CS224N WINTER 2022(һ)������(��Assignment1��)
CS224N WINTER 2022(��)�����������硢�������(��Assignment2��)
CS224N WINTER 2022(��)RNN������ģ�͡��ݶ���ʧ���ݶȱ�ը(��Assignment3��)
CS224N WINTER 2022(��)�������롢ע�������ơ�subwordģ��(��Assignment4��)
CS224N WINTER 2022(��)Transformers���(��Assignment5��)
����
��ʮ������������Ȼ���Դ���ǰ�����������,�ⲿ������Ŀǰ���ҹ���һ��,���������ı�ע,��Ϊ�ܶ����µ��о��;���ijɹ�����ϸ���Ƽ��Ķ����ṩ��paper����������,Ŀǰֻ������¼���ʵ�,�ʴ�(QA)�ⲿ���Ǻ���Ȥ��,֪ʶ��������������ʴ���ϢϢ��ص�,Coreference�������dz�˵�ı���ʶ������,��Ȼ����������һ���ܿ�����о�����,�ֵ�seq2seq��������ΪNLG
����,CS224N��һ����,���������ص㿴��ƪ�������paper,Ȼ���հ�CS224W��һ�¼�¼,��֮��ø������ˡ�
����Ŀ¼
lecture 11 �ʴ�ϵͳ
slides
[slides]
-
�ʴ�ϵͳ������:
- �𰸲ο���Դ:�ı���Ϣ�������ĵ���֪ʶ�⡢����ͼƬ��
- ��������:������(factoid)��dz�����(non-factoid)����������(open-domain)��������(closed-domain)����(simple)�������(compositional)���⡣
- ������:һ�仰��һ�λ���ö�����н�����ж��⡣
-
Freebase:���ڷǽṹ�����ı�
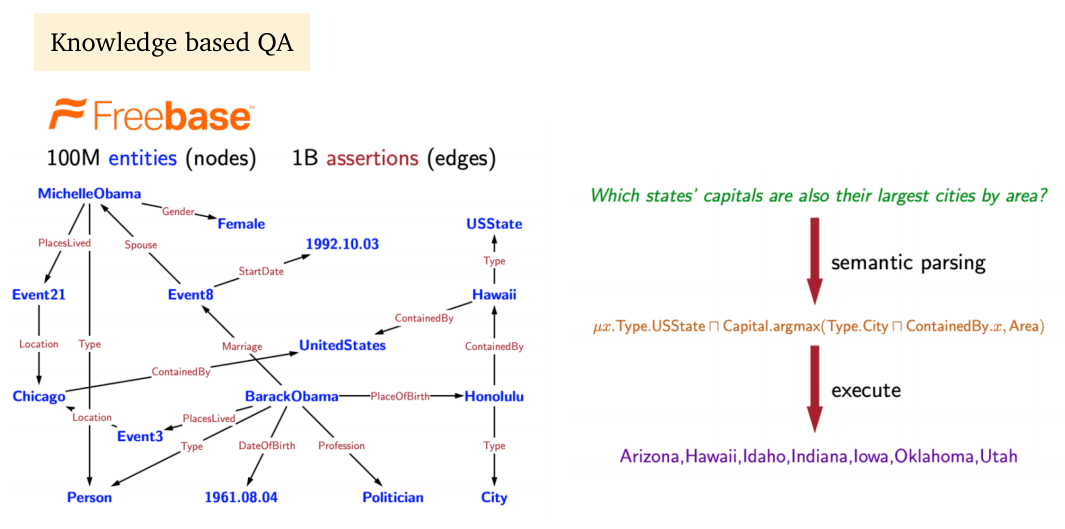
-
SQuAD:˹̹���ʴ����ݼ�,�����Ƽ��Ķ������н�Ϊ��ϸ��˵��;
������һЩ�ʴ����ݼ�:TriviaQA,Natural Questions,HotpotQA;
��ι���ģ�ͽ��SQuAD:
-
ģ������: C = { c 1 , . . . , c N } , Q = ( q 1 , . . . , q M ) , c i �� V , q i �� V C=\{c_1,...,c_N\},Q=(q_1,...,q_M),c_i\in V,q_i\in V C={c1?,...,cN?},Q=(q1?,...,qM?),ci?��V,qi?��V,���� N �� 100 , M �� 15 N\approx100,M\approx15 N��100,M��15
-
ģ�����: 1 �� start �� end �� N 1\le\text{start}\le \text{end}\le N 1��start��end��N
-
2016~2018���ʹ�õ��Ǵ�ע�������Ƶ�LSTMģ��:
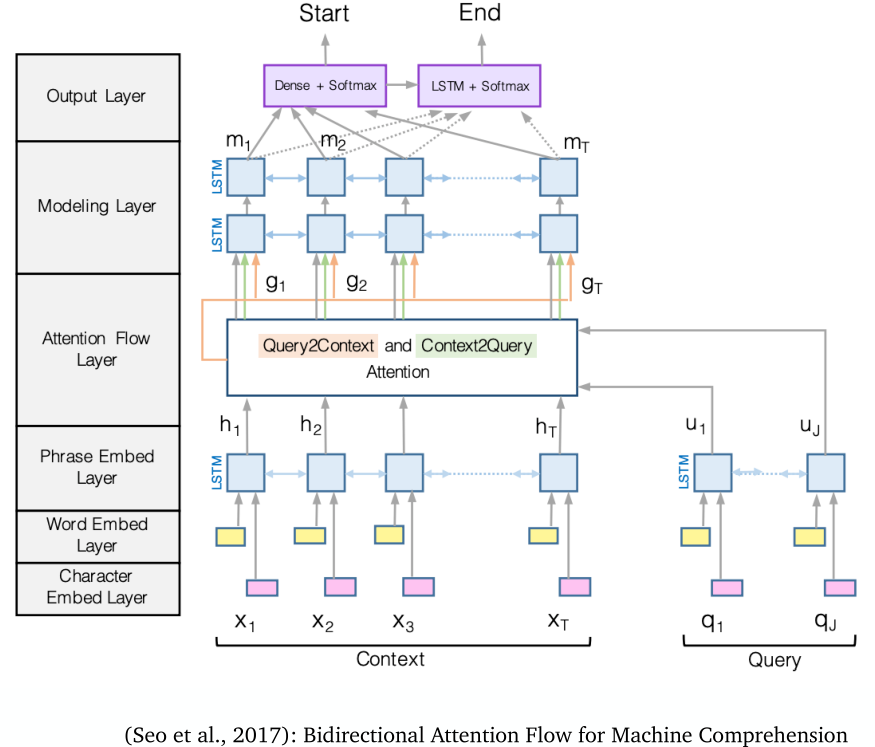
���������ͼ����BiDAFģ�Ϳ�ܵ�˼��(�ο��������Ƽ��Ķ��ĵڶ�ƪ)��
����� C C C��һ��BiLSTM��,����Q����һ��BiLSTM��,Ȼ�����ߵ�����״̬ȡע����,��������������BiLSTM��,�����ȫ���Ӳ���������(���ģ�ͼܹ�����BiDAF)
�������,BiDAF��Ƕ���õ�GloVeƴ����CNN����õ���Ƕ��charEmb:
emb ( c i ) = f ( [ GloVe ( c i ) ; charEmb ( c i ) ] ) emb ( q i ) = f ( [ GloVe ( q i ) ; charEmb ( q i ) ] ) \text{emb}(c_i)=f([\text{GloVe}(c_i);\text{charEmb}(c_i)])\\ \text{emb}(q_i)=f([\text{GloVe}(q_i);\text{charEmb}(q_i)]) emb(ci?)=f([GloVe(ci?);charEmb(ci?)])emb(qi?)=f([GloVe(qi?);charEmb(qi?)])
Ȼ�����뵽BiLSTM��:
c i �� = LSTM ( c i ? 1 �� , e ( c i ) ) �� R H c i �� = LSTM ( c i ? 1 �� , e ( c i ) ) �� R H c i = [ c i �� ; c i �� ] �� R 2 H q i �� = LSTM ( q i ? 1 �� , e ( q i ) ) �� R H q i �� = LSTM ( q i ? 1 �� , e ( q i ) ) �� R H q i = [ q i �� ; q i �� ] �� R 2 H \overset{\rightarrow}{c_i}=\text{LSTM}(\overset{\rightarrow}{c_{i-1}},e(c_i))\in\R^H\\ \overset{\leftarrow}{c_i}=\text{LSTM}(\overset{\leftarrow}{c_{i-1}},e(c_i))\in\R^H\\ {\bf c}_i=[\overset{\rightarrow}{c_i};\overset{\leftarrow}{c_i}]\in\R^{2H}\\ \overset{\rightarrow}{q_i}=\text{LSTM}(\overset{\rightarrow}{q_{i-1}},e(q_i))\in\R^H\\ \overset{\leftarrow}{q_i}=\text{LSTM}(\overset{\leftarrow}{q_{i-1}},e(q_i))\in\R^H\\ {\bf q}_i=[\overset{\rightarrow}{q_i};\overset{\leftarrow}{q_i}]\in\R^{2H} ci?��?=LSTM(ci?1?��?,e(ci?))��RHci?��?=LSTM(ci?1?��?,e(ci?))��RHci?=[ci?��?;ci?��?]��R2Hqi?��?=LSTM(qi?1?��?,e(qi?))��RHqi?��?=LSTM(qi?1?��?,e(qi?))��RHqi?=[qi?��?;qi?��?]��R2H
��������ע��������Ǽ��� c i {\bf c}_i ci?�� q i {\bf q}_i qi?�ĵ��ע����,����������ע����(context-to-query attention��query-to-context attention)
������������±���ʽ:
S i , j = w s i m ? [ c i ; q i ; c i �� q i ] �� R w s i m �� R 6 H S_{i,j}=w_{\rm sim}^\top[{\bf c}_i;{\bf q}_i;{\bf c}_i\odot{\bf q}_i]\in\R\quad w_{\rm sim}\in\R^{6H} Si,j?=wsim??[ci?;qi?;ci?��qi?]��Rwsim?��R6H
context-to-query attention(ÿ�����ⵥ���� c i c_i ci?�Ĺ�����)���¼���:
�� i , j = softmax j ( S i , j ) �� R a i = �� j = 1 M �� i , j q j �� R 2 H \alpha_{i,j}=\text{softmax}_j(S_{i,j})\in\R\quad{\bf a}_i=\sum_{j=1}^M\alpha_{i,j}{\bf q}_j\in\R^{2H} ��i,j?=softmaxj?(Si,j?)��Rai?=j=1��M?��i,j?qj?��R2H
query-to-context attention(ÿ���������㵥���� q i q_i qi?�Ĺ�����)���¼���:
�� i = softmax i ( max ? j = 1 M ( S i , j ) ) �� R N b = �� i = 1 N �� i c i �� R 2 H \beta_{i}=\text{softmax}_i(\max_{j=1}^M(S_{i,j}))\in\R^N\quad {\bf b}=\sum_{i=1}^N\beta_i{\bf c_i}\in \R^{2H} ��i?=softmaxi?(j=1maxM?(Si,j?))��RNb=i=1��N?��i?ci?��R2H
���յ�ע�������Ϊ:
g i = [ c i ; a i ; c i �� a i ; c i �� b i ] �� R 8 H {\bf g}_i=[{\bf c}_i;{\bf a}_i;{\bf c}_i\odot{\bf a}_i;{\bf c}_i\odot {\bf b}_i]\in\R^{8H} gi?=[ci?;ai?;ci?��ai?;ci?��bi?]��R8H
�����ϵ�Modeling��ͱȽϼ���:
m i = BiLSTM ( g i ) �� R 2 H m_i=\text{BiLSTM}({\rm g_i})\in\R^{2H} mi?=BiLSTM(gi?)��R2H
����Output��õ�Ԥ��𰸵�ǰ��λ�ñ�ǩ:
p s t a r t = softmax ( w s t a r t ? [ g i ; m i ] ) p e n d = softmax ( w e n d ? [ g i ; m i �� ] ) m i �� = BiLSTM ( m i ) �� R 2 H w s t a r t , w e n d �� R 10 H p_{\rm start}=\text{softmax}(w_{\rm start}^\top[{\bf g}_i;{\bf m}_i])\\ p_{\rm end}=\text{softmax}(w_{\rm end}^\top[{\bf g}_i;{\bf m}_i'])\\ {\bf m}_i'=\text{BiLSTM}({\bf m}_i)\in \R^{2H}\\ w_{\rm start},w_{\rm end}\in\R^{10H} pstart?=softmax(wstart??[gi?;mi?])pend?=softmax(wend??[gi?;mi��?])mi��?=BiLSTM(mi?)��R2Hwstart?,wend?��R10H
Ŀ�꺯���� start \text{start} start�� end \text{end} end�Ľ�������ʧ:
L = ? log ? p s t a r t ( s ? ) ? log ? p e n d ( e ? ) \mathcal{L}=-\log p_{\rm start}(s^*)-\log p_{\rm end}(e^*) L=?logpstart?(s?)?logpend?(e?)
���ģ������Ч����F1�÷�77.3,�����о����Ϊ:�� ����context-to-query attention�õ�F1�÷�67.7;
�� ����query-to-context attention�õ�F1�÷�73.7;
�� ����charEmb�õ�F1�÷�75.4;
Ŀǰ���Ƚ���ģ��(2017��)���Դﵽ79.7��ˮƽ��
-
2019��֮�����õ��������Ķ������BERT�������ģ�͵���:slides p.31
���������������ˮƽ:
F1 EM ����ˮƽ 91.2 82.3 BiDAF 77.3 67.7 BERT-base 88.5 80.8 BERT-large 90.9 84.1 XLNet 94.5 89.0 ReBERTa 94.6 88.9 ALBERT 94.8 89.3 ����BiDAF�IJ�����ֻ��2.5M,BERT�����������Ҳ��110M~330M��ˮƽ,��ǰ�ߵ�Ԥѵ��������GloVe,���ߵ�Ԥѵ���ͺܶ��ˡ�
��Ȼ�Ƚ���ģ���Ѿ���SQuAD��Խ������,�����Ⲣ����ζ���Ķ����������Ѿ������,��Ϊ��������������ϱ�����Ȼ�ܲ�(TriviaQA,NQ,QuAC,NewsQA):What do Models Learn from Question Answering Datasets?

-
-
�ܶ���Ȼ���Դ��������Ա���Լ���Ķ�����:����Ϣ��ȡ�������ɫ��ע;
-
�Ƿ������Ƹ��õ�Ԥѵ��Ŀ��?
SpanBERT����������µ��뷨:
-
masking contiguous spans of words instead of 15% random words
-
using the two end points of span to predict all the masked words in between = compressing the information of a span into its two endpoints
y i = f ( x s ? 1 , x e + 1 , p i ? s + 1 ) y_i=f(x_{s-1},x_{e+1},p_{i-s+1}) yi?=f(xs?1?,xe+1?,pi?s+1?)
-
-
�ĵ��������͵�QAģ�Ϳ��(���������������):�Ƽ��Ķ�����ƪDrQA��
˼�������һ���ĵ��������ȼ����ĵ�,Ȼ����ĵ���ժȡ�𰸡�
����ļ���������TFIDF,�Ķ�����BiDAF���������ࡣ
ע������Ҳ����ѵ��һ��������(�ͱ��ߵľ������,�о�û�����Ҫ)��
-
���µ��о����������ɴ�,���Ǽ�����,����о���:
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
-
һЩ������ģ��Ҳ�������ڿ��������ʴ�,��Ҫ����Ԥ�ⱻ�ڵ��ĵ���,���������Ҳ��һ���ʴ�:
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
-
�ʴ��ĵ���ͨ�����������Ķ���(ԶԶ�����ʻ����ģ,��ά���ٿ�Ϊ�����������600��),���ʹ�ó��ܵ�������ʾ�Dz���ʵ��,�Ƽ��Ķ����һƪ���ǽ����������,���ѧϰ����ij��ܱ�ʾ�������Ƽ�һƪ���������о�Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
notes
[notes]
�����ıʼDz�����ϸ������һ�����ڽ�������ı���ͼ����ʴ��������̬�ڴ�����(Dynamic Memory Networks,DMN,Ask Me Anything: Dynamic Memory Networks for Natural Language Processing)��DMN������QA��������,��ʹ����������˵Ҳ���Ѵ洢һ������ֵ�����,�������Ҫʹ�ö�̬�ڴ档
�����������˲��������ʵ��:֪��
����������DMN�ĸ���ģ��:
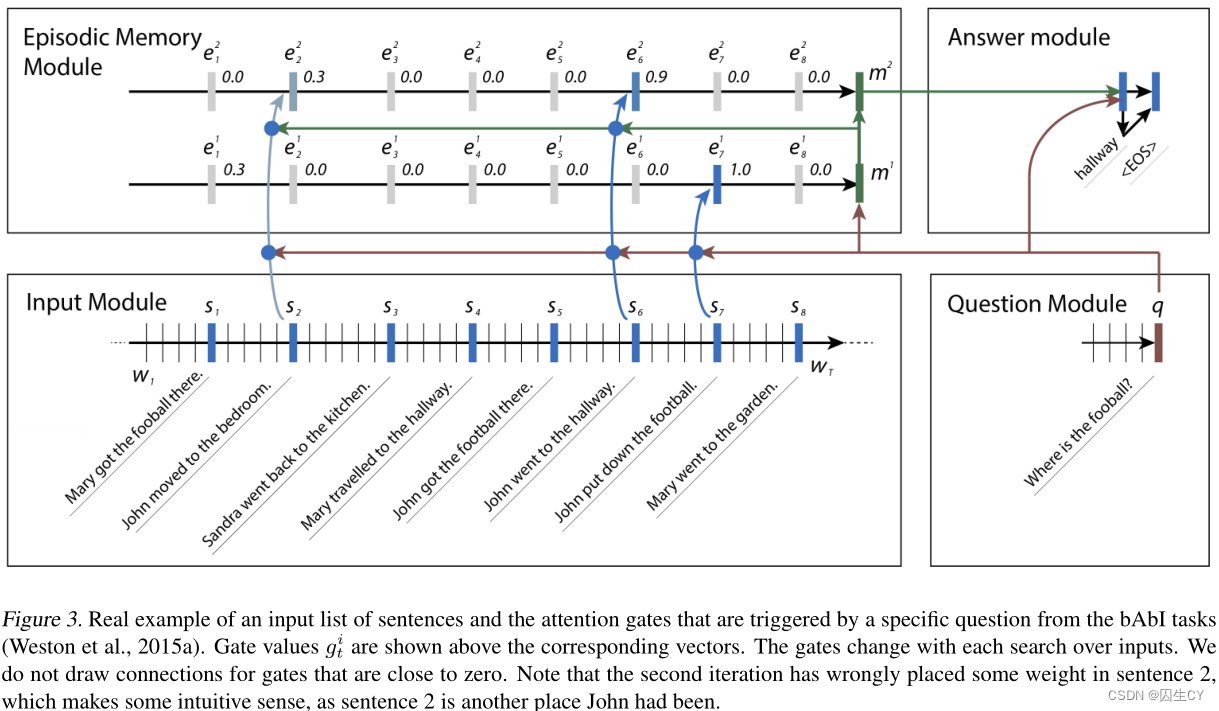
-
����ģ��(Input Module):������Ϊ T 1 T_1 T1?�ĵĵ���������Ϊ����,����Ϊ T C T_C TC?����ʵ��ʾ��Ϊ������������һϵ�е���,���� T 1 = T C T_1=T_C T1?=TC?;�������һϵ�о���,�� T 1 T_1 T1?���ھ����еĵ���������
��GRU��ȡ����,�� h t = GRU ( x t , h t ? 1 ) h_t=\text{GRU}(x_t,h_{t-1}) ht?=GRU(xt?,ht?1?),���� x t = L [ w t ] x_t=L[w_t] xt?=L[wt?],���� L L L��Ƕ�����, w t w_t wt?����ʱ��� t t t���ĵ��ʡ�
-
����ģ��(Question Module):
����һ����GRU����ȡ����: q t = GRU ( L [ w t Q ] , q t ? 1 ) q_t=\text{GRU}(L[w_t^Q],q_{t-1}) qt?=GRU(L[wtQ?],qt?1?),����ģ������������ı����ʾ��
-
Ƭ���ڴ�ģ��(Episodic Memory Module):��������֮��
˼��:�����Ӽ���ı�ʾ(��������ģ��)���뵽˫��GRU��,������Ƭ���ڴ��ʾ��
��Ƭ���ڴ��ʾΪ m i m^i mi,��Ƭ�α�ʾ(episode representation,ע���������)Ϊ e i e^i ei,���ʼ��Ƭ���ڴ��ʾΪ m 0 = q m^0=q m0=q,Ȼ���������� m i = GRU ( e i , m i ? 1 ) m^i=\text{GRU}(e^i,m^{i-1}) mi=GRU(ei,mi?1),����Ƭ�α�ʾͨ������ģ�������״̬������ϸ���:
h t i = g t i GRU ( c t , h t ? 1 i ) + ( 1 ? g t i ) h t ? 1 i e i = h T C i h_t^i=g_t^i\text{GRU}(c_t,h_{t-1}^i)+(1-g_t^i)h_{t-1}^i\quad e_i=h_{T_C}^i hti?=gti?GRU(ct?,ht?1i?)+(1?gti?)ht?1i?ei?=hTC?i?
����ע�������� g g g�����ø��ַ�������,�������������ƪDMN������,�������ļ��㷽�������ŵ�:
g t i = G ( c t , m i ? 1 , q ) G ( c , m , q ) = �� ( W ( 2 ) tanh ? ( W ( 1 ) z ( c , m , q ) + b ( 1 ) ) + b ( 2 ) ) z ( c , m , q ) = [ c , m , q , c �� q , c �� m , �O c ? q �O , �O c ? m �O , c ? W ( b ) q , c ? W ( b ) m ] g_t^i=G(c_t,m^{i-1},q)\\ G(c,m,q)=\sigma(W^{(2)}\tanh(W^{(1)}z(c,m,q)+b^{(1)})+b^{(2)})\\ z(c,m,q)=[c,m,q,c\circ q,c\circ m,|c-q|,|c-m|,c^\top W^{(b)}q,c^\top W^{(b)}m] gti?=G(ct?,mi?1,q)G(c,m,q)=��(W(2)tanh(W(1)z(c,m,q)+b(1))+b(2))z(c,m,q)=[c,m,q,c��q,c��m,�Oc?q�O,�Oc?m�O,c?W(b)q,c?W(b)m]
�����Ļ�,���������ڴ��д洢�Ķ�����ֱ�������������,ģ���е��ſؾͻᱻ����,�ڵ� i i i��������,���ܽ�õ���֪ʶ�����Խ������,���ǿ��Լ������е� i + 1 i+1 i+1�����������統��������Where is the football?,��������ΪJohn kicked the football��John was in the field,�����������,John��football�������ڵ�1�ε����б���ϵ��,ʹ�������ܹ�������������Ϣִ��һ������������(transitive inference)�� -
�ش�ģ��(Answer Module):
��Ȼ��һ��GRU������,������ģ��������Ƭ���ڴ�ģ��������Ϊ����,���һ������(��һ��������):
y t = softmax ( W ( a ) a t ) a t = GRU ( [ y t ? 1 , q ] , a t ? 1 ) y_t=\text{softmax}(W^{(a)}a_t)\\ a_t=\text{GRU}([y_{t-1},q],a_{t-1}) yt?=softmax(W(a)at?)at?=GRU([yt?1?,q],at?1?)
suggested readings
-
(SQuAD: 100,000+ Questions for Machine Comprehension of Text)
����100K��ע�õ�����(��ά���ٿ��ռ�,������100~150)������(�����ڳ�)����(�����е�һС�����)��Ԫ�顣SQuAD����Ŀǰ�����Ѿ����,����Ȼ�������ŵ��ʴ����ݼ�֮һ,����������о���
ģ������ָ���Ǿ�ȷƥ���(����ȫ�Ҷ�Ƭ��,ֻ����һ����ȡֵ)��F1�÷�(�������ҵ���Ƭ�κ���ʵƬ�ε�ȷ�����ٻ���,Ȼ��ȡ����ƽ��),����ı��ֱַ���0.823��0.912,��������(�е�������ṩ�������):
Q:?What?did?Tesla?do?in?December?1878? A:?left?Graz,?left?Graz,?left?Graz?and?servered?all?relations?with?his?familty Prediction:?left?Graz?and?severed Exact?match:?max { 0 , 0 , 0 } = 0 F1-score:?max { 0.67 , 0.67 , 0.61 } \text{Q: What did Tesla do in December 1878?}\\ \text{A: {left Graz, left Graz, left Graz and servered all relations with his familty}}\\ \text{Prediction: {left Graz and severed}}\\ \text{Exact match: max}\{0,0,0\}=0\\ \text{F1-score: max}\left\{0.67,0.67,0.61\right\} Q:?What?did?Tesla?do?in?December?1878?A:?left?Graz,?left?Graz,?left?Graz?and?servered?all?relations?with?his?familtyPrediction:?left?Graz?and?severedExact?match:?max{0,0,0}=0F1-score:?max{0.67,0.67,0.61} -
BiDAFģ�ͼܹ������,����slides�����Ѿ��dz���ϸ˵����˼����ԭ����(Bidirectional Attention Flow for Machine Comprehension)
-
DrQAģ�������,���ĵ����м����ĵ�,�ٴ��ĵ��м����𰸽���������⡣(Reading Wikipedia to Answer Open-Domain Questions)
-
����ѵ���ĵ����������ĵ��Ķ�������������⡣(Latent Retrieval for Weakly Supervised Open Domain Question Answering)
-
DPRģ��,Ҳ����BERTѵ���ĵ�������,����ʹ�õ�������𰸵���������ѵ����(Dense Passage Retrieval for Open-Domain Question Answering)
-
���ǹ���ѧϰ�����(Learning Dense Representations of Phrases at Scale)
lecture 12 ��Ȼ��������
slides
[slides]
-
������ô����:��Ȼ���Դ���(NLP)=��Ȼ��������(NLU)+��Ȼ��������(NLG),seq2seq����ͨ������NLG���롣
-
�������е�TopK����(�Ƽ��Ķ����ֵ�һƪ�͵���ƪ):slides p.31
��ʹ�����ܹ�����������ں�С��һ���ʻ㷶Χ��,ʣ�µĺ�ѡ���ʹ��ɵĸ��ʺͿ���Ҳ���Ӵ��,ͳ���ϳ�Ϊ��β(heavy tailed),�������,�����ѡ���ʵ�ȷ����ʶ��Ǵ��ġ�һ����˵K��ȡֵ��5/10/20;
��ʵ����TopK�����е�����������,���Ƽ��Ķ�����ƪΪ��,�����Զ����ɹ���,���ÿ�λ���10����ѡ��(K=10),����ÿ�ζ�����10������̫��,��˸�������Ҫ��֦��
Ȼ�������һ������Ҫ�ĸ������softmax temperature,����softmax�������һ��scaling,�������:
P t ( y t = w ) = exp ? ( S w ) �� w �� �� V exp ? ( S w �� ) ? P t ( y t = w ) = exp ? ( S w / �� ) �� w �� �� V exp ? ( S w �� / �� ) P_t(y_t=w)=\frac{\exp(S_w)}{\sum_{w'\in V}\exp(S_{w'})}\longrightarrow P_t(y_t=w)=\frac{\exp(S_w/\tau)}{\sum_{w'\in V}\exp(S_{w'}/\tau)} Pt?(yt?=w)=��w����V?exp(Sw��?)exp(Sw?)??Pt?(yt?=w)=��w����V?exp(Sw��?/��)exp(Sw?/��)?
����� �� \tau ����Ϊ�¶Ȳ���,��������ƽ�� P t P_t Pt?:- �� �� > 1 \tau>1 ��>1,���ʷֲ������ھ���,�Ա��ڵõ�����ĺ�ѡ�����
- �� �� < 1 \tau<1 ��<1,���ʷֲ�������ͻأ(���ĺ���,�̵�����),�Ա��ڵõ����ٵĺ�ѡ�����
��Զ��סsoftmax������һ�������㷨,��ֻ��һ���������ڲ��Եļ���,����Ի���softmax�����ƽ����㷨(�������������)��
����������Ľ���������кܲ�,���Կ��Ƕ����һЩ������ں�ѡ������,�����Ƽ��Ķ��ж������ᵽ�ġ�
���ںܶ�������lecture6�غϡ�
suggested readings
- slides p.31�ᵽ��NLG�����е�TopK������(The Curious Case of Neural Text Degeneration)
- �ı�������(Get To The Point: Summarization with Pointer-Generator Networks)
- slides p.31�ᵽ��NLG�����е�TopK������(Hierarchical Neural Story Generation)
- �Ի�ϵͳ��(How NOT To Evaluate Your Dialogue System)
lecture 13 ��֪ʶ���ɵ�����ģ��
slides
[slides]
-
����ģ�Ϳ����������������ı�������,��:
�� �ı�����(Summarization)
�� �Ի�ϵͳ(Dialogue)
�� �Զ���ȫ(Autocompletion)
�� ��������(Machine learning)
�� ����������(Fluency evaluation)
-
֪ʶ��֪������ģ��:
�����н���text-to-SQL,������Ȼ��������תΪSQL��ѯ��䡣
�������˼�ǽ�����ģ��ֱ����Ϊ֪ʶ��,��Ϊ����ģ�ʹ���Ѿ��ں����ķǽṹ���DZ�ע���ı���ѵ��,��֪ʶ����Ҫ�ֶ���ע��
����ʹ������ģ��ȱ�ٿɽ����ԡ����ζȲ�Ҳ�������
-
��֪ʶ���ɵ�����ģ����:
-
��Ԥѵ���õ�ʵ��Ƕ�����ӵ�����Ƕ����:ERNIE,QAGNN/GreaseLM
�����ᵽ����USA,United States of America,America����ָ����,��������ʵ���ϻ�õ�����������,���������Ҫ����ʵ��Ƕ��������ģ�������ֵ���һ����,�����Ҫ��ʵ��Ƕ���õ��ı���,��������ʵ������(entity linking)��
ѵ��ʵ��Ƕ��,������Ҫ֪ʶͼ�ķ���(TransE),Ҳ����ʹ��word-entity co-ocuurence methods(��Wikipedia2Vec),�Լ�ʹ��Transformer��ʵ���������б���(BLINK)��
��ô�õ���ʵ������ e k e_k ek?������ô���ӵ�����Ƕ�� w j w_j wj?����?
h j = F ( W t w j + W e e k + b ) h_j=F(W_tw_j+W_ee_k+b) hj?=F(Wt?wj?+We?ek?+b)
���� e k e_k ek?�� w j w_j wj?�Ƕ�Ӧ��ʵ���뵥��,ֱ���� W t e k W_te_k Wt?ek?�� W e w j W_ew_j We?wj?Ӧ����ͬһ�����ռ���,��Ϊʵ���뵥��֮�����alignment
���ַ���������ERNIE���Ƽ��Ķ���������ϸ��¼,���������һ��QAGNN/GreaseLM,�ǹ���֪ʶͼ��������ģ��������������,�õ�ģ����ͼ������(��ƪpaper��2021��,�dz��µ�һ���о�,ֵ��ϸ��)��

-
ʹ���ⲿ�洢:
��һ�ַ����������������֪ʶ��ı���,�����Ҫ����ѵ��ʵ��Ƕ��,ģ��ҲҪ����ѵ����
��������ֱ��ʹ���ⲿ�洢,����˼������֪ʶͼ�������½�ģ����ģ���ʡ�
�������ڴ����������ʱ,˳�㹹��һ���ֲ�֪ʶͼ��:

ע��ֲ�֪ʶͼ��Ӧ��������֪ʶͼ��һ���Ӽ�,�ֲ�֪ʶͼ���ܹ�����һ����ǿ���ź�����Ԥ����һ�����ʻ���ʲô,����Ԥ����һ�����ʷ�����ͼ��ʾ:

���Dz�����ֱ��Ԥ����һ������,����������ģ�͵�����״̬��Ԥ����һ�����ʵ�����,Ȼ����������(��Ӧ��ͼ�ұ߿��ڵĽ��):
-
�ھֲ�KG�еĹ���ʵ��:�ھֲ�KG���ҵ��÷���ߵĸ��ڵ��Լ���ϵ(ʹ������ģ�͵�����״̬,�Լ�ʵ���ϵ��Ƕ��):
P ( p t ) = softmax ( v p ? h t ) P(p_t)=\text{softmax}(v_p\cdot h_t) P(pt?)=softmax(vp??ht?)
���� p t p_t pt?��DZ�ڵĸ�ʵ��, v p v_p vp?�Ƕ�Ӧ��ʵ��Ƕ��, h t h_t ht?��LM����״̬,��������Ԥ��top��ϵ��ʵ��,Ȼ��:�� ��һ��ʵ�彫����KG��Ԫ���е�βʵ��(top��ʵ��,top��ϵ,βʵ��);
�� ��һ�����ʽ���������һ��ʵ����ӽ��ĵ��ʡ�
-
���ھֲ�KG�еĹ���ʵ��:�ҵ�����KG�÷���ߵ�ʵ��(ʹ������ģ�͵�����״̬��ʵ��Ƕ��),��:
�� ��һ��ʵ�彫���ǵ÷���ߵ�Ԥ��ʵ��;
�� ��һ�����ʽ���������һ��ʵ����ӽ��ĵ��ʡ�
-
��ʵ��:��һ��ʵ�����None,��һ������ֻ��������ģ����Ԥ���ˡ�
-
-
�Ķ�ѵ������:�ܷ��ӵؽ�֪ʶ���ɵ��ǽṹ���ı���?(�Ƽ��Ķ�����ƪPretrained Encyclopedia)
����˼����ѵ��ģ�����������֪ʶ,���巽���ǽ��ı��е�ʵ����滻Ϊͬ���͵���ͬʵ��ָ���ʵ���,�Թ�����֪ʶ������(negative knowledge statements),����ģ��Ԥ���Ƿ�ʵ�屻�滻�ˡ�����:J.K. Rowling is the author of Harry Potter�����,���ǰ�������һ�����Ǽٵġ�
���Ƽ��Ķ�����ƪpaper�ж�����һ��ʵ���滻��ʧ��Ŀ�꺯����ʹ��ģ���ܹ�������پ���:
L e n t R e p = 1 e �� E + + log ? P ( e �O C ) + ( 1 ? 1 e �� E + ) log ? ( 1 ? P ( e �O C ) ) \mathcal{L}_{\rm entRep}=\textbf{1}_{e\in\mathcal{E}^+}+\log P(e|C)+(1-\textbf{1}_{e\in\mathcal{E}^+})\log(1-P(e|C)) LentRep?=1e��E+?+logP(e�OC)+(1?1e��E+?)log(1?P(e�OC))
���� e e e��һ��ʵ��, C C C��������, E + \mathcal{E}^+ E+��ʾ��ʵʵ��ʡ�
-
-
�������ֵ���������������ģ���е�֪ʶ,���忴�Ƽ��Ķ����ֵ����һƪ��
-
һЩ�������µĽ�չ:
-
Retrieval-augmented language models:
REALM, Guu et al., ICML 2020
RAG, Lewis et al., NeurIPS 2020
Retro, Borgeaud et al., 2022 -
Modifying knowledge in language models:
-
More knowledge-aware pretraining for language models:
-
More efficient knowledge systems:
-
Better knowledge benchmarks:
-
suggested readings
-
��Ԥѵ���õ�ʵ��Ƕ�����ӵ�����Ƕ���С�(ERNIE: Enhanced Language Representation with Informative Entities)
ģ�ͽṹ(ERNIE:Enhanced Language Representation with Informative Entities):
-
�ı�������:���˫��Transformer������,���ڱ����ı����;
-
֪ʶ������:�鼶�ṹ,ÿһ���������ֹ���:
�� ������ע������:һ��������ʵ��Ƕ��,һ�����ڵ���Ƕ��;
�� һ���ںϲ�(fusion layer)���ںϲ�������ע����������;
�������:
h j = �� ( W ~ t ( i ) w ~ j ( i ) + W ~ e ( i ) + e ~ k ( i ) + b ~ ( i ) ) fusion?representation w j ( i ) = �� ( W t ( i ) h j + b t ( i ) ) token?embedding?output(fed?to?next?block) e k ( i ) = �� ( W e ( i ) h j + b e ( i ) ) entity?embedding?output(fed?to?next?block) \begin{aligned} h_j&=\sigma(\tilde W_t^{(i)}\tilde w_{j}^{(i)}+\tilde W_e^{(i)}+\tilde e_k^{(i)}+\tilde b^{(i)})&&\text{fusion representation}\\ w_j^{(i)}&=\sigma(W_t^{(i)}h_j+b_t^{(i)})&&\text{token embedding output(fed to next block)}\\ e_k^{(i)}&=\sigma(W_e^{(i)}h_j+b_e^{(i)})&&\text{entity embedding output(fed to next block)}\\ \end{aligned} hj?wj(i)?ek(i)??=��(W~t(i)?w~j(i)?+W~e(i)?+e~k(i)?+b~(i))=��(Wt(i)?hj?+bt(i)?)=��(We(i)?hj?+be(i)?)??fusion?representationtoken?embedding?output(fed?to?next?block)entity?embedding?output(fed?to?next?block)?

ѵ����ʽ������Ԥѵ����������:masked language model,next sentence prediction(ǰ��������BERT����ѵ������),Knowledge pretrain task(dEA),����������������ڸǵ�һЩtʵ�嵥�ʵĶ����ע,Ȼ��Ԥ��ʵ������,��Ӧ���������е��ĸ����ʶ�Ӧ,�������:
p ( e j �O w i ) = exp ? ( W w i ? e j ) �� k = 1 m exp ? ( W w i ? e k ) p(e_j|w_i)=\frac{\exp(Ww_i\cdot e_j)}{\sum_{k=1}^m\exp(Ww_i\cdot e_k)} p(ej?�Owi?)=��k=1m?exp(Wwi??ek?)exp(Wwi??ej?)?
���Ԥѵ���Ķ����Ǹ��õ�ѧϰ����ʵ��Ķ�����Ϣ,������Ϊ������ʵ��������Ϣ������������������յ�Ŀ�꺯��:
L E R N I E = L M L M + L N S P + L d E A \mathcal{L}_{\rm ERNIE}=\mathcal{L}_{\rm MLM}+\mathcal{L}_{\rm NSP}+\mathcal{L}_{\rm dEA} LERNIE?=LMLM?+LNSP?+LdEA?
����ѵ���õ�������ģ��������������ȡ�������������������̸һ��ERNIE������������:
- �ɹ������ʵ�����ı�(ͨ���ںϲ��Լ�֪ʶԤѵ������);
- ������֪ʶ��ǿ�����������������;
- ��Ҫ��ǰ�������ı��е�ʵ�����֪ʶ���������,��ܷ�ʱ,���Ҳ������ס�
-
-
�ڶ��ַ���,ʹ���ⲿ֪ʶ�⽨ģ����ģ�͡�(Barack��s Wife Hillary: Using Knowledge Graphs for Fact-Aware Language Modeling)
-
�����ַ���,�ı�ѵ������,��֪ʶ����ںϵ��ǽṹ���ı���(Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model)
-
������ģ����Ϊ֪ʶ�⡣(Language Models as Knowledge Bases?)
���ǹ�����������ģ���е�֪ʶ��һƪpaper,˼���ǽ�������ж��ٹ�ϵ�͵�֪ʶ�Ѿ���������Ŀǰ������ģ���С����Է�������ͨ����MASK��������ģ��Ԥ���ڵ���MASK����ʲô�ʡ�
��Ŀ��https://github.com/facebookresearch/LAMA,����LAMA��Ȼ�о�����,�����ѽ���Ϊʲô����ģ�ͻ���ֵú�(��������ģ��ֻ�Ǽ�ס�˵��ʵĹ��ֹ�ϵ,����������֪ʶ)��
���Ǻ����������˸Ľ�E-BERT,ȥ������Щ����Ҫ��ϵ��֪ʶ����Ԥ���MASK��
���е��о�,�����ڽ��LM����֪��֪ʶ,���������LAMA�ļ������,ԭ���Dz�ѯ��ʽ����(���Ӹ�ʽ����),������֪�°����ij�������������,���Dz�ѯ�ǰ°��������ںδ�,����ܾ�崻��ˡ�������������ɸ����LAMA��ʾ(prompts),ͨ����ά���ٿ����ھ�ģ��,Ȼ��ʹ�û���(back-translation)�ķ�ʽ��������ʾ��
project milestone
lecture 14 ƫ��,�����빫��
�����й���һ�㲻�ῼ����Щ���⡣�Թ�,����û��slides����,ֻ����ƪ�Ƽ��Ķ���
suggested readings
- (The Risk of Racial Bias in Hate Speech Detection)
- (Social Bias Frames)
- (PowerTransformer: Unsupervised Controllable Revision for Biased Language Correction)
lecture 15 ������ǿģ��+֪ʶ
����������lecture13���غ�,���ǽ���ν�֪ʶ����ģ�͡�
slides
[slides]
-
֪ʶ�༭:slides p.7(�Ƽ��Ķ���һƪ)
����һ�����µ��о�����,���Ǻܸ������,�о�����������ͼ����������,��Ҫ��ϸ����ƪpaper���ܳ������ס�
p.8-26����Transformer��feed-forward���൱���Ǽ�ֵ���ֵ�(Transformer Feed-Forward Layers Are Key-Value Memories):
y = W 2 �� ( W 1 x ) y=W_2\sigma(W_1x) y=W2?��(W1?x)
����˵��������˵���ijЩ֪ʶ���ı���(�����ǰ��ƶ�������λ�ôӰ����Ϊ����,�о����֪ʶ�ĸı�,�����絽������ôѧ����Ӧ���ָı��)����������:
�� Transformer��feedforward���������Ϊ��ֵ�洢(��֪ʶ���洢��ǰ������ģ����);
�� Transformer��������ʵ��ʵ����һ�������ϲ���ʵ����Ϣ;
�� ����һ���µ��о�����,���ۿ��ܺܿ�ͻ�仯;
-
�ڴ���ǿģ��(momory-augment model):slides p. 38
�ڴ������:�����ĵ������ݿ���Ŀ��ѵ��������ʵ��Ƕ�롣
Ӧ��:��������Ի�ϵͳ/�ʴ�ϵͳ,�������ɡ�ͼ�����ɡ���ʵ����;
�ؼ�����������:ѡȡʲô�����ڴ�?��μ����ڴ�?���ʹ�ü��������ڴ�?
����ٵ��������Ƽ��Ķ��ڶ�ƪ(LaMDA,��������ĶԻ�������):
-
����ģ�ͽ���ʹ����Transformer�Ľ�����,����ɺܶ����,��˽�������ǽ̻�LaMDAʹ��������������֤���������Ļش�
-
������������LaMDA�����˶��ϵͳ�������е�ʵ��,������һ������:
ģ������:
- User: Base, When wae the Eiffel Tower built?
- Base: Research, It was constructed in 1887.
- Research: Search engine, Eiffel Tower construction data
- Search Engine: Research, 15 essential things to know about the Eiffel Tower. The Eiffel Twoer was built in record time: 2 years, 2 months and 5 days. From late January 1887 to March 31, 1889��
ģ�����:
- Research: User, Work started on it in January 1887 and it was opened in March 1889.
����:
�� �����ⲿ�������߿��Խ����ı���Ϊ����,����������õ����ı�;
�� ���ʹ���ⲿ���߿��Թ��Ϊ(boils down to):1)ѧϰ�����ı���ѯ(���뵽�ⲿ����);2)ѧϰ�����ⲿ���ߵ����
�� ������������ʹ�ñ�Transformerģ��������;
-
-
ѵ��һ��������:slides p.67
������о�:Dense Passage Retrieval for Open-Domain Question Answering
������һ����ѯ(˭��ָ�����������),Ȼ���ά���ٿ��м���һƪ����,�Ķ��������𰸡�
û��ѵ��������ô��:ORQA
�����ϼ���������һ�����ֺ���:
f ( input , memory ) �� score f(\text{input},\text{memory})\rightarrow \text{score} f(input,memory)��score
����ͨ�����������������������ֲ�:
p ( memory �O input ) = exp ? f ( input,memory ) �� i exp ? f ( input ) p(\text{memory}|\text{input})=\frac{\exp f(\text{input,memory})}{\sum_i\exp f(\text{input})} p(memory�Oinput)=��i?expf(input)expf(input,memory)?
һ�������õ�һ��memory,�������������Ƿ��а���,�����Ǽ���Reader��s probability of generating right answer:
p ( gold?answer �O input,memory ) p(\text{gold answer}|\text{input,memory}) p(gold?answer�Oinput,memory)
������ϸ�,���������memory�ļ�������,���͡���ô��������������һ��memory,Ȼ������һ����,��ô�������ȷ�ĸ����ж���?
KaTeX parse error: Expected '}', got '_' at position 53: ��t})p(\text{gold_?answer|input,me��
��ʽ������һ���Ǽ������ĸ���,�ڶ������Ķ����ɹ��ĸ���,����������ÿһ��memory�ij��ԡ�һЩmemory��ɹ�,����һЩ���ʧ��,QRQA��˼�����ʹ���ݶ��½������������ʽ(ȡ����),���� p ( memory|input ) p(\text{memory|input}) p(memory|input)����Ȼ��Ȼ���������ܺõ�memory�ϡ�һ�����ڴ�������������ѯ���ش������Եķ���:slides p.83(�Ƽ��Ķ�����ƪ)
����һ��:
�� ����������һ������,����Ϊinput��memory,����õ�����score
�� �мලѧϰ:����ÿ������,�ṩ��memory��memory,Ȼ��ʹ�ü������ܹ���ȷ���֡�
�� �������мලѧϰ,��ʹ��end-to-endѧϰ��
�� �Դ���,��memory����������ģ��,����������ߵ����֡�
�� ���Դ�����,�����ᴴ������������(ʹ��MASK)
-
���ʹ��memory:slides p.89
�Ƽ��Ķ�:Entity-Based Knowledge Conflicts in Question Answering,���������ʴ��Ƿֲ�����,�����������CAIL2021Ҳ�Dz�ࡣ
��κ���ʹ���ڴ������ѵ�:��Զ��ס��Ҫ̫���������ⲿ���ڴ�,Ҳ������ģ����ȫ���ӵ��ⲿ�ڴ�ļ��������
suggested readings
����ƪ���ǽ�����dz��µ��о�,slides���ֶ����ἰ��
- ֪ʶ�༭��(Locating and Editing Factual Knowledge in GPT)
- һ���ڴ���ǿģ�͡�(LaMDA: Language Models for Dialog Applications)
- ���������IJ�ѯ�ش�������(REALM: Retrieval-Augmented Language Model Pre-Training)
lecture 16 ��������,���ݹ�������,�ɷַ���
slides
[slides]
-
RNN��һ��������������������̫�����������һ�����ʵ���Ϣ(��Ϊ��Ϣ�����ŵݹ���ݼ�)��
-
CNN���������ı�����,��Ϊ�ı��Ŀ鼶�������ڷ�����˵�DZȽ�������ġ�����CNN�ǿ��Բ��������(kernel���ڵı��������ǿ��Բ���)��
CNN�Ļ���֪ʶ����¼,������̸��
-
�ڶ������ᵽ�ľ��Ǿ䷨��(��������������������ϵ���������,��Ŀǰ�����Ĺ���,������ھ䷨�����ɿ��Ի�ȥ��lecture6������),�䷨��������Դ���������Ǿ��еݹ�ṹ��(���䵽�Ӿ�ȵ�)��
�䷨���������漰���ɷַ������ⲿ�ֵ��о�������������,������,�������Ҫ�õ���Щ����,�϶�����Ҫ������Щ�о��ġ�
**Ȼ����Ը��ݾ䷨������̬����,��ȹ��������ʵ�������ṹ���������ı����д���!**����뷨����Ҫ(��Ȼ��ԭ����˼�е㱳��,���Ҿ������ƺ�������һ������),�Ҿ��õ�ȷ�������,�䷨����������ʹ��ͼ������ķ��������õ���ʾ,Ҳ��������ָ��ģ�͵Ĺ���,���������Ļ�ģ�;Ͳ���Ψһ����,��������Ȼ������취ʹ��һЩ�ſ�������ʹ��ģ�;��пɱ��ԡ������Ҫ�ú�˼��һ��!
slides p.44-47��һ��̰�����ɾ䷨���İ취,�����Ǵӵײ����еݹ�,�о����������ʿ��Ժϲ�,ȡ������ߵĽ��кϲ���,���Ž�ʣ�µ����뵽��һ�εݹ���,��Ϊ�䷨����ȷ��������������,����ǰ���������ı䵥��˳��,�����ҿ���ֱ�Ӵӵײ������������г���,�������ɵ�һ���Ƕ�����,���Ǿ䷨���ǿ����ж���,������Ҳ���ؼ�,��Ϊ��������ת��Ϊ�������������һ�����ģ����TreeRNN��
�ҿ�������Ҳ����������һ���ıʼ�(http://www.hankcs.com/nlp/cs224n-tree-recursive-neural-networks-and-constituency-parsing.html),����������
-
TreeRNN,TreeLSTM,Recursive Neural Tensor Networks
�����ᵽ�˶�ƪpaper,�ֶ���Manningд��,������Ե�arxiv@manning���ѿ�Manning������,�ùؼ���Tree����,�����ҵ��ܶ����õĶ�����
suggested readings
- CNN�������з��ࡣ(Convolutional Neural Networks for Sentence Classification)
- (Improving neural networks by preventing co-adaptation of feature detectors)
- CNN���ڽ�ģ��䡣(A Convolutional Neural Network for Modelling Sentences)
- �䷨��������(Parsing with Compositional Vector Grammars.)
- �䷨�����еijɷַ�����(Constituency Parsing with a Self-Attentive Encoder)
lecture 17 ��ģ�͵�������
suggested readings
Scaling Laws for Neural Language Models
��ƪֵ�ú��滨ʱ��úÿ�һ�¡�
20220606����:���ı�ע�Ѹ��µ��ҵIJ���
lecture 18 ��ָ��ϵ
slides
[slides]
-
��ָ��ϵ(Coreference Resolution)�о����DZ���ʶ���о�,��ͬһʵ��IJ�ͬʵ����ʶ����е�ʵ������Լ�,����Ҫ��ʶ�������ʵ���(mention)���з����Ǻ��ѵġ�
-
Mention:ָ�ı���ָ��ij��ʵ���һ�鵥��
���¿��Է�Ϊ����:
�� ����:I, your, it, she, him(ʹ�ô���tagger����)
�� ����ʵ��:����,����(ʹ������ʵ��ʶ��ϵͳ����)
�� �����Զ���(ʹ�þ䷨����������)
ʵ��ʶ��(Mention Detection)Ҳ��������ô����,��������������еĴ�����Mention��?
�� It is sunny
�� The best donut in the world
�� 100 miles
��ô��δ�����Щbad mentions?����ѵ��ģ��,�������ʱ��,���Ƕ�����������Ϊ��ѡ��Mention,��֮����ÿһ�����ʶ�������ָ(����˵ȷ�е�ָ��ij�������ʵ��)
-
Anaphora v.s. Coreference:ǰ���Ǿ䷨�ϵĸ�ָ,�����Ǵ����ϵĹ�ָ��

-
Coreferenceģ��:
-
���ڹ����ģ��(�˳ƴ�������,pronominal anaphora resolution)
1976��Hobb����ļ����㷨:
1. Begin at the NP immediately dominating the pronoun 2. Go up tree to first NP or S. Call this X, and the path p. 3. Traverse all branches below X to the left of p, left-to-right, breadth-first. Propose as antecedent any NP that has a NP or S between it and X 4. If X is the highest S in the sentence, traverse the parse trees of the previous sentences in the order of recency. Traverse each tree left-to-right, breadth first. When an NP is encountered, propose as antecedent. If X not the highest node, go to step 5. 5. From node X, go up the tree to the first NP or S. Call it X, and the path p. 6. If X is an NP and the path p to X came from a non-head phrase of X (a specifier or adjunct, such as a possessive, PP, apposition, or relative clause), propose X as antecedent (The original said ��did not pass through the N�� that X immediately dominates��, but the Penn Treebank grammar lacks N�� nodes��.) 7. Traverse all branches below X to the left of the path, in a left-to-right, breadth first manner. Propose any NP encountered as the antecedent 8. If X is an S node, traverse all branches of X to the right of the path but do not go below any NP or S encountered. Propose any NP as the antecedent. 9. Go to step 4
������ʼ�л���֪ʶ���˳ƹ�ָ��ϵ���⡣
-
Mention Pari/Mention Ranking
����Ծ���ʶ�������Mention,ѵ��һ���ۺ�������Mention���оۺϡ�
���߸���һЩ,ֱ��ѵ��һ����������,�ж�����Mention�Ƿ���ڹ�ָ:
J = ? �� i = 1 N �� j = 1 i y i j log ? p ( m j , m i ) J=-\sum_{i=1}^N\sum_{j=1}^iy_{ij}\log p(m_j,m_i) J=?i=1��N?j=1��i?yij?logp(mj?,mi?)
Ȼ�����Խ������������ -
End-to-end neural coreference:ѵ��������ģ��,���Ƽ��Ķ��ڶ�ƪ��
-
-
�ṩ������ָ��ϵ��demo:
suggested readings
- �̲��½ڡ�(Coreference Resolution Chapter from Jurafsky and Martin)
- (End-to-end Neural Coreference Resolution)
lecture 19 �༭������
slides
[slides]
��һ���ǽ�����ô����������(���ӻ�,��,����������˳��,ģ�ͼܹ�,���ݷ����仯,��ε���ģ������Ӧ�仯�������),����������ģ��ѵ�����ڴ�ռ��,��Ҫ��slides̫����,�������ݱȽ���ɢ,���˾���ʵ��Ӧ�ø���ҪһЩ,����������������ɡ�
�е�����lecture15�����ݡ�
���
ǰ����������ʱ���������CS224N,�ܹ黹�������á�
�������,�˻���ȥ,�Ὣ�δ�?
������������
����End

