Deep Residual Learning for Image Recognition
���ķ���pdf������markdown�ļ�:����ԭ�漰���뼰�ʼ�
resnet����ʵ�ּ���������ͼ�ͽ���:resnet����ʵ�ּ���������ͼ�ͽ���
������Ȳв�ѧϰ��ͼ��ʶ��
ժҪ
? �����ε����������ѵ����(��ע:�������)���������һ���в�ѧϰ���,�ԼԱ���ǰʹ�õ�������и��������ѵ�������Ǹ��ݲ�������ʽ�ؽ������±�ʾΪѧϰ�в��( learning residual functions),������ѧϰδ���庯���������ṩ���ۺϵľ���֤��,������Щ�в�����������Ż�,���ҿ��ԴӴ�������ӵ�����л�þ��ȡ�(��ע:������ȵ�����,����Ҳ������)��ImageNet���ݼ���,���ǹ��Ʋв��������ȿɴ�152��C��vgg�����8����[41],����Ȼ���нϵ͵ĸ����ԡ���Щ�в����ļ�����ͼ���ϵ����ﵽ��3.57%�� �����������ILSVRC2015�ķ��������һ��,���ǻ���CIFAR-10���ݼ�������100���1000������硣
? ��ʾ����ȶ��������Ӿ�ʶ�������Ƿdz���Ҫ�ġ������������ǵı�ʾ�dz�����,������coco���������ݼ��ϵõ���28%����ԸĽ��� ��Ȳв����������Dzμ�ILSVRC & COCO 2015 ��������ʹ��ģ�͵Ļ���,����������ImageNet��⡢ImageNet��λ��COCO����Լ�COCO�ָ��Ͼ�����˵�һ���ijɼ���
1 ����(Introduction)
(��ע:ժҪ��һ����ϸ����)
? ������������[22,21]������ͼ�����[21,50,40]��һϵ��ͻ�ơ����������Ȼ�ؽ���/��/�߲������[50]�ͷ������Զ˵��˵Ķ�㷽ʽ������һ��,�������ġ���Ρ�����ͨ���ѵ��������((���)���ḻ�������֤��[41,44]����,�������������Ҫ,�ڸ�����ս�Ե�ImageNet���ݼ�[36]�ϵ����Ƚ��[41,44,13,16]�������ˡ��dz��[41]ģ��,���Ϊ16[41]��30[16]������������ƽ��(nontrivial)���Ӿ�ʶ������[8,12,7,32,27]Ҳ�ӷdz����ģ���л������ࡣ
? �������Ҫ�Ե�������,������һ������:ѧϰ���õ��������ѻ�����IJ�һ��������?�ش���������һ���ϰ���������֪���ݶ���ʧ/��ը[1,9]������,����һ��ʼ���谭������(hamper convergence )��Ȼ��,��������ںܴ�̶�����ͨ��������ʼ��[23,9,37,13]���м��һ����(batch normalization)[16]�������,��ʹ����ʮ��������ڷ���������ݶ��½�(SGD)���ܹ�������
? ������������ܹ���ʼ����ʱ,�ͻᱩ¶��һ���˻�����:����������ȵ�����,ȷ�Դﵽ����(����ܲ���Ϊ��),Ȼ��Ѹ���˻����������ϵ���,�����˻������ɹ�����������,��[10,41]���в���,�������ǵ�ʵ������֤��,����������ӵ��ʵ���ȵ�ģ�����ᵼ�¸��ߵ�ѵ�������(**��ע:**ovefitting��ѵ���ȽϺö����Բ���,����������Ǹ��������ѵ����Ҳ���Ǻܺ�)ͼ1��ʾ��һ������ʾ����
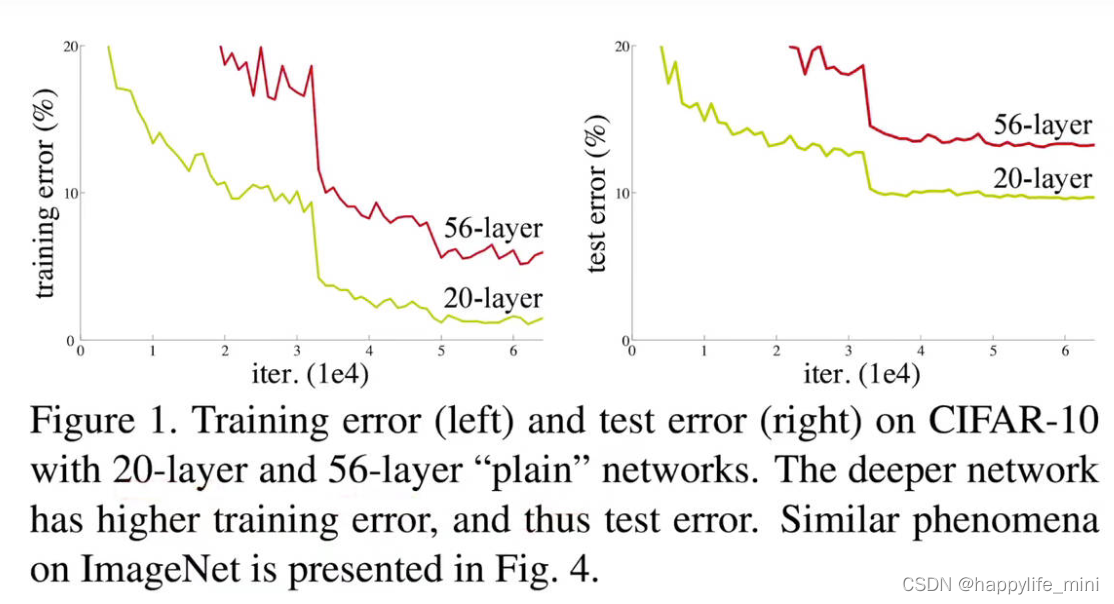
ͼ1��20���56�㡰���ء������CIFAR-10�ϵ�ѵ������(��)�Ͳ��Դ���(��)������Խ��,ѵ�����Խ��,�������Խ��ͼ4�и�����ImageNet�ϵ�����������
? (ѵ�����ȵ�)�˻�����,������������ṹ��ͬ�������Ż��������ǿ���һ����dz�������һ�������Ӧ�ĸ���Ľṹ(��ע:���������ָ������dz�������ټ�һЩ����ȥ),�������������Ӹ���㡣���ڹ���������ģ��,���ǿ����ҵ�һ�ֽ������:���ӵIJ��Ǻ��ӳ��,���������Ǵ�ѧϰ��dz��ģ���и��Ƶġ��ù����������Ĵ��ڱ���,�����ģ�Ͳ��������dzģ���ߵ�ѵ����(��ע:���dz������ѵ���IJ���,�������Ч����Ӧ�ñ��,������֮�������ӳ��IJ�,���۲����,����ʵ�ʽ�������)����ʵ�����,�������е���������ҵ���������ȹ���Ľ�������û����(���ڿ���ʱ����������)��
? �ڱ�����,����ͨ��������Ȳв�ѧϰ���(deep residual learning framework)������˻����⡣���Dz���ϣ��ÿ���ѵ��IJ㶼ֱ���ʺ�����Ļ���ӳ��,������ʽ������Щ�����һ���в�ӳ��(residual mapping)�� ��������ĵײ�ӳ��Ϊ H(x),�����öѵ��ķ����Բ��������һ��ӳ��: F(x):=H(x)?x�� ���ԭ����ӳ��ת��Ϊ: F(x)+x�����Ǽ����Ż��в�ӳ����Ż�ԭʼ��δ�ο���ӳ�����ס��ڼ��������,������ӳ�������ŵ�,�в����������һ�ѷ����Բ���Ϻ��ӳ������ס�(��ע:����˼��,�����Ѿ���һ��ģ��ѧ����x,��֮������µIJ�,����ԭ���¼���IJ�Ҫѧϰ����H(x),���ڲ�ѧH(x),������ѧϰH(x)-x,��ô��ʵ�¼���IJ�ѧϰ������ʵֵ��֮ǰѧ�õ�ֵ�IJв�)
? ��ʽ F(x)+x ����ͨ��ǰ��������( feedforward neural networks )��**���������(shortcut connections)��**��ʵ��(ͼ2)��(��ע:���ϸ�����90����Ѿ������)shortcut connections[2,34,49]������һ������������ӡ��ڱ�����,shortcut connectionsִֻ�к��ӳ��,���ǵ���������ӵ����Ӳ�������(ͼ2)��**��Ƚݾ����ӼȲ����Ӷ���IJ���,Ҳ�����Ӽ���ĸ����ԡ�**����������Ȼ����ʹ�÷�����SGD���ж˵��˵�ѵ��,���ҿ���ʹ�ù�����(����caffe[19])��ʵ��,�������������( solvers)��
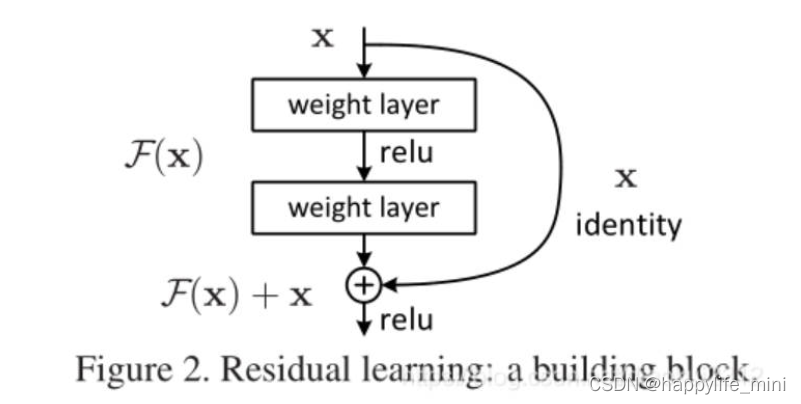
? ͼ2���в�ѧϰ:һ����ľ��
? ������ImageNet[36]�Ͻ������ۺ�ʵ��,��˵���˻����Ⲣ�����ǵķ��������������������:
? 1) ���ǵļ���в����������Ż�,����Ӧ�ġ����ء���(���IJ����)������ȵ�����,ѵ�����ϴ�;
? 2) ���ǵ����в������������ش���ȵĴ���������л�þ�������,����ǰ����������Ľ��Ҫ�õöࡣ
? CIFAR-10���ݼ���Ҳ���������Ƶ�����,���������������ķ������Ż��ѶȺ�Ч�����������Ƕ���һ���ض����ݼ����Եġ�������������ݼ���չʾ�˾����ɹ�ѵ����100�����ϵ�ģ��,��̽����1000�����ϵ�ģ�͡�
? ��ImageNet���༯[36]��,�������ü���IJв����õ��˺ܺõĽ�������ǵ�152��ʣ����������Ϊֹ��ImageNet�ϳ��ֵ����������,���临�Ӷ���Ȼ����vgg����[41]�����ǵ������ImageNet���Լ�����3.57%��ǰ5����( top-5 error),����ILSVRC 2015���ྺ���л���˵�һ������������ʶ��������Ҳ�кܺõķ�������,ʹ������ILSVRC�е�ͼ�������⡢ͼ�����綨λ��coco����coco�ָ�����˵�һ������һǿ������֤�ݱ���,�в�ѧϰԭ����ͨ�õ�,���������������������Ӿ��ͷ��Ӿ����⡣
2 ��ع���(RelatedWork)
(��ע:����֮ǰ�����Ѿ�����һЩ��ع���)
? **�в��ʾ��**��ͼ��ʶ����,VLAD[18]���òв��������ֵ���б���ı�ʾ,Fisher����[30]���Ա�ʾΪVLAD�ĸ��ʰ汾[18]�����߶���ͼ������ͷ����������ʾ��[4,48]������ʸ������,����ʣ������[17]�ȱ���ԭʼʸ������Ч��
? �ڵ�ˮƽ�Ӿ��ͼ����ͼ��ѧ��,�������ƫ�ַ���(PDEs),�㷺ʹ�õĶ�������[3]�ڶ�߶��Ͻ�ϵͳ���¶���Ϊ������,����ÿ�������⸺��ϴֺͽ�ϸ�߶�֮��IJв��( residual solution )�������������һ��ѡ���Ƿֲ��Ԥ����( hierarchical basis preconditioning)[45,46],���������������߶�֮���ʾ�в������ı�����[3,45,46]��֤����Щ������Ȳ�֪����IJв����ʵı�����������ÿ�öࡣ��Щ��������,һ���õ��䷽��Ԥ�������Լ��Ż���
? ��������� �ݾ�����[2, 34, 49] �Ѿ������˺ܳ���һ��ʵ���������о����̡�һ��ѵ������֪��(MLPs)������ʵ��������һ�����Բ�,�������������ӵ����[34,49]����[44,24]��,һЩ�м��ֱ�����ӵ�����������,���ڽ����ʧ/��ը�ݶ�(������)��[39,38,31,47]������������ýݾ�����ʵ�ּ��в���Ӧ���ݶȺʹ������ķ�������[44]��,��Inception��������һ���ݾ���֧�ͼ�������ķ�֧��ɵġ�
? ���ͬʱ,�� ��������(��highway networks��)[42,43]���ݾ��������ſغ���[15]�����������Щ������������,�����в���,�����ǵĺ�ȿ������( identity shortcuts )�������ġ����ſؽݾ����رա�(�ӽ�����)ʱ,��·���еIJ��ʾ�Dzв�����෴,���ǵĹ�ʽ����ѧϰ�в��;���ǵĺ�ȿ��������Զ����ر�,������Ϣ���ᱻ���ݳ�ȥ,�����ӵIJв������ѧϰ������,������������ȼ���(����,����100��)�������,û�б��ֳ���ȷ�Ե���ߡ�
3 Deep Residual Learning
3.1 �в�ѧϰ(Residual Learning)
? �����ǰ�H(x)�������ɼ��������(��һ����������)��ɵĵײ�ӳ��,��x��ʾ��Щ���еĵ�һ��������롣��������������Բ���Խ����ƽ����Ӻ���[28],������������ǿ��Խ����ƽ��в��,��H(X)?x(������������������ͬ��ά��)�����,�����������Ӳ����H(X),����������ʽ������Щ�����һ���в��F(x):=H(x)?x��ԭ���ĺ�����˱��F(x)+x����Ȼ��������ʽ��Ӧ���ܹ������ؽ������������ĺ���(�����),��ѧϰ�����׳̶ȿ����Dz�ͬ�ġ�
? ����**���±�ʾ( reformulation)**�����й��˻�����ķ�ֱ��������������(ͼ1,��)�����������ڽ����������۵�,������Խ����ӵIJ㹹��Ϊ���ӳ��,������ε�ģ��Ӧ�þ��в�������dz��ṹ��ѵ�������˻������������ߺ����ö�������Բ�ƽ����ӳ�䡣���òв�ѧϰ�ع�,������ӳ�������ŵ�,������߿��Լؽ���������Բ��Ȩֵ������,�Աƽ����ӳ�䡣
? ��ʵ�������,���ӳ�䲻̫���������ŵ�,�������ǵ����±��������������Ԥ�������а����ġ�������ź������ӽ��ں��ӳ���������ӳ��,�������Ӧ�ø������ҵ�����ӳ���йص��Ŷ�(perturbations),�����ǽ�����Ϊ�µ��Ŷ���ѧϰ������ͨ��ʵ��(ͼ7)֤����ѧϰ�IJв��һ�㶼�н�С����Ӧ,˵�����ӳ���ṩ�˺�����Ԥ������
3.2 ͨ����ݷ�ʽ���к��ӳ��(Identity Mapping by Shortcuts)
? ���Ƕ�ÿ��������IJ�β��òв�ѧϰ��ͼ2��չʾ����һ����ľ��(building block )����ʽ��,�ڱ�����,���ǿ�����һ����ľ�鱻����Ϊ:
? y = F(x, {Wi}) + x. (1)
? ����x��y�ǿ��ǵIJ��������������������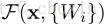
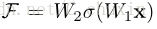
? ��ʽ(1)�е�shortcut����û�����Ӷ���IJ����ͼ��㸴�Ӷ����ⲻ����ʵ���к���������,���������DZȽ���ͨ����Ͳв�����ʱҲ����Ҫ�� ���ǿ����ڲ�������ȡ������Լ�����ɱ�����ͬ�Ļ����϶�����������й�ƽ�ıȽ�(���˿��Ժ��Բ��Ƶ�Ԫ�ؼ��ļӷ�)��
? �ڵ�ʽ(1)��,x��F��ά��������ȡ��������������(����,�ڸ�������/���ͨ��ʱ),���ǿ���ͨ���������ִ������ͶӰWs ,��ƥ��ά��:
? y = F(x, {Wi}) +Wsx. (2)
? �ڵ�ʽ(2)��,���ǻ�����ʹ�÷���Ws������,���ǽ�ͨ��ʵ��֤��,���ӳ����ڽ���˻��������㹻��,�����Ǿ��õ�,���ֻ����ƥ��ά��ʱ��ʹ��Ws��
? �в��F����ʽ�����ġ����ĵ�ʵ���漰һ������F,����������������(ͼ5),Ȼ���������и���IJ㡣�����Fֻ��һ������,��ʽ1���������Բ�:y=w1x+x,�Դ�����û�з����κ����ơ�
? ���ǻ�ע�,��ȻΪ�˼����,������ʾ���ǹ���ȫ��ͨ���,�����������ھ����㡣����F(x,{wi})���Ա�ʾ��������㡣Ԫ�ؼ��ӷ�������������ӳ������Ӧͨ����ִ�еġ�.
3.3 ������ϵ�ṹ(Network Architectures)
? ���Dz����˸�����ͨ/�в�����,���۲쵽һ�µ�����Ϊ���ṩ���۵�ʵ��,���Ƕ�ImageNet������ģ�ͽ���������������
? Plain���硣 ���ǵ�plain����ṹ(ͼ3,��)��Ҫ��VGG���� (ͼ.3,��)����������������ҪΪ3*3���˲���,����ѭ��������Ҫ��:(i) �������ӳ��ߴ���ͬ�IJ㺬����ͬ�������˲���;(ii) ��������ߴ����,���˲�������������һ������֤ÿ���ʱ�临�Ӷ���ͬ������ֱ���ò���Ϊ2�ľ���������²�����������һ��ȫ��ƽ���ز��һ������Softmax��1000·ȫ���Ӳ��������ͼ3(��),��Ȩֵ�IJ������Ϊ34 ��
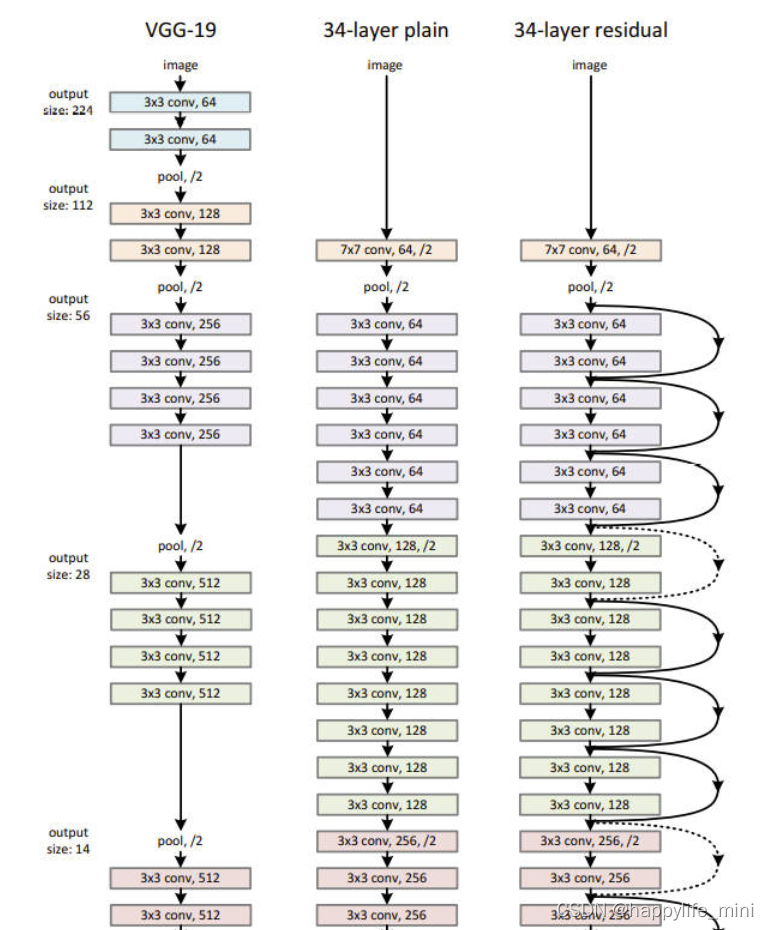

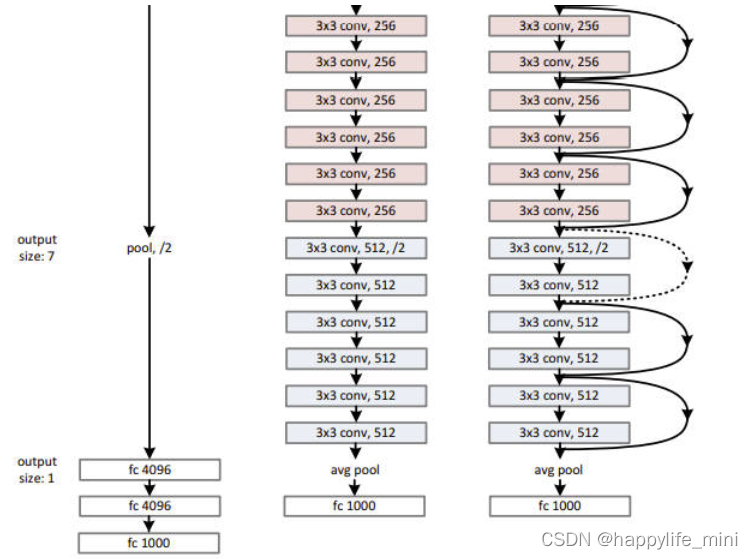

ͼ3 ��Ӧ��ImageNet�������ܾ����� ��:VGG-19ģ�� (196�ڸ�FLOPs)��Ϊ�ο�����:plain����,����34��������(36 �ڸ�FLOPs)����:�в�����,����34��������(36�ڸ�FLOPs)�����߱�ʾ��shortcuts������ά�ȡ�Table 1չʾ�˸���ϸ�ں��������塣
? ֵ��ע�����,��vgg��[41](ͼ3,��)���,���ǵ�ģ�;��и��ٵ��˲������͵ĸ��Ӷȡ����ǵ�34�����(baseline)��36��FLOPs�˼�),��ΪVGG-19(196��FLOPs)��18%��
? **�в����硣**��������plain����,���Dz���������(ͼ3,��)������ת��Ϊ��Ӧ�IJв�汾�������������ߴ���ͬʱ(ͼ3�е�ʵ�߿������),����ֱ��ʹ�ú�ȿ�ݼ�(��ʽ1)�� ��ά������ʱ(��3�е����߲���),��������ѡ��:
? (A) shortcut��Ȼʹ�ú��ӳ��,�����ӵ�ά����ʹ��0�����,�������������Ӷ���IJ���;
? (B) ʹ�ù�ʽ2��ӳ��shortcut��ʹά�ȱ���һ��(ͨ��11�ľ���)�� ����������ѡ��,��shortcut��Խ���ֳߴ������ͼʱ,��ʹ��strideΪ2�ľ�����**(��ע:1 * 1������ͼ��������ı����,����,32 32* 64������ͼ,����256��1* 1* 64�ľ�����,���յõ�32* 32*256������ͼ)**
3.4 ʵ��(Implementation)
? ���Ƕ�ImageNet��ʵ����ѭ��[21,41]�е������� ����ͼ��Ĵ�Сʹ���Ķ̱߳�������Ĵ�[256,480] �в����������ߴ���չ( scale augmentation)[41]�� ��ͼ�����ˮƽ��ת�������ȡ224��224 crop,����ȥÿ������ƽ��(the per-pixel mean)[21]��ʹ����[21]�е�����ɫ��ǿ��������ѭ[16],��ÿ�ξ���֮��,�ڼ���֮ǰ��������һ��(BN)[16]��������[13]һ����ʼ��Ȩ��,���㿪ʼѵ������plain/�в���������ʹ��С������СΪ256��SGD��ѧϰ���ʴ�0.1��ʼ,������ȶ�ʱ����10,���� ����ģ�ͽ���60?10^4�ε���ѵ����(��ע:��������ͨ�������batch size�Ĵ�С���иı�,��������һ��˵Ϊѵ�����ٱ����ݼ�)����ʹ�õ�Ȩ��˥��Ϊ0.0001,����Ϊ0.9��(��ע:���ڱȽϱ��IJ�����ʼ��)���Dz�ʹ��Dropout[14],����[16]��������
? �ڲ�����,Ϊ�˽��бȽ�,���Dz�ȡ����10-crop���ԡ� Ϊ��ȡ����õ�Ч��,���Dz�����[41,13]�е�ȫ������ʽ,�����ڶ�߶���ƽ������(ͼ������С,ʹ�϶̵�һ��Ϊ{224,256,386,480,640}(��ע:��ͬ�ķֱ���))��
4 ʵ��(Experiments)
4.1 ImageNet����(ImageNet Classification)
? ������ImageNet 2012�������ݼ�[36]�����������ǵķ���,�����ݼ�����1000���ࡣģ����128����ѵ��ͼ���Ͻ�����ѵ��,��50k����֤ͼ���Ͻ��������������ǻ�����˲��Է����������100k�Ų���ͼ������ս��������������ǰ1λ��ǰ5λ�Ĵ�����(top-1 and top-5 error rates)��
? **��ͨ�����硣**������������18���34����ͨ���硣34����ͨ����ͼ3(��)��18����ͨ���������Ƶ���ʽ.��ϸ����ϵ�ṹ����1��
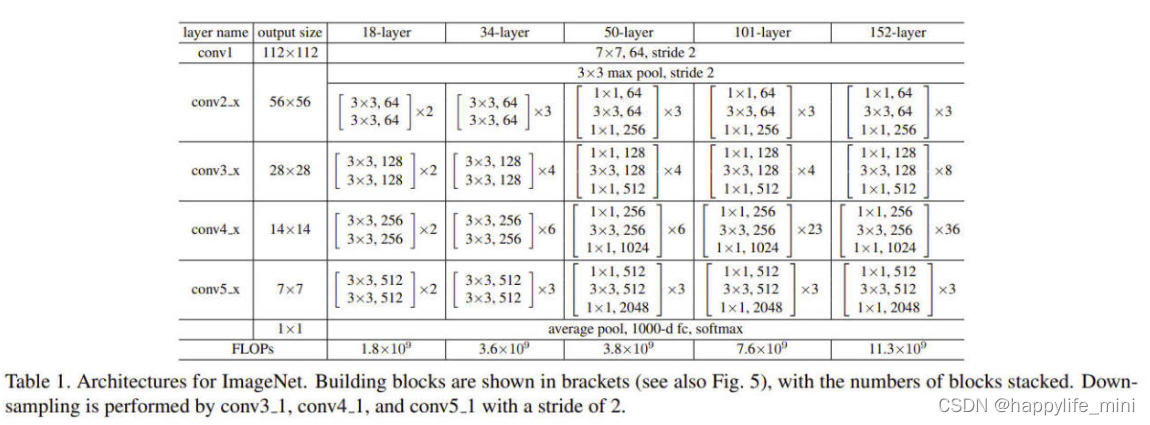
��1. ��Ӧ��ImageNet�Ľṹ��ܡ�������Ϊ������IJ���(ͬ����Fig.5),������������жѵ����²�����strideΪ2��conv3_1��conv4_1��conv5_1 ��ʵ�֡�
(��ע:���ڸ��������ṹ��50,101,152���resnet,ʹ�õĸ����ƿ�����bottleneck,��1* 1�ľ�����ͨ����)
? ��2�Ľ������,�����34����ͨ���Ƚ�dz��18����ͨ�����и��ߵ���֤��Ϊ�˽�ʾԭ����ͼ4(��)��,������ѵ�������бȽ����ǵ�ѵ��/��֤��������������ѵ�������й۲쵽��34����ͨ�����˻���������������ѵ��������ѵ�����ϴ�,����18����ͨ���Ľ�ռ�( solution space)��34����ͨ�����ӿռ䡣
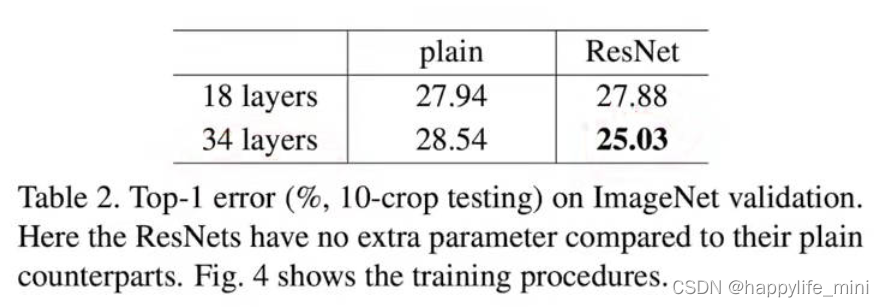
��2��ImageNet��֤�ϵ�Top-1����(%,10-crop ����)��������,����ͨ�ĶԵ������,�в���û�ж���IJ�����ͼ4չʾ����ѵ���̡�
? ������Ϊ�����Ż����Ѳ�̫���������ݶ���ʧ����ġ���Щ������ʹ��BN[16]����ѵ��,�Ӷ�ȷ��ǰ�����źž��з��㷽����ǻ���֤��ʹ��BN������ݶȾ��н�������Ϊ(norms)������������ǰ��������źŶ�������ʧ����ʵ��,34����ͨ����Ȼ�ܹ��ﵽ���о������ľ���(��3),������������ij�̶ֳ��Ͽ��Թ����������Ʋ�����ͨ�����ܾ���ָ������ĵ������ٶ�,�Ӷ�Ӱ��ѵ�����ļ�С��3�C�����Ѿ������˸����ѵ������(3��),����Ȼ�۲쵽�˻�����,�����������ⲻ����ͨ����ʹ�ø���ĵ�����������������Ż����ѵ�ԭ���ڽ������о���
? **�в����硣**������,��������18���34��в���(ResNet).���߽ṹ��������ͨ����ͬ,ֻ��Ҫ����ÿ��3��3������������һ���������,��ͼ3(��)��ʾ���ڵ�һ���Ƚ���(��2��ͼ4��),����ʹ�����п�ݷ�ʽΪ���ӳ��,�Լ�ʹ�����������ά��(ѡ��A)�����,����ͨ�Ķ�Ӧ�������,����û�ж���IJ�����
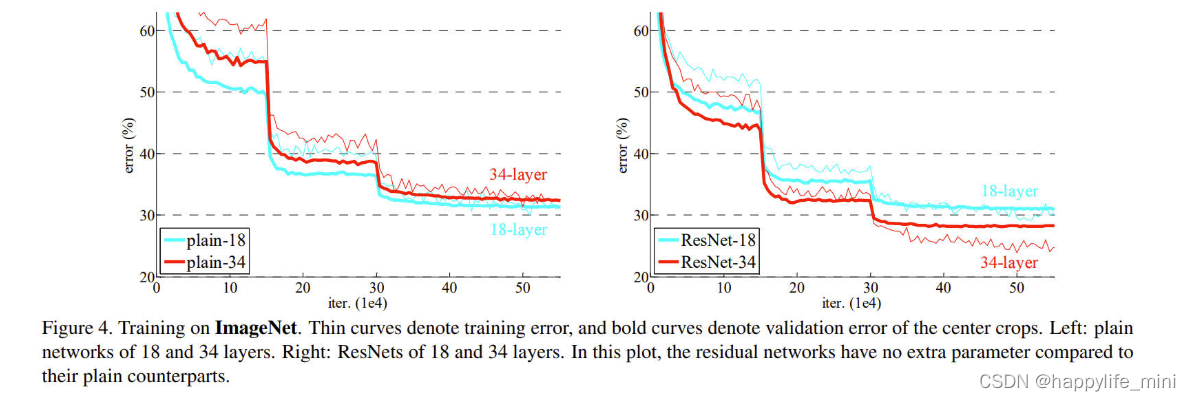
ͼ4������ImageNet��ѵ����ϸ���߱�ʾѵ�����,�������߱�ʾ����crop����֤����:18���34�����ͨ���硣��:18���34��в����硣�ڴ�ͼ��,����ͨ�������,�в�����û��(����)����IJ�����
? ���Ǵӱ�2��ͼ4����������Ҫ�Ĺ۲���������,ʹ�òв�ѧϰ�������֮ǰ(��ͨ��)�෴----34��ResNet����18�� ResNet(2.8%).����Ҫ����,34��ResNet��ѵ�����ҪС�ö�,���ҿ����ƹ㵽��֤���ݡ������,�����������,�˻�����õ��˺ܺõĽ��,���������跨�����ӵ�����л���˾������档(��ע:��ɫ�Ľ�ϸ���߱�ʾ����ѵ�����,֮����ѵ��������ڲ������,����Ϊ��ѵ����ʹ�ô���������ǿ,ʹ��ѵ�����ϴ�,�����Ե�ʱ��δ��������ǿ,�����Ƚϵ�;���ߵ�����λ����ѧϰ�ʵ��½�,ѧϰ�ʳ���0.1,�ڻ��һ���������Сѧϰ��,�����ݽ��и���ȷ��ѵ��,������Ӧ�ý���,��Ϊ�ں�ʱ���Dz�ȷ���ġ�������cos(x)��������Ϊѧϰ�ʵ��½��ٶ�,ȡ���˱ȽϺõĽ����)
? �ڶ�,����ͨ�Ķ�Ӧ�������,34��ResNetʹTop-1��������3.5%(��2),���dzɹ��ؼ�����ѵ�����(ͼ2)�Ľ��(ͼ4�� VS ��))����һ�Ƚ���֤�˲в�ѧϰ�ڼ���ϵͳ�ϵ���Ч�ԡ�
? ���,���ǻ�ע�,18����ͨ/�в������д�����ȵľ�ȷ��(��2),��18��ResNet�������ٶȸ���(ͼ4�� VS ��)�������硰��̫�(���������18��)ʱ,��ǰ��SGD���������Ȼ�ܹ�Ϊ��ͨ�����ҵ��õĽ�������������������,ResNetͨ�������ڽ��ṩ����������ٶ������Ż���
? ��ȿ�ݼ� VS **ͶӰ��ݼ�( Projection Shortcuts)��**�����Ѿ�֤��,�����ĺ�ȿ�ݼ�������ѵ���������������о�ͶӰ��ݼ�(��ʽ2���ڱ�3��,���DZȽ�������ѡ��:
? (A)������ݼ���������ά��,���п�ݷ�ʽ����������(���2��ͼ4����ͬ);
? (B)ͶӰ��ݼ��������ӳߴ�,��������ݼ��Ǻ�ȿ�ݼ�;
? ?���п�ݼ�����ͶӰ��ݼ���
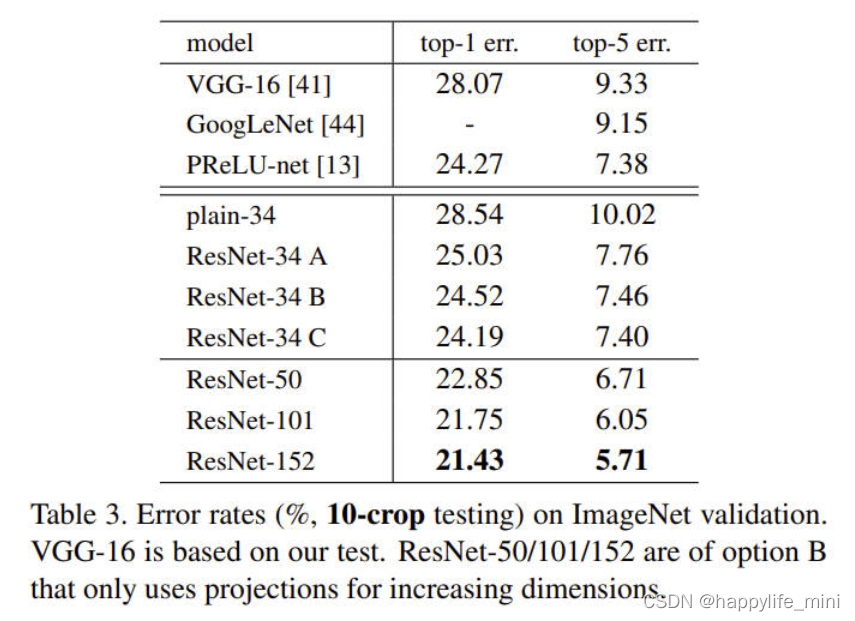
��3����ImageNet��֤�Ĵ�����(%,10-crop����)��vgg-16�ǻ������ǵIJ��ԡ�ResNet-50/101/152���ڷ���B ,��ֻ�����ӵ�ά��ʹ��ͶӰ(��ݼ�)��
? ��3��ʾ,����������ѡ�����ͨ�Ķ�Ӧ����Ҫ�õöࡣB��A�Ժ�,������Ϊ,������ΪA��������ά��ʵ���ϲ�û��(ʹ��)�в�ѧϰ��C��B�Ժ�,���ǰ������������(13��)ͶӰ��ݼ�����Ķ������������a/b/c֮���С�������,ͶӰ��ݼ����ڽ���˻����Ⲣ����Ҫ�����,�ڱ��ĵ����ಿ����,������ʹ��ѡ��c�Խ��ͼ���/ʱ�临�ӶȺ�ģ�ʹ�С����ȿ�ݼ����ڲ�����������ܵ�ƿ���ܹ�(bottleneck architectures)�ĸ������ر���Ҫ��(��ע:ͶӰ�����ӻ�������㸴�Ӷ�,����resnet����ʹ��B����,����1* 1������һ��ͶӰ)
? �����ε�ƿ���ܹ���(��ע:���������resnet)������,���ǽ������������ImageNet�ĸ����ε����硣���ڿ��ǵ����Ǹ��������ѵ��ʱ��,���ǽ���ľ��(building block)��Ϊƿ�����(bottleneck design)������ÿ���в��F,����ʹ��һ����3����ɵĶ�ջ,������2��(ͼ5)��������ֱ���1��1��3��3��1��1����,����1��1�㸺���СȻ������(�ָ�)ά��,ʹ3��3���Ϊ����/���ά����С��ƿ��(��ע:���ټ���)��ͼ5������һ������,����������ƶ��������Ƶ�ʱ�临�Ӷ���
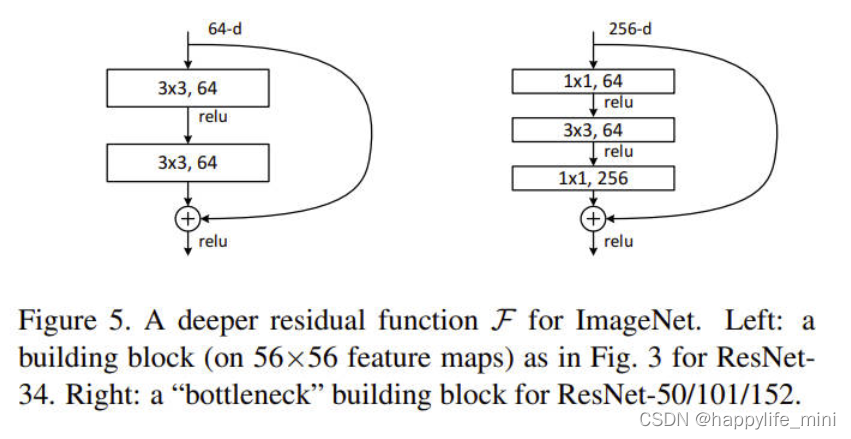
ͼ5��ImageNet��һ�������εIJв��F����ͼ:��ͼ3��ʾ������ResNet-34��һ������ľ��(��56��56����ͼ��)����:ResNet-50/101/152�ġ�ƿ������ľ�顣
? �����ĺ�ȿ�ݼ�����ƿ���ܹ�������Ҫ�������ͼ5(��)�е�ͬ��ȿ�ݼ���ͶӰ��ݼ�����,���Կ���ʱ�临�ӶȺ�ģ�ʹ�С�ӱ�,��Ϊ��ݷ�ʽ���ӵ�������ά�˵㡣���,��ȿ�ݼ�Ϊƿ������ṩ�˸���Ч��ģ�͡�
? 50��ResNet:���ǽ�34�������е�ÿ��2����滻Ϊ���3��ƿ����,�Ӷ��γ�һ��50��ResNet(��1)������ʹ��ѡ��B������ά�ȡ�����ģʽ��38�ڴ�FLOPs��
? **101���152�� ResNet:**����ʹ�ø���������������101���152���ResNet(��1)��ֵ��ע�����,��Ȼ�����������,��152�� ResNet((113�ڴ� FLOPs)�ĸ�������Ȼ����vgg-16/19��(153/196�ڴ� FLOPs)��
? 50/101/152��ResNet��34�������൱��̶ȵ�ȷ������(��3�ͱ�4)������û�й۲쵽�˻�������,���,���ǿ������ܴӴ�����ӵ�����л�õ������ľ�ȷ�ԡ���������ָ�궼�ܿ�����ȵĺô�(��3�ͱ�4)��
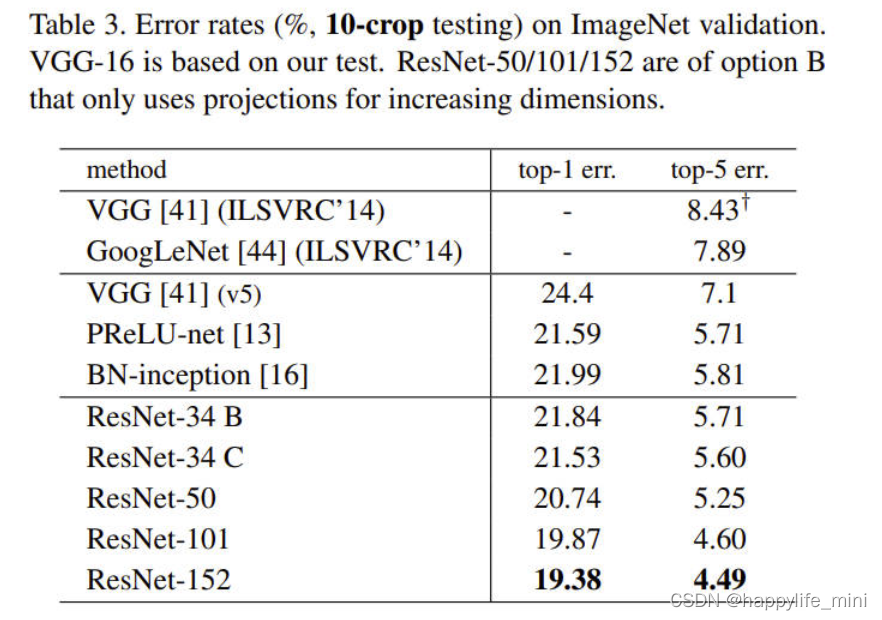
? ��4��ImageNet��֤���ϵ�ģ�ͽ���Ĵ�����(%)(����?�����˲��Լ�)��
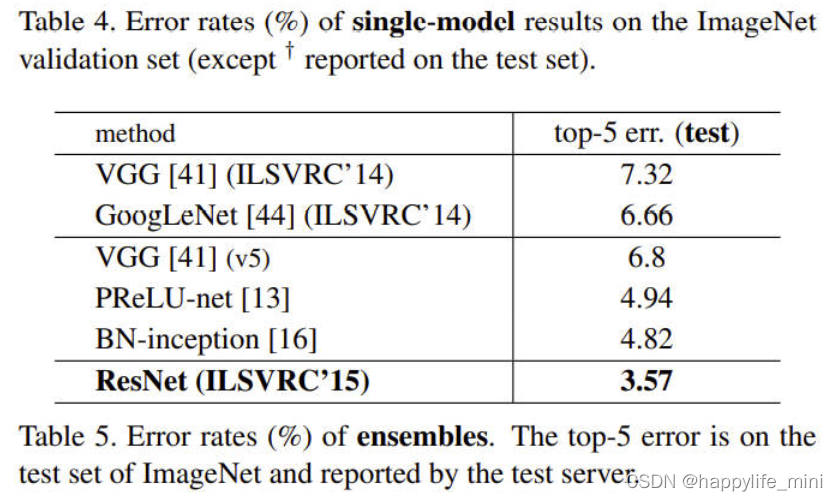
? **�����Ƚ��ķ����Ƚϡ�**�ڱ�4��,���ǽ���֮ǰ��õĵ�ģ�ͽ�����бȽϡ����ǵĻ���34��ResNet�Ѿ��ﵽ�˷dz�������ȷ�ԡ����ǵ�152�� ResNet�ĵ�ģ��Top-5��֤���Ϊ4.49%�������һģ�͵Ľ������������ǰ�ļ��ɽ��(��5)�����ǽ�������ͬ��ȵ�ģ����ϳ�һ������(���ύʱֻ������152������)���⽫�õ��˲��Լ���3.57%��Top-5����(��5).��һ��Ŀ�����2015��ILSVRC�ĵ�һ����
4.2 CIFAR-10�����(CIFAR-10 and Analysis)
? ������CIFAR-10���ݼ�[20]�����˸�����о�,�����ݼ�����50��ѵ��ͼ���10������10k����ͼ��������ѵ�����Ͻ�����ʵ��ѵ��,���ڲ��Լ��Ͻ��������������ǵ��ص��Ǽ����������Ϊ,�������ƽ����Ƚ��Ľ��,������������ʹ�üļܹ����¡�
? ��ͨ/�в�ṹ��ѭͼ3(��/��)�е���ʽ����������32��32ͼ��,ÿ���ر���ȥÿ����ƽ��( with the per-pixel mean subtracted)����һ��Ϊ3��3�����㡣Ȼ��,�����ڳߴ�Ϊ{32,16,8}������ӳ���Ϸֱ�ʹ��3��3�����Ĺ�6n�����,ÿ��������ͼ��С����2n�㡣�˲����ֱ�Ϊ{16,32,64}���²�������2�IJ����ľ�����ִ�еġ�������ȫ��ƽ���ء�10·ȫ���Ӳ��softmaxΪ����������6n+2���Ȩ�㡣�±������˸���ϵ�ṹ:
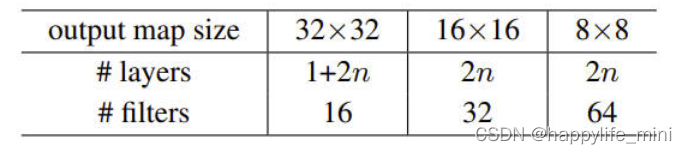
? ��ʹ�ÿ������ʱ,���DZ����ӵ�3��3��Ķ���(�ܹ�3n���ݾ�)����������ݼ���,��������������¶�ʹ����ȿ�ݼ�(��ѡ��A),���,���ǵIJв�ģ�͵���ȡ����ȺͲ������Ӧ����ͨģ����ȫ��ͬ��
? ����ʹ��Ȩ��˥��Ϊ0.0001,����Ϊ0.9,��������[13]�е�Ȩֵ��ʼ����[13]��bn[16],��û��ʹ��Dropout����Щģ����������GPU��ѵ����,С������СΪ128�����ǵ�ѧϰ�ٶ�Ϊ0.1,�ڵ�32K��48K�ε���ʱ����10,��64k����ʱ��ֹѵ��,������45k/5kѵ��/��֤�ķָ���������ǰ���[24]�еļ�������ǿ����ѵ��:ÿ�����4������,�����ͼ���ˮƽ��ת�������ȡ32��32֡�����ڲ���,����ֻ����ԭʼ32��32ͼ��ĵ�һͼ��
? ���DZȽ�n={3,5,7,9},�Ӷ��γɵ�20,32,44��56�����硣ͼ6(��)��ʾ����ͨ������Ϊ������ͨ�������������,���ѵ�����ϴ��������������ImageNet(ͼ4��)��mnist(��[42])�ϵ�����,����������Ż�������һ���������⡣
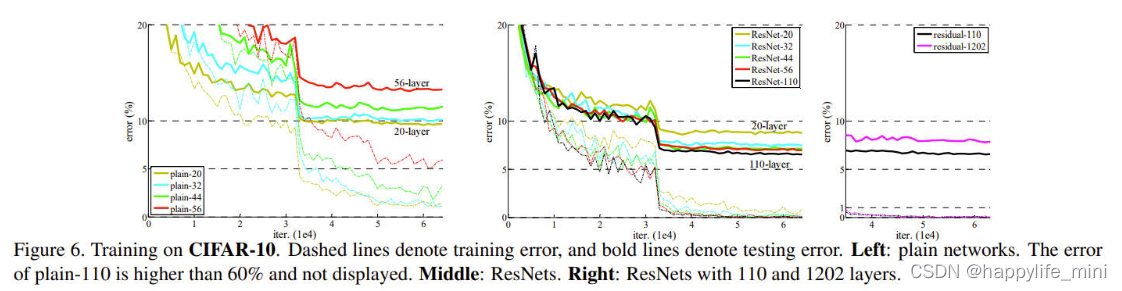
ͼ6����CIFAR-10�ϵ�ѵ�������߱�ʾѵ������,�����߱�ʾ���Դ�����:��ͨ���硣��ͨ-110��������60%,����ʾ���м�:�в�������:��110���1202��IJв�����
? ���ǽ�һ��̽���˵�n=18ʱ��õ�110��ResNet�������������,���Ƿ��ֳ�ʼѧϰ����0.1̫��,��������ʼ���������,����ʹ��0.01��ѧϰ����Ϊѵ������,ֱ��ѵ�����С��80%(Լ400�ε���),Ȼ��ѧϰ���ʸ�Ϊ0.1����ѵ����ѧϰ�ƻ������ಿ�ֺ���ǰһ�������110�������ܹ��ܺõ�����(ͼ6, ��)�����IJ����� FitNet[35]�� Highway42����������ݵ�������,��ȴ�����Ƚ��Ľ��֮һ(6.43%,��6)��
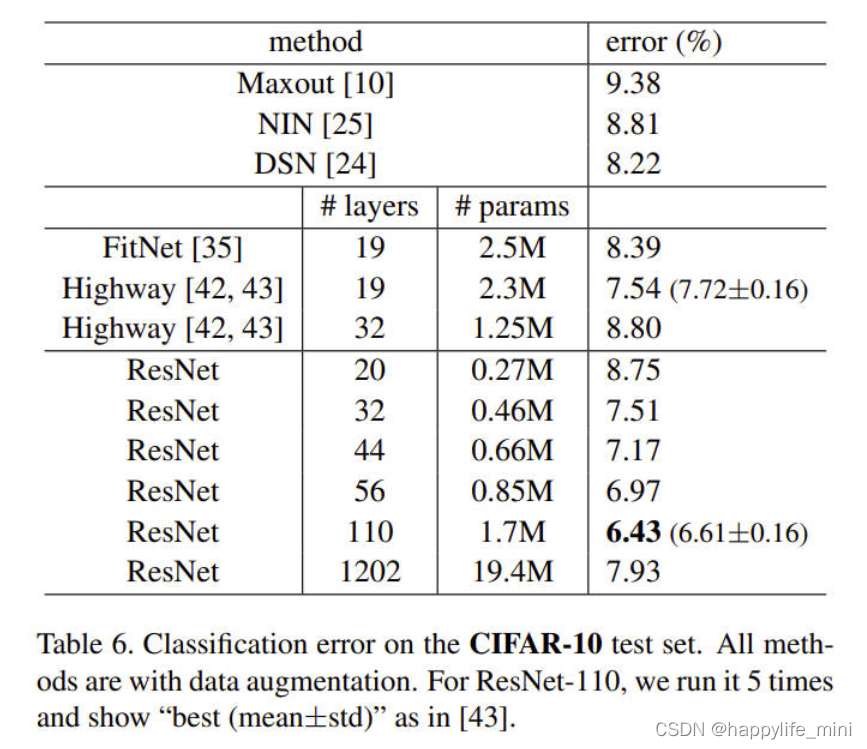
��6��CIFAR-10���Լ��ķ���������з�ʽ����������ǿ������ResNet-110,��������5��,��ʾ�����(ƽ����STD)��,��[43]�С�
? **����Ӧ������**ͼ7��ʾ����Ӧ�ı���(std)����ӦΪÿ��3��3������,����BN֮��,������������(relu/�ӷ�)֮ǰ������ResNet,��������ʾ�˲в������Ӧǿ�ȡ�ͼ7�����в�������Ӧһ�����ͨ����С����Щ���֧�������ǵĻ�������(��3.1��),���в��һ��ȷDzв�����ӽ����������ǻ�ע�,�����ResNet����Ӧ���Ƚ�С,��ͼ7��ResNet-20��56��110֮��ıȽ���ʾ�����и���IJ�ʱ,������һ��в��������ڶ��źŽ��н��ٵ��ġ�(**��ע:����������IJ�û��ʹ��ģ�ͱ�ø���,�����вв����ӵĴ���,�����¼ӵIJ㲻��ѧ���κζ���,Ȩֵ���ǿ���0;**��˼����˵������1000��Ķ���,����Ҳ��ǰ100������,������900�������û��ʲô��������ѧϰ,���������ͼ��������ʾ,����������ͨ�����resnet�õ���ͬ�IJ���,��ͨ�������û��ѵ����,�������Ա�)
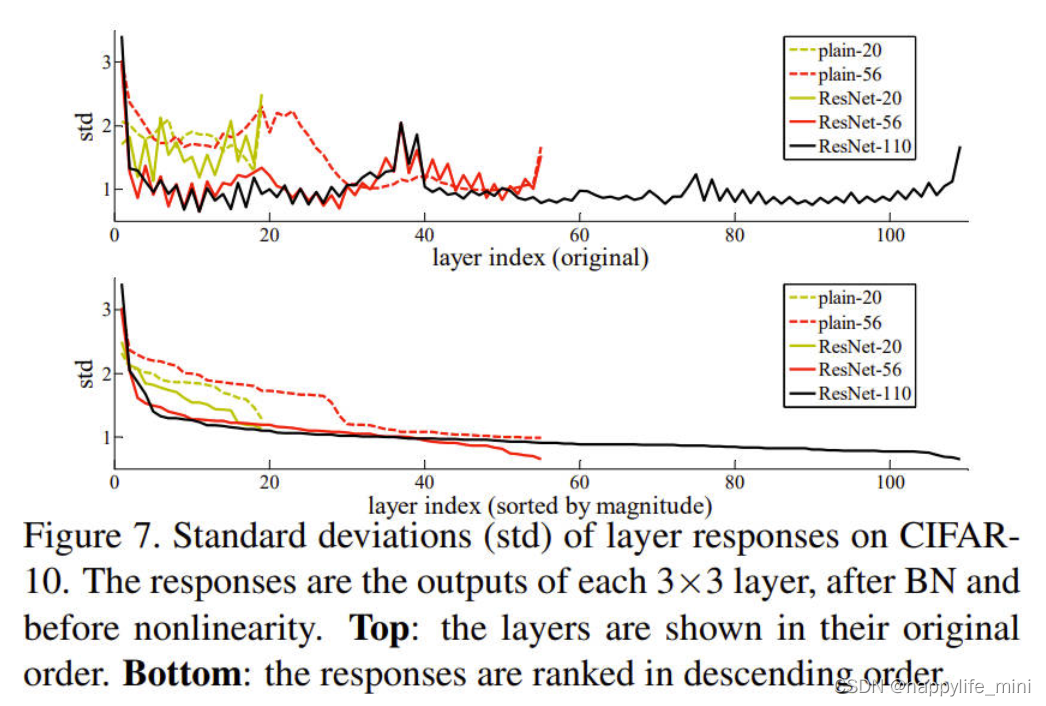
ͼ7��CIFAR-10����Ӧ�ı���(STD)����Ӧ��ÿ��3��3������,��BN֮��,�ڷ�����֮ǰ������:���㰴ԭ����˳����ʾ���ײ�:��Ӧ���������С�
? **̽������1000��(������)��**����̽����һ������1000������ģ�͡���������n=200�õ�1202������,���������������������������ѵ�������ǵķ����������Ż�����,��1000�������ѵ�����С��0.1%(ͼ6,��)�����IJ��������Ȼ�൱��(7.93%,��6)��
? ������Щ����������ģ����,�Դ���һЩ�д���������⡣���1202������IJ��Խ�������ǵ�110�������,�������߶������Ƶ�ѵ����������Ϊ������Ϊ��������������С���ݼ�,1202��������ܲ���Ҫ�ش�(19.4M)���ڴ����ݼ�ʹ��ǿ����,��maxout[10]��dropout[14],���Ի����ѽ��([10,25,24,35]�����ڱ�����,����ʹ�õ����� maxout/��©�ķ���,ֻ��ͨ������ݵĽṹ�����ʵ������,������ɢ���Ż������ѵĹ�ע������,���ǿ���������Ͽ�����߽��,�������ǽ���о��ķ���
4.3 ����PASCAL��MS-COCO��Ŀ����(Object Detection on PASCAL and MS COCO)
? �÷���������ʶ��������нϺõķ������ܡ���7�ͱ�8��ʾ��PASCAL VOC 2007 and 2012[5]��COCO[26]��Ŀ������߽�������Dz���Faster R-CNN[32]��Ϊ��ⷽ����������,���Ƕ���ResNet-101�滻VGG-16[41]�ĸĽ�����Ȥ��ʹ��������ģ�͵ļ��ʵ��(����¼)����ͬ��,�������ֻ�ܹ鹦�ڸ��õ����硣��ֵ��ע�����,�ھ�����ս�Ե�coco���ݼ���,���ǵõ���coco��������6.0%������(map@[.5,.95]),,����һ��28%����ԸĽ�����һ������ȫ�鹦����ѧϰ�ı���(learned representations)��
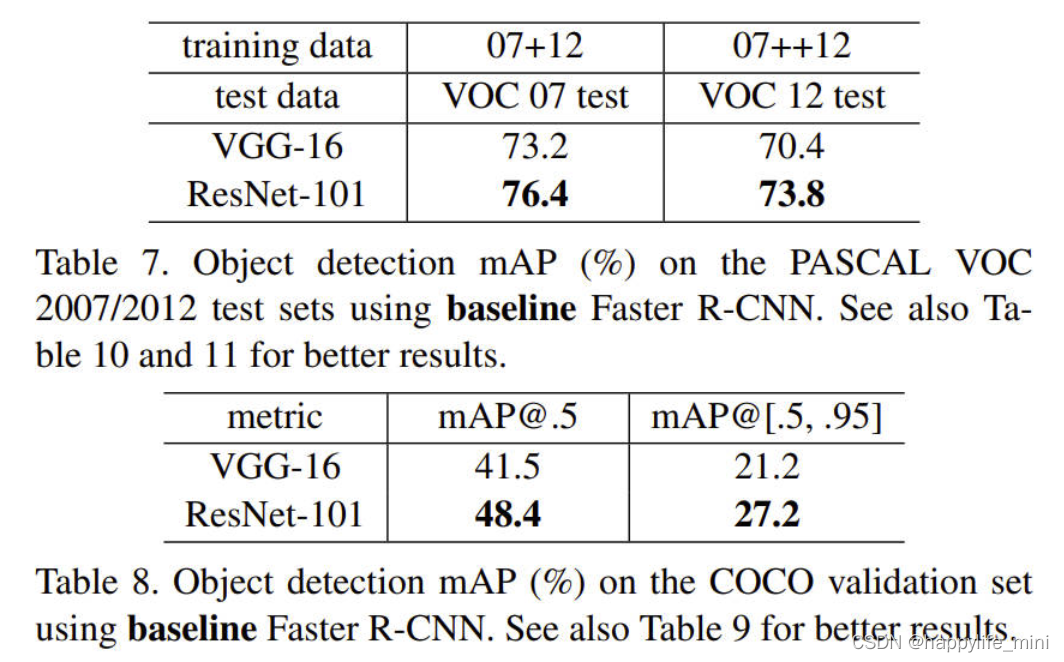
��7����Pascal voc 2007/2012���Լ���ʹ�û���Faster R-CNN��Ŀ���� mAP(%)�����õĽ����10��11��
��8����coco��֤���� ʹ�û���Faster R-CNN��Ŀ����mAP(%)��������9,�Ի�ø��õĽ����
(��ע:mAP����Ŀ��������õ����ں���ê�ȵ�ָ��,Խ��Խ��)
? �������ʣ����,������ILSVRC�ļ�����Ŀ�л���˵�һ��:Imagenet���,ImageNet��λ,coco����coco�ָ�������¼��
References(�����)
[1] Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on NeuralNetworks, 5(2):157�C166, 1994.
[2] C. M. Bishop. Neural networks for pattern recognition. Oxford university press, 1995.
[3] W. L. Briggs, S. F. McCormick, et al. A Multigrid Tutorial. Siam, 2000.
[4] K. Chatfield, V. Lempitsky, A. Vedaldi, and A. Zisserman. The devil is in the details: an evaluation of recent feature encoding methods. In BMVC, 2011.
[5] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zis-serman. The Pascal Visual Object Classes (VOC) Challenge. IJCV, pages 303�C338, 2010.
[6] S. Gidaris and N. Komodakis. Object detection via a multi-region & semantic segmentation-aware cnn model. In ICCV, 2015.
[7] R. Girshick. Fast R-CNN. In ICCV, 2015.
[8] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[9] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
[10] I. J. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio. Maxout networks. arXiv:1302.4389, 2013.
[11] K. He and J. Sun. Convolutional neural networks at constrained time cost. In CVPR, 2015.
[12] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
[13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[14] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
[15] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735�C1780, 1997.
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[17] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. TPAMI, 33, 2011.
[18] H. Jegou, F. Perronnin, M. Douze, J. Sanchez, P. Perez, and C. Schmid. Aggregating local image descriptors into compact codes. TPAMI, 2012.
[19] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093, 2014.
[20] A. Krizhevsky. Learning multiple layers of features from tiny images. Tech Report, 2009.
[21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[22] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to hand-written zip code recognition. Neural computation, 1989.
[23] Y.LeCun, L.Bottou, G.B.Orr, andK.-R.M��ller. Efficientbackprop. In Neural Networks: Tricks of the Trade, pages 9�C50. Springer, 1998.
[24] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeply-supervised nets. arXiv:1409.5185, 2014.
[25] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv:1312.4400, 2013.
[26] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll��r, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV. 2014.
[27] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[28] G. Mont��far, R. Pascanu, K. Cho, and Y. Bengio. On the number of linear regions of deep neural networks. In NIPS, 2014.
[29] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
[30] F. Perronnin and C. Dance. Fisher kernels on visual vocabularies for image categorization. In CVPR, 2007.
[31] T. Raiko, H. Valpola, and Y. LeCun. Deep learning made easier by linear transformations in perceptrons. In AISTATS, 2012.
[32] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[33] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. arXiv:1504.06066, 2015.
[34] B. D. Ripley. Pattern recognition and neural networks. Cambridge university press, 1996.
[35] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio. Fitnets: Hints for thin deep nets. In ICLR, 2015.
[36] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. arXiv:1409.0575, 2014.
[37] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv:1312.6120, 2013.
[38] N. N. Schraudolph. Accelerated gradient descent by factor-centering decomposition. Technical report, 1998.
[39] N. N. Schraudolph. Centering neural network gradient factors. In Neural Networks: Tricks of the Trade, pages 207�C226. Springer,1998.
[40] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. Le- Cun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[41] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[42] R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks. arXiv:1505.00387, 2015.
[43] R. K. Srivastava, K. Greff, and J. Schmidhuber. Training very deep networks. 1507.06228, 2015.
[44] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, 2015.
[45] R. Szeliski. Fast surface interpolation using hierarchical basis functions. TPAMI, 1990.
[46] R. Szeliski. Locally adapted hierarchical basis preconditioning. In SIGGRAPH, 2006.
[47] T. Vatanen, T. Raiko, H. Valpola, and Y. LeCun. Pushing stochastic gradient towards second-order methods�Cbackpropagation learning with transformations in nonlinearities. In Neural Information Processing, 2013.
[48] A. Vedaldi and B. Fulkerson. VLFeat: An open and portable library of computer vision algorithms, 2008.
[49] W. Venables and B. Ripley. Modern applied statistics with s-plus. 1999.
[50] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional neural networks. In ECCV, 2014.

