڶ����ؼ�Ҫ��(�û�������)��,���ǵķ������Ը���(�����������û�����һ���ԭ�ⲻ�����ڶԻ����ᵽ)��
��ͬ���ȵĶԻ��ϵ�����
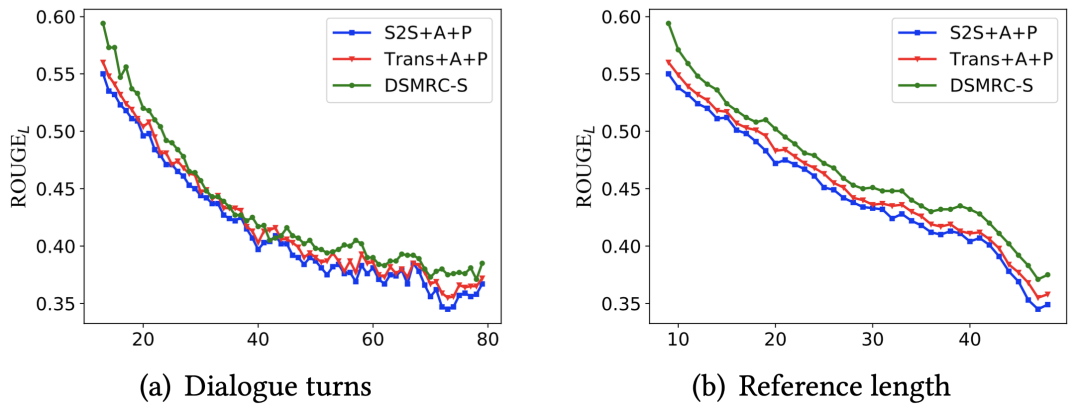
����ͼ��ʾ,����Ҳչʾ��ģ���ڲ�ͬ�ĶԻ��ִκ�ժҪ���ȵ������ϵ����ܡ����ŶԻ��ִκ�ժҪ���ȵ�����,���з�����ROUGE-L���������½�,������ΪԤ���Ѷȵ��������������ǵķ���DSMRC-S�ڲ�ͬ�ĶԻ��ִκ�ժҪ���ȵ�������,�����ֱ�Baseline�������õ�ȷ�ʡ�
4. �ܽ���չ��
�����Ƚ������ı�ժҪ�ľ��䷽��,������ȡʽժҪ����������ʽժҪ����,�������˸�Ϊ���Ļ��ھ���ල�Ķ������Span-Level����,�÷�����ǿ��������ROUGE-Lָ���BLEUָ���ϸ߳���3%���ҡ�δ��,���ǽ������·�������ڶԻ�ժҪ��̽����ʵ��:
-
��Span�𰸵�ժҪ��ȡ����;
-
����Prompt������ʽ�Ի�ժҪ������̽��;
-
�Ի��ṹ����Ƚ�ģ,�����Ϊ�ḻ�ĶԻ���Ϣ��
5. �����
[1] A. M. Rush, S. Chopra, and J. Weston, ��A neural attention model for abstractive sentence summarization,�� in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015.
[2] A. See, P. J. Liu, and C. D. Manning, ��Get to the point: Summarization with pointer-generator networks,�� in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017.
[3] S. Gehrmann, Y. Deng, and A. M. Rush, ��Bottom-up abstractive summarization,�� in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018.
[4] ?C. Liu, P. Wang, J. Xu, Z. Li, and J. Ye, ��Automatic dialogue summary generation for customer service,�� in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019.
[5] ?S. Chopra, M. Auli, and A. M. Rush, ��Abstractive sentence summarization with attentive recurrent neural networks,�� in NAACL HLT 2016.
[6] ?Y. Miao and P. Blunsom, ��Language as a latent variable: Discrete generative models for sentence compression,�� in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016.
[7] ?D. Wang, P. Liu, Y. Zheng, X. Qiu, and X. Huang, ��Heterogeneous graph neural networks for extractive document summarization,�� in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020.
[8] ?M. Zhong, D. Wang, P. Liu, X. Qiu, and X. Huang, ��A closer look at data bias in neural extractive summarization models.��
[9] ?Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, and T. Zhao, ��Neural document summarization by jointly learning to score and select sentences,�� in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018,
[10] ?J. Cheng and M. Lapata, ��Neural summarization by extracting sentences and words,�� in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016
[11] ?R. Nallapati, F. Zhai, and B. Zhou, ��Summarunner: A recurrent neural network based sequence model for extractive summarization of documents,�� in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence,
[12] ?H. Pan, J. Zhou, Z. Zhao, Y. Liu, D. Cai, and M. Yang, ��Dial2desc: End-to-end dialogue description generation,�� CoRR, vol. abs/1811.00185, 2018.
[13] ?C. Goo and Y. Chen, ��Abstractive dialogue summarization with sentence-gated modeling optimized by dialogue acts,�� in 2018 IEEE Spoken Language Technology Workshop, SLT 2018
[14] ?J. Gu, T. Li, Q. Liu, Z. Ling, Z. Su, S. Wei, and X. Zhu, ��Speaker-aware BERT for multi-turn response selection in retrieval-based chatbots,�� in CIKM ��20
[15] ?K. Filippova, E. Alfonseca, C. A. Colmenares, L. Kaiser, and O. Vinyals, ��Sentence compression by deletion with lstms,�� in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015.
[16] R. Nallapati, B. Zhou, C. N. dos Santos, C ?. Gu ?lc ?ehre, and B. Xiang, ��Abstractive text summarization using sequence-to-sequence rnns and beyond,�� in Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016,
[17] A. Celikyilmaz, A. Bosselut, X. He, and Y. Choi, ��Deep communicating agents for abstractive summarization,�� in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics
[18] R. Paulus, C. Xiong, and R. Socher, ��A deep reinforced model for abstractive summarization,�� in 6th International Conference on Learning Representations, ICLR 2018
[19] L. Zhao, W. Xu, and J. Guo, ��Improving abstractive dialogue summarization with graph structures and topic words,�� in Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020,
[20] Y. Zou, L. Zhao, Y. Kang, J. Lin, M. Peng, Z. Jiang, C. Sun, Q. Zhang, X. Huang, and X. Liu, ��Topic-oriented spoken dialogue summarization for customer service with saliency-aware topic modeling,�� in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021
[21] Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, and T. Zhao, ��A joint sentence scoring and selection framework for neural extractive document summarization,�� IEEE ACM Trans. Audio Speech Lang. Process., vol. 28, pp. 671�C681, 2020.
[22] Y. Chen and M. Bansal, ��Fast abstractive summarization with reinforce-selected sentence rewriting,�� in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018.
[23] A. Jadhav and V. Rajan, ��Extractive summarization with SWAP-NET: sentences and words from alternating pointer networks,�� in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018,
[24] S. Narayan, S. B. Cohen, and M. Lapata, ��Ranking sentences for extractive summarization with reinforcement learning,�� in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018,
[25] X. Zhang, M. Lapata, F. Wei, and M. Zhou, ��Neural latent extractive document summarization,�� in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,
[26] Y. Liu, I. Titov, and M. Lapata, ��Single document summarization as tree induction,�� in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019,
[27] ?J. Xu, Z. Gan, Y. Cheng, and J. Liu, ��Discourse-aware neural extractive text summarization,�� in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
[28] ?M. Zhong, P. Liu, Y. Chen, D. Wang, X. Qiu, and X. Huang, ��Extractive summarization as text matching,�� in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
[29] ?Y. Wu, W. Wu, C. Xing, ou, and Z. Li, ��Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots,�� in ACL 2017,
[30] ?Z.Zhang,J.Li,P.Zhu,H.Zhao,andG.Liu,��Modelingmulti-turn conversation with deep utterance aggregation,�� in COLING 2018,
[31] ?X. Zhou, L. Li, D. Dong, Y. Liu, Y. Chen, W. X. Zhao, D. Yu, and H. Wu, ��Multi-turn response selection for chatbots with deep attention matching network,�� in ACL 2018
[32] ?C. Tao, W. Wu, C. Xu, W. Hu, D. Zhao, and R. Yan, ��One time of interaction may not be enough: Go deep with an interaction-over-interaction network for response selection in dialogues,�� in ACL 2019
[33] ?M. Henderson, I. Vulic, D. Gerz, I. Casanueva, P. Budzianowski, S. Coope, G. Spithourakis, T. Wen, N. Mrksic, and P. Su, ��Training neural response selection for task-oriented dialogue systems,�� in Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019
[34] ?J. Devlin, M. Chang, K. Lee, and K. Toutanova, ��BERT: pre-training of deep bidirectional transformers for language understanding,�� in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019,
[35] ?J. Dong and J. Huang, ��Enhance word representation for out-of-vocabulary on ubuntu dialogue corpus,�� CoRR, vol. abs/1802.02614, 2018.
[36] ?C. Goo and Y. Chen, ��Abstractive dialogue summarization with sentence-gated modeling optimized by dialogue acts,�� in 2018 IEEE Spoken Language Technology Workshop, SLT 2018,
[37] ?Q. Chen, Z. Zhuo, and W. Wang, ��BERT for joint intent classification and slot filling,�� CoRR, vol. abs/1902.10909, 2019.
[38] ?L. Song, K. Xu, Y. Zhang, J. Chen, and D. Yu, ��ZPR2: joint zero pronoun recovery and resolution using multi-task learning and BERT,�� in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
[39] S. Chuang, A. H. Liu, T. Sung, and H. Lee, ��Improving automatic speech recognition and speech translation via word embedding prediction,�� IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 93�C105, 2021.
[40] C.-Y. Lin, ��ROUGE: A package for automatic evaluation of summaries,�� in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74�C81.
[41] K. Papineni, S. Roukos, T. Ward, and W. Zhu, ��Bleu: a method for automatic evaluation of machine translation,�� in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics,
[42] J. Li, M. Galley, C. Brockett, J. Gao, and B. Dolan, ��A diversity-promoting objective function for neural conversation models,�� in NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics.
[43] Y. Liu and M. Lapata, ��Text summarization with pretrained encoders,�� in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019,
[44] I.Sutskever,O.Vinyals,andQ.V.Le,��Sequence-to-sequence learning with neural networks,�� in Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014
[45] D. Bahdanau, K. Cho, and Y. Bengio, ��Neural machine translation by jointly learning to align and translate,�� in 3rd International Conference on Learning Representations, ICLR 2015,
[46] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, ��Attention is all you need,�� in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017,
[47] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, ��Exploring the limits of transfer learning with a unified text-to-text transformer,�� J. Mach. Learn. Res., vol. 21, pp. 140:1�C140:67, 2020.
[48] R.Nallapati, F. Zhai, B. Zhou, ��SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents.�� AAAI 2017.
[49] Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, T. Zhao, ��Nerual Document Summarization by Jointly Learning to Score and Select Sentences,�� ACL 2018.
[50] Abigail See, Peter J Liu, and Christopher D Manning. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368, 2017.
[51] Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov and Luke Zettlemoyer. ��BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.�� ACL (2020).
[52] Zhang, Jingqing, Yao Zhao, Mohammad Saleh and Peter J. Liu. ��PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization.�� ArXiv abs/1912.08777 (2020): n. pag.
[53] Yuan, Lin and Zhou Yu. ��Abstractive Dialog Summarization with Semantic Scaffolds.�� ArXiv abs/1910.00825 (2019): n. pag.
[54] Zou, Yicheng, Lujun Zhao, Yangyang Kang, Jun Lin, Minlong Peng, Zhuoren Jiang, Changlong Sun, Qi Zhang, Xuanjing Huang and Xiaozhong Liu. ��Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling.�� AAAI (2021).
[55] Brown, Tom B. et al. ��Language Models are Few-Shot Learners.�� ArXiv abs/2005.14165 (2020): n. pag.
[56] Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. ��Language Models are Unsupervised Multitask Learners.�� (2019).
[57] Radford, Alec and Karthik Narasimhan. ��Improving Language Understanding by Generative Pre-Training.�� (2018).
[58] Mihalcea, Rada and Paul Tarau. ��TextRank: Bringing Order into Text.�� EMNLP (2004).
[59] Hartigan, J. A. and M. Anthony. Wong. ��A k-means clustering algorithm.�� (1979).
[60] Comaniciu, Dorin and Peter Meer. ��Mean Shift: A Robust Approach Toward Feature Space Analysis.�� IEEE Trans. Pattern Anal. Mach. Intell. 24 (2002): 603-619.
[61] Lin, Chin-Yew. ��ROUGE: A Package for Automatic Evaluation of Summaries.�� ACL 2004 (2004).
[62] Papineni, Kishore, Salim Roukos, Todd Ward and Wei-Jing Zhu. ��Bleu: a Method for Automatic Evaluation of Machine Translation.�� ACL (2002).
[63] Ishikawa, Kai, Shinichi Ando and Akitoshi Okumura. ��Hybrid Text Summarization Method based on the TF Method and the Lead Method.�� NTCIR (2001).
[64] Feng, Xiachong, Xiaocheng Feng and Bing Qin. ��A Survey on Dialogue Summarization: Recent Advances and New Frontiers.�� ArXiv abs/2107.03175 (2021): n. pag.
[65] El-Kassas, Wafaa S., Cherif R. Salama, Ahmed A. Rafea and Hoda Korashy Mohamed. ��Automatic text summarization: A comprehensive survey.�� Expert Syst. Appl. 165 (2021): 113679.
[66] Nallapati, Ramesh, Bowen Zhou, C��cero Nogueira dos Santos, ?aglar G��l?ehre and Bing Xiang. ��Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond.�� CoNLL (2016).
[67] Shi, Tian, Yaser Keneshloo, Naren Ramakrishnan and Chandan K. Reddy. ��Neural Abstractive Text Summarization with Sequence-to-Sequence Models.�� ACM Transactions on Data Science 2 (2021): 1 - 37.
[68] Fabbri, Alexander R., Irene Li, Tianwei She, Suyi Li and Dragomir R. Radev. ��Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model.�� ArXiv abs/1906.01749 (2019): n. pag.
[69] Li, Wei and Hai Zhuge. ��Abstractive Multi-Document Summarization Based on Semantic Link Network.�� IEEE Transactions on Knowledge and Data Engineering 33 (2021): 43-54.
[70] DeYoung, Jay, Iz Beltagy, Madeleine van Zuylen, Bailey Kuehl and Lucy Lu Wang. ��MS?2: Multi-Document Summarization of Medical Studies.�� EMNLP (2021).
[71] Nallapati, Ramesh, Feifei Zhai and Bowen Zhou. ��SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents.�� AAAI (2017).
[72] Narayan, Shashi, Shay B. Cohen and Mirella Lapata. ��Ranking Sentences for Extractive Summarization with Reinforcement Learning.�� NAACL (2018).
[73] Zhong, Ming, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu and Xuanjing Huang. ��Extractive Summarization as Text Matching.�� ACL (2020).
[74] Zhang, Jingqing, Yao Zhao, Mohammad Saleh and Peter J. Liu. ��PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization.�� ArXiv abs/1912.08777 (2020): n. pag.
6. ��������
���������١����ۡ���ܡ����ʡ������³��,����������ƽ̨/������������
----------? END? ----------
��Ƹ��Ϣ
���������������������������ܽ�����������Ʒ�з�,��������ҵ�����̬���,�ṩ�������Ϳ������ݵĴ��ģ������������Ӧ���������������з�����,�Ŷ�������ʶ�𡢺ϳɡ��������⡢�����ʴ�Ͷ��ֽ����ȼ������ѽ��ɴ��ģ�ļ���ƽ̨����,���з�������������ˡ����ܿͷ����������ݷ����Ƚ�������Ͳ�Ʒ,�ڹ�˾�ḻ��ҵ���й㷺���;ͬʱ����Ҳ�dz���������ҵ�Ľ��ܺ���,ͨ����������Ӧ��ƽ̨����������ֻ��������֡��������䡢���ܳ�������������鿪չ�Խ�,�������������Ӧ���ṩ�������û���
����������������Ƹ��Ȼ���Դ����㷨����ʦ���㷨ר��,����Ȥ��ͬѧ���Խ�����������chenjiansong@meituan.com��
���ſ��к���
���ſ��к��������ڴ���Ÿ��������У�����л������ǿ�ĺ���������ƽ̨,�������ŷḻ��ҵ����������Դ����ʵ�IJ�ҵ����,���Ŵ���,������ϵ�����,Χ���˹����ܡ������ݡ������������˼�ʻ���˳��Ż������־��á��������������,��ͬ̽��ǰ�ؿƼ��Ͳ�ҵ����������,�ٽ���ѧ�к��������ͳɹ�ת��,�ƶ������˲�����������δ��,�����ڴ���������У�Ϳ���Ժ������ʦ��ͬѧ�ǽ��к�������ӭ��ʦ��ͬѧ�Ƿ����ʼ���:meituan.oi@meituan.com?��
���ܻ�Ƽ�

5��28������,���Ž��;������㷨ר��һ��,�����Ի������㷨�����ķ�չ����������ս,�Լ��ڿͷ����ܻ�������峡�����ģӦ��ʵ�����ĸ����ʵ��,ϣ�����ҽ���ѧϰ,��ͬ������
����������DZ���ɳ����Ʒ��,����˽�����,��ӭ������
Ҳ���㻹�뿴
? |?Transformer ���������������е�ʵ��
? |?DSTC10��������Ի����������ھ������ܽ�
�Ķ�����
---

